Li Feifei'nin son konuşması: Görsel zeka, insanlarla bilgisayarlar arasında işbirliği yapmak ve iletişim kurmak için köprü görevi görüyor | CNCC2017

Lei Feng.com AI Teknolojisi İnceleme Raporu: Çin Bilgisayar Derneği CCF tarafından düzenlenen Çin Bilgisayar Konferansı CNCC 2017, 26 Ekim'de Fuzhou Boğazı Uluslararası Kongre ve Sergi Merkezi'nde açıldı. Toplantıya çok sayıda insan katıldı ve ana mekan tıklım tıklımdı. Leifeng.com AI Technology Review ayrıca konferansın raporuna katılmak için bir muhabir ekibi gönderdi.
26'sı sabahı düzenlenen açılış töreninin ardından, özel olarak davet edilen bir dizi konuk, bilgisayar biliminin gelişiminde yeni teknolojileri ve uygulamaları, doğal dil net karını, yapay zekanın insanlara nasıl hizmet ettiğini ve bilgi platformlarında yapay zekanın uygulanmasını kapsayan konularda canlı konuşmalar yaptı. Bekle. Stanford Üniversitesi'nde doçent olan, Google Cloud'un baş bilim adamı ve makine öğrenimi sektörünün referans figürlerinden biri olan Li Feifei, "Görsel Zeka: ImageNet'in Ötesinde" başlıklı bir konuşma yaptı.
Li Feifei ilk önce biyoloji için vizyonun önemini ve nesne tanıma görevlerinde bilgisayar vizyonunun hızlı gelişimini tanıttı. Ardından, sizinle bilgisayarla görmenin bir sonraki hedefini tartışmaya devam edin: sahne anlayışını zenginleştirmenin yanı sıra bilgisayarla görme ve dil kombinasyonunun ilerlemesi ve beklentileri ve göreve dayalı bilgisayar vizyonu. Dil ile birleştirilen sahne anlayışı ve bilgisayar görüşü, insanlar ve bilgisayarlar arasında daha fazla köprü kurdu.Görev odaklı bilgisayar görüşü de robotik alanında parlayacak. Li Feifei'nin ekibinin çalışmalarını tanıtması da çeşitli ve heyecan verici.

Li Feifei, nesne tanıma olan görsel zeka oluşturmadaki ilk kilometre taşını tanıttı. İnsanlar, benzersiz görsel tanıma yeteneklerine sahiptir ve bilişsel sinirbilimciler tarafından yapılan birçok çalışma bu fenomeni göstermiştir. Li Feifei, sahnedeki izleyicilerle küçük bir etkileşim kurdu, ekranda yalnızca 0,1 saniye süren bir dizi fotoğrafı başka bir açıklama yapmadan gösterdi ve seyirci yine de resimlerden birinde bir kişi olduğunu fark edebilir.
MIT profesörü Simon Thorpe tarafından 1996 yılında yapılan bir deneyde, beyin dalgalarını kaydederek, insanların, memeliler, kuşlar, hayvanlar, içerip içermediğini ayırt etmek için 150 ms'lik karmaşık bir fotoğrafı gözlemlemesi gerektiğini gösterdi. Balık veya böcekler.

Karmaşık nesnelerin bu hızlı görsel olarak tanınması, insan görsel sisteminin temel özelliğidir ve aynı zamanda bilgisayar görüşünde "Kutsal Kase" dir. Son 20 yılda, nesne tanıma, bilgisayarla görme topluluğunda önemli bir görev haline geldi. ImageNet, katkıda bulunan veri setlerinden biridir.

2010'dan bu yana, 2010'dan 2017'ye kadar, ImageNet Challenge'ın nesne tanıma hata oranı orijinalin onda birine düştü. 2015 yılına kadar, hata oranı insan seviyelerine ulaştı veya hatta daha düşüktü. Bu, temelde bilgisayarla görmenin basit nesne tanıma probleminin üstesinden geldiğini gösterir.
Tabii ki, bilgisayarla görme araştırması sadece insanların zengin görsel deneyiminin temeli olan ImageNet ve nesne tanıma ile bitmeyecek.

