Kuru ürünler Aktivasyon işlevi hakkında 6 temel bilgi noktası, lütfen ustalaştığınızdan emin olun!

Kaynak: AI Youdao
Bu makale hakkında 2800 kelime 6 dakika okumanız tavsiye edilir.
Bu makale, yaygın olarak kullanılan Sigmoid, tanh, ReLU, Leaky ReLU, ELU, Maxout aktivasyon fonksiyonlarının temel bilgi noktalarını özetlemektedir.
Sinir ağı modelinde, çıktı katmanı dahil her gizli katmanın bir aktivasyon fonksiyonu (Aktivasyon Fonksiyonu) gerektirdiğini biliyoruz. Daha tanıdık ve yaygın olarak kullanılan aktivasyon fonksiyonları ReLU, Sigmoid ve benzerlerini içerir. Ancak, seçim yöntemleri ve her etkinleştirme işlevinin ayırt edici özellikleri için özel dikkat gerektiren birkaç nokta vardır. Bugün yaygın olarak kullanılan Sigmoid, tanh, ReLU, Leaky ReLU, ELU, Maxout aktivasyon fonksiyonlarının temel bilgi noktalarını özetleyeceğiz.
Neden bir aktivasyon fonksiyonuna ihtiyacınız var
Bir sinir ağındaki tek bir nöronun temel yapısı iki bölümden oluşur: doğrusal çıktı Z ve doğrusal olmayan çıktı A. Aşağıda gösterildiği gibi:
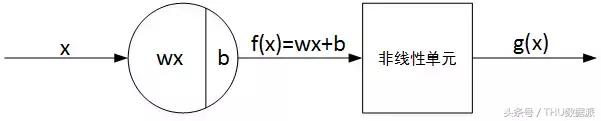
Bunlar arasında, f (x) doğrusal çıktı Z'dir, g (x) doğrusal olmayan çıktıdır ve g () etkinleştirme işlevidir. Genel olarak konuşursak, aktivasyon işlevi genellikle doğrusal olmayan bir işlevdir ve rolü sinir ağına bazı doğrusal olmayan faktörler eklemektir, böylece sinir ağı daha karmaşık sorunları daha iyi çözebilir.
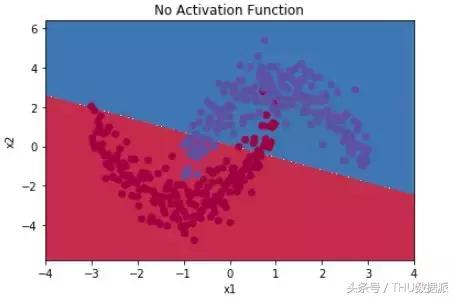
Basit bir örnek olarak, basit lojistik regresyon kullanmak gibi iki sınıflandırma problemi için aktivasyon fonksiyonu kullanılmıyorsa, aşağıdaki şekilde gösterildiği gibi yalnızca basit doğrusal bölme yapılabilir:
Aktivasyon işlevi kullanılırsa, aşağıdaki şekilde gösterildiği gibi doğrusal olmayan bölme elde edilebilir:
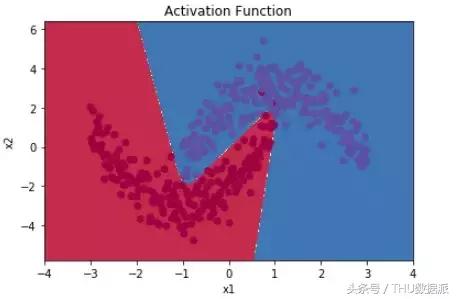
Aktivasyon fonksiyonunun doğrusal olmayan faktörleri tanıtmamıza yardımcı olabileceği, böylece sinir ağının daha karmaşık problemleri daha iyi çözebileceği görülebilir.
Bir soru var, aktivasyon işlevi neden genellikle doğrusal değil ama doğrusal değil? Ters tarafta, tüm aktivasyon fonksiyonları doğrusal ise, aktivasyon fonksiyonu g (z) = z, yani a = z'dir. Daha sonra, örnek olarak iki katmanlı bir sinir ağını ele alırsak, nihai çıktı:

Çıkarımdan sonra, ağ çıktısının hala X'in doğrusal bir kombinasyonu olduğunu gördük. Bu, sinir ağlarını kullanmanın etkisinin doğrudan doğrusal modeller kullanmaktan farklı olmadığını göstermektedir. Birden çok gizli katmana sahip bir sinir ağı olsa bile, etkinleştirme işlevi olarak doğrusal bir işlev kullanılırsa, nihai çıktı yine de doğrusal bir modeldir. Bu durumda sinir ağının hiçbir etkisi yoktur. Bu nedenle, gizli katmanın aktivasyon işlevi doğrusal olmamalıdır.
