Çin Bilimler Akademisi Otomasyon Enstitüsü Akıllı Algılama ve Hesaplama Araştırma Merkezi'nden 11 makale CVPR | CVPR 2018 tarafından kabul edildi
Leifeng.com AI teknolojisi inceleme notu: Bu makalenin yazarı Guo Rui'e, ilk olarak Çin Bilimler Akademisi Otomasyon Enstitüsü'nün "Akıllı Algılama ve Hesaplama Araştırma Merkezi" nin WeChat kamu hesabında yayınlandı.
CVPR, bilgisayarla görme, örüntü tanıma ve yapay zeka alanında üst düzey uluslararası bir konferanstır. 18-22 Haziran 2018 tarihleri arasında ABD'nin Salt Lake City kentinde düzenlenecek. AI Technology Review ayrıca sahneye ön saflarda raporlar getirecek. Makalenin yazarı veya konferansa katılmak üzere olan bir şirket olmanıza bakılmaksızın, raporlama / işbirliği için lütfen AI Technology Review (WeChat ID: aitechreview) editörü ile iletişime geçin.
Akıllı Algılama ve Hesaplama Araştırma Merkezi, Çin Bilimler Akademisi Otomasyon Enstitüsü'nün bağımsız bir bilimsel araştırma bölümüdür ve her yerde bulunan akıllı algılama teorisi ve teknolojisi ve beraberindeki büyük algılama verilerinin akıllı analizi ve işlenmesi çalışmalarına adanmıştır. Bu yılki CVPR 2018'de Intelligent Algı ve Bilgisayar Araştırma Merkezi'nin kabul ettiği 11 makale bir kez daha rekor seviyeye ulaştı.
Kağıt 1 Kısmi Yüz Tanıma için Dinamik Özellik Öğrenimi
Lingxiao He, Haiqing Li, Qi Zhang, Zhenan Sun
Video gözetimi ve cep telefonu gibi sahnelerde kısmi yüz tanıma çok önemli bir görevdir. Bununla birlikte, kısmi yüz tanımayı incelemek için birkaç yöntem vardır. Tam evrişimli ağ ve seyrek temsil sınıflandırmasını birleştiren yüz tanıma probleminin bir bölümünü çözmek için dinamik bir özellik eşleştirme yöntemi öneriyoruz. İlk olarak, Galeri ve Sonda'nın özellik haritalarını çıkarmak için tam evrişimli ağı kullanın; ikincisi, Galeri'nin özellik haritalarını, Sonda özellik haritalarıyla aynı boyuttaki alt özellik haritalarına ayırmak için büyük ve küçük bir kayan pencere kullanın ve ardından dinamik özellik sözlüğünü kullanın; son olarak, seyrek ifadeyi kullanın Sonda özellik haritası ve dinamik özellik sözlüğü arasındaki benzerliği eşleştirmek için sınıflandırma. Dinamik özellik eşleştirme yöntemine dayanarak, tam evrişimli ağı optimize etmek için kayan bir kayıp öneriyoruz. Bu kayıp, sınıf içi varyasyonu azaltır ve sınıflar arası varyasyonu artırır, böylece dinamik özellik eşleştirme performansını artırır. Diğer kısmi yüz tanıma yöntemleriyle karşılaştırıldığında, dinamik eşleştirme yöntemimiz iyi performans sağlar.