Bir sonraki anahtar adım, görsel ilişkilerin tanımlanmasıdır. Bu görevin tanımı şudur: "Algoritma modeline bir fotoğraf girin, algoritmanın içindeki anahtar nesneleri tanımlayabilmesi, konumlarını bulması ve aralarındaki ikili ilişkiyi bulması umuduyla."
Her iki fotoğraf da insanlara ve alpakalara ait, ancak olanlar tamamen farklı. Bu, salt nesne tanımanın tanımlayamayacağı şeydir.

Derin öğrenme çağından önce, bu alanda pek çok çalışma vardı, ancak bunların çoğu, insan kontrollü bir alanda mekansal ilişkiler, eylem ilişkileri ve benzer ilişkiler gibi yalnızca birkaç ilişkiyi analiz edebiliyordu. Bilgi işlem gücünün ve veri hacminin patlamasıyla birlikte, derin öğrenme çağındaki araştırmacılar nihayet büyük ilerleme kaydetti. Bu, evrişimli sinir ağının görsel temsilinin ve dil modelinin kombinasyonunu gerektirir.
Li Feifeinin ekibi tarafından ECCV2016ya dahil edilen makalelerde, modelleri zaten mekansal ilişkileri, karşılaştırma ilişkilerini, anlamsal ilişkileri, eylem ilişkilerini ve konum ilişkilerini tahmin edebiliyor. "Tüm nesneleri listelemenin" yanı sıra, sahnedeki nesneler arasındaki ilişkilerin zengin bir anlayışına doğru ilerliyor. Sağlam bir adım atıldı.

İlişki tahminine ek olarak, örneklemsiz öğrenme de yapılabilir. Örneğin, modeli eğitmek için sandalyede oturan bir kişinin fotoğrafını ve yerdeki bir yangın musluğunun fotoğrafını kullanın. Ardından, yangın musluğunun üzerinde tek başına oturarak başka bir fotoğraf çekin. Algoritma bu resmi görmemiş olsa da, "yangın musluğunun üzerinde oturan bir kişi" olduğunu ifade edebilir.

Benzer şekilde, eğitim setinde sadece "ata binen insanlar" ve "şapka giyen insanlar" resimleri olmasına rağmen, algoritma "şapkalı bir atı" tanıyabilir.

Li Feifeinin ekibinin ECCV 2016 makalesinin ardından, bu yıl çok sayıda ilgili makale yayınlandı ve hatta bazıları modellerinin performansını bile aştı. Ayrıca bu görevle ilgili araştırmaların zenginliğini ve gelişmesini görmekten de çok memnun.
Nesne tanıma sorunu büyük ölçüde çözüldükten sonra, Li Feifei'nin bir sonraki hedefi nesnenin kendisinden çıkmaktır. Microsoft'un Coco veri seti artık bir resim + etiket değil, bir resim + resmin ana içeriğini açıklayan kısa bir cümle.
Üç yıllık hazırlığın ardından Li Feifei ekibi, 100.000 görüntü, 4.2 milyon görüntü açıklaması, 1.8 milyon soru ve cevap çifti, 1.4 milyon etiketli nesne, 1.5 milyon ilişki ve 1.7 milyon içeren Görsel Genom veri kümesini başlattı. Makale özellikleri. Bu çok zengin bir veri setidir ve amacı nesnenin kendisinden çıkıp daha geniş bir nesne yelpazesi arasındaki ilişkiye, dile, mantığa vb. Odaklanmaktır.


Görsel Genom veri kümesinden sonra, Li Feifei ekibi tarafından yapılan bir başka çalışma, sahne tanımayı yeniden anlamaktır.
Tek başına sahne tanıma basit bir iştir. Google'da "takım elbiseli adam" veya "sevimli köpek yavrusu" araması, size doğrudan istenen sonucu verecektir.

Ama "şirin köpek yavrusu tutan takım elbiseli bir adam" aradığınızda, hiç iyi sonuç alamazsınız. Performansı burada kötüleşiyor Nesneler arasındaki bu tür bir ilişkiyle uğraşmak zor bir şey.

