"Alpha Dog" yeniden gelişiyor! Genel algoritma AlphaZero için birkaç satranç türünü fethetmek ne kadar zor!
Leifeng.com AI Technology Review raporu: DeepMind sessizce yeni bir makale yayınladı ve bir "AlphaZero" tanıttı. İlk başta DeepMind'in soğuk pirinç pişirmeyi de öğrendiğini düşünüyorduk Sonuçta, AlphaGo Zero "Sıfırdan Öğrenmek" kitabı Ekim ayında yayınlandı ve herkes bunu defalarca tartıştı. Ama daha yakından bakabilirim, bu sefer AlphaZero sadece Go oynayabilen bir önceki yapay zeka değil. Evrenseldir. Ayrıca satranç ve Japon satrancı da oynayabilir, bu yüzden ismindeki "Go" kaldırılır; sadece bu değil, Go geçen sefer AlphaGo Zero'dan bile daha iyi oynadı. AlphaGo Zero'yu öğrendikten sonra, Ke Jie zaten insanoğlunun gereksiz olduğundan yakınıyordu.Bu sefer bir grup Go oyuncusu satranç oyuncularını tekrar ağlamaya yönlendirebilir.
Teknik açıdan, genel bir pekiştirmeli öğrenme modeli, yeterince basit ve Go oynamaya adanmış önceki modellerden daha iyi performans gösteriyor? "Bedava öğle yemeği yok" kanunu geçersiz mi?

AlphaGo'nun evriminde, DeepMind mühendislerinin derin pekiştirmeli öğrenmenin doğası hakkındaki düşüncelerine ve girişimlerine tanık olduk. Önceden bilgi gerektirmeyen, kaynak tüketimini azaltan, eğitim hızını artıran vb. Sürekli optimizasyonun getirdiği sürekli optimizasyonu da gördük. ilerleme. Yapay özellikler kullanmaktan, dağ savaşında Fan Hui'yi yenmekten, ilk makaleyi yayınlayan AlphaGo Fan, 50 TPU üzerinde çalışan Li Shishi 4: 1'i yenmeye ve yayınlanan belgesel AlphaGo Lee'den Wuzhen 3: 0'a kadar. Ke Jie'yi yendikten ve AlphaGo fantezisini yalnızca 4 TPU ile bozguna uğratan tüm AlphaGo Masters'ı parçaladıktan sonra, AlphaGo Zero'nun AlphaGo Ustasını geçmeye devam etmek için kendi kendimize öğretilenlere güvenerek yapay özellikleri ve tüm insan ustalarını terk etmeyi bekledik. AlphaGo Zero'nun mükemmel God of Go olduğunu hissettiğimizde, DeepMind beklenmedik bir şekilde bu daha genel amacı, çeşitli satranç oyunlarını oynayabilen ve Go'da performansı artıran genel bir takviye öğrenme modelini getiriyor. "AlphaZero".
AlphaGo Zero'nun son birkaç sürümü herkese aşina olmalı, ancak yine de yeni AlphaZero ile kolay karşılaştırma için kısaca gözden geçiriyoruz. AlphaGo her zaman sınırlı bir Monte Carlo Ağaç Araması (MCTS) derinliğine sahip olmuştur ve ardından bir sonraki adımı tahmin etmek ve mevcut durumu değerlendirmek için esas olarak strateji ağına ve değer ağına güvenmektedir. AlphaGo'nun önceki sürümünde, politika ağı ve değer ağı iki farklı derin sinir ağıdır.Sıfır versiyonunda, aynı ResNet'in iki set çıkışı vardır; AlphaGo Zero'nun önceki sürümlerinde, durumun yüksek bir duruma dönüştürülmesi gerekir. Katmanın yapay özellikleri daha sonra ağın girdisi olarak kullanılır.İnsan oyun kaydını öğrenmek ve daha sonra kendi kendine oynamanın pekiştirmeli öğrenmesine dönüştürmek gerekir.Rastgele simülasyon için ayrı bir hızlı hareket ağı vardır.AlphaGo Zero, ağın girişi olarak doğrudan konum durumunu kullanır. Rastgele ağ ağırlıkları doğrudan takviye öğrenmeyi başlatır, hızlı yürüme ağını terk eder ve yürümeyi simüle etmek için doğrudan ana sinir ağını kullanır. AlphaGo Zero'nun fikirlerinin ve model yapısının büyük ölçüde basitleştirildiği, bu da daha hızlı eğitim ve koşu hızı ve daha yüksek satranç gücü getirdiği görülebilir. Ve bu kadar basit bir model çok iyi sonuçlar verebilir, bu yüzden araştırmacılar AlphaGo Zero'ya hayran kaldı.
