Derin öğrenmede dengesiz veri setlerinin işlenmesi
Leifeng.com Yapay Zeka Teknolojisi Yorumu: Derin öğrenmede veriler çok önemlidir. Ancak elde ettiğimiz veriler genellikle en alakasız verilerden ve ilgilendiğimiz verilerin küçük bir kısmından oluşabilir. Peki, ihtiyacımız olan sonuçları elde etmek için bu veri setlerini nasıl işleyeceğiz? Mühendis George Seif, bu sorunun ağırlık dengesi yöntemi ve örnekleme yöntemi ile çözülebileceğine inanıyor. Lei Feng'in AI Technology Review tarafından derlenen görüşleri aşağıdadır.

Thanos gibi veri kümenize denge getirin
Tüm veriler mükemmel değildir. Aslında, tamamen dengeli bir gerçek dünya veri seti elde ederseniz, çok şanslı olacaksınız. Çoğu durumda, verilerinizde belirli bir derecede sınıf dengesizliği olacaktır, yani her sınıfın farklı sayıda örneği vardır.
Veri setimizin dengeli bir veri seti olmasını neden istiyoruz?
Bir derin öğrenme projesinde, uzun zaman alabilecek herhangi bir göreve zaman harcamadan önce, bunun değerli bir araştırma olmasını sağlamak için neden bunu yapmamız gerektiğini anlamak önemlidir. Birkaç tür veriyi gerçekten önemsediğimizde, sınıf dengeleme tekniği gerçekten gereklidir.
Örneğin, mevcut piyasa durumuna, konut özelliklerine ve bütçemize göre bir ev satın alıp almayacağımızı tahmin etmeye çalıştığımızı varsayalım. Bu durumda doğru satın alma kararını vermemiz çok önemli çünkü bu kadar büyük bir yatırım. Aynı zamanda, model bize satın almamız gerektiği zaman satın almamamızı söylüyor ki bu çok da önemli değil. Bir evi kaçırırsak, her zaman satın alınacak başka evler olacaktır, ancak bu kadar büyük bir varlığa yanlış yatırım yapmak çok kötüdür.
Bu örnekte, satın alma davranışı üreten birkaç kategorinin verilerinde kesinlikle çok kesin olmamız gerekiyor ve satın alma davranışı üretmeyen bu kategorilerin verileri çok önemli değil. Ancak, gerçek verileri gözlemlediğimizde, "satın alma" verileri "satın alma" verilerinden çok daha azdır. Modelimiz "satın alma" verilerini çok iyi öğrenme eğilimindedir çünkü en fazla veriye sahiptir. Ancak, "satın alma" verileri çalışmasında kötü performans gösterir. Bu, "satın alma" tahminine daha fazla dikkat edebilmemiz için verilerimizi dengelemeyi gerektirir.
Peki ya azınlık verilerini gerçekten umursamıyorsak? Örneğin, resim sınıflandırması yaptığımızı ve sınıf dağılımınızın şuna benzer olduğunu varsayalım:
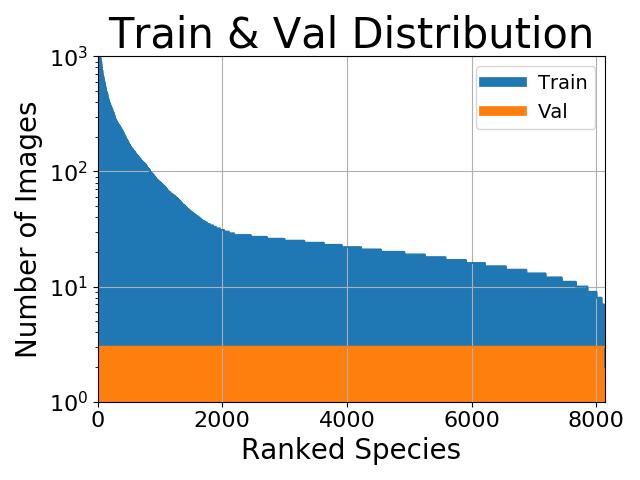
İlk bakışta, verilerimizi dengelemek faydalı görünüyor. Ancak bu birkaç kategoriyle ilgilenmeyebiliriz. Belki de asıl amacımız mümkün olan en yüksek doğruluk oranını elde etmektir. Bu durumda, herhangi bir denge kurmanın bir anlamı yoktur, çünkü doğruluğumuzun çoğu daha fazla eğitim örneği olan sınıflardan gelir. İkinci olarak, veri seti dengesiz olsa bile, hedef en yüksek doğruluk yüzdesine ulaştığında, sınıflandırma çapraz entropi kaybı genellikle iyi performans gösterir. Kısacası, azınlığımızın hedeflerimiz üzerinde çok az etkisi vardır, bu nedenle denge gerekli değildir.