Yalnızca "banklar" ve "insanlar" ın nesne tanımasına odaklanırsanız, "banklarda oturan insanlar" arasındaki ilişkiyi alamazsınız; ağ "oturan kişileri" tanımak için eğitilmiş olsa bile, resmin tamamını görmeniz garanti edilmez.

Nesnenin dışındaki ve sahnenin içindeki tüm ilişkileri dahil etme ve ardından kesin ilişkiyi çıkarmanın bir yolunu bulmaları için bir fikirleri var.

Sahnede çeşitli karmaşık anlamsal bilgiler içeren bir sahne grafiği (grafik) varsa, sahne tanıma çok daha iyi yapılabilir. Tüm detayları uzun bir cümle içinde tarif etmek zor olabilir, ancak uzun bir cümleyi sahne grafiğine çevirdikten sonra onu grafikle ilgili bir yöntemde görüntüyle karşılaştırabiliriz; sahne grafiği de veritabanının bir parçası olarak kodlanabilir. Veritabanı perspektifinden sorgulama yapın.

Li Feifei'nin ekibi, birçok anlamsal bilgi içeren sahnelerde birçok iyi nicel sonuç elde etmek için sahne grafiği eşleştirme teknolojisini kullandı. Peki bu sahne grafiklerini kim tanımlıyor? Görsel Genom veri setinde, sahne grafikleri manuel olarak tanımlanır. Varlıklar, yapılar, varlıklar arasındaki ilişkiler ve görüntülerle eşleştirme, Li Feifei'nin ekibi tarafından manuel olarak yapılır. Süreç zahmetlidir ve gelecekte bunları düzeltmek istemezler. Her sahne bu tür işler yapar. Yani bu çalışmadan sonra, dikkatlerini otomatik sahne grafiği oluşturmaya da çeviriyorlar.

Örneğin, kendisinin ve öğrencilerinin birlikte tamamladığı CVPR2017 kağıdı, otomatik olarak sahne grafikleri oluşturmak için bir şemadır.Bir giriş görüntüsü için, önce nesne tanımanın aday sonuçlarını elde edin ve ardından varlıklar ve varlıklar arasındaki ilişkiyi elde etmek için grafik muhakeme algoritmalarını kullanın. İlişkiler vb; bu işlem otomatik olarak yapılır.

Burada bazı yinelemeli bilgi aktarım algoritmaları söz konusudur ve Li Feifei ayrıntılı olarak açıklamadı. Ancak bu sonucun gösterdiği şey, bu modelin çalışma şekli ile insanların yaptıkları arasında birçok benzerlik olduğu.

Bu, insanlığa gelen yepyeni bir olasılıklar kümesini temsil ediyor. Sahne grafikleri yardımıyla bilgileri çıkarabilir, ilişkileri tahmin edebilir, yazışmaları anlayabilir ve daha fazlasını yapabiliriz.

QA sorunları da daha iyi çözüldü.

Diğer bir araştırma amacı, resme açıklayıcı bir metinden tam bir paragraf vermektir.
Li Feifei, California Teknoloji Enstitüsü'nde doktora öğrencisiyken, insanlardan bir fotoğrafı incelemelerinin istendiği bir deney yaptı ve ardından onlardan mümkün olduğunca fotoğrafta gördüklerini söylemelerini istedi. Deneyi yaparken, deneklerin önündeki ekranda bir fotoğraf hızla parladı ve daha sonra onu başka bir görüntü veya duvar kağıdı benzeri bir görüntü ile kapladı ve işlevi, retinalarında kalan bilgileri temizlemekti.
O halde gördüklerini mümkün olduğunca yazsınlar. Sonuçlara bakılırsa, bazı fotoğraflar daha kolay görünebilir, ancak aslında farklı uzunluklarda görüntüleme süresi seçmiş olmamızdan kaynaklanıyor En kısa fotoğraf, o sırada monitörün görüntüleme hızının üst sınırına ulaşan yalnızca 27 milisaniye görüntülendi; bazı fotoğraflar 0,5 gösterdi Saniyeler, insanın görsel anlayışı için fazlasıyla yeterli.