Tüm gizli katmanlar lineer aktivasyon fonksiyonları kullanıyorsa ve sadece çıktı katmanı lineer olmayan aktivasyon fonksiyonları kullanıyorsa, tüm sinir ağının yapısının basit bir lojistik regresyon modeline benzediğini ve etkinin tek bir nöronunkinden farklı olmadığını belirtmek gerekir. Ek olarak, bir sınıflandırma probleminden ziyade uygun bir problem ise, çıktı katmanının aktivasyon fonksiyonu doğrusal bir fonksiyon kullanabilir.
Sigmoid
Sigmoid aktivasyon fonksiyonunun grafiksel ifadesi aşağıdaki gibidir:

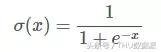
Sigmoid fonksiyonunun değer aralığı (0,1) arasında, monoton ve süreklidir ve elde edilmesi kolaydır.Genellikle iki sınıflı bir sinir ağının çıktı katmanında kullanılır.
Sigmoid işlevinin eksikliklerine odaklanalım.
Her şeyden önce, Sigmoid fonksiyonunun geniş bir doygunluk alanı vardır ve bu da gradyanın kaybolmasına neden olur. Doygunluk bölgesi aşağıdaki şekilde gösterilmektedir:
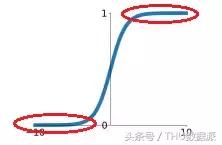
Yukarıdaki şekilde kırmızı elips ile işaretlenen doygunluk bölgesindeki eğri pürüzsüzdür ve gradyan değeri çok küçüktür, yaklaşık olarak sıfırdır. Ayrıca Sigmoid fonksiyonunun doygunluk bölgesi çok geniştir, örneğin haricindeki diğer bölgeler doygunluk bölgesine benzer. Bu durum, gradyanın kolayca kaybolmasına neden olabilir, bu da sinir ağı eğitiminin zorluğunu artıracak ve sinir ağı modelinin performansını etkileyecektir.
İkincisi, Sigmoid işlevinin çıktısı sıfır olmayan simetriktir, yani çıktı her zaman sıfırdan büyüktür. Bunun ne etkisi olacak? Sigmoid fonksiyonunun çıktısı (Wx + b) ise ve 0'ı tatmin ediyorsa bir bakalım. < (Wx + b) < 1. Ters türetme işleminde, kayıp fonksiyonu J'nin (Wx + b) 'ye göre türetilmesi d olsun, şimdi J'nin W'ye göre kısmi türevini hesaplayın:
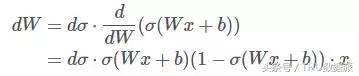
Bunların arasında (Wx + b) > 0,1- (Wx + b) > 0.
Nöronun girdisi x > 0 ise, d ne kadar pozitif veya negatif olursa olsun, her zaman dW'yi her zaman pozitif veya her zaman negatif elde edebilirsiniz. Yani, parametre matrisinin W her bir elemanı hem pozitif hem de negatif olarak aynı yönde değişecektir. Bu, sinir ağı eğitimi için elverişsizdir Aynı sembol yönündeki tüm W değişiklikleri, eğitim hızını azaltacak ve model eğitim süresini artıracaktır. Aşağıdaki şekilde gösterildiği gibi, merdivenlerden aşağı inmemiz gereken zaman her zaman doğrudan aşağı inme süresinden çok daha uzun gibi:

Şekilde, kırmızı kesik çizgi yukarıda tartışılan durumdur ve mavi çapraz çizgi, W'nin hepsinin aynı yönde değişmediği durumdur.
Sigmoid fonksiyonunun bu problemi için, nöronun x girdisinin genellikle önceden işlendiğini, yani ortalama değerin sıfıra normalleştirildiğini belirtmekte fayda var. Bu aynı zamanda dW'nin pozitif veya negatif olmasını etkili bir şekilde önleyebilir.
