Word2Vec - derin öğrenmede küçük bir adım, doğal dil işlemede büyük bir adım
Lei Feng Net Press: Bu makale, Lei Feng Net'in altyazı grubu olan orijinal başlık A, Word2Vec tarafından derlenen teknik bir blogdur - Derin Öğrenmede küçük bir adım ancak Doğal Dil İşlemeye doğru dev bir adım, yazar makine öğrenimi mühendisi Suvro Banerjee
Çeviri | Yu Zhipeng Lin Xiao Redaksiyon | Cheng Sijie Bitirme | Kong Lingshuang
Orijinal bağlantı:
https://towardsdatascience.com/word2vec-a-baby-step-in-deep-learning-but-a-giant-leap-towards-natural-language-processing-40fe4e8602ba
Giriş
Word2Vec modeli, "kelime gömme" dediğimiz kelimelerin vektör temsilini öğrenmek için kullanılır. Genellikle bir ön işleme adımı olarak kullanılır, ardından kelime vektörü, tahmin sonuçları oluşturmak ve çeşitli ilginç işlemleri gerçekleştirmek için ayırıcı modele (genellikle RNN) gönderilir.
Neden word2vec öğrenmelisiniz
Görüntü ve ses işleme sisteminin ihtiyaç duyduğu zengin, yüksek boyutlu veri seti, her orijinal görüntünün piksel yoğunluğuna göre vektör olarak kodlanır.Tüm bilgiler bu verilerde kodlanır, böylece sistemde çeşitli varlıklar kurulabilir. (Kedi köpek gibi) ilişki.
Bununla birlikte, geleneksel doğal dil işleme sistemleri genellikle kelimeleri ayrı atomik semboller olarak ele alır, bu nedenle kedi Id537 olarak ve köpek Id143 olarak temsil edilebilir. Bu kodlar keyfidir ve sisteme çeşitli atomik semboller arasındaki ilişki hakkında herhangi bir bilgi sağlayamaz. Bu, modelin köpeklerin verilerini işlerken modelin öğrendiği kedilerin özellikleriyle ilgili olamayacağı anlamına gelir (örneğin, hepsi hayvan, hepsinin dört bacağı var, hepsi evcil hayvan, vb.).
Kelimeleri benzersiz, ayrı kimlikler olarak temsil etmek, veri seyrekliğine daha da yol açabilir ve aynı zamanda istatistiksel modelleri başarılı bir şekilde eğitmek için daha fazla veriye ihtiyacımız olabileceği anlamına gelir. Vektör gösterimini kullanmak bu sorunları önleyebilir.
Bir örnek görelim
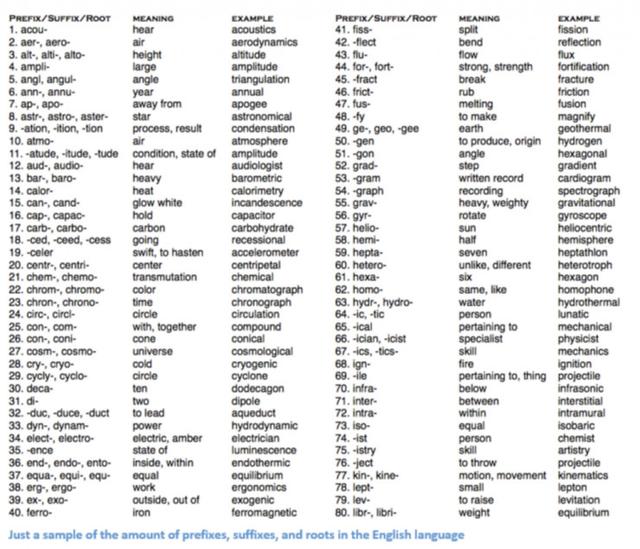
Geleneksel NLP yöntemi birçok dilbilim alanı bilgisini içerir, "fonem" ve "morfem" gibi terimleri anlamanızı gerektirir, çünkü dilbilimde birçok sınıflandırma vardır, fonem ve morfem bunlardan ikisi. Geleneksel NLP yöntemlerinin aşağıdaki kelimeleri nasıl anlamaya çalıştığını görelim.
Bir kelime hakkında (ifade ettiği duygu, tanımı vb.) Bazı bilgileri elde etmek istediğimizi varsayalım, kelimeyi 3 kısma ayırıyoruz. Yani önek, son ek, kök.

