Jeff Dean'in son makalesi: Derin öğrenme indeksleme daha hızlı ve daha az yer kaplıyor
("MIT Technology Review" APP'nin Çince ve İngilizce versiyonu artık çevrimiçi ve yıllık aboneler her hafta teknoloji İngilizcesi dersini canlı yayınlıyor ve ayrıca bir teknoloji İngilizce öğrenme topluluğu da var ~)
AlphaZero'nun haberlerini birkaç gün önce takip ettiyseniz, TPU'ya aşina olmanız gerekir. TPU (Tensor Processing Unit), Google tarafından makine öğrenimi için özel olarak oluşturulmuş yüksek performanslı bir işlemcidir. Her işlemi gerçekleştirmek için daha az transistör gerektirir, bu nedenle daha verimlidir . AlphaZero, TPU'nun yardımıyla gücünü de uygulayabiliyor.
Son zamanlarda, NIPS konferansı sırasında Google'ın beyni başkanı Jeff Dean, Google'ın AI çipleri üzerine yaptığı son araştırmayı ayrıntılı olarak tanıttı. Hepimizin bildiği gibi, derin öğrenme çok fazla bilgi işlem kaynağı gerektirir ve sistemleri tasarlama şeklimizi değiştiriyor. Öğrenilen Dizin Google'ın en son araştırma sonuçlarından biridir - gelenekselden farklı yeni bir indeks.
Kağıt adresi:
https://arxiv.org/pdf/1712.01208v1.pdf

Şekil Jeff Dean
Verileri verimli bir şekilde almak istediğimizde, indeksleme en iyi cevaptır. Dizin bir modeldir ve ana fikri, verilerin sıralanmasını veya anahtar değerlerin yapısını öğrenebilen bir model tasarlamak ve bunu veri kayıtlarının yerini veya varlığını anlamak için bir sinyal olarak kullanmaktır. Geleneksel dizin modelleri arasında B-Tree-Index (B-tree index), Hash-Index (hash index), BitMap-Index (bitmap index) vb. Bulunur.
Farklı veri yapıları ve farklı ihtiyaçlar için, şu anda insanların aralarından seçim yapabileceği çeşitli dizinler bulunmaktadır. Örneğin, anahtar değere dayalı arama durumunda karma indeksi son derece etkilidir, B-Ağacı, aralık gereksinimleri olan istekler için daha uygundur ve Bloom filtreleri indeksi, verilerin varlığını kontrol etmek için özel olarak kullanılır.
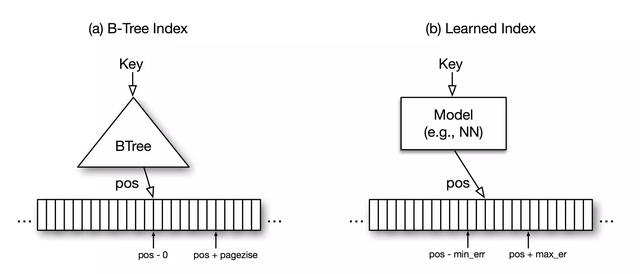
Şekil | (a) B-Tree indeksi, temelde anahtar değerleri veri depolama konumlarıyla eşleyen bir modeldir. (B) Öğrenilen Dizinin alternatif yapısı
Endeks, veri sisteminde son derece önemli bir konuma sahiptir ve son birkaç on yılda, mühendisler tarafından optimizasyonun odak noktası olmuştur. Bununla birlikte, mevcut tüm geleneksel dizinler ortak veri yapılarını hedeflemektedir. En kötü veri dağıtımının iyi bir evrenselliğe sahip olduğunu varsayarlar, ancak gerçek dünyadaki bazı ortak ve yaygın veri kalıplarından tam olarak yararlanamazlar.
Veri dağıtımını ve diğer özellikleri anlayabilirseniz, endeksi büyük ölçüde optimize edebilir ve hesaplama ve depolama için gerekli kaynakları azaltabilirsiniz. Bununla birlikte, gerçek dünya verileri karmaşık ve çeşitlidir ve mutlaka bilinen belirli bir modele uymak zorunda değildir. Ayrıca, mühendislerin her bir özel veri stili için çözümler tasarlaması son derece maliyetlidir. Ancak makine öğrenimi ve performansı artan donanım bize bu tür fırsatları getirdi.
