Kaggle yarışma yolculuğuna nasıl başlanır
Bu makale, AI Araştırma Enstitüsü tarafından derlenen, orijinal başlığı olan teknik bir blogdur:
Kaggle'da Yarışmaya Nasıl Başlanır
Yazar | Chirag Chadha
Çeviri | IinIh Editor | Demps Jeff, Wang Liyu
Orijinal bağlantı:
https://towardsdatascience.com/how-to-begin-competing-on-kaggle-bd9b5f32dbbc

İlk makine öğrenimi kursunuzu yeni tamamladıysanız, yeni öğrendiğiniz bilgileri nasıl kullanmaya başlayacağınızdan emin değilsiniz. O zaman basit bir Iris veri kümesiyle başlamalı veya Titanic verilerini alıştırma yapmalısınız (yapmanız gereken ilk şey bu olabilir). Ama daha ilginci, doğrudan başlayabilir, internette yabancılarla rekabet edebilir ve ikramiye alabilir misiniz?
Bu makaleyi okuyorsanız, Kaggle'ın yapılandırılmış (sayısal veya kategorik tablo verileri) ve yapılandırılmamış verileri (metin, resimler, ses gibi) kullanabileceğiniz bir veri bilimi rekabet platformu olduğunu zaten bilmelisiniz. , Çok sayıda makine öğrenimi konusuna katılın ve herkesin özlediği ödüller ve Kaggle altın madalyası kazanma hedefiyle. Başkalarıyla rekabet etmekten çekingen olacağınızı söyleseniz de en önemli şey oyunun sonuçlarına dikkat etmemek, daha fazlasını öğrenmek. Bu zihniyetle, oyunun ilginç, ödüllendirici ve hatta bağımlılık yapıcı hale geldiğini göreceksiniz.
İlk adım bir oyun seçmektir
İlgilendiğiniz bir oyun bulun
Yeni bir oyuna başladığınızda göz önünde bulundurmanız gereken en önemli şey budur. Bir sorunu çözmek ve verilerin tüm ayrıntılarını öğrenmek için kendinize yaklaşık iki ay vermeniz gerekir. Bu çok zaman alıyor. Çok ilgilenmediğiniz bir oyunu seçmek sizi sadece daha da ilgisiz hale getirecek ve birkaç hafta sonra oyuna katıldıktan sonra vazgeçmenizi sağlayacaktır. Oyunun zaman çizelgesine erken katılmak, size arka plan bilgisini öğrenmek ve topluluk üyeleriyle problem çözmenin tüm aşamalarında öğrenme kalitesini iyileştirmek için daha fazla zaman verecektir.
Öğrenmeye odaklanın
Oyundan sıkıldığınızı ve bunun çok zor olduğunu düşünüyorsanız, mümkün olduğunca öğrenmeye odaklanın ve ilerlemeye devam edin. Daha fazlasını öğrenebilmek için öğrenme materyallerine odaklanın. Artık liderlik tablosundaki sıralamanız için endişelenmediğinizde, belki bir atılım bulabilirsiniz.
En yüksek puana sahip çekirdeklerdeki her kod satırını anlamaya çalışın.
Sonuçları iyileştirmenin basit yolları olup olmadığını kendinize sorun. Örneğin, modelin puanını iyileştirmek için yeni özellikler oluşturabilir misiniz? Daha iyi performans elde etmek için kullandıkları öğrenme oranını biraz ayarlamak mümkün mü? Tekerleği yeniden icat etmeye çalışmak yerine asılı meyveler arayın. Bu zihniyet, hayal kırıklığına uğramamanızı sağlarken öğrenmenizi büyük ölçüde hızlandırabilir.
Kurallardaki garip kuralları kontrol edin
Bu, diğer içerik kadar önemli değil, yine de dikkat edin. Yakın tarihli bir rekabet aşağıdaki kuralı içeriyordu:
gizli bilgiler ve ticari sırlar içermemelidir ve tescilli bir patent veya halihazırda bir patent başvurusu yapan bir başvuru olamaz.
Bir kullanıcı forumda, bu çift düzenlemenin okuldan ayrılma kullanımını yasadışı hale getireceğini ve bu teknolojinin Google tarafından patentlendiğini söyledi.
Çekirdekler ve tartışma
Oyun boyunca Çekirdekleri ve tartışma alanlarını sık sık kontrol etmeniz gerekir.
Bu alana ve konuya olan ilginizin derecesini belirlemek için bazı EDA'lara (Keşif Veri Analizleri ?, Keşif Verileri Analizleri ?, Keşif Verileri Analizi?) Bakarak başlayın. Diğer kişilerin sonuçlarına göz atarken, bu modele uygun veriler için özellik mühendisliği gibi yeni fikirler üzerinde düşünürken.
Tartışma forumundaki "hoş geldiniz" yazısında çok iyi bir arka plan bilgisi sağlanmıştır.
Bu rekabet alanında bilgi edinmek faydalı olmalıdır.Bu, modelinizin nasıl çalıştığını anlamanıza yardımcı olabilir ve özellik mühendisliğinize büyük ölçüde yardımcı olabilir. Problemi anlamak için oyun mümkün olduğunca çok materyal okumaya başlamadan önce genellikle bir veya iki hafta geçiriyorum. Herkese yardımcı olmak için, yarışma organizatörlerinin çoğu forumda tanıtım yazıları oluşturacak ve bu alandaki önemli makale / makalelere bağlantılar verecek. Ayrıca, büyük veri kümelerinin nasıl çözüleceğine dair ipuçları ve verilere ilişkin temel içgörüler sağlayabilir. Elinizdeki sorun hakkında daha fazla bilgi edindiğinizde, bu süreçler her zaman kontrol etmeye ve incelemeye değer.