Daha fazlasına nasıl gidilir
Aslında, satranç için AI yazma sürecinde, insanlar her zaman her satrancın farklı özelliklerine göre bazı özel beceriler tasarlamışlardır. İki strateji ve değer ağını uygulayan AlphaGo Zero'daki kalıntılara sahip CNN ağı, aslında Go'nun bazı özelliklerinden yararlanır: Oyunun kuralları, evrişimli sinir ağının paylaşılan ağırlığı ile tutarlı olan dönüşümsel değişmezdir; Qi değeri, evrişimli ağın yerel yapısıyla tutarlıdır; tüm satranç tahtası rotasyonel ve simetriktir ve mevcut veri geliştirme ve birleştirme yöntemleri eğitimde rahatlıkla kullanılabilir; eylem alanı basittir ve yalnızca tek bir konuma yerleştirilmesi gerekir. Satranç taşlarının kategorisi; sonuç alanı basittir, beraberlik olmadan kazanır veya kaybeder. Yukarıdaki tüm özellikler AlphaGo Zero'nun sorunsuz ve hızlı bir şekilde eğitilmesine yardımcı olabilir.
Şimdi, DeepMind araştırmacıları AlphaGo Zero'yu daha farklı hareketler oynayabilen daha genelleştirilmiş bir algoritmaya dönüştürmek istediklerinde, bazı işleme yöntemlerini yeniden düşünmeleri gerekiyor. Örneğin, satranç ve Japon satrançta, hareketin yüksekliği mevcut taşın konumuna bağlıdır ve her bir taş farklı hareketlere sahiptir; satranç tahtasının durumu, satrancın yönünü etkileyecek şekilde dönmez ve aynasızdır. ; Satranç beraberliğe sahip olabilir; Japon satrancı ele geçirilen rakibin taşlarını tahtaya bile koyabilir. Go ile karşılaştırıldığında bu özellikler, hesaplama sürecini AlphaGo Zero gibi CNN ağları için daha karmaşık ve daha az uygun hale getirir. Buna karşılık, 2016 Dünya Satranç Algoritma Şampiyonası'nın (TCEC) şampiyonu Stockfish, insan ustalarının manuel özelliklerini, ince ayarlı ağırlıkları, alfa-beta budama algoritmasını, ayrıca büyük ölçekli sezgisel arama ve birçok özelleşmiş Satranç adaptasyon programı. İnsan Japon Go şampiyonunu yenen en güçlü algoritma Elmo da benzer.
AlphaZero, AlphaGo Zero'nun genelleştirilmiş evrimsel bir sürümüdür. AlphaGo Zero'nun yapay özellikler gerektirmeyen özelliklerini korumaya devam eder, takviye öğrenmeyi sıfırdan gerçekleştirmek için derin sinir ağları kullanır ve Monte Carlo ağaç aramasının özelliklerini birleştirir ve ardından ağı azaltmak için ağ parametrelerini günceller Strateji ağının çıktı eylemi ile Monte Carlo ağacının arama olasılığı arasındaki benzerliği en üst düzeye çıkarırken, tahmin edilen oyun sonucu ile gerçek sonuç arasındaki hata.
AlphaZero ve AlphaGo Zero arasındaki belirli farklar aşağıdaki gibidir:
-
AlphaGo Zero, kazanma oranını tahmin edecek ve ardından yalnızca kazanma ve kaybetmenin iki sonucunu dikkate alan kazanma oranını optimize edecektir; AlphaZero, oyunun sonucunu tahmin edecek ve ardından bir beraberlik ve hatta bazı olası sonuçları içeren tahmin edilen sonuca ulaşma olasılığını optimize edecektir.