Tüm bu durumlarda, verileri dengelemek istediğimiz bir durumla karşılaştığımızda bize yardımcı olmak için kullanılabilecek iki teknik vardır.
(1) Ağırlık dengesi yöntemi
Ağırlık dengesi yöntemi, kaybı hesaplarken her eğitim örneğinin ağırlığını değiştirerek verilerimizi dengeler. Genel olarak, kayıp fonksiyonumuzdaki her örnek ve sınıf, 1.0 olan aynı ağırlığa sahiptir. Ancak bazen, daha önemli belirli kategorilerin veya belirli eğitim örneklerinin daha fazla ağırlığa sahip olduğunu umabiliriz. Yine ev satın alma örneğimize değinecek olursak, "satın al" kategorisinin doğruluğu bizim için en önemli olduğundan, bu kategorideki eğitim örneklerinin zarar fonksiyonu üzerinde önemli bir etkisi olmalıdır.
Her örneğin kaybını, sınıflarına bağlı bazı faktörlerle çarparak basitçe sınıfları ağırlıklandırabiliriz. Keras'ta bunun gibi şeyler yapabiliriz:
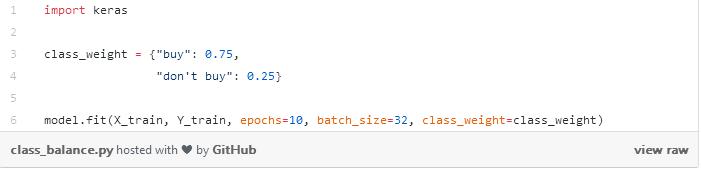
Bir sözlük oluşturduk ve temel olarak "satın alma" kategorimizin kayıp fonksiyonunun ağırlığının% 75'ini oluşturması gerektiğini söyledik, çünkü daha önemli olan "satın alma" kategorisi, buna göre% 25'e ayarladık. Elbette bu değerler, uygulama senaryosunda en iyi ayarları bulmak için kolayca ayarlanabilir. Bir sınıfın diğer sınıftan önemli ölçüde daha fazla örneği varsa, bu yöntemi dengelemek için de kullanabiliriz. Daha fazla azınlık sınıfı örneği toplamak için zaman ve kaynak harcamak zorunda kalmadan tüm sınıfların kayıp işlevimiz üzerinde aynı etkiye sahip olmasını sağlamak için ağırlık dengesi yöntemini kullanmayı deneyebiliriz.
Eğitim örneklerinin ağırlıklarını dengelemek için kullanabileceğimiz bir başka yöntem, aşağıda gösterildiği gibi odak kaybı yöntemidir. Ana fikri şudur: veri setimizde, her zaman sınıflandırması diğer örneklerden daha kolay olan bazı eğitim örnekleri olacaktır. Eğitim sırasında, bu örnekler% 99 doğrulukla sınıflandırılırken, diğer daha zorlayıcı örnekler kötü performans gösterebilir. Sorun, sınıflandırması kolay eğitim örneklerinin hala kayıplara neden olmasıdır. Daha zorlayıcı başka veri noktaları olduğunda, doğru şekilde sınıflandırılırlarsa, bu veri noktaları genel doğruluğumuza daha büyük katkı sağlayabilir. Neden onlara hala aynı ağırlığı veriyoruz?
