Teoriden pratiğe, CNN'i TensorFlow ile nasıl uygulayacağınızı öğretin
Lei Feng Net Not: Bu makalenin yazarı Song Chuanbiao, orijinal metin yazarda bulunmaktadır. kişisel blog Leifeng.com yetkilendirildi.
1. CNN'nin tanıtımı
Tamamen bağlı yapay bir sinir ağında, her iki bitişik katman arasındaki her nöron bir kenarla bağlanır. Giriş katmanının özellik boyutu çok yükseldiğinde, tam bağlı ağın eğitmesi gereken parametreler çok artacak ve hesaplama hızı çok yavaşlayacaktır.Örneğin siyah beyaz 28 × 28 el yazısı dijital resim, giriş Aşağıdaki şekilde gösterildiği gibi katmanda 784 nöron vardır:

Ortada yalnızca bir gizli katman kullanılırsa, w parametresinde 784 × 15 = 11760'dan fazla olacaktır; giriş, RGB formatında renkli 28 × 28 el yazısıyla yazılmış bir dijital resim ise, giriş nöronunda 28 × 28 × 3 olacaktır. = 2352 .... Görüntüleri işlemek için tamamen bağlı bir sinir ağı kullanmanın çok fazla eğitim parametresi gerektirdiğini görmek kolaydır.
Evrişimli Sinir Ağında (CNN), evrişimli katmanın nöronları yalnızca önceki katmanın bazı nöron düğümlerine bağlıdır, yani nöronları arasındaki bağlantılar tam olarak bağlı değildir ve aynı katmandadır. Belirli nöronlar arasındaki bağlantıların ağırlığı w ve ofset b paylaşılır (yani aynıdır), bu da gerekli eğitim parametrelerinin sayısını büyük ölçüde azaltır.
Evrişimli sinir ağı CNN'nin yapısı genellikle şu birkaç katmanı içerir:
Giriş katmanı: veri girişi için kullanılır
Evrişimli katman: özellik çıkarma ve özellik eşleme için evrişim çekirdeği kullanın
Uyarma katmanı: Evrişim aynı zamanda doğrusal bir işlem olduğundan, doğrusal olmayan bir haritalamanın eklenmesi gerekir
Havuzlama katmanı: aşağı örnekleme, özellik haritalarının seyrek işlenmesi, veri hesaplamalarının miktarını azaltma.
Tamamen bağlı katman: özellik bilgisi kaybını azaltmak için genellikle CNN'nin kuyruğuna yeniden uydurulur
Çıktı katmanı: sonuçları çıkarmak için kullanılır
Elbette ortada başka bazı işlevsel katmanlar da kullanılabilir:
Normalleştirme katmanı (Toplu Normalleştirme): CNN'deki özelliklerin normalleştirilmesi
Katman bölme: farklı bölgelerdeki belirli (resim) verileri ayrı ayrı inceleyin
Füzyon katmanı: bağımsız olarak özellik öğrenimi gerçekleştiren dalların füzyonu
İkincisi, CNN'nin hiyerarşik yapısı
Giriş katmanı:
CNN'nin giriş katmanında, (resim) veri girişinin formatı, tamamen bağlı sinir ağının giriş formatından (tek boyutlu vektör) farklıdır. CNN'nin girdi katmanının girdi formatı, resmin yapısını korur.
Siyah beyaz 28 × 28 bir resim için, CNN girişi, aşağıdaki şekilde gösterildiği gibi 28 × 28 iki boyutlu bir nörondur:

RGB formatındaki 28 × 28 resimler için, CNN girişi, aşağıdaki şekilde gösterildiği gibi 3 × 28 × 283D nörondur (RGB'deki her renk kanalının 28 × 28 matrisi vardır):

Evrişimli katman:
Evrişim katmanında birkaç önemli kavram vardır:
yerel alıcı alanlar
paylaşılan ağırlıklar
Girişin 28 × 28 iki boyutlu bir nöron olduğunu varsayarsak, 5 × 5 yerel alıcı alan (alıcı alan) tanımlarız, yani gizli katmandaki nöronlar giriş katmanındaki 5 × 5 nöronlara bağlanır. * 5 alanı, aşağıdaki şekilde gösterildiği gibi Yerel Alıcı Alanlar olarak adlandırılır:

Benzer şekilde görülebilir: Gizli katmandaki nöronlar, önceki katmanın bazı özelliklerini hissetmek için sabit boyutlu bir algılama alanına sahiptir. Tamamen bağlı bir sinir ağında, gizli katmandaki nöronların algılama alanı, önceki katmanın tüm özelliklerini görecek kadar büyüktür.
Evrişimli sinir ağında, gizli katmandaki nöronlar göreceli olarak küçük bir algı görünümüne sahiptir ve bir önceki katmanın özelliklerinin sadece bir kısmı görülebilir.Aynı katmandaki diğer nöronları elde etmek için algı görünümü kaydırılarak bir önceki katmanın diğer özellikleri elde edilebilir. Aynı katmandaki diğer nöronlardan:

Hareketli adım uzunluğunu 1 olarak ayarlayın: Soldan sağa tarayın, her seferinde 1 ızgarayı hareket ettirin, taradıktan sonra bir ızgara daha aşağı kaydırın ve soldan sağa tekrar tarayın.
Spesifik süreç animasyonda gösterilir:


Evrişimsel katmanın nöronlarının sadece önceki katmanın bazı nöron düğümlerine bağlı olduğu ve her bağlı hattın bir w ağırlığına karşılık geldiği görülebilir.
Bir algı alanı bir evrişim çekirdeğine sahiptir.Algı alanındaki ağırlık w matrisini evrişim çekirdeği olarak adlandırıyoruz; algılama alanının girişe tarama aralığına adım; adım nispeten büyük olduğunda (adım) > 1) Kenarın bazı özelliklerini taramak için, algılama alanı "sınırların dışında" olabilir. Şu anda, sınırın genişletilmesi gerekir (ped). Sınır genişletmesi 0 veya diğer değerlere ayarlanabilir. Adım boyutu ve sınır genişletme değeri boyutu kullanıcı tarafından belirlenir.
Evrişim çekirdeğinin boyutu kullanıcı tarafından tanımlanır, yani tanımlanmış görüş alanının boyutu; evrişim çekirdeğinin ağırlık matrisinin değeri, evrişimsel sinir ağının parametresidir.Bir ofset terimine sahip olmak için, evrişim çekirdeğine bir önyargı eşlik edebilir Vardiya terimi b için, başlangıç değerleri rastgele oluşturulabilir ve eğitim yoluyla değiştirilebilir.
Bu nedenle, görsel algı alanını tararken, bir sonraki nöron katmanının değeri hesaplanabilir:

Bir sonraki katmandaki tüm nöronlar için, önceki katmandaki nöronların özelliklerini farklı pozisyonlardan tespit ederler.
Bir evrişim çekirdeği ile alıcı bir görüş alanını tarayarak oluşturulan bir sonraki nöron matrisi katmanına bir özellik haritası (özellik haritası) diyoruz. Aşağıdaki şeklin sağ tarafı bir özellik haritasıdır:
Bu nedenle, aynı özellik haritasındaki nöronlar aynı evrişim çekirdeğini kullanır, bu nedenle bu nöronlar ağırlıkları paylaşır, ağırlıkları ve buna eşlik eden ofsetleri evrişim çekirdeğinde paylaşır. Bir özellik haritası bir evrişim çekirdeğine karşılık gelir. 3 farklı evrişim çekirdeği kullanırsak, 3 özellik haritası çıkarabiliriz: (algı görüş alanı: 5 × 5, kumaş uzunluğu adım: 1)

Bu nedenle, CNN'nin evrişimli katmanında, eğitmemiz gereken parametreler büyük ölçüde (5 × 5 + 1) × 3 = 78'e indirgenir.
Girişin 28 × 28 RGB bir görüntü olduğunu varsayarsak, yani giriş 3 × 28 × 28 iki boyutlu bir nörondur.Şu anda, evrişim çekirdeğinin boyutu sadece uzunluk ve genişlik ile değil, aynı zamanda derinlik ve algıyla da ifade edilir. Aşağıdaki şekilde gösterildiği gibi, ilgili derinliğe sahiptir:

Şekilden görülebilir: algı alanı: 3 × 2 × 2; evrişim çekirdeği: 3 × 2 × 2, derinlik 3; sonraki katmandaki nöronun değeri: b + 2d = 01i = 01j = 0wdijxdij Evrişim çekirdeğinin derinliği, görüş alanının derinliği ile aynıdır. Her ikisi de giriş verileriyle belirlenir.Uzunluk ve genişlik sizin tarafınızdan ayarlanabilir ve ayrıca numara sizin tarafınızdan da ayarlanabilir.Bir evrişim çekirdeği hala bir özellik haritasına karşılık gelir.
Not: "adım = 1", hem uzunluk hem de genişlikteki hareket aralığının 1 olduğu anlamına gelir, yani adım genişliği = 1 ve adım yüksekliği = 1
Teşvik katmanı:
Uyarma katmanı esas olarak evrişimli katmanın çıktısında doğrusal olmayan bir eşleştirme gerçekleştirir, çünkü evrişimli katmanın hesaplanması hala doğrusal bir hesaplamadır. Kullanılan aktivasyon işlevi genellikle ReLu işlevidir:
f (x) = maks (x, 0)
Evrişim tabakası ve uyarma tabakası genellikle birlikte "evrişimli tabaka" olarak adlandırılır.
Havuzlama katmanı:
Girdi evrişimli katmandan geçtiğinde, görüş alanı görece küçükse ve kumaş uzunluğu adım nispeten küçükse, ortaya çıkan özellik haritası (özellik haritası) hala nispeten büyüktür ve her özellik haritasının boyut azaltma işlemi havuzlama katmanı ve çıktı aracılığıyla gerçekleştirilebilir. Derinlik aynı kalır, yine de özellik haritalarının sayısı.
Havuz katmanında, özellik haritası matrisini taramak ve "görünüm havuzundaki" matris değerlerini hesaplamak için bir "görüş alanı havuzu (filtre)" vardır. Genellikle iki hesaplama yöntemi vardır:
Maksimum havuz oluşturma: "Havuz görünümü" matrisindeki maksimum değeri alın
Ortalama havuzlama: "havuz görünümü" matrisindeki ortalama değeri alın
Tarama işlemi ayrıca tarama bezi adımının uzunluğunu da içerecektir, tarama yöntemi evrişimli katmanla aynıdır, önce soldan sağa tarama ve ardından kumaşın uzunluğu boyunca aşağıya ve ardından soldan sağa doğru hareket ettirme. Aşağıdaki örnekte gösterildiği gibi:
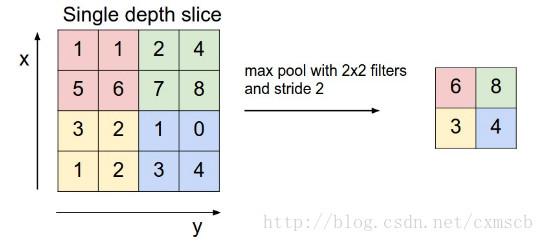
Bunların arasında, "havuz görünümü" filtresi: 2 × 2; kumaş uzunluğu adım: 2. (Not: "Chihua Vision" kişisel bir addır)
Son olarak, üç 24 × 24 özellik matrisi elde etmek için üç 24 × 24 özellik haritası aşağı örneklenebilir:

Normalleştirme katmanı:
1. Toplu Normalleştirme
Toplu Normalleştirme (toplu normalleştirme), sinir ağı katmanının ortasında ön işleme işlemini gerçekleştirir, yani önceki katmanın girdisi normalleştirilir ve ardından ağın bir sonraki katmanına girer, bu da "gradyan dağılımını" etkili bir şekilde önleyebilir. ", ağ eğitimini hızlandırmak için.
Toplu Normalleştirme özel algoritması aşağıdaki şekilde gösterilmektedir:

Her eğitim için, eğitim için batch_size örnekleri alın. BN katmanında, bir nöronu bir özellik olarak düşünün. Batch_size örnekleri, bir özellik boyutunda ve ardından her nöron xi boyutunda batch_size değerlerine sahip olacaktır. Bu örneklerin ortalamasını ve varyansını gerçekleştirin, formül aracılığıyla xi değerini alın ve ardından her bir nörona karşılık gelen çıktı yi elde etmek için ve parametrelerini doğrusal olarak eşleyin. BN katmanında, her nöron boyutunda, w ağırlığı gibi eğitimle optimize edilebilen bir ve parametresi olacağı görülebilir.
Evrişimli bir sinir ağında toplu normalleştirme gerçekleştirirken, genellikle ReLu tarafından etkinleştirilmeyen özellik haritaları toplu olarak normalleştirilir ve çıktı, uyarma fonksiyonunun kısmi türevini ayarlamak için uyarma katmanının girişi olarak kullanılır.
Bunun bir yolu, özellik haritasındaki nöronları öznitelik boyutu olarak kullanmaktır ve ve parametrelerinin toplamı 2 × fmapwidth × fmaplength × fmapnum'a eşittir.Bu yapılırsa, parametre sayısı çok olacaktır;
Diğer bir yaklaşım, bir özellik haritasını bir özellik boyutu olarak ele almaktır.Bir özellik haritasındaki nöronlar, özellik haritasının ve parametrelerini paylaşır. ve parametrelerinin toplamı 2 × fmapnum'a eşittir. Ortalama ve varyans hesaplanır Batch_size eğitim örneklerinde her bir özellik haritası boyutunun ortalaması ve varyansı.
Not: fmapnum, bir örneğin özellik haritalarının sayısını ifade eder.Özellik haritalarının nöronlar gibi belirli bir sırası vardır.
Eğitim süreci ile Toplu Normalleştirme algoritmasının test süreci arasındaki fark:
Eğitim sürecinde, eğitim için CNN ağına batch_size eğitim örneklerinin sayısını her koyduğumuzda, BN katmanında, çıktıyı hesaplamak için gereken ortalama ve varyansı doğal olarak elde edebiliriz;
Test sürecinde, genellikle CNN ağına yalnızca bir test numunesi gireriz. Bu, BN katmanında hesaplanan ortalama ve varyansın her ikisinin de 0 olacağı anlamına gelir. Yalnızca bir örnek girişi olduğundan, BN katmanının girdisi de çok büyük görünecektir. CNN ağının çıkışında hatalara yol açan sorun. Bu nedenle, test sürecinde BN katmanında normalize edildiğinde eğitim setindeki tüm örneklerin her boyutunun ortalamasını ve varyansını kullanmamız gerekir.Elbette, hesaplama kolaylığı için, batch_num eğitim sürecinde BN katmanında her seferinde geri dönebiliriz. Birleştirme sırasında, her boyutun ortalaması ve varyansı eklenir ve son olarak ortalama tekrar hesaplanır.
2. Yerel Yanıt Normalleştirme
Yerel Yanıt Normalleştirmesinin normalleştirme yöntemi esas olarak farklı bitişik evrişim çekirdeklerinin çıktıları arasında (ReLu'dan sonra) oluşur, yani girdi ReLu'dan sonra farklı özellik haritalarında gerçekleşir.
LRN'nin formülü aşağıdaki gibidir:
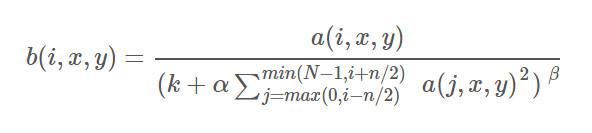
onların arasında:
a (i, x, y), i-inci evrişim çekirdeğinin çıktısının (ReLu katmanından geçen) özellik haritasındaki (x, y) konumundaki değeri temsil eder.
b (i, x, y), LRN'den sonra a (i, x, y) çıktısını temsil eder.
N, evrişim çekirdeği sayısını, yani giriş özelliği haritalarının sayısını temsil eder.
n, size bağlı olan komşuların evrişim çekirdek sayısını (veya özellik haritalarını) temsil eder.
k, , kullanıcı tarafından ayarlanan veya karar verilen hiperparametrelerdir.
BN ile fark: BN, mini parti verilerine dayanmaktadır. Yakın komşu normalizasyonunun yalnızca kendisi tarafından belirlenmesi gerekir. BN eğitiminin öğrenme parametreleri vardır; BN normalizasyonu esas olarak farklı örnekler arasında meydana gelir ve LRN normalizasyonu esas olarak farklı Evrişim çekirdeğinin çıktısı arasında.
Katmanlar halinde kesin:
Bazı uygulamalarda resmi kesmek ve belli bir alanı bağımsız olarak öğrenmek gerekir. Bu şekilde, belirli bölümler için algı alanını ayarlayarak daha güçlü bir şekilde öğrenebilirsiniz.
Füzyon katmanı:
Füzyon katmanı, dilim katmanlarını birleştirebilir veya farklı boyutlardaki evrişim çekirdekleriyle öğrenilen özellikleri birleştirebilir.
Örneğin, GoogleLeNet'te, hedef özellikleri öğrenmek için çoklu çözünürlüklü evrişim çekirdekleri kullanılır ve her özellik haritasının uzunluğunu ve genişliğini tutarlı hale getirmek için dolgu kullanılır ve ardından birden çok özellik haritası, derinlemesine birbirine dikilir:

Birkaç füzyon yöntemi vardır, biri özellik matrisleri arasında ekleme kademesidir, diğeri ise özellik matrisi (+, -, x, max, conv) üzerinde işlemler gerçekleştirmektir.
Tamamen bağlı katman ve çıktı katmanı
Tamamen bağlı katman, esas olarak, özellik bilgisi kaybını azaltmak için özellikleri yeniden düzenler; çıktı katmanı, esas olarak nihai hedef sonucu çıkarmak için hazırlanır. Örneğin, aşağıdaki şekilde gösterildiği gibi VGG'nin yapı şeması:

Üç, tipik bir evrişimli sinir ağı
LeNet-5 modeli
Dijital tanımaya başarıyla uygulanan ilk evrişimli sinir ağı modeli (evrişimli katmanın kendi aktivasyon işlevi vardır, aşağıda aynıdır):

Evrişim katmanının evrişim çekirdeğinin kenar uzunluğu 5 ve adım uzunluğu 1'dir; havuz katmanının pencere kenarı uzunluğu 2 ve adım uzunluğu 2'dir.
AlexNet modeli
Belirli yapı şeması:
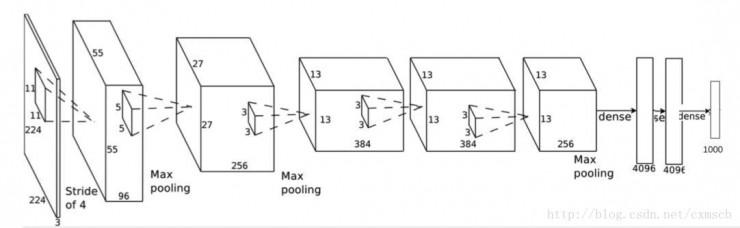
AlexNet'in yapısından, klasik evrişimli sinir ağı yapısının genellikle:
Giriş katmanı (Evrişimli katman + Havuzlama katmanı?) + Tam bağlı katman + Çıktı katmanı
AlexNet evrişim katmanının evrişim çekirdeğinin yan uzunluğu 5 veya 3'tür ve havuzlama katmanının penceresinin yan uzunluğu 3'tür. Belirli parametreler şekilde gösterilmektedir:

VGGNet modeli
VGGNet modelinin ve AlexNet modelinin yapısı çok fazla değişmedi ve evrişimli katmana çok sayıda evrişimli katman eklendi. AlexNet (üstte) ve VGGNet (altta) arasındaki karşılaştırma aşağıdaki şekilde gösterilmektedir:

Spesifik parametreler şekilde gösterilmiştir: CONV3-64: evrişim çekirdeğinin uzunluğunun ve genişliğinin 3 olduğunu ve sayının 64 olduğunu gösterir; POOL2: havuz oluşturma penceresinin uzunluğunun ve genişliğinin hem 2 hem de diğerlerinin benzer olduğunu gösterir.

GoogleNet modeli
Farklı çözünürlüklere sahip çoklu evrişimli çekirdekler kullanılır ve son olarak bunlardan elde edilen özellik haritaları, yapıda gösterildiği gibi derinlemesine bir araya getirilir:

Bunların arasında Başlangıç modülü adı verilen bazı ana modüller vardır, örneğin:

Başlangıç modülünde çok sayıda 1 × 1 evrişim çekirdeği kullanılır. 1 × 1 evrişimli çekirdek kullanılırken, adım boyutu 1 olduğunda, giriş özelliği haritasının uzunluğu ve genişliği ve çıktı özelliği haritası değişmez, ancak şu şekilde değiştirilebilir: 1 × 1 evrişimli çekirdeklerin sayısı, özellik haritasının kalınlığını azaltabilir ve böylece bazı eğitim parametrelerini azaltabilir.
GoogleNet'in bir diğer özelliği de tamamen evrişimli bir yapı (FCN) olmasıdır.Ağın sonunda tamamen bağlı bir katman kullanılmaz, bir yandan bu parametre sayısını azaltabilir ve aşırı sığdırılması kolay değildir, diğer yandan bazı mekansal bilgileri de beraberinde getirir. Kayıp. Tamamen bağlantılı katman yerine, global ortalama havuzlama (Global Average Pooling, GAP) yöntemi kullanılır. Buradaki fikir, her kategori için bir özellik haritası çıkarmak ve ardından her özellik haritasındaki ortalama değeri, son softmax katmanına girdi olarak almaktır. .
ResNet modeli
Önceki CNN modelinde, girdi katman katman aşağı aktarılır (solda) Katman derin olduğunda model iyi eğitilmez. ResNet modelinde, düşük seviyeden öğrenilen özellikler ile yüksek seviyeden öğrenilen özellikleri (toplama işlemi, şeklin sağında) birleştirir, böylece ters transfer yapıldığında türev daha hızlı transfer edilir ve gradyan dağılım fenomeni azaltılır.
Not: F (X) şekli, eklenebilmesi için X'in şekline eşit olmalıdır.

Dört, Tensorflow kodu
Ana işlev açıklaması:
Evrişimli katman:
tf.nn.conv2d (input, filter, strides, padding, use_cudnn_on_gpu = None, data_format = None, name = None)
Parametre Tanımı:
data_format: giriş formatını gösterir, iki tür vardır: "NHWC" ve "NCHW", varsayılan "NHWC" dir
girdi: girdi 4 boyutlu bir format (görüntü) verisidir, verilerin şekli data_format tarafından belirlenir: data_format "NHWC" olduğunda, giriş verilerinin şekli eğitim sırasında sırasıyla resim sayısı, resim yüksekliği ve resim genişliği olarak ifade edilir , Görüntü kanallarının sayısı. Veri_formatı "NHWC" olduğunda, giriş verilerinin şekli şu şekilde ifade edilir:
filtre: Evrişim çekirdeği 4 boyutlu bir formattaki verilerdir: şekil şu şekilde ifade edilir: evrişim çekirdeğinin yüksekliği, genişliği ve derinliği (kanal içi giriş ile aynı olmalıdır) ve çıkış özelliği eşlemlerinin sayısı (yani, evrişim çekirdeği) Numara).
adımlar: Adım uzunluğunu temsil eder: 4 uzunluğunun tek boyutlu bir listesi, her öğe data_format'a karşılık gelir ve data_format'ın her bir boyutundaki hareketli adım uzunluğunu temsil eder. Varsayılan girdi biçimi: "NHWC" olduğunda, adım sayısı =. Bunlar arasında, batch ve in_channels 1 olmalıdır, yani sadece bir numunenin bir kanalındaki özellik haritasında hareket ettirilebilirler. İn_height ve in_width, evrişim çekirdeğinin özellik haritasının yüksekliği ve genişliği üzerinde hareket ettiği kumaş uzunluğunu, yani adım yüksekliği ve adım genişliği .
dolgu: doldurma yöntemini belirtir: "AYNI", basitçe kenarı 0 ile doldurmak olarak anlaşılan dolgu yöntemini belirtir, ancak başka bir gereksinim vardır: soldaki (üst) sıfırların sayısı ve sağdaki (alt) sıfırların sayısı Aynı veya bir eksik "GEÇERLİ", yöntemin doldurulmadığı ve fazlalığın atıldığı anlamına gelir. Özel formül:
"AYNI": output_spatial_shape = (input_spatial_shape / strides )
"VALID": output_spatial_shape = ((input_spatial_shape - (uzamsal_filter_shape -1) / adım )
Havuzlama katmanı:
tf.nn.max_pool (value, ksize, strides, padding, data_format = NHWC, name = None)
Veya
tf.nn.avg_pool ()
Parametre Tanımı:
değer: havuzlamanın girdisini gösterir: 4 boyutlu bir format verisi, verilerin şekli data_format tarafından belirlenir, varsayılan olarak şekil
Diğer parametreler ve tf.nn.cov2d türü
ksize: havuz oluşturma penceresinin boyutunu gösterir: tek boyutlu bir uzunluk listesi 4, genellikle gruplar ve kanallar üzerinde havuz oluşturmak istemediğiniz için değerini 1 olarak ayarlayın.
Toplu Nomalizasyon katmanı:
batch_normalization (x, ortalama, varyans, uzaklık, ölçek, varyans_epsilon, ad = Yok)
Ortalama ve varyans, tf.nn.moments aracılığıyla hesaplanır:
batch_mean, batch_var = tf.nn.moments (x, axes =, keep_dims = True), eksenlerin girdisine dikkat edin. Boyut olarak özellik haritası ile genel normalleştirme için, özellik haritasının şekli ise, eksenler şu şekilde atanacaktır:
x, giriş özelliği haritasıdır, dört boyutlu verilerdir; ofset ve ölçek, tek boyutlu Tensor verileridir ve şekil, özellik haritasının derinliğine eşittir.
Kod örneği:
Sklearn kitaplığındaki el yazısı rakam tanıma, evrişimli bir sinir ağı oluşturularak gerçekleştirilir.Yerleşik evrişimli sinir ağının yapısı aşağıdaki şekilde gösterilmektedir:

tensorflow'u tf olarak içe aktar
sklearn.datasets'ten import load_digits
numpy'yi np olarak içe aktar
digits = load_digits
X_data = digits.data.astype (np.float32)
Y_data = digits.target.astype (np.float32) .reshape (-1,1)
X_data.shape yazdır
Y_data.shape yazdır
(1797, 64)
(1797, 1)
sklearn.preprocessing'den MinMaxScaler ithal
ölçekleyici = MinMaxScaler
X_data = scaler.fit_transform (X_data)
sklearn.preprocessing'den OneHotEncoder'ı içe aktar
Y = OneHotEncoder.fit_transform (Y_data) .todense # one-hot encoding
Y
matris(,
,
,
...,
,
,
>)
# Resim formatına dönüştürme (toplu iş, yükseklik, genişlik, kanallar)
X = X_data.reshape (-1,8,8,1)
batch_size = 8 # MBGD algoritmasını kullanarak batch_size değerini 8 olarak ayarlayın
def generatebatch (X, Y, n_examples, batch_size):
aralıktaki batch_i için (n_examples // batch_size):
start = batch_i * batch_size
end = start + batch_size
batch_xs = X
batch_ys = Y
batch_xs verim, batch_ys # Her partiyi oluştur
tf.reset_default_graph
# Giriş katmanı
tf_X = tf.placeholder (tf.float32,)
tf_Y = tf.placeholder (tf.float32,)
# Evrişimli katman + aktivasyon katmanı
conv_filter_w1 = tf.Variable (tf.random_normal ())
conv_filter_b1 = tf.Variable (tf.random_normal ())
relu_feature_maps1 = tf.nn.relu (\
tf.nn.conv2d (tf_X, conv_filter_w1, strides =, padding = 'AYNI') + conv_filter_b1)
# Havuzlama katmanı
max_pool1 = tf.nn.max_pool (relu_feature_maps1, ksize =, strides =, padding = 'AYNI')
max_pool1 yazdır
Tensor ("MaxPool: 0", şekil = (?, 4, 4, 10), dtype = float32)
# Evrişimli katman
conv_filter_w2 = tf.Variable (tf.random_normal ())
conv_filter_b2 = tf.Variable (tf.random_normal ())
conv_out2 = tf.nn.conv2d (relu_feature_maps1, conv_filter_w2, strides =, padding = 'AYNI') + conv_filter_b2
dönüşüm_sayısı2 yazdır
Tensör ("add_4: 0", şekil = (?, 4, 4, 5), dtype = float32)
# BN normalleştirme katmanı + aktivasyon katmanı
batch_mean, batch_var = tf.nn.moments (conv_out2 ,, keep_dims = True)
shift = tf.Variable (tf.zeros ())
ölçek = tf.Variable (tf.ones ())
epsilon = 1e-3
BN_out = tf.nn.batch_normalization (conv_out2, batch_mean, batch_var, shift, scale, epsilon)
yazdır BN_out
relu_BN_maps2 = tf.nn.relu (BN_out)
Tensör ("batchnorm / add_1: 0", şekil = (?, 4, 4, 5), dtype = float32)
# Havuzlama katmanı
max_pool2 = tf.nn.max_pool (relu_BN_maps2, ksize =, strides =, padding = 'AYNI')
max_pool2 yazdır
Tensör ("MaxPool_1: 0", şekil = (?, 2, 2, 5), dtype = float32)
# Özellik haritasını genişletin
max_pool2_flat = tf.reshape (max_pool2,)
# Tamamen bağlı katman
fc_w1 = tf.Variable (tf.random_normal ())
fc_b1 = tf.Variable (tf.random_normal ())
fc_out1 = tf.nn.relu (tf.matmul (max_pool2_flat, fc_w1) + fc_b1)
# Çıktı katmanı
out_w1 = tf.Variable (tf.random_normal ())
out_b1 = tf.Variable (tf.random_normal ())
pred = tf.nn.softmax (tf.matmul (fc_out1, out_w1) + out_b1)