-
Go kuralları döndürme ve aynalama ile değişmez olduğundan, özellikle Go için tasarlanmış AlphaGo Zero ve genel AlphaZero'nun farklı uygulama yöntemleri vardır. AlphaGo Zero eğitiminde, her oyun için 8 simetrik geliştirme verisi yapılacak; Monte Carlo ağaç aramasında, oyun önce rastgele rotasyon veya ayna dönüşümünden geçecek ve ardından sinir ağı tarafından değerlendirilecek, böylece Monte Carlo değerlendirmesi Farklı önyargıların ortalaması alınabilir. Hem satranç hem de Japon satrancı asimetriktir ve yukarıda bahsedilen simetriye dayalı yöntemler kullanılamaz. Dolayısıyla AlphaZero, eğitim verilerini geliştirmediği gibi Monte Carlo ağaç aramasında da oyunu değiştirmez.
-
AlphaGo Zero'da, kendi kendine oynayan oyun, önceki tüm yinelemelerde en iyi performans gösteren sürümden oluşturulmuştur. Her eğitim yinelemesinden sonra, oyuncunun yeni sürümünün performansı, orijinal en iyi performans gösteren sürümle karşılaştırılmalıdır; yeni sürüm orijinal sürümü% 55'in üzerinde bir kazanma oranıyla geçebilirse, bu yeni sürüm haline gelecektir. Yeni "en iyi performans gösteren sürüm" ve ardından onu sonraki yineleme optimizasyonu için yeni bir oyun oluşturmak üzere kullanın. Buna karşılık, AlphaZero her zaman yalnızca sürekli olarak optimize edilmiş bir sinir ağına sahiptir.Kendi kendine eşleştirme satranç oyunu da ağ tarafından en son parametrelerle üretilir.Artık değerlendirmeden önce "en iyi performans gösteren sürümün" ortaya çıkmasını beklemiyor. Ve yineleme. Bu aslında kötü bir sonuçla eğitim riskini artırır.
-
AlphaGo Zero'daki arama kısmının hiperparametreleri, Bayes optimizasyonu ile elde edilir. AlphaZero, tüm satranç türleri için aynı hiperparametre setini doğrudan kullanır ve her satranç türü için ayrı bir ayarlama yapılmaz. Tek istisna, eğitim sırasında stratejinin önceki sürümüne eklenen gürültü miktarıdır.Bu, ağın yeterli keşif yeteneklerine sahip olmasını sağlamak içindir; gürültünün boyutu, her satranç türü için tipik uygulanabilir hareketlerin sayısı ile orantılı olarak ölçeklenir.
AlphaZero gücünü açığa çıkarır
Yazarlar, sırasıyla üç AlphaZero satranç, Japon satrancı ve Go örneğini eğitmek için aynı algoritma ayarlarını, ağ mimarisini ve hiper parametreleri (sadece az önce bahsedilen gürültü seviyesi) kullandılar. Eğitim rastgele başlatılan parametrelerle başlar. Toplam adım sayısı 700.000 adımdır ve mini parti boyutu 4096'dır; kendi kendine eşleşmeler oluşturmak için 5000 birinci nesil TPU kullanılır ve sinir ağlarını eğitmek için 64 ikinci nesil TPU kullanılır (Leifeng.com) AI Teknolojisi İncelemesi Not: İkinci nesil TPU'nun bellek bant genişliği daha yüksektir).

Standart olarak Elo puanlarını kullanan AlphaZero, 700.000 hamlenin tümünü tamamlamadan önce önceki en iyi satranç, Japon satrancı ve Go programları Stockfish, Elmo ve AlphaGo Zero'yu geride bıraktı. AlphaGo Lee versiyonunu 8 saatlik eğitim süresinde binlerce TPU yardımıyla geçebileceğini söylemek mantıklı ... Yaklaşık 400.000 adımlık eğitimin ardından AlphaGo Zero'yu önemli bir farkla geçmeye devam etmek hala şaşırtıcı. AlphaZero'da bazı (muhtemelen) avantajlı ayrıntılardan vazgeçtikten sonra, Go konusunda uzmanlaşmış, zaten mükemmel görünen AlphaGo Zero'yu genel bir algoritma olarak yendi. "Öğle yemeği yok" yasası burada geçici olarak geçersiz görünüyor. aynı.