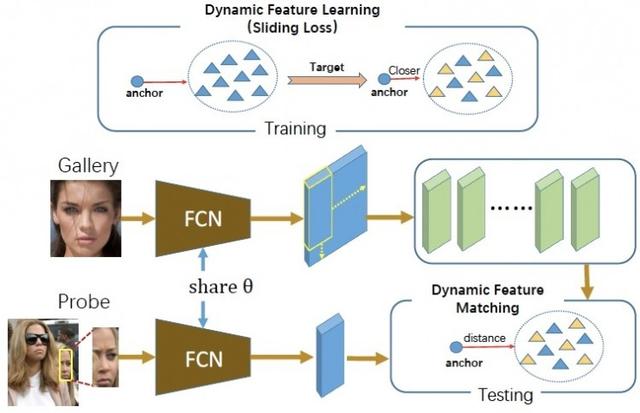
Dinamik özellik eşleştirmeye dayalı kısmi yüz tanıma çerçevesi
Bildiri 2 Kısmi Kişilerin Yeniden Tanımlanması için Derin Mekansal Özelliklerin Yeniden Yapılandırılması: Serbest Stil Yaklaşımı
Lingxiao He, Jian Liang, Haiqing Li, Zhenan Sun
Bazı yayaların yeniden belirlenmesi çok önemli ve zorlu bir sorundur. Kısıtlamasız bir ortamda, yayalar duruş ve görüş açısındaki değişikliklerle kolayca tıkanır, bu nedenle bazen tanıma için sadece kısmen görülebilen yaya görüntüleri kullanılabilir. Bununla birlikte, birkaç çalışma, bazı yayaları tanımlayabilen bir yöntem önermiştir. Bazı yayaların yeniden tanımlanması sorunuyla başa çıkmak için hızlı ve doğru bir yöntem öneriyoruz. Önerilen yöntem, girdi görüntü boyutuna karşılık gelen uzamsal özellik haritasını çıkarmak için tam bir evrişimli ağ kullanır, böylece girdi görüntüsünün boyut kısıtlamaları yoktur. Farklı boyutlardaki bir çift yaya görüntüsünü eşleştirmek için, yaya hizalamasını gerektirmeyen bir yöntem öneriyoruz: derin mekansal özellik rekonstrüksiyonu. Özellikle, farklı uzamsal özellik haritalarının benzerliğini hesaplamak için sözlük öğrenmedeki yeniden yapılandırma hatasına başvururuz. Bu eşleştirme yöntemine göre, aynı kişiden gelen görüntü çiftlerinin benzerliğini artırmak için uçtan uca öğrenme yöntemini kullanırız ve bunun tersi de geçerlidir. Yöntemimizin hizalama gerektirmediği ve giriş görüntüsünün boyutunda bir sınırlama olmadığı görülebilir. Kısmi REID, Kısmi iLIDS ve Market1501 konusunda iyi sonuçlar elde ettik.
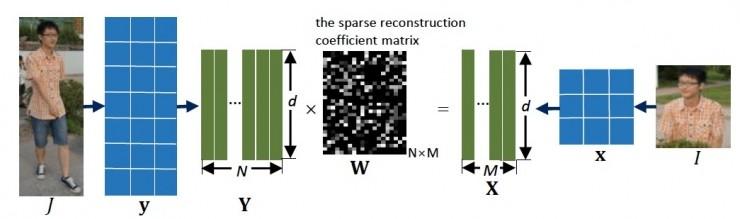
Derin uzaysal özellik rekonstrüksiyonu
Kağıt 3 Kişiyi Yeniden Tanımlama Modellerinin Genelleştirilmesini Geliştirmek İçin Olumsuz Bir Şekilde Kapatılmış Örnekler
Houjing Huang, Dangwei Li, ZhangZhang, Kaiqi Huang
Yaya yeniden tanımlama (ReID), bir çapraz kamera yaya erişim görevidir.Aydınlatma değişiklikleri, görüş açısı değişiklikleri ve tıkanma gibi karmaşık faktörler nedeniyle, mevcut modeller genellikle eğitim aşamasında yüksek doğruluk elde eder, ancak test aşamasının performansı tatmin edici değildir . Modelin genelleme performansını iyileştirmek için, veri setini genişletmek için özel bir örnek öneriyoruz: ters kapanma örnekleri.
Tüm yöntem süreci şu şekildedir: (1) Yaygın olarak kullanılan yönteme göre bir ReID modeli eğitin; (2) Modelin eğitim örneklerini tanırken dikkat ettiği alanları bulmak için ağ görselleştirme yöntemini kullanın ve (kısmen) yeni oluşturmak için bu alanları kapatın. Aynı zamanda bu örneklerin orijinal kategori etiketlerini de saklıyoruz; (3) Son olarak yeni örnekleri orijinal veri setine ekliyor ve önceki yönteme göre yeni bir model eğitiyoruz. Bu tür bir örnek sadece gerçekte tıkanma durumunu simüle etmekle kalmaz, aynı zamanda model için zor bir örnektir.Modelin eğitimi için ivme sağlayabilir, böylece yerel minimumdan sıyrılır ve modelin aşırı uyumunu azaltır. Deney, orijinal ReID modelinin, eğitim örneklerini tanırken yalnızca bazı yerel vücut bölgelerine odaklandığını ve yeni örnekler ekleyerek eğitilen modelin, daha önce dikkat edilmeyen bazı vücut bölgelerine de dikkat ederek test aşamasında modelin sağlamlığını artırdığını buldu. . Aşağıdaki şekil, ReID'nin bir ID çoklu sınıflandırma modeli kullandığı ve model görselleştirme yönteminin bir kayan pencere kapatma yöntemi kullandığı bu yöntemin özel bir uygulamasıdır.
