Sınıflandırma problemindeki boyutsal felaketin ayrıntılı açıklaması ve çözümü
Lei Feng Net Not: Bu makale ilk olarak İngilizce web sitesinde "mankenler için bilgisayar ziyareti" olarak yayınlandı, çevirmen Red Stone, orijinal olarak çevirmende yayınlandı kişisel blog Leifeng.com yetkilendirildi.
1. Giriş
Bu makalede, sözde "boyutluluk laneti" ni tartışacağız ve bir sınıflandırıcı tasarlarken neden bu kadar önemli olduğunu açıklayacağız. İlerleyen bölümlerde, bu kavramın sezgisel bir açıklamasını vereceğim ve onu boyutluluk laneti nedeniyle aşırı uyum örneği üzerinden açıklayacağım.
Bu örneği düşünün, bazı resimlerimiz var ve her resim bir yavru kedi veya bir köpek yavrusu tasvir ediyor. Resimdeki kedi mi yoksa köpek mi olduğunu otomatik olarak tanımak için bir sınıflandırıcı oluşturmaya çalışıyoruz. Bunu yapmak için, öncelikle kedi ve köpeklerin nicel özelliklerini göz önünde bulundurmamız gerekir, böylece sınıflandırıcı algoritma bu özellikleri resimleri sınıflandırmak için kullanabilir. Örneğin, kedileri ve köpekleri kürk rengi özellikleriyle, yani resimdeki farklı kırmızı, yeşil ve mavi dereceleriyle tanımlayabiliriz, basit bir doğrusal sınıflandırıcı tasarlayabiliriz:
0,5 * kırmızı + 0,3 * yeşil + 0,2 * mavi ise > 0.6:
dönüş kedisi;
Başka:
dönüş köpeği;
Kırmızı, yeşil ve mavinin üç rengi özellik olarak adlandırılır, ancak yalnızca bu üç özelliği kullanarak mükemmel bir sınıflandırıcı elde edemezsiniz. Bu nedenle, resmi açıklamak için daha fazla özellik ekleyebiliriz. Örneğin, resmin X ve Y yönlerinde ortalama kenar veya gradyan yoğunluğunu hesaplayın. Artık sınıflandırıcımızı oluşturmak için toplam 5 özellik var.
Daha iyi bir sınıflandırma efekti elde etmek için renk, doku dağılımı ve istatistiksel bilgiler gibi daha fazla özellik ekleyebiliriz. Belki yüzlerce özellik elde edebiliriz, ancak sınıflandırıcının performansı daha iyi olacak mı? Cevap biraz sinir bozucu: hayır! Aslında, özelliklerin sayısı belirli bir değeri aştığında, bunun yerine sınıflandırıcının etkisi azalır. Şekil 1, "boyutsal felaket" olan bu eğilimi göstermektedir.

Şekil 1. Boyut arttıkça sınıflandırıcının performansı artar; boyut belirli bir değere yükseldikten sonra sınıflandırıcının performansı düşer
Bir sonraki bölümde bu eğrinin neden oluşturulduğunu açıklayacak ve bundan nasıl kaçınılacağını tartışacağız.
2. Boyutsal felaket ve aşırı uyum
Daha önce tanıtılan kedi ve köpekler örneğinde, sonsuz sayıda kedi ve köpek resmi olduğunu varsayıyoruz, ancak, zaman ve işlem gücü kısıtlamaları nedeniyle, sadece 10 resim (kedi resimleri veya köpek resimleri) elde ediyoruz. Nihai hedefimiz, bu 10 görüntüye dayalı olarak, 10 örneğin ötesinde sonsuz sayıda görüntüyü doğru şekilde sınıflandırabilen bir sınıflandırıcı oluşturmaktır.
Şimdi, iyi bir sınıflandırıcı elde etmek için basit bir doğrusal sınıflandırıcı kullanalım. Örneğin yalnızca bir özellik kullanılıyorsa, resmin ortalama kırmızılığını kırmızı kullanın.

Şekil 2. Tek bir özellik eğitim örneklerini sınıflandırmada iyi performans göstermiyor
Şekil 2, yalnızca bir özelliğin kullanılmasının optimal bir sınıflandırma sonucu elde etmediğini göstermektedir. Bu nedenle, ikinci bir özellik eklemeyi düşünüyoruz: resmin ortalama yeşilliği yeşil.