Örneğin, "un" önekinin zıt veya olumsuzluk anlamına geldiğini biliyoruz ve ayrıca "ed" kelimesinin bir kelimenin zamanını (geçmiş zaman) belirleyebileceğini de biliyoruz. Tüm kelimenin anlamını ve ifade edilen duyguyu "ilgi" kökünden kolayca çıkarabiliriz, çok basit mi? Bununla birlikte, tüm farklı önekleri ve son ekleri dikkate alırken, tüm olası kombinasyonların anlamını anlamak için çok yetenekli bir dilbilimci gereklidir.
Derin öğrenme esasen öğrenmek demektir. Büyük veri kümeleri üzerinde eğitim yoluyla kelime temsilleri oluşturmak için bazı yöntemler kullanacağız.
Kelime vektör

Her kelimeyi temsil etmek için d boyutlu bir vektör kullandığımızı varsayalım, d = 6 olduğunu varsayalım. Cümledeki her bir benzersiz kelime için bir kelime vektörü oluşturmak istiyoruz.

Şimdi değerleri nasıl atayacağımızı düşünelim Bu kelimeyi ve bağlamını, anlamını ve anlambilimini bir şekilde ifade edebilmeyi umuyoruz. Bunun bir yolu, bir birlikte oluşum matrisi oluşturmaktır.
Birlikte oluş matrisi, kelimenin tüm topluluklarda (veya eğitim setinde) ve diğer tüm kelime kombinasyonlarında kaç kez göründüğünü içeren bir matristir. Birlikte oluşum matrisinin neye benzediğine bir göz atalım.


Yukarıdaki basit birlikte oluşma matrisi örneğiyle, çok sayıda çok yararlı bilgi elde edebiliriz. Örneğin, "love" ve "like" sözcük vektörlerinin her ikisinin de aldıkları isimlerin (NLP ve köpekler) sayıları olan 1 sayısı içerdiğini fark ettik. "I" sayısı da 1 sayısı içerir, dolayısıyla bu kelimenin belirli bir fiil olması gerektiğini belirtir. Çok sayıda cümleden oluşan büyük veri kümeleri ile uğraşırken, bu benzerliğin daha net hale geleceğini hayal edebilirsiniz. Örneğin, "beğenmek", "aşk" ve diğer eşanlamlılar, benzer bağlamlarda oldukları için benzer kelime vektörlerine sahip olacaktır.
Şu anda, iyi bir başlangıç yapmış olsak da, her bir kelimenin boyutunun, külliyat arttıkça doğrusal olarak artacağını da unutmamalıyız. 1 milyon kelimemiz varsa (NLP standardında pek fazla değil), 1 milyon * 1 milyonluk bir matrisimiz olacak ve bu çok seyrek (çok sayıda 0 element). Bu açık bir şekilde depolama verimliliği açısından en iyi çözüm değildir. Bu kelime vektörlerini temsil etmenin en iyi yolunu bulmada birçok gelişme var. En ünlülerinden biri Word2Vec'dir.
Resmi yönerge
Vektör uzayı modelleri (VSM'ler), semantik olarak benzer kelimelerin yakındaki noktalara (birbirine yakın gömülü) eşlendiği sürekli bir vektör uzayındaki kelimeleri temsil eder (gömer). VSM'lerin NLP'nin geliştirilmesinde uzun bir geçmişi vardır, ancak hepsi aynı bağlamda görünen kelimelerin benzer anlamlara sahip olduğunu belirten dağıtılmış varsayıma dayanır. Bu prensibi kullanan yöntemler iki kategoriye ayrılabilir:
1. Saymaya dayalı yöntemler (örneğin: gizli anlambilim analizi);
2. Tahmin yöntemleri (örneğin: sinirsel olasılıklı dil modeli)
Aralarındaki fark--
Sayma yöntemi, bir kelimenin sıklığı ve büyük metin külliyatındaki bitişik kelimelerin istatistiksel verilerini hesaplamak için kullanılır ve daha sonra bu istatistiksel verilerin her bir kelimesi küçük ve yoğun bir vektöre eşlenir.
Tahmin modeli, öğrenilen küçük yoğun gömme vektörlerine dayanarak (modelin parametreleri dikkate alınarak) doğrudan komşularından kelimeleri tahmin etmeye çalışır.