Son olarak, Sigmoid işlevi üstel işlemi içerir ve işlem maliyeti nispeten büyüktür.
tanh
Tanh aktivasyon fonksiyonunun grafiksel ifadesi aşağıdaki gibidir:
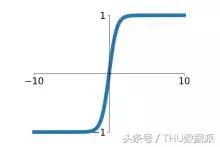
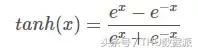
Tanh fonksiyonunun değer aralığı (-1,1) arasında, monoton ve süreklidir ve türetilmesi kolaydır.
Sigmoid fonksiyonu ile karşılaştırıldığında, tanh fonksiyonunun iki ana avantajı vardır: Birincisi, yakınsama hızı daha hızlıdır Aşağıdaki şekilde gösterildiği gibi, tanh fonksiyonunun lineer bölgesinin eğimi Sigmoid fonksiyonunkinden daha büyüktür. Bu alanda eğitim hızı daha hızlı olacaktır. İkincisi, tanh fonksiyonunun çıktısının ortalama değeri sıfırdır, bu nedenle Sigmoid fonksiyonundaki dW'nin her zaman pozitif veya negatif olması, eğitim hızını etkileyen bir sorun yoktur.
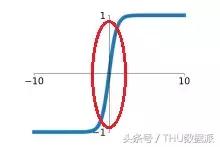
Bununla birlikte, Sigmoid işlevi gibi tanh işlevi de doygunluk bölgesindeki gradyanı ortadan kaldırma sorununa sahiptir. Doygunluk bölgesi Sigmoid'inkinden bile daha büyük, ancak açık değil.
ReLU
ReLU aktivasyon fonksiyonunun tam adı Rectified Linear Unit'dir ve grafiksel ifadesi aşağıdaki gibidir:
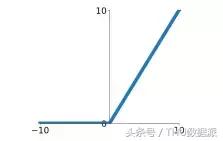
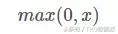
ReLU işlevi, son yıllarda daha sıcak aktivasyon işlevlerinden biridir. Sigmoid ve tanh işlevleriyle karşılaştırıldığında, ana avantajları aşağıdaki yönleri içerir:
- Doygunluk bölgesi yoktur ve gradyan kaybolması sorunu yoktur.
- Karmaşık üstel hesaplama, basit hesaplama ve geliştirilmiş verimlilik yok.
- Gerçek yakınsama hızı, Sigmoid / tanh hızından yaklaşık 6 kat daha hızlıdır.
- Biyolojik nöral aktivasyon mekanizması ile Sigmoid'den daha uyumludur.
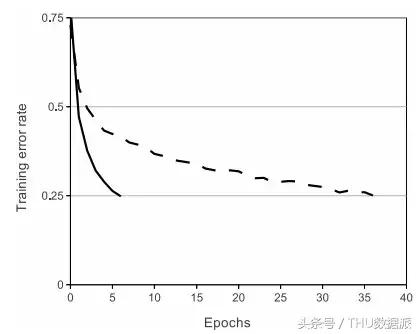
Aşağıdaki şekil ReLU ve tanh arasındaki yakınsama hızı farkını karşılaştırmaktadır. Veri seti CIFAR 10'dur ve model dört katmanlı bir evrişimli sinir ağıdır. Şekilde, düz çizgi ReLU'yu temsil eder ve kesikli çizgi tanh'ı temsil eder ReLU, 0.25'lik hata oranına tanh'den daha hızlı ulaşır. ("ImageNet Classification with Deep Convolutional Neural Networks" makalesinden alıntılanmıştır)
Bununla birlikte, ReLU işlevinin dezavantajları da açıktır. Her şeyden önce, ReLU'nun çıktısı hala sıfır olmayan simetriktir ve dW'nin her zaman pozitif veya negatif olduğu görünebilir, bu da eğitim hızını etkiler.
İkincisi ve en önemlisi, x < 0 olduğunda, ReLU çıkışı her zaman sıfırdır. Nöronun çıktısı sıfır ise, geri yayılma sırasında ağırlıkların ve parametrelerin gradyanı sıfır olacak ve ağırlıkların ve parametrelerin hiçbir zaman güncellenmemesine, yani nöronun başarısız olmasına ve "ölü nöron" oluşmasına neden olacaktır. Bu nedenle, bu soruna yanıt olarak, ReLU nöronları bazen 0,01 gibi pozitif bir önyargı değerine başlatılır.