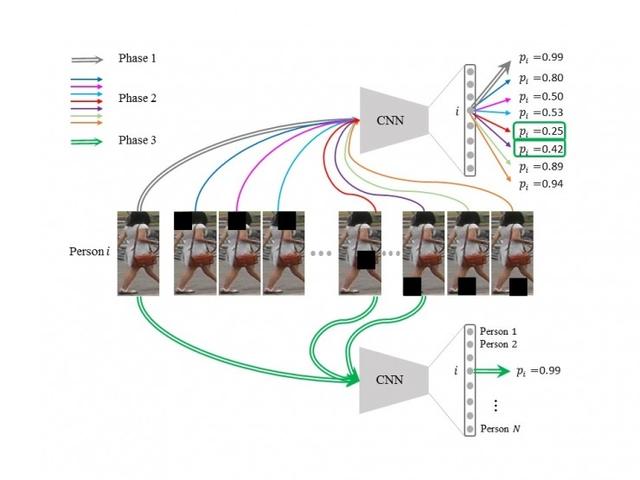
Düşman tıkanmasına dayalı veri büyütme algoritmasının akış şeması
Bildiri 4 Anlamsal Kavramları Öğrenme ve Görüntü ve Cümle Eşleştirme Sırası
Yan Huang, Qi Wu, Liang Wang
Görüntü metni eşleştirmesinin temel sorunu, görüntü metni arasındaki modlar arası benzerliğin doğru bir şekilde nasıl ölçüleceğidir. Veri analizi yoluyla, görüntü metinlerinin esas olarak aşağıdaki iki nedenden dolayı eşleştirilebileceğini bulduk: 1) Görüntü metinleri farklı modal özellikleri yansıtsa da, ortak anlamsal kavramlar içerir; 2) anlamsal kavramların toplanması, Sıralı, ancak belirli bir semantik sıraya göre düzenlenmiş. Bu nedenle, resim metninde yer alan anlamsal kavramları ve anlamsal düzeni birlikte öğrenmek için bir model öneriyoruz. Model, herhangi bir görüntünün içerdiği anlamsal kavramlar kümesini tahmin etmek için çok etiketli bölgeselleştirilmiş bir evrişimli ağ kullanır. Daha sonra elde edilen anlamsal kavramlara göre düzenli olarak düzenlenir, yani anlamsal düzen öğrenilir. Bu işlem, özellikle görüntü metni eşleştirme ve oluşturma stratejilerinin birleştirilmesiyle gerçekleştirilir. Ek olarak, yerel anlamsal kavramlar ve küresel bağlamsal bilgiler arasındaki tamamlayıcı etkileri ve ayrıca metin oluşturma üzerindeki etkisini araştırır. Önerilen yöntemimizin etkinliğini doğrulamak için mevcut ana görüntü ve metin eşleştirme veritabanları Flickr30k ve MSCOCO üzerinde çok sayıda deney gerçekleştirdik ve en iyi modlar arası erişim sonuçlarını elde ettik.
