Yao Cong, CSG Algoritması Başkanı, Megvii Teknolojisi: Derin Öğrenme Çağında Metin Algılama ve Tanıma Teknolojisi AI Araştırma Enstitüsü 103 Konferans Salonu
Lei Feng Net AI Araştırma Enstitüsü Basın: Derin öğrenmenin yükselişi ve gelişmesiyle birlikte, bilgisayar görüşü alanı muazzam değişikliklere uğradı. Bilgisayarla görmede önemli bir araştırma konusu olan sahne metin tespiti ve tanıma, kaçınılmaz olarak bu dalga tarafından süpürülüyor ve birlikte derin öğrenme çağına giriliyor. Son yıllarda, bu konudaki araştırmacıların hepsi düşünce, yöntem ve performansta muazzam değişikliklere tanık oldu.Bu açık sınıfın konukları sizinle ilgili içeriği paylaşacak.
Konuk paylaşma:
Yao Cong, lisans ve doktora derecelerini Huazhong Bilim ve Teknoloji Üniversitesi Telekomünikasyon Fakültesi'nden almıştır.Ana araştırma yönü doğal sahnelerde metin algılama ve tanımadır. IEEE TPAMI, IEEE TIP ve en iyi konferanslar CVPR, ICCV ve ECCV gibi önemli uluslararası dergilerde ondan fazla makale yayınladı. Şu anda, Megvii Teknolojisinde (Face ++) bulut hizmeti iş algoritması başkanıdır, doğal sahne OCR, yüz yaşam algılama ve diğer teknolojilerin araştırma ve geliştirmesine başkanlık etmekte ve FaceID İnternet kimlik doğrulama hizmetleri ve Face ++ açık platformu için algoritma desteği sağlamaktadır.
Herkese açık sınıfın tekrar adresi:
Konuyu paylaş: Derin öğrenme çağında metin algılama ve tanıma teknolojisi
Ana hatları paylaşın:
-
Arka plan ve genel bakış
-
Sahne metni algılama ve tanımada son gelişmeler
-
Gelecek trendler ve potansiyel yönler
-
sıradan uygulama
Lei Feng Network AI Araştırma Enstitüsü Paylaşılan içeriği aşağıdaki gibi düzenleyin:
Arka plan ve genel bakış
Görsel tanımada metin neden bu kadar önemlidir? Bunun iki nedeni vardır: taşıyıcı olarak metin ve ipucu olarak metin.
Taşıyıcı olarak metin

Her şeyden önce, metin doğal bir oluşum değil, bir insan yaratımıdır. Doğal olarak zengin ve doğru üst düzey anlamsal bilgi içerir, insan düşüncelerini ve duygularını iletir.Sıradan görüntü veya video bilgisini doğrudan tarif etmek zordur, ancak metin kullanılabilir. To. Örneğin, iki bin yıl önceki tarihi bir olayla ilgili kişiyi, zamanı ve yeri anlayabileceğiniz "Tarihsel Kayıtlar".
İpucu olarak metin

İkincisi, metin görsel tanıma için önemli bir ipucudur. Yukarıda gösterildiği gibi, bu, bina ve bitkilerin bulunduğu bir sokak görünümü resmidir. Resmin konumu hakkında başka sorular sorarsanız, yukarıdaki bilgilerden bilemezsiniz. Ortadaki gri maskeyi kaldırırsanız, bunun " Zhongguancun Plaza Alışveriş Merkezi ". Metin bilgilerinin yardımıyla, görüntünün konumu doğru bir şekilde öğrenilebilir. Metin ve diğer görsel ipuçlarının (kenar, renk, doku vb.) Çok güçlü bir tamamlayıcı etkiye sahip olduğu görülebilir.Metin algılama ve tanıma sayesinde daha zengin ve daha doğru bilgiler elde edilebilir.
Tanım
Öyleyse, araştırma perspektifinden, metin algılama ve tanıma sorunu nasıl tanımlanır?

Basitçe ifade etmek gerekirse, metin algılama, algoritma hesaplaması yoluyla doğal sahnede kelime veya metin satırı düzeyinde metin örnekleri (varsa konumu işaretleyin) olup olmadığına karar verme sürecini ifade eder.