Word2vec, orijinal metinden kelime düğünlerini öğrenmek için özellikle etkili bir hesaplamalı tahmin modelidir. Sürekli kelime çantası modeli (CBOW) ve Skip-Gram modeli olmak üzere iki biçime sahiptir. Algoritmik olarak bu modeller, CBOW'un kaynak bağlam sözcüğünden hedef sözcüğü öngörmesi dışında, skip-Gram'ın tersini yapması ve sözcüğü hedef sözcüğün kaynak bağlamından öngörmesi dışında benzerdir.
Aşağıdaki tartışmada, atlama modeline odaklanacağız.
Matematik kullanımı
Geleneksel olarak, nöral olasılıklı dil modelleri, bir softmax fonksiyonu biçiminde önceki h ("tarih") kelimesi verilen bir sonraki kelime wt ("hedef") olasılığını maksimize etmek için maksimum olasılık prensibi kullanılarak eğitilir.
Hedef kelime wt ve bağlam h'nin uyumluluğunu hesaplamak için skoru (wt, h) kullanın (genellikle iç çarpım işlemi kullanılarak).
Bu modeli eğitim setinde log olma olasılığını en üst düzeye çıkararak eğitiyoruz. Bu nedenle, aşağıdaki kayıp fonksiyonunu maksimize ediyoruz.
Bu, dil modellemesi için uygun bir standartlaştırılmış olasılık modeli sağlar.
Aynı argüman, bu hedefi maksimize etmek için değiştirilen değişkenleri (veya parametreleri) açıkça gösteren biraz farklı bir formülle de ifade edilebilir.
Amacımız, mevcut kelimenin etrafındaki kelime dağarcığını tahmin etmek için kullanılabilecek bazı kelime temsillerini bulmaktır. Özellikle, tüm külliyatımızın ortalama günlük olasılığını maksimize etmek istiyoruz:
Özünde, bu denklemin mevcut wt kelimesinin c boyutundaki bir pencerede belirli bir kelimeyi gözlemleme olasılığı p vardır. Bu olasılık, mevcut wt kelimesine ve parametresinin bazı ayarlarına bağlıdır (modelimiz tarafından belirlenir). Tüm külliyatta bu olasılığı en üst düzeye çıkarmak için bu parametreleri ayarlamayı umuyoruz.
Temel parametrelendirme: Softmax modeli
Temel atlama-gram modeli, daha önce gördüğümüz gibi softmax fonksiyonunu geçme olasılığını p tanımlar. Wi'yi N ve boyutlarına sahip tek sıcak bir kodlama vektörü olarak düşünürsek ve bu bir N × K matrisi gömme matrisiyse, bu da sözlüğümüzde N kelime olduğu ve öğrendiğimiz yerleştirmenin K boyutuna sahip olduğu anlamına gelir, o zaman Tanımlayabiliriz ...
Matris teta'nın öğrendikten sonra bir gömme arama matrisi olarak düşünülebileceğini belirtmek gerekir.
Mimari açıdan, basit bir üç katmanlı sinir ağıdır.

Üç katmanlı bir ağ yapısı oluşturun (bir giriş katmanı, bir gizli katman ve bir çıktı katmanı)
Bir kelimeyi iletin ve yakındaki kelimeleri eğitmesine izin verin
Çıktı katmanını kaldırın, ancak girişi ve gizli katmanları koruyun
Ardından, kelime haznesinden bir kelime girin. Gizli katman tarafından verilen çıktı, giriş kelimesinin `` kelime gömme '' dir.
Bu parametreleştirmenin büyük bir dezavantajı vardır ve bu da büyük külliyatta yararlılığını sınırlar. Spesifik olarak, modelimizin tek bir ileri geçişini hesaplamak için, softmax işlevini değerlendirmek için tüm korpus kelime dağarcığını özetlememiz gerektiğini fark ettik. Bu, büyük veri kümeleri için çok abartılıdır, bu nedenle hesaplama verimliliği için bu modelin alternatif yaklaşımlarını dikkate alıyoruz.
Hesaplama verimliliğini artırın
Word2vec'de özellik öğrenimi için tam bir olasılık modeline ihtiyacımız yok. CBOW ve skip-gram modelleri, gerçek hedef kelimeleri (wt) aynı bağlamda k sanal (girişim) kelimeden w ayırt etmek için ikili sınıflandırma hedefleri (lojistik regresyon) kullanılarak eğitilir.
Matematiksel olarak işlem, her nesneyi maksimize etmektir.