Şekil 3. İkinci özelliği eklemek hala doğrusal olarak bölümlere ayrılamaz, yani kediyi ve köpeği tamamen ayırabilecek düz bir çizgi yoktur.
Son olarak, üçüncü bir özellik eklemeye karar verdik: üç boyutlu bir özellik alanı elde etmek için resmin ortalama maviliği:

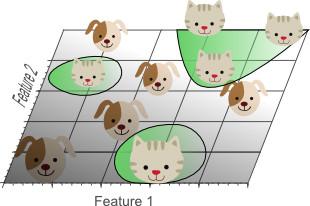
Şekil 4. Doğrusal ayrılabilirliği sağlamak için üçüncü bir özellik eklemek, yani kediyi ve köpeği tamamen ayıran bir düzlem vardır.
Üç boyutlu özellik uzayında, kedi ve köpeği tamamen ayırmak için bir uçak bulabiliriz. Bu, üç özelliğin doğrusal kombinasyonunun 10 eğitim örneğini en iyi şekilde sınıflandırabileceği anlamına gelir.

Şekil 5. Ne kadar fazla özellik olursa, doğru sınıflandırmaya ulaşma olasılığı o kadar yüksektir
Yukarıdaki örnek, en iyi sınıflandırma etkisi elde edilene kadar özelliklerin sayısını artırmanın bir sınıflandırıcı oluşturmanın en iyi yolu olduğunu kanıtlıyor gibi görünüyor. Ancak Şekil 1'de durumun böyle olmadığına inanıyoruz. Bir soruya dikkat etmemiz gerekiyor: Özellik boyutu arttıkça, özellik uzayındaki eğitim örneğinin yoğunluğu üssel olarak nasıl azalır?
1D alanda (Şekil 2'de gösterilmiştir), 10 eğitim örneği 1B özellik alanını tamamen kaplar ve özellik alanının genişliği 5'tir. Bu nedenle, 1D'deki numune yoğunluğu 10/2 = 5'tir. 2D uzayda (Şekil 3'te gösterilen) ayrıca 10 eğitim numunesi vardır ve oluşturduğu 2D özellik uzay alanı 5x5 = 25'dir, bu nedenle 2D'deki numune yoğunluğu 10/25 = 0.4'tür. Son olarak, 3B alanda, 10 eğitim örneğinin oluşturduğu özellik uzayının boyutu 5x5x5 = 125, yani 3B'deki örnek yoğunluğu 10/125 = 0,08'dir.
Unsur eklemeye devam edersek, tüm unsur uzayının boyutu artar ve gittikçe daha seyrekleşir. Seyreklik nedeniyle, sınıflandırmaya ulaşmak için bir hiper düzlem bulmamız daha kolay. Bunun nedeni, özelliklerin sayısı sonsuz hale geldikçe, eğitim örneğinin optimal hiper düzlemin yanlış tarafında olma olasılığının sonsuz küçük hale gelmesidir. Bununla birlikte, yüksek boyutlu sınıflandırma sonuçlarını düşük boyutlu uzaya yansıtırsak, ciddi bir sorun ortaya çıkacaktır:
Şekil 6. Çok fazla özelliğin kullanılması gereğinden fazla takmaya neden olur. Sınıflandırıcı, çok fazla örnek verinin anormal özelliklerini (gürültüyü) öğrenmiştir ve yeni verilere genelleme yeteneği iyi değildir.
Şekil 6, 3B sınıflandırma sonuçlarının 2B özellik alanına nasıl yansıtıldığını gösterir. Örnek veriler, 3D olarak doğrusal olarak ayrılabilir ancak 2D olarak ayrılamaz. Aslında, en iyi doğrusal sınıflandırma etkisini elde etmek için üçüncü bir boyut eklemek, düşük boyutlu bir özellik uzayında doğrusal olmayan bir sınıflandırıcı kullanmaya eşdeğerdir. Sonuç olarak, sınıflandırıcı eğitim verilerinin gürültüsünü ve anormalliklerini öğrenir, ancak örnek dışındaki verilere uydurma etkisi ideal değildir, hatta zayıftır.
Bu kavrama aşırı uyum denir ve boyutluluk lanetinin doğrudan bir sonucudur. Şekil 7, sınıflandırma için yalnızca 2 özellik kullanan bir doğrusal sınıflandırıcının iki boyutlu bir plan görünümünü göstermektedir.
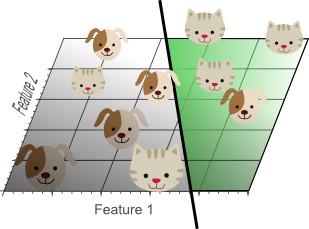
Şekil 7. Tüm eğitim örnekleri doğru şekilde sınıflandırılamasa da, bu sınıflandırıcının genelleme yeteneği Şekil 5'ten daha iyidir.
Şekil 7'deki basit doğrusal sınıflandırıcı Şekil 5'teki doğrusal olmayan sınıflandırıcıdan daha az etkili olmasına rağmen, Şekil 7'deki sınıflandırıcının genelleştirme yeteneği daha güçlüdür. Bunun nedeni, sınıflandırıcının örnek verilerin gürültüsünü ve anormalliklerini öğrenmemesidir. Öte yandan, daha az öznitelik kullanarak boyutluluk laneti önlenebilir ve eğitim örneklerinin aşırı uyumu olmayacaktır.
Şekil 8, yukarıdakileri farklı bir şekilde açıklamaktadır. Sınıflandırıcıyı eğitmek için yalnızca bir özellik kullandığımızı, 1B özellik değeri aralığının 0 ile 1 arasında sınırlı olduğunu ve her bir kedi ve köpeğe karşılık gelen özellik değerinin benzersiz olduğunu varsayalım. Eğitim numunesinin özellik değerinin, özellik değeri aralığının% 20'sini oluşturmasını istiyorsak, eğitim numunelerinin sayısı toplam numune sayısının% 20'sine ulaşmalıdır. Şimdi, ikinci bir özellik eklerseniz, yani düz bir çizgiden düz bir 2B özellik alanına geçerseniz, bu durumda, özellik değeri aralığının% 20'sini kapsamak istiyorsanız, eğitim örnek sayısı toplam örnek sayısının% 45'ine (0,450 .45 = 0.2). 3B alanda, özellik değeri aralığının% 20'sini kapsamak istiyorsanız, eğitim örneklerinin sayısının toplam örnek sayısının% 58'ine ulaşması gerekir (0,580,58 * 0,58 = 0,2).