Metin tanıma bir adım daha ileri gider: Metin algılamaya dayalı olarak bir bilgisayar tarafından okunabilen ve düzenlenebilen metin alanlarını sembollere dönüştürme işlemidir.
Mücadele
Şu anda, metin algılama ve tanıma birçok zorlukla karşı karşıyadır. Her şeyden önce, geleneksel OCR'den (Optik Karakter Tanıma) farklıdır, çünkü aşağıda gösterildiği gibi, doğal sahnedeki metin çok değişir, sol tipik bir taranmış belge görüntüsü ve sağ, doğal sahnede toplanan çok sayıda görüntüdür. görüntü.

Karşılaştırma yoluyla, soldaki arka planın çok temiz olduğu ve sağdaki arka planın çok dağınık olduğu; soldaki yazı tipinin alışılmadık ve sağın sürekli değiştiği; soldaki düzen nispeten düz ve birleşik, sağdaki düzen ise standartlardan yoksun, çeşitli ve karmaşık; soldaki renkler monoton ve sağdaki renkler çeşitli. .
Genel olarak, metin algılama ve tanımada üç büyük zorluk vardır:
1) Sahne metninin çeşitliliği. Metin rengi, boyutu, yönü, dili, yazı tipi vb.

2) Görüntü arka planının paraziti. Günlük hayatın her yerinde görülebilen sinyal ışıkları, göstergeler, çitler, çatılar, pencereler, tuğlalar, çiçekler ve çimenlerin metinle belli bir benzerliği vardır, bu da metin algılama ve tanıma sürecine büyük müdahale getirir.

3) Üçüncü zorluk, görüntünün kendisinin görüntüleme sürecinden gelir. Örneğin, metin görüntüleri içeren fotoğraflarda gürültü, bulanıklık, tekdüze olmayan aydınlatma (güçlü yansımalar, gölgeler), düşük çözünürlük ve kısmi kapanma gibi sorunlar vardır.Bu aynı zamanda algoritma tespiti ve tanıması için çok büyük bir zorluktur.

Sahne metni algılama ve tanımada son gelişmeler
Araştırmacıların yukarıda bahsedilen problemleri çeşitli açılardan çözmeye çalışmasının nedeni, yukarıda bahsedilen çoklu zorluklardır. Bu tartışmanın konusu, derin öğrenme çağında metin algılama ve tanıma alanındaki son gelişmelerdir. Bu gelişmeler 5 kategoriye ayrılmıştır:
Anlamsal bölümleme ve nesne algılama yöntemlerinden ilham alın
Basitleştirilmiş boru hattı
Keyfi metin işleniyor
Dikkat Kullanın
Sentetik verileri kullanın.
İlk kategori: anlamsal bölümleme ve hedef tespit yöntemlerinden ilham alın
Anlamsal bölümleme ve hedef algılama yöntemlerinden elde edilen doğal sahne metin algılama ve tanıma teknolojisinin temsili çalışması temel olarak:
Bütünsel Çok Kanallı Tahmin
Metin kutuları
Rotasyon Önerileri
Köşe Lokalizasyonu ve Bölge Segmentasyonu.
Geleneksel yöntemlerle karşılaştırıldığında, derin öğrenme yöntemleri genel nesne anlamsal bölümlemeden ve hedef tespit algoritmalarından ilham alacaktır. Örneğin, Ke Megvii Technology'nin 2015 yılında Holistic Multi-Channel Prediction adlı bir çalışması vardı.

Geleneksel metin algılama yönteminden farklı olarak, Bütünsel Çok Kanallı Tahmin, metin algılama problemini anlamsal bir bölümleme problemine dönüştürür.Metin alanı, tüm görüntünün anlamsal bölümlendirilmesi ile elde edilir.Yukarıda gösterildiği gibi, sol orijinal görüntü ve sağ tahmin edilen maskedir. Film görüntüsünde metin alanı vurgulanır ve arka plan alanı bastırılır.
Bütünsel Çok Kanallı Tahmin girdisi yerel bir alan değil, görüntünün tamamıdır; ayrıca konsept ve işlev açısından bu yöntem, kayan pencere veya bağlı bileşen yönteminden farklıdır.

Spesifik olarak, Bütünsel Çok Kanallı Tahmin, görüntü alanı, karakter konumu ve bitişik karakterler arasındaki bağlantı yönü dahil olmak üzere üç global piksel seviyesi tahmini çıktılar. Bu üç tür bilgi aracılığıyla, kırmızı dikdörtgende gösterildiği gibi en sağdaki sonuç resmini çıkarın. Bu yöntemin avantajı, yatay, çok yönlü ve eğri metni aynı anda işleyebilmesidir.