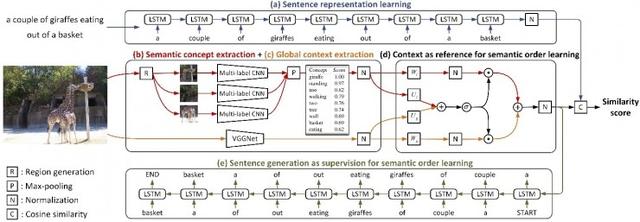
Ortak görüntü anlamsal kavramı ve anlamsal sıra öğrenme çerçevesi
Kağıt 5 A2-RL: Görüntü Kırpma için Estetik Bilinçli Güçlendirme Öğrenimi
Debang Li, Huikai Wu, Junge Zhang, Kaiqi Huang
Mevcut görüntü verilerinin miktarı artmaya devam ettikçe, otomatik görüntü işleme talebi giderek artmıştır ve görüntü kırpma, görüntü işlemede çok önemli bir adımdır. Otomatik görüntü kırpma teknolojisi yalnızca çoğu resmin işlenmesini hızlı bir şekilde tamamlamakla kalmaz, aynı zamanda profesyonel kameramanların görüntünün kompozisyon kalitesini iyileştirmek için daha iyi bir perspektif bulmasına yardımcı olur ve bu da büyük bir uygulama değerine sahiptir. Görüntü kırpmanın veri açıklamasını elde etmek zor olduğundan ve genel veri miktarı küçük olduğundan, A2-RL takviye öğrenmeye dayalı zayıf denetimli (kırpma kutusu etiketlemesi yok) bir görüntü kırpma algoritması öneriyoruz. Önceki zayıf denetimli otomatik kırpma algoritmalarının çoğu, çok sayıda hesaplama kaynağı ve zaman gerektiren aday bölgeleri elde etmek için kayan pencereler kullanır.Yukarıdaki sorunları çözmek için, bir aracı (aracı) kullanarak otomatik kırpmaya takviye öğrenimi ekliyoruz. Giriş görüntüsünde aday alanın konumunu ve boyutunu uyarlamalı olarak ayarlayın. Temsilci, görüntünün küresel ve yerel özelliklerini gözlem bilgisi olarak kullanır ve bir sonraki eylemi güncel ve geçmiş gözlemlere dayanarak belirler. Eğitim sürecinde, temsilci ödülü görüntü kalitesi puanına göre hesaplar ve eğitim için A3C algoritmasını kullanır ve sonunda daha iyi bir aday bölge ayarlama stratejisi öğrenir. Deney sırasında, yöntemimiz birden fazla standart kırpılmış veri kümesinde test edildi ve yalnızca hızda önemli bir gelişme sağlamakla kalmadı, aynı zamanda önemli ölçüde iyileştirilmiş doğruluk elde etti. Yöntemimizin genel çerçevesi şu şekildedir:
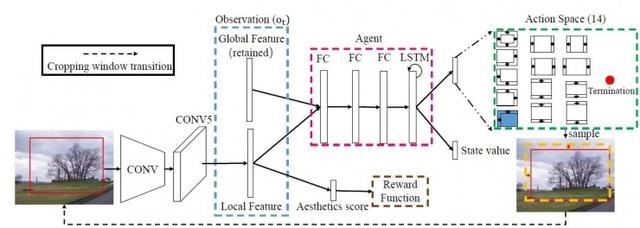
Takviye öğrenmeye dayalı otomatik görüntü kırpma modeli mimarisi
Makale 6 Sıfır Atış Tanıma için Gizli Özelliklerin Ayrımcı Öğrenimi
Yan Li, Junge Zhang, Kaiqi Huang, Jianguo Zhang
Zero-Shot Learning, görsel ve anlamsal alanlar arasında ortak bir gömülü boşluk öğrenerek test setindeki bilinmeyen kategorileri test edebilir. Önceki sıfır örneklem çalışması, sıfır örneklemli öğrenmede görsel özelliklerin ve anlamsal özelliklerin rolünü göz ardı ederek, temel olarak gömülü uzamsal öğrenme sürecine odaklandı. Geleneksel sıfır örneklem öğrenme sürecinde yetersiz özellik ifade ayrımcılığı sorununu hedefleyerek, görsel alan ve anlamsal alanın iki yönünden geliştirilmiş yöntemler öneriyor ve aynı anda her iki alanda da daha fazla ayırt edici özellik ifadeleri öğreniyoruz ve sonra büyük ölçüde Sıfır örneklemli öğrenmenin tanıma performansı iyileştirildi. Özellikle, 1) Görsel alanda, orijinal görüntüden ayırt edilen görüntü alanını otomatik olarak kazan yakınlaştırma ağı öneriyoruz. 2) Anlamsal alanda, kullanıcı tanımlı özniteliklere ek olarak, "örtük öznitelikleri" ayrımcılık ile otomatik olarak öğrenmek için üçlü kayıp kullanırız. 3) Son olarak, görüntü uzayında ayrımcı bölge madenciliğinin iki modülü ve anlamsal alanda ayırt edici gizli nitelik öğrenimi, uçtan uca bir çerçevede birlikte öğrenilir ve birlikte teşvik edilir.