Şekil 8. Özellik değeri aralığının% 20'sini kapsaması için gereken eğitim örneği sayısı, boyutluluk arttıkça katlanarak artar
Başka bir deyişle, mevcut eğitim örneklerinin sayısı sabitlenmişse, o zaman özellik boyutu artırılırsa aşırı uyum meydana gelecektir. Öte yandan, öznitelik boyutu artırılırsa, aynı öznitelik değer aralığını kapsamak ve aşırı uydurmayı önlemek için, gerekli eğitim örneği sayısı katlanarak artacaktır.
Yukarıdaki örnekte, boyutluluk lanetinin seyrek eğitim verilerine neden olabileceğini gösterdik. Ne kadar çok özellik kullanılırsa, veriler o kadar seyrekleşir, bu da sınıflandırıcının sınıflandırma etkisinin daha kötü olmasına yol açar. Boyutsallık laneti, arama alanında veri seyrekliğinin eşit olmayan dağılımına da neden olabilir. Aslında, orijinin etrafındaki veriler (hiperküpün merkezinde), arama alanının köşelerindeki verilerden çok daha seyrektir. Bu, aşağıdaki örnekle açıklanabilir:
Bir birim karenin bir 2B özellik uzayını temsil ettiğini düşünün, öznitelik uzayının ortalama değeri birim karenin merkezinde yer alır ve merkezden bir birim mesafedeki tüm noktalar karenin yazılı dairesini oluşturur. Birim çembere düşmeyen eğitim örnekleri, arama alanının köşelerine ve merkeze daha yakındır ve bu örneklerin, özellik değerlerindeki büyük farklılık nedeniyle sınıflandırılması zordur (örnekler karenin köşelerine dağıtılır). Bu nedenle, örneklerin çoğu birimin yazılı dairesi içine düşerse, sınıflandırılması daha kolay olacaktır. Şekil 9'da gösterildiği gibi:

Şekil 9. Birim çemberin dışında kalan eğitim örnekleri, özellik uzayının köşelerinde yer alır ve özellik uzayının merkezinde bulunan örneklere göre sınıflandırılması daha zordur.
İlginç bir soru, özellik uzayının boyutsallığını arttırdığımızda, karenin hacmi (hiper küp) değiştikçe dairenin hacmi (hiper küre) nasıl değişir? Boyut nasıl değişirse değişsin, bir hiperküpün hacmi 1'dir ve 0,5 yarıçaplı bir hiper kürenin hacmi d boyutuyla aşağıdaki gibi değişir:

Şekil 10, d boyutu arttıkça hiper kürenin hacminin nasıl değiştiğini göstermektedir:

Şekil 10. d boyutu büyük olduğunda, hiper kürenin hacmi sıfıra meyillidir.
Bu, boyutlar büyüdükçe, hiper kürecik hacminin değişmeden kalırken hiperküre hacminin sıfırlanma eğiliminde olduğunu gösterir. Bu şaşırtıcı karşı-sezgisel keşif, kısmen sınıflandırmadaki boyutluluk laneti sorununu açıklıyor: Yüksek boyutlu bir alanda, eğitim verilerinin çoğu, özellik alanı olarak tanımlanan hiperküpün köşelerine dağıtılır. Daha önce de belirtildiği gibi, özellik uzayının köşelerindeki örneklerin doğru sınıflandırılması, hipersferdeki örneklere göre daha zordur. Şekil 11, bu sonucu 2B, 3B ve görselleştirilmiş 8D hiperküpler (2 ^ 8 = 256 köşe) örneklerinden göstermektedir.
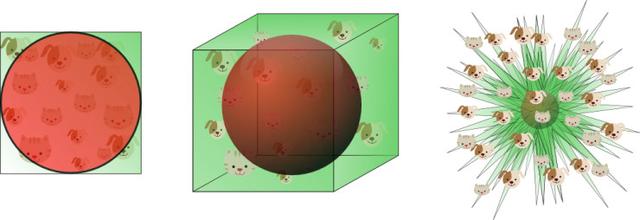
Şekil 11. Boyutsallık arttıkça nicel verilerin çoğu köşelere dağılmıştır.
8 boyutlu bir hiper küre için, verilerin yaklaşık% 98'i 256 köşesinde yoğunlaşmıştır. Sonuç olarak, özellik uzayının boyutu sonsuz hale geldiğinde, örnek noktasından maksimum ve minimum Öklid uzaklığı arasındaki farkın ağırlık merkezine ve minimum Öklid mesafesine oranı sıfıra meyillidir:
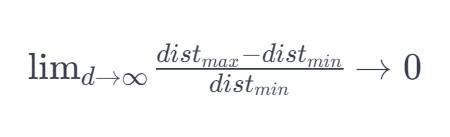
Bu nedenle, yüksek boyutlu uzayda mesafe ölçümü giderek geçersiz hale gelir. Sınıflandırıcı bu mesafe ölçümlerine dayandığından (Öklid mesafesi, Mahalanobis mesafesi, Manhattan mesafesi gibi), daha az düşük boyutlu uzamsal özellik vardır ve sınıflandırma daha kolaydır. Benzer şekilde, yüksek boyutlu uzaydaki Gauss dağılımı düzleşecek ve kuyruk daha uzun olacaktır.
3. Boyutsal felaketten nasıl kaçınılır
Şekil 1, boyutsallık arttıkça sınıflandırıcının performansının azaldığını göstermektedir. Öyleyse soru, "büyük" ne anlama geliyor? Aşırı uyumdan nasıl kaçınılır? Ne yazık ki, sınıflandırma problemlerinde kaç tane özelliğin kullanılması gerektiğini belirleyen sabit kurallar yoktur. Aslında, eğitim örneklerinin sayısına, karar sınırının karmaşıklığına ve hangi sınıflandırıcının kullanıldığına bağlıdır.
Teoride sonsuz sayıda eğitim örneği varsa, boyutsal felaket gerçekleşmez ve mükemmel bir sınıflandırıcı elde etmek için sonsuz sayıda özellik kullanabiliriz. Daha az eğitim verisi, kullanılacak daha az özellik. N eğitim örneği 1B özellik alanını kapsıyorsa, 2B'de aynı yoğunluğu kapsamak için NN verileri gerekir ve 3B'de NN * N verileri gerekir. Diğer bir deyişle, boyutsallık arttıkça, eğitim örneklerinin sayısının katlanarak artması gerekmektedir.
Buna ek olarak, doğrusal olmayan karar sınırlarına sahip sınıflandırıcılar (sinir ağları, KNN sınıflandırıcılar, karar ağaçları, vb.) İyi sınıflandırma etkilerine sahiptir, ancak genelleme kabiliyeti zayıftır ve aşırı uyuma eğilimlidir. Bu nedenle, bu sınıflandırıcıları kullanırken boyutluluk çok yüksek olamaz. İyi genelleme becerisine sahip bir sınıflandırıcı kullanıyorsanız (Bayes sınıflandırıcı, doğrusal sınıflandırıcı gibi), sınıflandırıcı modeli karmaşık olmadığı için daha fazla özellik kullanabilirsiniz. Şekil 6, yüksek boyutlardaki basit bir sınıflandırıcının, durum uzayındaki karmaşık bir sınıflandırıcıya karşılık geldiğini göstermektedir.