Belgede, tabii ki, DeepMind ayrıca tam eğitimli AlphaZero'nun gerçek yarışmalarda, sırasıyla 100 oyunda Stockfish, Elmo ve AlphaGo Zero (eğitim süresi 3 gün) ile rekabet etmesine izin verdi ve adım başına düşünme süresi bir dakika ile sınırlı; AlphaGo Zero ve AlphaZero her ikisi de 4 TPU ile donatılmış tek bir sunucuda çalışır.
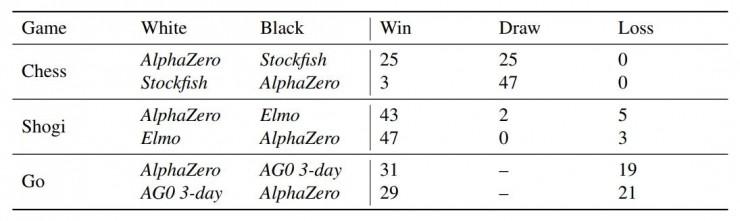
Sonuç şaşırtıcı değil. AlphaZero, Stockfish'e karşı satrançta bir oyun kaybetmedi ve Japonya toplamda 8 oyun kaybetti. AlphaGo Zero ayrıca AlphaGo Zero'ya karşı% 60 kazanma oranı kazandı.
AlphaZero ve AlphaGo'nun çeşitli sürümlerinde, algoritmanın derin sinir ağlarının yardımıyla Monte Carlo ağaç aramasının ölçeğini büyük ölçüde azalttığını hepimiz biliyoruz. Stockfish ve Elmo ile karşılaştırıldığında, bu gelişme oldukça açıktır: AlphaZero'nun satranç için saniyede yalnızca 80.000 pozisyon araması gerekirken, Stockfish'in sayısı 70 milyon; AlphaZero, Japon satrancı için saniyede 40.000 pozisyon gerektirir. Elmo'nun rakamı 35 milyon; aynı zamanda AlphaZero da satrançta çok büyük bir avantaj elde etti. Buradaki derin sinir ağı, seçici olarak daha fazla potansiyel hareket hakkında düşünebilen insanlar gibidir. Makale ayrıca düşünme süresinin verimliliğini de test etti. Stockfish ve Elmo'yu 40 ms düşünme süresi ile ölçüt olarak alan AlphaZero'nun satranç gücü, düşünme süresi ile daha hızlı artar. DeepMind araştırmacıları, satranç görevlerinde alfa-beta budama algoritmasının Monte Carlo ağaç aramasından daha iyi olduğuna dair önceki inancın doğru olup olmadığını sorgulamaya bile başladı.

Yazarlar sonunda AlphaZero'nun insanlara karşı öğrendiği satranç bilgisini doğruladılar. İnsanların çevrimiçi satranç kayıtlarından 100.000'den fazla kez görünen ortak açılış formları buldular ve AlphaZero'nun bu açılışları bağımsız olarak da öğrenebildiğini ve genellikle kendi kendine oyunda kullanıldığını buldular. Dahası, oyun insanlar için yaygın olarak kullanılan bu açılış formatlarıyla başlarsa, AlphaZero her zaman Stockfish'i yenebilir, bu da AlphaZero'nun gerçekten de satrançtaki çeşitli değişiklikleri öğrendiğini gösterir.
sonuç olarak
İnsanlar satrancı yapay zeka araştırmasının önemli bir seviyesi olarak gördüklerinden beri, araştırmacılar tarafından geliştirilen satranç algoritmaları neredeyse her zaman kaçınılmaz yapay özelliklere ve belirli satranç için belirli optimizasyonlara sahiptir. Şimdi, yapay özellikler gerektirmeyen, herhangi bir insan satranç kaydı, hatta herhangi bir özel optimizasyon gerektirmeyen genel pekiştirmeli öğrenme algoritması AlphaZero nihayet ortaya çıktı ve önceki en iyi algoritmayı ve hatta insan dünya şampiyonunu aşmak için sadece birkaç saatlik eğitim süresi gerekiyor. Algoritmaların ve bilgi işlem kaynaklarının zaferi, insanlığın en önemli araştırma sonucudur. DeepMindın çeşitli sorunları çözebilen genel yapay zeka vizyonu bize gittikçe yaklaşıyor gibi görünüyor.
Kağıt adresi: https://arxiv.org/pdf/1712.01815.pdf
Lei Feng.com AI Technology Review tarafından derlenmiştir.