Diğer bir yöntem de tek adımlı evrensel nesne algılayıcı SSD'den esinlenen TextBoxes'tır.Özü, metni özel bir hedef olarak alıp SSD üzerinden modellemektir. Buradaki temel model VGG-16'dır. Evrişimli katman, hedef metnin var olup olmadığı, uzunluk, genişlik, boyut ve yön gibi bilgileri verirken yüksek doğruluk ve verimlilik sağlar.
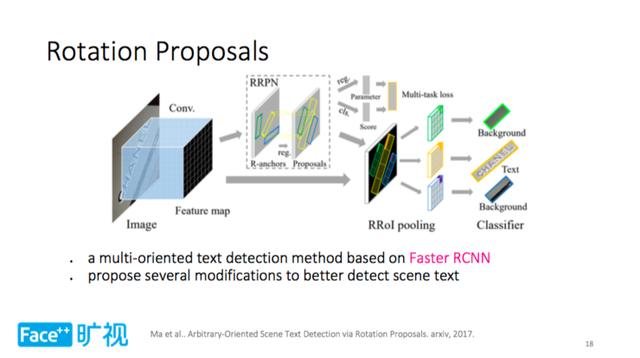
Daha hızlı R-CNN gibi hedef algılama alanında iki aşamalı dedektörler de vardır. Üçüncü metin algılama yöntemi Rotation Proposals olarak adlandırılır. İki adımlı algılama kategorisine aittir. Esas olarak Daha Hızlı R-CNN'den yararlanır. Çerçeve tutarlı kaldığında, sahne metnini daha iyi algılamak için değiştirilir. Bu, Metin genel amaçtan farklı olduğu için, örneğin, büyük bir en boy oranı değişikliği ve dönüş yönü vardır.

Döndürme Önerileri temel olarak iki şey yapar: Birincisi çapa noktasını genişletmek, yönü artırmak ve en boy oranını değiştirmektir; ikincisi, çeşitli döndürme durumlarını işleyen ve sonraki işlemleri kolaylaştırmak için düzenli özellik haritalarını ayıran RRoI havuz katmanıdır.

Megvii Technology CVPR 2018, "Köşe Lokalizasyonu ve Bölge Segmentasyonu ile Çok Yönlü Sahne Metin Algılama" başlıklı makaleyi içeriyordu - bir bileşik metin algılama yöntemi önerdi - Köşe Yerelleştirme ve Bölge Bölümleme (köşe algılama ve bölge bölümleme), en önemli özelliği Hedef bölümlemenin kapsamlı kullanımı ve anlamsal bölümleme iki yöntem.
Bu yöntem neden öneriliyor? Bunun nedeni, gerçek sahne metni örneklerinin bazen birbirine yakın olması veya hatta birbirine yapışması ve bölümleme ve algılamanın işe yaramaz hale gelmesidir. Şu anda, işleme için iki dal kullanılır, bir dal metin alanının köşesini bulur ve diğer dal, bu iki tür bilgi metnini metin konumu ve güvenilirlik çıktıları için birleştirerek metin alanı bölümleme gerçekleştirir.
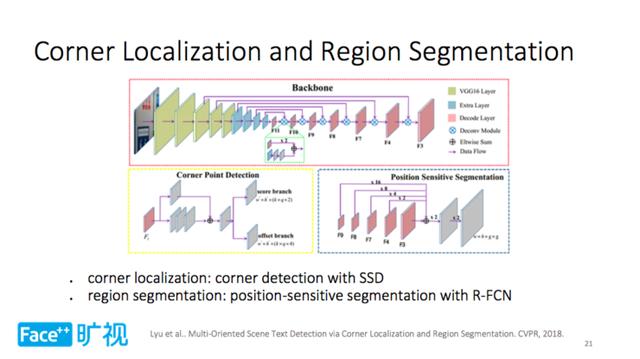
Yukarıda gösterildiği gibi, Köşe Lokalizasyonu ve Bölge Segmentasyonunun temel modeli VGG-16'dır, özellikleri çıkarmak için üzerine çok sayıda evrişimli katman eklenir ve ardından iki dal vardır:
Köşe algılama dalı, SSD aracılığıyla köşeyi bulur, ağ üzerinden köşeyi çıkarır ve son olarak köşenin konumunu elde eder;
Metin bölgesi bölümleme dalı, daha doğru metin algılama sonuçları elde etmek için farklı göreceli konumlara sahip bölümleme haritaları oluşturmak için R-FCN tabanlı konuma duyarlı bölümleme kullanır.
İkinci kategori: daha basitleştirilmiş bir boru hattı
Derin öğrenme çağında, neredeyse tüm metin algılama ve tanıma yöntemleri basitleştirilmiş ve daha verimli Ardışık Düzenleri kullanacaktır. Bu, paylaşmanın ikinci yöntemidir ve temsili çalışması DOĞU'dur.