Bu nedenle, aşırı uyum, yalnızca yüksek boyutlu uzayda nispeten az sayıda parametrenin tahmin edilmesi ve düşük boyutlu uzayda birden fazla parametrenin tahmin edilmesi durumunda meydana gelir. Örneğin, Gauss yoğunluğu işlevinin iki tür parametresi vardır: ortalama ve kovaryans matrisi. 3B uzayda kovaryans matrisi, toplam 6 değer (3 ana köşegen değer ve 3 çapraz olmayan değer) ve 3 ortalama değer içeren 3x3 simetrik bir matristir. Bunları bir araya toplayın, toplam 91D'de, Gauss yoğunluğu işlevi yalnızca 2 parametre (1 ortalama, 1 varyans) gerektirir; 2B'de Gauss yoğunluğu işlevi 5 parametre gerektirir (2 ortalama, 3 kovaryans parametresi). Boyut arttıkça, parametre sayısının düz bir şekilde arttığını görebiliriz.
Önceki makalede, parametrelerin sayısı artarsa, parametrelerin varyansının artacağını bulduk (tahmin yanlılığı ve eğitim örneklerinin sayısının aynı kalması şartıyla). Bu, çevrenin artması durumunda, tahmin edilen parametrelerin varyansının artması ve bunun da parametre tahminlerinin kalitesinde bir düşüşe neden olacağı anlamına gelir. Sınıflandırıcının varyansındaki bir artış, aşırı uyum anlamına gelir.
Bir başka ilginç soru da şu: hangi özelliklerin seçilmesi gerektiği. N özellik varsa, M özelliğini nasıl seçmeliyiz? Bunun bir yolu, Şekil 1'deki eğride en iyi konumu bulmaktır. Ancak, tüm özellik kombinasyonlarını eğitmek ve test etmek zor olduğundan, en iyi seçeneği bulmanın başka yolları da vardır. Bu yöntemlere özellik seçme algoritmaları denir ve sezgisel yöntemler (açgözlü algoritma, en iyi ilk yöntem, vb.) Genellikle en iyi özellik kombinasyonunu ve miktarını bulmak için kullanılır.
Diğer bir yöntem, N unsurları orijinal özelliklerden birleştirilen M unsurları ile değiştirmektir. Orijinal özelliklerin doğrusal veya doğrusal olmayan kombinasyonunu optimize ederek problemin boyutluluğunu azaltan bu algoritmaya özellik çıkarma denir. İyi bilinen bir boyut azaltma tekniği, ilgisiz boyutları ortadan kaldıran ve N orijinal unsuru doğrusal olarak birleştiren Temel Bileşen Analizidir (PCA). PCA algoritması, orijinal verinin maksimum varyansını koruyarak, düşük boyutlu bir doğrusal alt uzay bulmaya çalışır. Bununla birlikte, en büyük veri varyansı, verilerin en önemli sınıflandırma bilgilerini temsil etmek zorunda değildir.
Son olarak, aşırı uyumu test etmek ve önlemek için kullanılan çok faydalı bir teknik çapraz doğrulamadır. Çapraz doğrulama, orijinal eğitim verilerini birden çok eğitim örneği alt kümesine böler. Sınıflandırıcının eğitimi sırasında, sınıflandırıcının doğruluğunu test etmek için bir örnek alt kümesi kullanılır ve parametre tahmini için diğer örnekler kullanılır. Çapraz doğrulama sonucu eğitim örneği alt kümesi tarafından elde edilen sonuçla tutarsızsa, bu, aşırı uyumun meydana geldiği anlamına gelir. Eğitim örnekleri sınırlıysa, k-katlama yöntemini kullanabilir veya çapraz doğrulama için bir atış bırakabilirsiniz.
Dört, sonuç
Bu makalede, özellik seçimi, özellik çıkarma, çapraz doğrulama ve boyutluluk lanetinin neden olduğu aşırı uyumdan kaçınmanın önemini tartıştık. Basit bir aşırı uydurma örneğiyle, boyutluluk lanetinin önemli etkisini gözden geçirdik.
Leifeng.com'da İlgili Okumalar:
Metin sınıflandırması (açık) uygulamak için TensorFlow'u nasıl kullanacağınızı öğretin
Metin sınıflandırması uygulamak için TensorFlow'u kullanmayı öğretin (aşağıda)