Model gerçek kelimelere yüksek olasılık ve gürültülü kelimelere düşük olasılık atadığında, bu hedef maksimize edilir. Teknik olarak buna negatif örnekleme denir ve önerdiği güncelleme, limit içindeki softmax fonksiyonunun güncellemesine yaklaşır. Ancak hesaplama açısından, özellikle çekici, çünkü hesaplama kaybı işlevi artık sadece kelime dağarcığındaki (V) tüm kelimeler yerine seçtiğimiz gürültülü kelimelerin sayısına (k) dayanabilir, bu da onu daha hızlı eğitir. Tensorflow gibi yazılım paketleri, gürültü kontrastı tahmini (NCE) kaybı adı verilen çok benzer bir kayıp işlevi kullanır.
Skip-gram modelinin sezgisel deneyimi
Örnek olarak, veri setini dikkate almalıyız.
hızlı kahverengi tilki tembel köpeğin üzerinden atladı
Önce bir veri kümesi ve bunların göründükleri bağlam oluştururuz. Şimdi vanilya tanımına bağlı kalalım ve kelime penceresini "bağlam" içindeki hedef kelimenin sol ve sağ tarafları olarak tanımlayalım. 1'lik bir pencere boyutunu kullanarak, (bağlam, hedef) çiftlerinden oluşan bir veri kümesine sahibiz.
(, hızlı), (, kahverengi), (, tilki), ...
Skip-gram'ın bağlamı ve hedefi tersine çevirdiğini ve hedef kelimeden her bağlam kelimesini tahmin etmeye çalıştığını hatırlayın, böylece görev "hızlı", "hızlı" ve "tilki" den "ve" kahverengi "yi tahmin edecektir.
Bu nedenle, veri entegrasyonumuz aşağıda gösterildiği gibi (giriş, çıkış):
(hızlı, hızlı), (hızlı, kahverengi), (kahverengi, hızlı), (kahverengi, tilki), ...
Amaç işlevi tüm veri setinde tanımlanır, ancak genellikle her bir örneği (veya batch_size örneğinin "minibatch" ini) optimize etmek için Stokastik Gradyan Azalışı (SGD) kullanırız, bu genellikle 16
Eğitim adımında, amacın hızlı bir şekilde tahmin etmek olduğu yukarıdaki ilk eğitim vakasını gözlemlediğimizi hayal edelim. Bazı gürültü dağılımından (genellikle tek karakterli bir dağılım) num_noise seçiyoruz.Gürültü (karşılaştırma) örneklerinin sayısı seçilir (bu birim, her bir kelimenin görünümünün diğer tüm kelimelerin görünümünden bağımsız olduğunu varsayar, bu da üretim sürecini alabileceğimiz anlamına gelir. Bunu bir zar dizisi yuvarlama dizisi P (w) olarak düşünün.
Basitlik uğruna, num_noise = 1 olduğunu varsayıyoruz ve bir müdahale örneği olarak koyunları seçiyoruz. Daha sonra, gözlemlenen ve gürültülü örnekler için kaybı hesaplıyoruz, yani, "t" zaman adımındaki hedef -
Amacımız, objektif işlevi maksimize etmek için gömme parametresini güncellemektir. Bunu, gömme parametresine göre kayıp gradyanını türeterek yapıyoruz.

Ardından, gradyan yönünde hareket ederek gömme parametrelerini güncelliyoruz. Bu süreç tüm eğitim seti boyunca tekrarlandığında, model gerçek kelimeler ile gürültülü kelimeleri başarılı bir şekilde ayırt edene kadar her kelime için gömme vektörünü "hareket ettirme" etkisine sahip olacaktır.
Öğrenme vektörünü 3 boyuta projelendirerek görselleştirebiliriz. Bu görsel değişkenleri gözlemlediğimizde, bu vektörlerin kelimeler ve aralarındaki ilişki hakkında bazı anlamsal bilgileri yakaladığı açıktır ki bu pratik uygulamalarda çok yararlıdır.
Referans
Word2Vec'in Tensorflow uygulaması
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado ve Jeffrey Dean tarafından yazılan Kelimeler ve İfadelerin Dağıtık Temsili ve Kombinasyonu-Araştırma makalesi
Aneesh Joshi'nin word2vec için pratik kılavuzu
Adit Deshpande Natural Language için yorumlar
Rohan Verma'nın dil modeli
Leifeng.com altyazı grubu tarafından derlenmiştir.