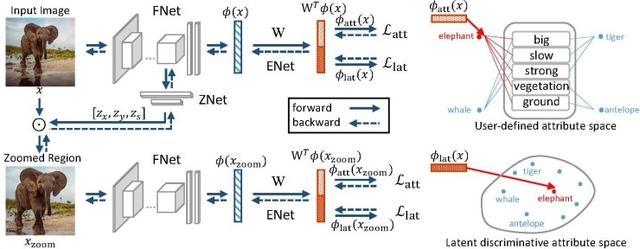
Sıfır örneklemli öğrenme için örtük bir ayrımcı özellik madenciliği çerçevesi
Kağıt 7 Poz Güdümlü Fotogerçekçi Yüz Döndürme
Yibo Hu, Xiang Wu, Bin Yu, Ran He, Zhenan Sun
Derin öğrenmenin gelişmesiyle birlikte, yüz tanıma algoritmalarının performansı büyük ölçüde iyileştirildi, ancak büyük pozlu yüz tanıma sorununun acilen çözülmesi gerekiyor. Yüz döndürme, yüz tanımada büyük poz sorununa etkili bir çözüm sağlar. Keyfi bir açılı yüz döndürme algoritması öneriyoruz, Couple-Agent Pose-Guided Generative Adversarial Network (CAPG-GAN). CAPG-GAN, yüzün kilit noktalarının duruş bilgilerini kodlayarak yüz oluşturma görevini yerine getirmesi için yüzleşme oluşturma ağına rehberlik eder. Aynı zamanda, yüzün kimlik bilgisini ve yerel doku bilgisini sınırlamak için kimlik koruma kaybı işlevi ve tam varyasyon normal terimi kullanılır. Sonunda, algoritmamız hem Multil-PIE hem de LFW'de iyi tanıma oranları elde etti.Aynı zamanda, şekilde gösterildiği gibi, CAPG-GAN, yüzün anahtar kodlama bilgisine göre herhangi bir açıda yüzler oluşturabilir.

Farklı pozlarla yüz görüntüsü oluşturmanın sonuçları
Makale 8 Poz Temelli İnsan Görüntü Sentezi İçin Çok Aşamalı Çekişmeli Kayıplar
Chenyang Si, Wei Wang, Liang Wang, Tieniu Tan
Tek bir resmin çoklu görüntülü görüntü sentezi, bilgisayarla görmede çok önemli ve zorlu bir sorundur ve insanlar için çok görüntülü görüntü sentezi, insan davranışını anlamada önemli bir uygulama değerine sahiptir. İnsan çoklu-görüş sentezinin kullanılması, bilgisayar görüşünde çapraz görüş davranışı tanıma, çapraz-görüntü yaya yeniden tanıma vb. Gibi çapraz-görüş problemlerini etkili bir şekilde çözebilir. İnsan duruşlarının değişkenliği nedeniyle, insanların çoklu görüntülü görüntü sentezi, katı nesnelerin (arabalar, sandalyeler vb.) Çoklu bakış açılı sentezinden daha zordur. İnsan vücudunun kilit noktalarına dayanan çoklu görüntülü insan vücudu görüntü sentez algoritmasında çok aşamalı bir kayıp önleme işlevi öneriyoruz.Bu algoritma, yüksek kaliteli çok görüntülü insan vücudu görüntüleri oluşturabilir ve sentezlenen kişinin duruşunu üç boyutlu uzayda tutarlı tutabilir. Yüksek kaliteli görüntüler üretebilmek için, düşük boyutlu insan vücudu yapısından ön plana ve son olarak sentetik arka plana kadar çok aşamalı bir görüntü oluşturma modeli öneriyoruz.Ortalama kare hata kaybı işlevinden kaynaklanan görüntü bulanıklığı sorununu çözmek için çok aşamalı kayıp önleme işlevi kullanıyoruz . Algoritmamız şekilde gösterilmiştir:
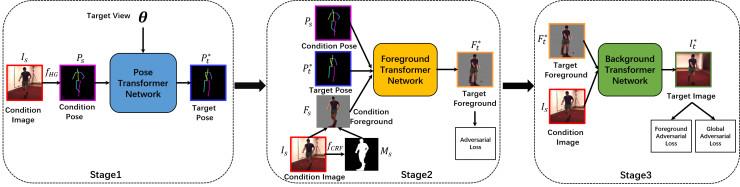