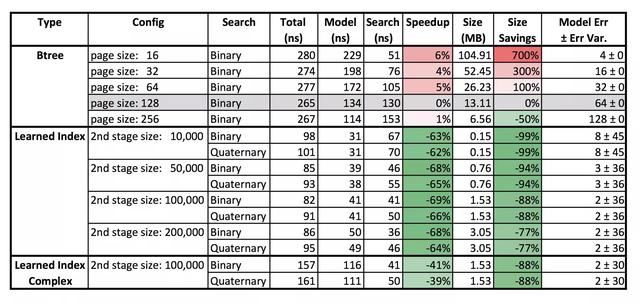
Şekil | Öğrenilmiş Dizin ve B-Ağacı sonuçlarının karşılaştırması: büyük ölçüde iyileştirilmiş hız ve azaltılmış depolama alanı
Google araştırmacıları bu tür öncüllere ve çıkarımlara dayanmaktadır: Bilinen tüm dizin yapıları diğer model türleriyle değiştirilebilir . Yeni bir dizin fikrini buldular. Verilerin belirli kalıplarını ve dahili ilişkilerini öğrenebilir, otomatik olarak özel bir dizin yapısı tasarlayabilirsiniz ve tasarım maliyeti son derece düşüktür. . Bu fikir, Öğrenilmiş Dizindir.
Makalede, B-Tree indeksi, hash indeksi ve Bloom-Filters indeksi için alternatifler önerdiler. Deneysel sonuçlar, Öğrenilmiş Dizinin son derece yüksek performansını göstermektedir. Araştırma gösteriyor ki, Yapay sinir ağı tarafından oluşturulan dizin, gerçek dünyadan verileri işlerken önbellek için optimize edilmiş B-Ağacı dizininden% 70 daha hızlıdır ve depolama alanı% 99'a kadar azaltılabilir.
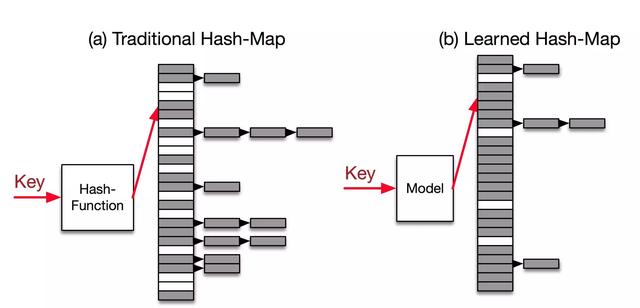
Şekil | Hash indeksi yerine Öğrenilen Dizin
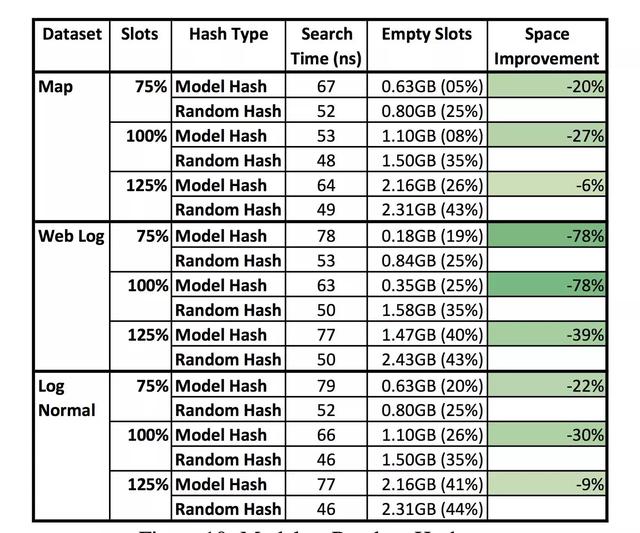
Şekil | Öğrenilen Dizin ve Karma Dizininin deneysel sonuçlarının karşılaştırılması: Öğrenilen Dizinin Model Karması, daha fazla depolama alanı tasarrufu sağlar.
Araştırmacılar, öğrenilen indeksin performansının geleneksel indeksleme yöntemlerini aştığı koşulları ve öğrenilen indeksin yapısının karşılaştığı ana zorlukları teorik olarak analiz ettiler. Donanımın hızla gelişmesiyle bu zorlukların korkmak için yeterli olmadığına ve öğrenilen dizinin avantajlarının yeni nesil donanımda (GPU ve hatta TPU) daha önemli olacağına inanıyorlar.
Şu anda, bu çalışma hala salt okunur veri analizi yüküne odaklanmıştır, ancak çok sayıda yazma işlemi içeren işteki uygulama için ayrıntılı plan çizilmiştir. Veri yönetim sisteminin temel kısmını bir öğrenme modeliyle değiştirme fikri, gelecekteki sistem tasarımında önemli bir etkiye sahip olacak ve bu çalışma şüphesiz bize şafağı görmemizi sağlıyor.
Evet, Google'ın tutkuları zaten çok açık. Bu yılki NIPS'de konuşmasında, " Geleneksel temel sistemin (işletim sistemi, depolama sistemi, derleme sistemi) kodu, makine öğreniminin sonuçlarından tam olarak yararlanmıyor. "Şimdiye kadar, onun makine öğrenimi için yeni araştırma yönlerini gördük: Bir bilgisayar sisteminin yapısını yeniden yapılandırmak için makine öğrenimini kullanın. Bu makine öğrenimi dizini yalnızca başlangıç olacak.