Megvii Technology, CVPR 2017'de yer alan "DOĞU: Etkili ve Doğru Sahne Metin Dedektörü" belgesinde oldukça basitleştirilmiş bir boru hattı yapısı ortaya koymuştur. Yukarıdaki şekilde gösterildiği gibi, en soldaki girdi görüntüsü, en sağdaki algoritmanın çıktı sonucudur ve ortadaki ise işleme adımıdır. DOĞU (alt), Boru Hattını iki orta adıma yoğunlaştırır, bunlardan biri çok kanallı FCN aracılığıyla geometrik bilgi tahminidir Ön plan ve arka plan tahmininin yanı sıra diğer adım NMS'dir ve son olarak çok yönlü metin algılama sonuçları elde edilir.

Peki DOĞU nasıl gerçekleştirilecek? Çok basit: Konum, ölçek ve yön gibi metnin ana bilgilerini açıklamak ve modellemek için tek bir ağ kullanın ve aynı anda birden fazla kayıp işlevi ekleyin, bu çok görevli eğitimdir. Yukarıda gösterildiği gibi, geometrik bilginin tahmini yardımı ile metin algılama sonucu elde edilebilir.
Bu yöntemin faydaları esas olarak iki yönden yansıtılmaktadır:
Doğruluk açısından, uçtan uca eğitim ve optimizasyona izin verir
Verimlilik açısından ara yedekli işleme adımları ortadan kaldırılır.

Yukarıdaki şekil, birden fazla yöntemin uygulanmasının bir karşılaştırmasıdır. Yatay eksen hızdır, dikey eksen doğruluktur ve kırmızı noktalar, DOĞU'nun iki çeşididir. Doğruluk ve hız, doğruluk ve hız açısından geleneksel yönteme göre üstün olduğu görülebilir. Kalite denetimi mükemmel bir denge sağlamıştır. EAST, endüstri standardı bir yöntem haline geldi ve kod açık kaynak. İlginç bir şekilde, bu hevesli netizen @argman (kodun bir parçası olan Megvii tarafından yapıldı) ve ilgilenen çocuklar deneyebilir; sadece kullanmak istiyorsan ve kaynak kodunu görmek istemiyorsan, şu anda EAST ayrıca OpenCV'nin en son sürümüne entegre edilmiş resmi bir modüldür.
Üçüncü kategori: keyfi metin biçimlerinin işlenmesi
Gerçek dünya metni ile başa çıkmak hâlâ bir zorlukla karşı karşıyadır: metin biçiminin değişkenliği. Metin algılama ve tanıma algoritmalarıyla nasıl başa çıkılır? Megvii Teknolojisi bunun için iki temsili çözüm sunar:
TextSnake
TextSpotter'ı Maske.

Megvii Technology tarafından ECCV 2018'e dahil edilen "TextSnake: Textf Abies Algılama için Esnek Bir Temsil" adlı kağıt, TextSnake adlı yeni ve esnek bir sunum önermektedir.
Yukarıda gösterildiği gibi, eğri metin alanı için, Şekil a, çok sayıda gereksiz arka plan içeriği içeren geleneksel bir koordinat hizalı dikdörtgen kullanır; Şekil b dikdörtgen kutuyu döndürür, arka plan içeriği azaltılır ve uyarlanabilirlik daha güçlü hale gelir; Şekil c Çevrelemek için düzensiz dörtgenler kullanıldığında, etki yine de ideal değildir. Dörtgenin eğri metin alanını tam olarak kapatamadığı sonucuna varılabilir.
Bu durumu daha doğru bir şekilde ele almak için, Şekil d, ölçek, yön, deformasyon vb. Dahil olmak üzere metindeki değişikliklere daha iyi uyum sağlamak için metin alanını bir dizi diskle kaplayan TextSnake yöntemini kullanır.