Poz temelli çok aşamalı çekişmeli öğrenmeye dayalı insan vücudu imaj sentezi ağı çerçevesi
Kağıt 9 Kişi Yeniden Tanımlama için Maske Rehberli Kontrastif Dikkat Modeli
Chunfeng Song, Yan Huang, Wanli Ouyang ve Liang Wang
Yayaların yeniden tanımlanması, önemli ve zorlu bir klasik bilgisayar görme görevidir. Genellikle kamera tarafından toplanan yaya görüntüsü dağınık bir arka plan içerir ve görüntüdeki yaya genellikle çeşitli duruş ve perspektiflere sahiptir.Bu çeşitliliğin neden olduğu zorluklar önceki çalışmalarda tam olarak çözülememiştir. Yukarıdaki problemleri çözmek için, ikili yaya segmentasyonu kontur haritasını ek bir girdi olarak sunduk ve renkli görüntü ile dört kanallı yeni bir girişte sentezledik ve ardından arka plandan bağımsız öğrenmek için segmentasyon kontur haritasına dayalı bir kontrast dikkat modeli tasarladık. Yaya özellikleri. Bu temelde, sırasıyla tüm görüntü alanı, yaya vücut alanı ve arka plan alanından gelen özellikleri sınırlandırmak için bölgesel düzeyde üçlü bir kayıp işlevi öneriyoruz Önerilen kayıp işlevi, tüm görüntü alanından ve yaya gövdesi alanından gelmesini sağlayabilir. Özellikleri, özellik alanına yakın ve arka plan alanından uzaktır ve sonunda arka planı kaldırma etkisini elde eder. Önerilen yöntem, üç yaya yeniden tanımlama veri setinde doğrulanmış ve şu anda en iyi performansı elde etmiştir.
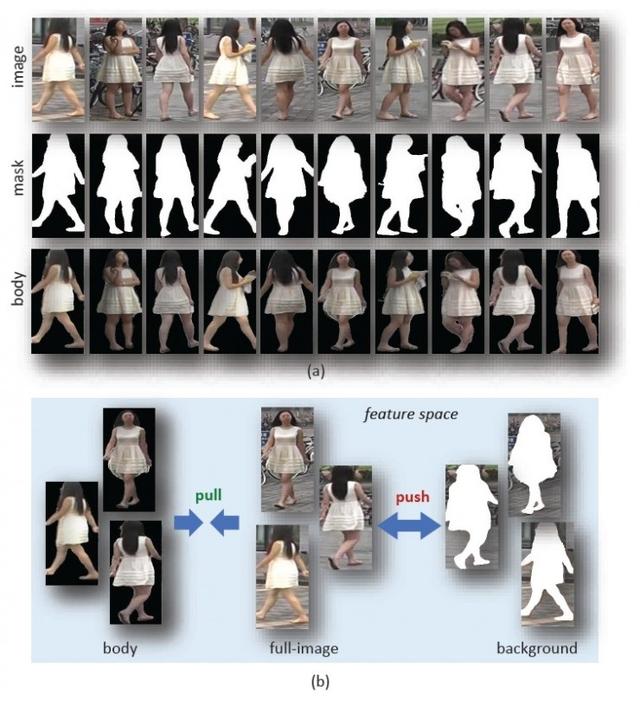
İkili bölütleme konturunun ve bölge düzeyinde üçlü kısıtlamaların şematik diyagramı
Kağıt 10 M ^ 3: Video Altyazı Oluşturma için Çok Modlu Bellek Modellemesi
Junbo Wang, Wei Wang, Yan Huang, Liang Wang, Tieniu Tan
Video açıklaması, vizyonu ve dili anlamanın çok önemli bir parçasıdır, ancak aynı zamanda çok zorlayıcı bir görevdir. İnsan-bilgisayar etkileşimi, video alma ve görme engelliler için videoları yeniden anlatma gibi birçok pratik uygulama değerine sahiptir. Bu sorunu çözmek için, video açıklaması için çok modlu bir bellek modeli öneriyoruz Bu model, uzun menzilli görsel metin bağımlılığını simüle etmek ve video açıklamasında küresel vizyon hedefine daha fazla rehberlik etmek için vizyon ve metin tarafından paylaşılan bir bellek hafızası kurar. endişesi. Nöral Turing Makinesi Modeli prensibinden dersler çıkaran model, çoklu okuma ve yazma işlemleri aracılığıyla videolar ve cümlelerle etkileşime giriyor ve görsel ve dil modalitelerinden gelen bilgileri depolamak için harici bir bellek ekliyor. Aşağıdaki şekil, video açıklaması için çok modlu bellek modellemesinin genel çerçevesini gösterir.