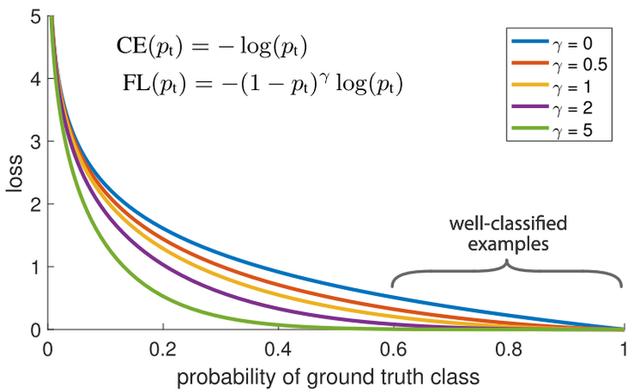
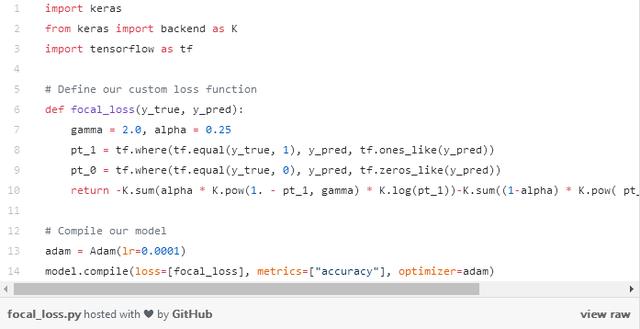
Odak uzaklığı kaybı yönteminin çözebileceği sorun tam da budur! Odak kaybı, tüm eğitim örneklerine eşit ağırlık vermek değil, iyi sınıflandırılmış örneklerin ağırlığını azaltmaktır. Bunun doğrudan etkisi, sınıflandırılması zor olan veriler üzerinde daha fazla eğitime odaklanmaktır! Veri dengesizliği olan gerçek bir ortamda, çoğu sınıf çok hızlı bir şekilde sınıflandırılacaktır çünkü daha fazla eğitim örnek verisine sahibiz. Bu nedenle, azınlık sınıflarına yönelik eğitimimizin daha yüksek bir doğruluk elde etmesini sağlamak için, odak uzaklığı kaybını bu azınlık sınıflarına eğitimde daha fazla göreceli ağırlık vermek için kullanabiliriz. Odak uzaklığı kaybı, Keras'ta özel bir kayıp işlevi olarak kolayca uygulanabilir:
(2) Fazla örnekleme ve yetersiz örnekleme
Doğru sınıf ağırlığını seçmek bazen karmaşıktır. Basit ters frekans işleme yapmak her zaman kullanışlı değildir. Odak kaybı yöntemi kullanışlıdır, ancak öyle olsa bile, her sınıftaki iyi sınıflandırılmış örneklerin ağırlığını aynı ölçüde azaltacaktır. Bu nedenle, verileri dengelemenin başka bir yolu, doğrudan örnekleme yoluyla elde etmektir. Aşağıdaki şekil bir örnektir.
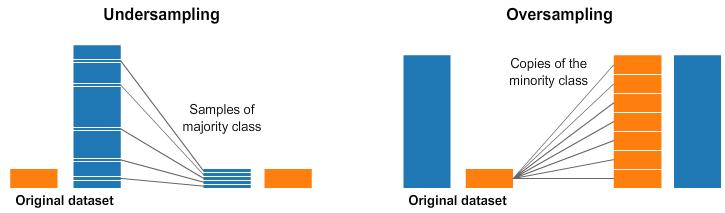
Yukarıdaki görselin sol ve sağ tarafında mavi sınıfımızın turuncu sınıfına göre daha fazla örneği var. Bu durumda, makine öğrenimi modelimizi eğitmeye yardımcı olabilecek iki ön işleme seçeneğimiz var.
Alt örnekleme, çoğunluk sınıfından yalnızca bazı verileri seçeceğimiz ve azınlık sınıfının sahip olduğu örnek verileri kullanacağımız anlamına gelir. Bu seçim, sınıfın olasılık dağılımını korumak için kullanılabilir. Bu çok kolay! Verilerimizi sadece örnek örneğini azaltarak dengeliyoruz!
Yüksek hızda örnekleme, azınlık sınıfının birkaç kopyasını oluşturacağımız anlamına gelir, böylece azınlık sınıfı ve çoğunluk sınıfı aynı sayıda örneğe sahip olur. Azınlığın doğruluk üzerindeki etkisini korumak için kopya sayısı yeterli olmalıdır. Daha fazla veri almadan veri setimizi düzenledik! Sınıf ağırlıklarını etkili bir şekilde belirlemekte zorlanıyorsanız, örnekleme sınıf dengesinin yerini alabilir.
Leifeng.com AI Technology Review tarafından derlenen George Seif blogu aracılığıyla.