Makine öğrenmiyor: o zamandan beri evrişimli sinir ağını (CNN) anlıyor
Makine www.jqbxx.com'u öğrenmiyor: Derin toplu makine öğrenimi, derin öğrenme algoritmaları ve teknik mücadele
Bugünden itibaren resmen evrişimli sinir ağını açıklamaya başladı. Bu zaten anlayamadığım bir şey, çünkü adı çok "gelişmiş". İnternette "evrişimin ne olduğunu" tanıtmak için yazılmış çeşitli makaleler özellikle dayanılmaz. Wu Enda'nın çevrimiçi dersini dinledikten sonra aniden anladı ve sonunda bu şeyin ne olduğunu ve neden olduğunu anladı. Burada CNN'i açıklamak ve bazı ilginç uygulamaları hayata geçirmek için muhtemelen 6 ~ 7 makale kullanacağım. Okuduktan sonra herkes sevdiği bir şeyi yapabilmelidir.
1. Giriş Sınır Algılama
En basit örneğe bir göz atalım: "kenar algılama". 8 × 8 boyutunda böyle bir resmimiz olduğunu varsayalım:

Resimdeki sayı, o konumdaki piksel değerini temsil eder.Piksel değeri ne kadar büyükse, rengin o kadar parlak olduğunu biliyoruz, bu nedenle örnek olarak sağdaki küçük pikseli daha koyu olarak boyarız. Resmin ortasındaki iki rengi ayıran çizgi, tespit etmek istediğimiz sınırdır.
Bu sınır nasıl belirlenir? Böyle bir filtreyi (çekirdek de denir) 3 × 3 boyutunda tasarlayabiliriz:

Daha sonra, bu filtreyi resmimizi "kaplamak", filtre kadar geniş bir alanı kaplamak, karşılık gelen öğeleri çarpmak ve sonra toplamak için kullanırız. Bir alanı hesapladıktan sonra, diğer alanlara gidin ve ardından orijinal resmin her köşesi kaplanana kadar hesaplayın. Bu süreç "evrişim" dir. (İşlem evrişiminin matematikte neyi ifade ettiği umurumuzda değil. Sadece CNN'de nasıl hesaplandığını bilmemiz gerekiyor.) Buradaki "kayma" bir adım boyutu içerir. Adım boyutumuz 1 ise, Ardından, bir yeri kapladıktan sonra, bir ızgarayı hareket ettirin, toplamda 6 × 6 farklı alanın kaplanabileceğini bilmek kolaydır.
Ardından, bu 6 × 6 bölgelerin evrişim sonuçlarını bir matriste birleştiriyoruz:
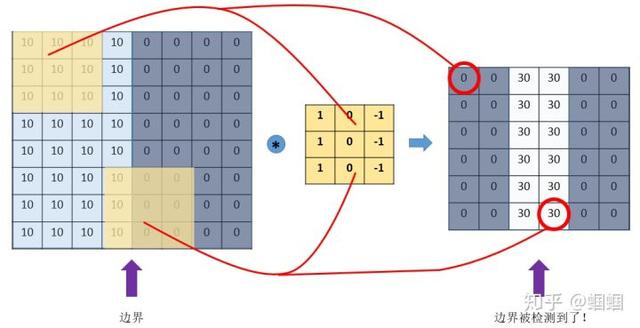
Eh? ! Ne buldun? Bu resimde ortadaki renk açık, her iki taraftaki renk koyu Bu da orjinal resmimizin ortasındaki bordürün buraya yansıdığını gösteriyor!
Yukarıdaki örnekten, görüntü ile kıvrımlı olmasını sağlayacak belirli bir filtre tasarlayarak görüntüdeki sınır gibi belirli özellikleri belirleyebileceğimizi bulduk. Yukarıdaki örnek dikey sınırı tespit etmektir, ayrıca yatay sınırı tespit edecek şekilde tasarlayabiliriz, sadece filtreyi 90 ° döndürmeniz yeterlidir. Diğer özellikler için, teoride, dikkatli bir tasarımdan geçtiğimiz sürece, her zaman uygun bir filtre tasarlayabiliriz.
CNN'miz (evrişimli sinir ağı) temel olarak görüntü tanıma ve diğer işlevleri gerçekleştirmek için yerel özelliklerden genel özelliklere kadar özellikleri sürekli olarak çıkarmak için filtreler kullanır.
Öyleyse soru şu ki, bu kadar çok çeşit filtreyi nasıl tasarlayabiliriz? Her şeyden önce, büyük bir itme görüntüsü için hangi özellikleri tanımlamamız gerektiği konusunda kesin olarak net değiliz. İkincisi, hangi özelliklerin orada olduğunu bilsek bile, ilgili filtreyi tasarlamak kolay olmayabilir. Binlerce olabilir.
Aslında, sinir ağlarını öğrendikten sonra, bu filtrelerin tasarlamamıza hiç ihtiyaç duymadığını biliyoruz.Her filtredeki sayılar parametre değildir.Makinenin bunları büyük miktarda veriyle "öğrenmesine" izin verebiliriz. Parametreler. Bu CNN'in prensibidir.
İki, CNN'nin temel kavramı
1. tamponlama
Yukarıdaki girişten, orijinal görüntünün filtre evrişiminden sonra (8,8) 'den (6,6)' ya kadar küçüldüğünü bilebiliriz. Tekrar yuvarladığımızı varsayalım, boyut (4,4) olur.
Sorun ne? İki ana sorun vardır: -Görüntü her kıvrıldığında, görüntü küçültülür, böylece birkaç kez döndürülemez ve kaybolur; -Görüntünün ortasındaki noktalarla karşılaştırıldığında, görüntünün kenarındaki noktalar evrişimde daha seyrek hesaplanır. Bu durumda, uç bilgileri kaybetmek kolaydır.
Bu sorunu çözmek için padding kullanabiliriz. Her evrişimden önce, resmin etrafına bir boşluk çemberi doldururuz, böylece evrişimden sonraki resim orijinali kadar büyük olur ve aynı zamanda orijinal kenar da daha fazla hesaplanır.