TextSnake ilkesinin şematik diyagramı yukarıdaki gibidir.Sarı alan düzensiz eğimli metin alanını temsil eder, yeşil çizgi metin alanının merkez çizgisini temsil eder, kırmızı nokta metin alanını kaplayan diskin merkez noktasını temsil eder, c ile temsil edilir, diskin yarıçapı r ile gösterilir ve yön bilgisi ile temsil edilir. anlamına gelir. Bu nedenle, metin örneği, simetri ekseninde ortalanmış bir dizi düzenli olarak üst üste binen disk olarak modellenebilir. Metnin ölçeği ve yönü değişken olduğu için, diskin de metne göre değişen değişken bir yarıçapı ve yönü vardır. Bu esnek gösterim, çok yönlü ve eğimli metin gibi çeşitli metin biçimlerine tam olarak uyarlanabilir.

TextSnake ile, metin algılamayı tamamlamak için bir hesaplama modeli nasıl tasarlanır? Aslında çok basittir yani geometrik öznitelik tanımı tamamlanır, birden fazla kanalın tahmin sonuçları FCN üzerinden çıkarılır ve entegrasyon gerçekleştirilir, ön plan ve arka plan ayrılır, merkez çizgisi bulunur ve metin alanı yarıçapına ve yönüne göre geri yüklenebilir.

Megvii Technology ECCV 2018, "Mask TextSpotter: Rasgele Şekillerle Metin Bulmak için Uçtan Uca Eğitilebilir Bir Sinir Ağı" başlıklı makaleyi içeriyordu, Mask R-CNN'den esinlenerek yeni bir model Mask TextSpotter'ı öneren başka bir çalışmayı tamamladı, Uçtan uca yolla, metin algılama ve tanıma aynı anda gerçekleştirilir. Mask TextSpotter'ın genel çerçevesi Mask R-CNN'ye dayanır ve değiştirilir ve metin de özel bir hedef olarak kabul edilir.

Belirli ayrıntılar yukarıda gösterilmiştir, sol, giriş görüntüsü ve sağ, çıktı sonucudur. RPN, metin aday bölgeleri oluşturmak için kullanılır; Hızlı R-CNN, aday bölgeleri puanlar ve koordinatlarına geri döner; Ayrıca, piksel seviyesinde segmentasyon ve karakterlerin tanınmasını da gerçekleştiren bir maske dalı vardır.
Bu, RNN sekans modellemesine veya CTC kaybının yardımıyla hesaplamaya dayanan geleneksel tanıma modülünden farklıdır, Mask TextSpotter doğrudan piksel düzeyinde segmentasyon gerçekleştirir, her pikseli sınıflandırır ve nihayet tanımayı tamamlamak için tüm sonuçları birleştirir.
Dördüncü kategori: Dikkatten öğrenin
NLP alanında ortaya çıkan Dikkat modelinin önemli etkisi nedeniyle, metin algılama ve tanıma alanına da girmiş ve bazı yeni fikirlere ilham vermiştir. Temsilci sonuçlar şunları içerir:
CRNN
YILDIZ ÇİÇEĞİ
FAN.

Dikkatten bahsetmeden önce, ilk olarak Megvii Teknolojisi TPAMI 2017'nin CRNN adlı bir çalışmasından bahsetmeme izin verin.Alt katman, özellikleri çıkarmak için CNN'yi, orta katman sıra modelleme için RNN'yi ve hedefi optimize etmek için CTC kaybını kullanıyor. Uçtan uca eğitilebilir bir metin tanıma yapısıdır, ancak Dikkat kullanmaz. Şu anda CRNN, bu alanda standart bir yöntem haline geldi ve GitHub'da açık kaynak kodlu.

Ardından Megvii Technology, TPAMI 2018'de ASTER adlı bir çözüm önerdi. Karakterlerin eğilme ve bükülme gibi sorunları olduğu için, tanıma aşamasında algılama mutlaka en ideal olanı değil, şu anda iki adımda tanınması gerekiyor. İlk adım, bir girdi görüntüsü vermek ve içindeki karakterleri tanımaya elverişli bir duruma düzeltmektir; ikinci adım tanımaktır. Burada vurgulanması gereken, düzeltme sürecinin ağ tarafından otomatik olarak öğrenilmesi ve ek açıklama olmamasıdır.

Daha sonra, yukarıda gösterildiği gibi, ASTER temelde iki modüle sahiptir: düzeltme ve tanıma. Düzeltme modülü, kontrol noktalarının tahminini daha doğru hale getirmek için STN temelinde optimize edilmiştir; tanıma modülü, sıralamayı tahmin edebilen Dikkatli klasik bir CNN + RNN yapısıdır.