kayıp = -tf.reduce_mean (tf_Y * tf.log (tf.clip_by_value (pred, 1e-11,1.0)))
train_step = tf.train.AdamOptimizer (1e-3) .minimize (kayıp)
y_pred = tf.arg_max (önceden, 1)
bool_pred = tf.equal (tf.arg_max (tf_Y, 1), y_pred)
doğruluk = tf.reduce_mean (tf.cast (bool_pred, tf.float32)) # doğruluk
tf.Session olarak oturum:
sess.run (tf.global_variables_initializer)
aralıktaki dönem için (1000): # 1000 döngüyü yineleyin
batch_xs için, generatebatch'te batch_ys (X, Y, Y.shape, batch_size): # Her döngüde MBGD algoritması gerçekleştirin
sess.run (train_step, feed_dict = {tf_X: batch_xs, tf_Y: batch_ys})
eğer (epoch% 100 == 0):
res = sess.run (doğruluk, feed_dict = {tf_X: X, tf_Y: Y})
baskı (epoch, res)
res_ypred = y_pred.eval (feed_dict = {tf_X: X, tf_Y: Y}). flatten #, tek bir örneği değil, yalnızca bir örnek grubunu tahmin edebilir
res_ypred yazdır
(0, 0,36338341)
(100; 0,96828049)
(200, 0.99666113)
(300, 0.99554813)
(400, 0.99888706)
(500; 0,99777406)
(600; 0.9961046)
(700; 0,99666113)
(800, 0.99499166)
(900, 0.99888706)
100. parti boyutu yinelemesinde, Toplu Normalleştirme etkisi sayesinde doğruluk oranı hızla yakınsamaya yaklaşıyor! Bu modelin henüz tek bir numuneyi tahmin etmek için kullanılamayacağına dikkat edilmelidir, çünkü BN tabakası hesaplandığında, tek bir numunenin ortalaması ve varyansı hem 0'dır hem de zıt tahmin etkisi elde edilecektir Çözüm için normalleştirme tabakasına bakınız.
sklearn.metrics'ten içe aktarma doğruluğu_score
baskı doğruluğu_sorusu (Y_data, res_ypred.reshape (-1,1))
0.998887033945
TensorFlow ve Neural Network Algorithm Advanced Application Class "başlayacak!
Başlangıçtan ileri düzeye, teori + gerçek savaş, TensorFlow'u tek noktadan derinlemesine anlama!
Bu kurs, derin öğrenme geliştiricilerine yöneliktir ve TensorFlow'un görüntü tanıma ve metin analizi gibi belirli sorunları çözmek için nasıl kullanılacağını öğretir. Kurs 10 haftayı kapsıyor.TensorFlow'un ilkeleri ve temel pratik becerileriyle başlayacak ve öğrencilere TensorFlow'da adım adım CNN, kendi kendine kodlama, RNN, GAN ve diğer modellerin nasıl oluşturulacağını öğretecek ve son olarak TensorFlow'a dayalı eksiksiz bir derin öğrenme geliştirme setinde ustalaşacak. beceri.
İki öğretim görevlisi Tong Da ve Bai Fachuan, ThoughtWorks'ün kıdemli teknik uzmanlarıdır ve büyük veri platformları ve derin öğrenme sistemi geliştirme projeleri oluşturma konusunda zengin deneyime sahiptir.
Saat: Her Salı ve Perşembe gecesi 20: 00-21: 00
Kurs süresi: Toplam 20 saat, 10 haftada tamamlandı, haftada 2 kez, her seferinde 1 saat
Çevrimiçi öğretim adresi:
Leifeng.com'daki ilgili okumalar (herkese açık hesap: Leifeng.com):
Zayıf denetimli öğrenmeye dayalı görüntü bölümlemede CNN uygulaması
Geçtiğimiz üç yılda CNN, görüntü bölümleme alanında hangi teknolojik değişiklikler yaşadı?