Örneğin, (8,8) 'in resmini (10,10)' a eklersek, (3,3) 'ün filtresinden sonra, (8,8) değişmeyecektir.
Yukarıdaki "evrişimden sonra boyutu değiştirmeden yapma" yöntemini "Aynı" yöntem olarak adlandırıyoruz ve herhangi bir boşluk içermeyen "Geçerli" yöntem olarak adlandırılıyor. Bu, bazı çerçeveleri kullanırken ayarlamamız gereken hiperparametredir.
2. adım adım uzunluğu
Daha önce tanıttığımız evrişimlerde varsayılan adım boyutu 1'dir, ancak aslında adım boyutunu diğer değerlere ayarlayabiliriz. Örneğin (8,8) girdisi için (3,3) filtresini kullanıyoruz, adım = 1 ise çıktı (6,6); adım = 2 ise çıktı (3,3); ( Buradaki örnek, sürekli aşağı yuvarlama dışında pek iyi değildir)
3. paylaşım
Bu havuzlama, belirli bir alanın ana özelliklerini çıkarmak ve modelin aşırı sığmasını önlemek için parametre sayısını azaltmaktır. Örneğin, aşağıdaki MaxPooling 2 × 2 pencere kullanır ve adım = 2 alır:

MaxPooling'e ek olarak, adından da anlaşılacağı gibi, o alanın ortalamasını almak için AveragePooling var.
4. Çok kanallı (kanallar) resimlerin evrişimi
Bunun ayrıca belirtilmesi gerekiyor. Renkli görüntüler genellikle üç RGB kanalına sahiptir, bu nedenle genellikle giriş verilerinin üç boyutu vardır: (uzunluk, genişlik, kanal). Örneğin, 28 × 28 RGB resim, boyut (28,28,3).
Önceki girişte, giriş görüntüsü 2 boyutlu (8, 8), filtre (3, 3) ve çıktı da 2 boyutlu (6, 6).
Giriş resmi (8,8,3) gibi üç boyutlu ise (yani bir kanal daha), bu zamanda filtremizin boyutu (3,3,3), sonuncusu olacaktır. Boyut, giriş kanalı boyutuyla tutarlı olmalıdır. Şu anda, evrişim, çarpıldıktan sonra üç kanalın tüm elemanlarının toplamıdır, yani önceki 9 ürünün toplamıdır ve şimdi 27 ürünün toplamıdır. Bu nedenle çıktı boyutu değişmeyecektir. Yine de (6,6).
Ancak genel olarak aynı anda evrişim yapmak için daha fazla filtre kullanacağız Örneğin, aynı anda 4 filtre kullanırsak çıktı boyutu (6,6,4) olacaktır.
Yukarıdaki süreci göstermek için özellikle aşağıdaki resmi çizdim:

Şekildeki giriş görüntüsü (8,8,3), 4 adet filtre var, hepsi (3,3,3) büyüklüğünde ve çıkan çıktı (6,6,4). Bence bu resim çok net bir şekilde çizildi ve iki anahtar sayı olan 3 ve 4'ün nasıl geldiğini gösterdi, bu yüzden ayrıntılı olmayacağım (bu çizim en az 40 dakika sürdü).
Aslında, CNN'e bakmak için daha önce öğrendiğimiz sinir ağı notasyonunu uygularsak,
- Giriş resmimiz X, şekil = (8,8,3); 4 filtre aslında tanrı altın ağının ilk katmanının W1 ,, şekil = (3,3,3,4) parametreleridir, bu 44 filtre; çıktımız Z1, şekil = (6,6,4); aslında relu gibi bir aktivasyon fonksiyonu olmalı, aktivasyondan sonra Z1 A1 olur, şekil = (6,6,4 );
Bu nedenle, önceki şekilde, bir aktivasyon işlevi ekledim ve karşılık gelen parçayı aşağıdaki gibi sembollerle işaretledim:
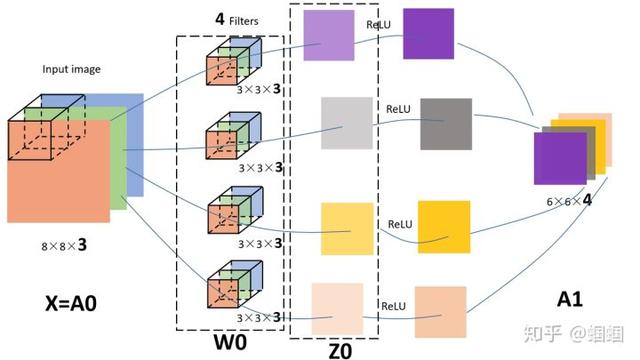
Böyle güzel bir resim toplamaya değer
Üçüncüsü, CNN'nin yapısı
Yukarıda evrişimin, havuzlamanın ve doldurmanın nasıl yapıldığını zaten biliyoruz. Şimdi, 3 katman içeren CNN'nin genel yapısına bir göz atalım:
1. Evrişimli katman (CONV)
Filtreler ve aktivasyon fonksiyonlarından oluşur. Genel olarak ayarlanacak hiperparametreler, filtrelerin sayısını, boyutunu, adım uzunluğunu ve dolgunun "geçerli" veya "aynı" olup olmadığını içerir. Tabii ki, hangi aktivasyon işlevinin seçileceğini de içerir.
2. Havuzlama katmanı (POOL)
Burada öğrenmemiz gereken bir parametre yoktur, çünkü buradaki parametrelerin tümü bizim tarafımızdan belirlenir, Maxpooling veya Ortalama havuzlama. Belirtilmesi gereken hiperparametreler, Maks veya ortalama olup olmadığını, pencere boyutunu ve adım boyutunu içerir. Genellikle, Maxpooling'i daha sık kullanırız ve genellikle (2, 2) boyutunda ve adım boyutu 2 olan bir filtre alırız. Bu şekilde, havuzlamadan sonra, giriş uzunluğu ve genişliği 2 kat azalacak ve kanallar değişmeden kalacaktır.
3. Tamamen Bağlı katman (FC)
Bundan daha önce bahsedilmedi çünkü bu, en aşina olduğumuz adam, daha önce öğrendiğimiz sinir ağındaki en yaygın katman olan bir dizi nöron. Bu katmanın her birimi, bir önceki katmanın her bir birimine bağlı olduğu için buna "tam bağlantı" denir. Burada belirtilecek hiperparametreler, nöron sayısından ve aktivasyon işlevinden başka bir şey değildir.
Daha sonra, CNN hakkında algısal bilgiler edinmek için bir CNN'e rasgele bakarız:

Yukarıdaki CNN, rastgele düşündüğüm bir CNN. Yapısı kullanılabilir: X-- > CONV (relu) - > MAXPOOL-- > CONV (relu) - > FC (relu) - > FC (softmax) - > Y temsil edecek.
Burada açıklanması gereken, birkaç kez evrişim ve havuzlamadan sonra, nihayet çok boyutlu verileri "düzleştireceğiz", yani (yükseklik, genişlik, kanal) verilerini yükseklik x genişlik uzunluğuna sıkıştıracağız. × kanal tek boyutlu bir dizidir ve daha sonra FC katmanına bağlanır, bundan sonra sıradan bir sinir ağından farklı değildir.
Şekilde de görebileceğiniz gibi, ağın derinleşmesiyle görüntülerimiz (tam anlamıyla ortadakilere görüntü denemez, ancak kolaylık sağlamak için diyelim ki) küçülüyor, ancak kanallar büyüyor ve büyüyor. . Şekildeki temsil, bize bakan kuboidin alanı küçülüyor, küçülüyor, ancak uzunluk artıyor ve uzuyor.
Dördüncü, evrişimli sinir ağı VS. geleneksel sinir ağı
Aslında, şimdi geriye dönüp baktığımızda, CNN daha önce öğrendiğimiz sinir ağından çok da farklı değil. Geleneksel sinir ağı, aslında birden çok FC katmanının üst üste binmesidir. CNN, FC'yi CONV ve POOL olarak değiştirmekten başka bir şey değildir, bu da nöronlardan oluşan geleneksel katmanı filtrelerden oluşan bir katmana dönüştürmektir.
Peki bu neden değişiyor? faydası nedir? Özellikle iki nokta var:
1. Parametre paylaşım mekanizması (parametre paylaşımı)
Geleneksel sinir ağı katmanını ve filtrelerden oluşan CONV katmanını karşılaştıralım: Görüntümüzün 8 × 8 boyutunda, yani 64 piksel olduğunu varsayalım, 9 birim ile tam bağlantılı bir katman kullandığımızı varsayalım:

Bu katman için kaç parametreye ihtiyacımız var? 64 × 9 = 576 parametreye ihtiyaç duyar (ofset terimi b dikkate alınmadan). Çünkü her bağlantının bir w ağırlığına ihtiyacı vardır.
O halde 9 birimlik bir filtrenin nasıl olduğuna bakalım:

Aslında, ona bakmanıza gerek yok.Birkaç birim için sadece birkaç parametre vardır, bu nedenle toplam 9 parametre vardır!
Çünkü farklı bölgeler için hepimiz aynı filtreyi paylaşıyoruz, dolayısıyla aynı parametre setini paylaşıyoruz. Bu da mantıklıdır.Önceki açıklamadan, filtrenin özellikleri tespit etmek için kullanıldığını biliyoruz Normal şartlar altında, bu özelliğin birden fazla yerde, örneğin birden fazla görüntü olabilen "dikey sınır" gibi görünmesi muhtemeldir. Görünürse, sadece aynı filtreyi paylaşmamız makul değil, aynı zamanda yapılmalıdır.
Parametre paylaşım mekanizmasının ağımızın parametre sayısını büyük ölçüde azalttığı görülebilir. Bu şekilde, daha iyi bir modeli eğitmek için daha az parametre kullanabiliriz, bu genellikle çabanın yarısı ile sonuçtan iki kat daha fazladır ve aşırı uydurmayı etkili bir şekilde önleyebiliriz. Benzer şekilde, filtrenin parametre paylaşımı nedeniyle, görüntü belirli bir dönüştürme işleminden geçse bile, "çeviri değişmezliği" olarak adlandırılan özellikleri yine de belirleyebiliriz. Bu nedenle model daha sağlamdır.
2. Bağlantıların seyrekliği (bağlantıların seyrekliği)
Evrişim işleminden, çıktı görüntüsündeki herhangi bir birimin yalnızca girdi görüntüsünün bir parçasıyla ilişkili olduğu görülebilir:

Geleneksel sinir ağlarında, hepsi tamamen bağlı olduklarından, herhangi bir çıkış birimi tüm giriş birimlerinden etkilenmelidir. Bu şekilde, görüntünün tanıma etkisi büyük ölçüde azalacaktır. Buna karşılık, her alanın kendine özgü özellikleri vardır ve diğer alanlardan etkilenmesini istemiyoruz.
CNN'in geleneksel NN'yi aşması ve yeni bir sinir ağları çağı açması tam da yukarıdaki iki avantajdan kaynaklanıyor.