Sızdıran ReLU
Leaky ReLU, ReLU'yu iyileştirmiştir ve grafiksel ifadesi aşağıdaki gibidir:
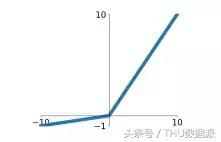
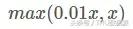
Leaky ReLU'nun avantajları ReLU'ya benzer:
- Doygunluk bölgesi yoktur ve gradyan kaybolması sorunu yoktur.
- Karmaşık üstel hesaplama, basit hesaplama ve geliştirilmiş verimlilik yok.
- Gerçek yakınsama hızı, Sigmoid / tanh hızından yaklaşık 6 kat daha hızlıdır.
- Nöronların başarısız olmasına ve "ölü nöronlar" oluşturmasına neden olmaz.
Tabii ki 0.01 faktörü ayarlanabilirdir ve genellikle çok büyük değildir.
ELU
ELU (Üstel Doğrusal Birimler) de ReLU'nun bir çeşididir ve grafiksel ifadesi aşağıdaki gibidir:
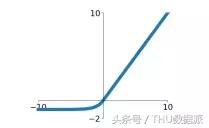
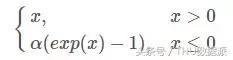
ELU, Leaky ReLU'nun tüm avantajlarını devralır:
- Doygunluk bölgesi yoktur ve gradyan kaybolması sorunu yoktur.
- Karmaşık üstel hesaplama, basit hesaplama ve geliştirilmiş verimlilik yok.
- Gerçek yakınsama hızı, Sigmoid / tanh hızından yaklaşık 6 kat daha hızlıdır.
- Nöronların başarısız olmasına ve "ölü nöronlar" oluşturmasına neden olmaz.
- Çıktı ortalaması sıfırdır
- Negatif doygunluk bölgesinin varlığı, ELU'yu Leaky ReLU'dan daha sağlam ve daha güçlü anti-gürültü yeteneği yapar.
Ancak ELU, büyük miktarda hesaplama sorunu olan üstel hesaplamayı içerir.
Maxout
Maxout ilk olarak ICML2013'te ortaya çıktı ve Goodfellow tarafından önerildi. İfadesi aşağıdaki gibidir:
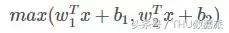
Maxout'un uygulama yeteneği çok güçlüdür, her türlü dışbükey işleve uyabilir. En sezgisel açıklama, herhangi bir dışbükey işlevin, keyfi bir hassasiyetle parçalı doğrusal bir işlevle yerleştirilebilmesi ve Maxout'un k gizli katman düğümlerinin maksimum değerini almasıdır. Bu "gizli katman" düğümleri de doğrusaldır, bu nedenle farklı Değer aralığı altında, maksimum değer parçalı doğrusal olarak da kabul edilebilir (yukarıdaki formülde k = 2).
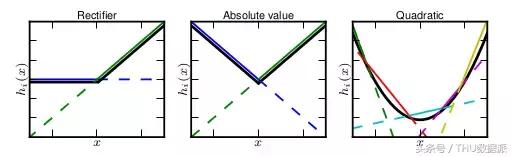
Yukarıdaki resim, "Maxout Networks. Ian J. Goodfellow, David Warde-Farley, Mehdi Mirza, Aaron Courville, Yoshua Bengio" makalesinden alıntılanmıştır. Maxout'un herhangi bir dışbükey işleve uyabileceği söylenebilir. K değeri ne kadar büyükse, o kadar çok segment. Daha iyi uyum etkisi.
Maxout, her zaman doğrusal bir bölge, doygunluk bölgesi, hızlı eğitim hızı ve nekrotik nöronların olmadığını garanti eder.
Uygun bir aktivasyon işlevi nasıl seçilir
- ReLU, hızlı olan ilk tercihtir, ancak öğrenme oranının ayarlanmasına dikkat edin.
- ReLU iyi çalışmazsa Leaky ReLU, ELU veya Maxout gibi çeşitleri kullanmayı deneyin.
- Tanh'ı deneyebilirsiniz.
- Sigmoid ve tanh, RNN (LSTM, dikkat mekanizması vb.) Yapısında geçit kontrolü veya olasılık değeri olarak kullanılır. Diğer durumlarda Sigmoid kullanımını azaltın.
- Sığ sinir ağlarında, hangi uyarma işlevinin kullanılacağının seçimi çok az etkiye sahiptir.