Tabii ki, Dikkatin kendisinde de bazı sorunlar var, örneğin, ICCV 2017'de yer alan "Odaklanma Dikkat: Doğal Görüntülerde Doğru Metin Tanıma Doğru" başlıklı makale FAN'ın çalışmasını önerdi.
Bazı durumlarda, Dikkat tahmini doğru olmayabilir Şekil a'da Dikkat, "K" üzerindeki son iki noktayı bulur ve bu da Dikkat noktalarının üst üste binmesine neden olur ve bu da yanlış konumlandırma ve kaymaya yol açar. FAN yöntemi, Dikkat noktasının konumunu sınırlar ve onu hedef metnin merkezi olarak kilitler, böylece üst üste binme ve sürüklenmeyi önler, Dikkat alanı daha düzenli hale gelir ve son tanıma etkisi de iyileştirilir.
Beşinci kategori: sentetik verilerin kullanılması
Derin öğrenme çağında, verilere olan talep büyük ölçüde artmıştır ve büyük miktarda veri, mükemmel modelleri eğitmek için elverişlidir. Bu nedenle, derin öğrenme çağındaki metin algılama ve tanıma yöntemlerinin neredeyse tamamı sentetik verileri kullanır ve temsili veri seti SynthText'tir.

SynthText, metin algılama ve tanıma alanında yaygın olarak kullanılan sentezle oluşturulan klasik bir sahne metin veri setidir. Ana fikir, önce gerçek sahnelerin binlerce görüntüsünü toplamak ve ardından yukarıdaki şekilde gösterildiği gibi karakterleri yapıştırmaktır.

Spesifik olarak, bazı doğal sahne görüntüleri verildiğinde, SynthText, derinliği tahmin etmek, bağlı bölgeleri altta yatan algoritmalarla bölümlere ayırmak ve metni yerleştirmek için bazı pürüzsüz bölgeleri bulmak gibi geometrik bilgileri ve bölge bölümlemesinin sonuçlarını tahmin etmek için temel algoritmaları kullanır ve sonunda metin içeren metin oluşturur. Görüntü veri kümesi.
Gelecek trendler ve potansiyel yönler
Megvii Teknolojisi, doğal sahne metin algılama ve tanıma teknolojisinin gelişme durumuna göre, derin öğrenme çağının bağlamıyla birlikte gelecekteki eğilimlerini ve potansiyel araştırma yönlerini analiz ederek, bu teknolojinin gelecekteki zorluklarını dört boyutta özetliyor:
Çok dilli metin algılama ve tanıma
Herhangi bir metin biçimini okuyun
Metin ve görüntü sentezi
Model sağlamlığı.
Çok dilli metin algılama ve tanıma

Nispeten düzgün metin alanları için, mevcut metin algılama teknolojisi büyük bir sorun değildir, ancak metin tanımayı içerdiğinde, birçok engel getiren iki yüzden fazla dil, farklı yazma yöntemleri ve son derece farklı yapılar ve diziler vardır. Her metin türü için bir model eğitmenin mantıksız olduğu açıktır. Bu nedenle, farklı metin türlerini işlemek için genel bir yöntem bulmak mümkün müdür? Önümüzdeki zorluklardan biri budur.
Her türlü metni okuyun

Mevcut karakter biçimleri çok çeşitlidir.Farklı renkler, yazı tipleri ve kombinasyonların neden olduğu farklı zorluk dereceleriyle karşı karşıya kaldığında, metin algılama ve tanıma teknolojisinin mevcut performansı pek tatmin edici değildir. Öyleyse, herhangi bir metin biçimini kullanabilen evrensel bir model var mı? Bu, gelecek için ikinci zorluktur.
Metin ve görüntü kombinasyonu yapmak

Sentetik sahne metin veri seti model eğitimi için çok elverişli olsa da, teknoloji henüz olgunlaşmadığından, üretilen görüntüler yeterince gerçek değildir ve görüntü çeşitliliği eksiktir, bu da sonuçta düşük veri seti kalitesi ve sınırlı eğitim gelişimi ile sonuçlanır. Öyleyse, daha gerçekçi ve zengin metin görsellerini nasıl sentezleyebiliriz? Bu, gelecek için üçüncü zorluktur.
Model sağlamlığı