Bu fotoğraf için kısa sürede görülebilen içerik de oldukça sınırlı olup, 500 milisaniyede uzun bir paragraf yazabilirler. Evrim bize uzun bir hikâyeyi sadece bir resim görerek anlatma yeteneği verdi.
Son 3 yılda, CV alanındaki araştırmacılar, görsellerdeki bilgilerin hikayelere nasıl dönüştürüleceği üzerine çalışıyorlar.

İlk olarak, bir özellik alanında görüntünün içeriğini temsil etmek için CNN kullanmak gibi görüntü açıklamaları üzerinde çalıştılar ve ardından bir dizi metin oluşturmak için LSTM gibi RNN'leri kullandılar. Bu tür çalışmaların 2015 yılı civarında pek çok sonucu var ve o zamandan beri bilgisayarın hemen hemen her şeyi bir cümle ile eşleştirmesine izin verebiliyoruz.

Şu iki örneği ele alalım, "turuncu yelek giyen bir işçi yol döşüyor" ve "siyah tişörtlü adam gitar çalıyor".


Bu, CVPR2015'in sonucudur. İki yıl sonra, Li Feifei ekibinin algoritması artık en gelişmiş algoritma değil, ama gerçekten de görüntü açıklama alanındaki öncü çalışmalardan biriydi.
Bu doğrultuda araştırma yapmaya devam ederken, ortaya çıkardıkları bir sonraki sonuç yoğun bir betimlemedir, yani bir resimde dikkatleri dağıtacak pek çok alan vardır, böylece farklı alanları betimleyen pek çok farklı cümle olabilir, sadece Sadece bir cümle tüm sahneyi açıklıyor. Burada CNN modeli ve mantıksal bölge algılama modelinin kombinasyonu ve ayrıca bir dil modeli kullanılır, böylece sahne yoğun bir şekilde etiketlenebilir.

Örneğin, "Sandalyede oturan iki kişi var", "Bir fil var", "Bir ağaç var" gibi bu resim oluşturulabilir.

Li Feifei öğrencilerinin bir başka iç mekan fotoğrafı da zengin içeriğe işaret etti.

Son CVPR2017 araştırmasında, performansı yeni bir seviyeye taşıdılar, sadece açıklayıcı cümleler değil, aynı zamanda metin paragrafları oluşturarak bunları uzamsal olarak anlamlı bir şekilde birleştirdiler. Bu şekilde "ağacın yanında duran bir zürafa, sağında yapraklar olan bir direk ve çitin arkasında siyah beyaz bir tuğla bina" vb. Yazabiliriz. İçinde hatalar olmasına ve Shakespeare'in eserlerinden çok daha düşük olmasına rağmen, vizyon ve dili birleştirmede ilk adımı zaten atmış durumdayız.

Dahası, vizyon ve dilin birleşimi hareketsiz bir görüntüde bitmiyor, sadece en son başarılardan biri. Başka bir çalışmada, video ve dili birleştirdiler.

Örneğin, bu CVPR2017 araştırması ortak akıl yürütme yapabilir ve açıklayıcı bir videodaki farklı bölümlerin metin yapısını sıralayabilir. Buradaki zorluk, metindeki varlıkları ayrıştırmaktır. Örneğin, ilk adım "sebzeleri karıştırmak" ve sonra "karışımı çıkarmaktır". Algoritma, "karışım" ın önceki adımda karıştırılan sebzeleri ifade ettiğini ayrıştırabilirse, harika olur.

Dilden sonra, Li Feifei ayrıca göreve dayalı görme sorunları ortaya çıkardı. Yapay zeka araştırma ailesinin tamamı için, görev odaklı yapay zeka, uzun vadeli ortak bir rüyadır.İnsanlar, robotlara bir isim vermek için dili kullanmayı başından beri umuyor ve ardından robotlar dünyayı gözlemlemek, görevleri anlamak ve tamamlamak için görsel yöntemler kullanıyor.
Bu, göreve dayalı klasik bir sorundur. İnsanlar şöyle der: "Mavi piramit harika. Kırmızı olmayan küpleri severim ama 5 hedronlu hiçbir şeyi sevmem. Gri kutuyu sever miyim? "Ardından makine veya robot veya aracı yanıt verecek:" Hayır, çünkü 5 hedronla doldurulmuş. " Bu karmaşık dünyayı anlamak ve mantık yürütmek görev odaklı.