Bu çerçeve, üç temel modül içerir: evrişimli ağlara dayalı bir video kodlayıcı, çok modlu bir bellek belleği ve LSTM'ye dayalı bir metin kod çözücü. (1) Evrişimli ağa dayalı video kodlayıcı, önce anahtar karelerin veya bölümlerin özelliklerini çıkarmak için önceden eğitilmiş 2B veya 3B evrişimli ağ modelini kullanır ve daha sonra geçerli kelimenin en alakalı görsel temsilini seçmek için zamanlama dikkat modelini kullanır ve (2) LSTM tabanlı metin kod çözücü, cümlelerin üretimini modellemek için LSTM modelini kullanır.Geçerli sözcüğün yalnızca önceki anın gizli temsiline değil, aynı zamanda bellekten okunan bilgiye de bağlı olduğunu öngörür. Benzer şekilde, güncellenmiş gösterimi bellek deposuna yazacaktır. (3) Çok modlu bellek depolaması, video kodlayıcılar ve metin kod çözücülerle etkileşim kurmak için bir bellek depolama matrisi içerir, örneğin, LSTM kod çözücülerinden gizli temsiller yazmak ve kod çözücüler için bellek içeriğini okumak. Her yazma işlemi çok modlu belleği güncelleyecektir. Son olarak, önerilen modeli iki genel veri seti (MSVD ve MSR-VTT) üzerinde değerlendirdik. Deneysel sonuçlar, önerilen modelin hem BLEU hem de METEOR göstergelerinde mevcut birçok en iyi sonucu aştığını göstermektedir.

Video açıklaması için çok modlu bellek modeli mimarisi
Kağıt 11 Hızlı Uçtan Uca Eğitilebilir Kılavuzlu Filtre
Huikai Wu, Shuai Zheng, Junge Zhang, Kaiqi Huang
Ortak örnekleme için yeni bir derin öğrenme modülü öneriyoruz - Kılavuzlu Filtreleme Katmanı. Bu modül, geleneksel Görüntü Kılavuzlu Filtreleme algoritmasını, geriye yayılabilen ve diğer modüllerle birlikte eğitilebilen bir derin öğrenme birimi olarak modeller.Ayrıca, esnekliği iyileştirmek için uyarlamalı olarak öğrenilebilen bir Rehberlik Haritası sunar. . Orijinal evrişimli sinir ağı ile birleştirilerek, kılavuzlu filtre ünitesi yoğun tahmin görevlerinde (Yoğun Tahmin Görevi) yaygın olarak kullanılabilir ve daha hızlı, daha yüksek doğruluk ve daha az bellek alanı elde edebilir. Deneyler, kılavuzlu filtre ünitesinin birçok görüntü işleme görevinde en iyi performansı elde edebileceğini ve 10 ila 100 kat hız artışı sağlayabileceğini kanıtlamıştır. Bilgisayarla görmedeki birçok yoğun eşleştirme görevinde, bu modül aynı zamanda önemli performans iyileştirmeleri sağlayabilir. Kod ve makale,
ps: //github.com/wuhuikai/DeepGuidedFilter.

Evrişimli sinir ağı ve önerilen kılavuzlu filtre birimi kullanılarak görüntüden görüntüye dönüşümün sonucunu görüntüleyin