Model sağlamlığı temel bir sorundur ve sorunu çözmenin anahtarıdır. Megvii Technology, geçmişte giriş görüntüsünün sınırında piksel pertürbasyonu gerçekleştirdi ve çıktının büyük bir sapmaya sahip olduğunu buldu, bu tamamen yanlış. Bu aynı zamanda mevcut tanıma modellerinin küçük bozulmalara (küçük ofsetler, rotasyonlar ve deformasyonlar gibi) çok duyarlı olduğu anlamına gelir. Peki modelin sağlamlığı nasıl artırılır? Bu, gelecek için dördüncü zorluktur.
sıradan uygulama
Derin öğrenmenin yardımıyla, metin algılama ve tanıma teknolojisi, ileriye dönük bir gelişme sağladı ve ilgili senaryolarda ve endüstrilerde yaygın olarak kullanıldı.Örneğin, Megvii'nin yapay zeka açık platformu Face ++, kart ve belge metin tanıma API çağrı hizmetleri sağlar ve kartlar ve belgeler sağlar. , TemplateOCR, belgeler için genel bir çerçeve çözümü.
Kart ve sertifika metni tanıma

Kartların ve sertifikaların metin tanıması her zaman sıcak bir endüstri talebi olmuştur.Megvii Technology'nin Face ++ resmi web sitesi, kullanıcıların aramaları için API'ler sağlar.Kullanıcıların yalnızca resim yüklemesi gerekir ve sistem gerçek zamanlı olarak sonuç üretir. Sistem şu anda kimlik kartı, ehliyet, ehliyet, banka kartı ve plaka numarası gibi metin tanımayı desteklemektedir.
TemplateOCR

Zamanın gelişmesiyle birlikte, sosyal işlevsel departmanlarda işbölümü rafine edildi ve prosedürler gittikçe daha karmaşık hale geliyor.Sertifika, kart, sözleşme ve belgelerin yapısı göz kamaştırıyor.Yüzlerce metin çerçevesinin tanıma görevleriyle nasıl baş edilir? Her bir metin çerçevesi için bir model eğitmek büyük insan gücü, malzeme kaynakları ve finansal kaynakları tüketecekse, açıkça maliyet etkin değildir.

TemplateOCR, Megvii tarafından verilen çözümdür. Bu, yapılandırılmış kartları, sertifikaları ve belgeleri tanımlamak için genel bir çerçevedir ve yalnızca üç adım gerektirir. İlk adım, şablon olarak net bir resim yüklemek ve ikinci adım, tanınması gereken metin alanını belirlemektir (referans alanını belirtmeye gerek yoktur) ve ardından tanımaya başlayabilirsiniz (API anında oluşturulur). Bu yöntem sadece farklı karelerdeki karakterler için model eğitimi zahmetinden kurtarmaz, aynı zamanda tanıma sürecini daha hızlı ve daha doğru hale getirir.
sonuç olarak
Şu anda, derin öğrenme çağında sahne metni algılama ve tanıma teknolojisinde hala büyük zorluklar var ve bunlar esas olarak aşağıdaki üç yönden yansıtılıyor:
Karakterlerin farklılıkları, dil, yazı tipi, yön, düzenleme vb. Gibi çeşitli biçimlerde mevcuttur;
Neredeyse ayırt edilemeyen öğeler (işaretler, çitler, duvar karoları, çimen vb.) Gibi arka planın karmaşıklığı;
Gürültü, bulanıklık, bozulma, düşük çözünürlük, düzensiz aydınlatma, kısmi tıkanma vb. Gibi girişim çeşitliliği.
Buna bağlı olarak, yukarıdaki zorluklara yanıt olarak, metin algılama ve tanıma üzerine özel araştırma aşağıdaki dört teknik eğilime sahiptir:
Daha güçlü modeller tasarlayın;
Çok yönlü ve eğimli metni tanıyın;
Çok dilli karakterleri tanımak;
Daha zengin ve gerçekçi veri kümeleri sentezleyin.
Yukarıdakiler, bu sayıda davetliler tarafından paylaşılan tüm içeriklerdir. Daha fazla genel sınıf videosu için lütfen izlemek için Leifeng.com'daki AI Araştırma Topluluğu'na ( gidin. WeChat genel hesabını takip edin: AI Araştırma Enstitüsü (okweiwu), en son genel sınıf canlı yayın süresi önizlemesini alabilirsiniz.