Li Feifeinin ekibi, bu tür sorunları yeniden araştırmak, çeşitli geometrik cisimlerle sahneler oluşturmak ve ardından bu sorunları nasıl anlayacağını, gerekçelendireceğini ve çözeceğini görmek için yapay zeka soruları sormak için Facebook ile birlikte çalıştı. Bu, özniteliklerin tanımlanmasını, sayılmasını, karşılaştırılmasını, uzamsal ilişkisini vb. İçerecektir.

Bu alandaki ilk kağıt CNN + LSTM + dikkat modelini kullandı.Sonuç fena değil.İnsanlar% 90'ın üzerinde doğru bir orana ulaşabilir.Makine% 70'e yakın bir başarı elde edebilmesine rağmen, hala büyük bir boşluk var. Bu boşluk, insanların akıl yürütmeyi birleştirebilmesi, ancak makinelerin yapamamasıdır.

ICCV'de yeni bir makalenin sonuçlarını tanıttılar. Yeni CLEVR veri setinin yardımıyla, bir soru, işlevlere sahip program bölümlerine ayrıştırılır ve ardından soruları yanıtlayabilen bir yürütme motoru, program bölümleri temelinde eğitilir. Bu şema, gerçek dünya sorunları hakkında mantık yürütmeye çalışırken çok daha yüksek kombinatoryal yeteneğe sahiptir.
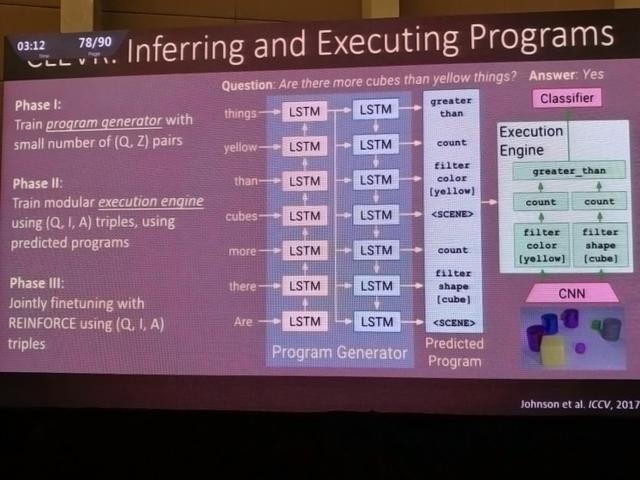
Testte nihayet insan performansını aştı.

Modelin gerçek performansı kesinlikle iyi. Örneğin bu örnekte, hangi şeklin belirli bir renk olduğunu sorarsak, "o bir küp" şeklinde yanıt verir, bu da mantığının doğru olduğunu gösterir. Aynı zamanda şeylerin sayısını da sayabilir. Bütün bunlar, algoritmanın sahne hakkında akıl yürütebileceğini gösteriyor. Isı haritası ayrıca modelin haritadaki alana doğru şekilde odaklandığını gösterir.

Görüntüyle ilgili görevler hakkında çok şey söyleyen Li Feifei, bunları iki kategoride özetledi.
-
Birincisi, ilişki tanıma, karmaşık anlamsal temsil ve nesne tanıma dışındaki sahne grafikleri;
-
Sahnenin ana fikrinin dışında, tek cümle açıklamasını, paragraf oluşturmayı, videoyu anlama ve ortak akıl yürütmeyi işlemek için vizyon + dili kullanmamız gerekir;

Li Feifei nihayet kızının bir resmini gösterdi.O sadece 20 aylık ama görsel yeteneği de günlük yaşamının önemli bir parçası.Okumak, resim yapmak, duyguları gözlemlemek vb. Bu büyük gelişmeler bu alandaki gelecekteki araştırmalar. Amaçları.

Görsel zeka, anlama, iletişim, işbirliği, etkileşim vb. İçin anahtar bir adımdır Bu alandaki insan keşfi daha yeni başlıyor.

(Bitiş)
CNCC2017 hala devam ediyor, lütfen Leifeng.com AI Technology Review'den gelen harika raporları dört gözle bekleyin.