Veri analizini keşfedin
Neye odaklanmalısın?
Veri kümesinin ilk analizi, analiz ettiğiniz veri türüne bağlı olarak büyük ölçüde değişir. Bununla birlikte, bu kavramlar genellikle çeşitli alanlarda benzerdir ve aşağıdaki içerik, araştırmanızın belirli alanına göre ayarlanabilir. Basitlik adına, bunun yapılandırılmış veri olduğunu varsayıyoruz. Veri analizinden önce bazı temel sorular.
Hedef veriler nasıl dağıtılır?
Farklı özelliklerden önce önemli bir korelasyon var mı?
Verilerde eksik değerler var mı?
Eğitim verileri test verilerine ne kadar benzer?
Hedef veriler nasıl dağıtılır?
Yapmanız gereken ilk şey, veri setindeki her kategorinin dağılımına bakmaktır. Bir sınıf dengesizliği varsa, onu hızlı bir şekilde bulmanız gerekir, çünkü model üzerinde önemli bir etkisi olacaktır. Özellikle eğitimde, bir kategori diğer bilgi kategorilerini ezecektir. Dengesiz kategorileri çözmek için bazı teknikler vardır (örneğin, SMOTE, ADASYN, numunelerin manuel olarak çıkarılması, dengesiz veri setlerini çözmek için model parametreleri), ancak önce verilerdeki kategorilerin tek tip olup olmadığını belirlememiz gerekir. Kontrol etmenin hızlı bir yolu, popüler matplotlib kitaplığına dayanan çizim kitaplığı, seaborn'dan geçmektir.
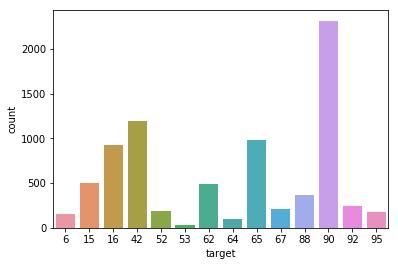
Çok kategorili dengesiz hedefler
Verilerde 90 kategorisinin fazlasıyla temsil edildiğini görebiliriz. Yukarıda bahsedilen SMOTE ve diğer teknikler daha dengeli bir veri seti oluşturabilir. Buna karşılık, model daha önce hiç görülmemiş ve denge problemleri olmayan verilere daha iyi genişletilebilir.
Özellikler arasında önemli bir korelasyon var mı?
Özellikler arasındaki Pearson korelasyon katsayısının hesaplanması, özelliklerde son derece yararlı bilgiler elde edebilir. Özelliklerin ilgili olup olmadığını bilmek, özellik mühendisliği yapmamıza veya gereksiz veri sütunlarını kaldırmamıza yardımcı olabilir. Örneğin, aşağıda gösterilen ısı haritasında, EXT_SOURCE_1, bir dış kaynak tarafından sağlanan kredi başvurusunda bulunan kişinin kredi notudur. Başvuru sahibinin gün cinsinden hesaplanan yaşı olan DAYS_BIRTH, EXT_SOURCE_1 ile negatif korelasyonludur. Bu, başvuru sahibinin yaşının EXT_SOURCE_1 hesaplamasına dahil edildiği anlamına gelebilir. Genel olarak konuşursak, model için fazladan bilgi sağlayan diğer özelliklerle (doğrusal korelasyon olarak adlandırılır) doğrusal olarak birleştirilebilen bir özelliği dahil etmekten kaçınmak istiyoruz.


Sayısal özellikler arasındaki pozitif ve negatif Pearson korelasyon katsayılarını gösteren ısı haritası
Verilerde eksik değerler var mı?
Her zaman mümkün olduğunca az eksik değer içeren eksiksiz bir veri kümesi elde ettiğinizden emin olmak istersiniz. Örneğin, model çok önemli bir özellik bulursa, ancak özellikteki çok sayıda satırın eksik değerler olduğunu tespit ederse, eksik değerleri girerek modelin performansını büyük ölçüde artırabilirsiniz. Bu, özelliğin değerini NaN içermeyen benzer satırlarla çıkararak yapılabilir. Diğer bir yol (dolgu olarak adlandırılır), eksik değerleri bir sonraki boş olmayan değerle doldurmaktır. Bir özellikteki boş olmayan verilerin ortalaması, medyan veya modu bazen eksik değerleri tahmin etmek için kullanılır. Pandas.DataFrame.fillna yöntemi, eksik değer sorunuyla başa çıkmak için bazı farklı seçenekler sunar.Bu Kaggle Çekirdeği de okumaya değer yararlı bir kaynaktır.
Ancak, eksik değerler her zaman hiçbir verinin kaydedilmediği anlamına gelmez. Bazen, bir özelliğe NaN'nin dahil edilmesi mantıklıdır, bu durumda yukarıdaki yöntem bu veri satırı için geçerli değildir. Örneğin, ikili hedefleri (başvuru sahibinin başvurusunun onaylanıp onaylanmadığı) içeren bir kredi başvurusu veri kümesi, bir başvuru sahibinin bir araca sahip olup olmadığının özelliklerini içerir. Bir kişinin arabası yoksa, otomobil tescil tarihi ile ilgili başka bir özellik, doldurulacak bilgi olmadığı için bir NaN değeri içerecektir.
Eğitim verileri ve test verileri ne kadar benzer?
Pandas DataFrame nesnesi, maksimum değer, ortalama değer, standart sapma, 50. yüzdelik değer vb. Gibi veri kümesindeki özelliklerin istatistiksel bilgilerini sağlayabilen pandas.Dataframe.describe yöntemini içerir. Bu yöntem başka bir DataFrame döndürür, böylece istediğiniz ek bilgileri ekleyebilirsiniz. Örneğin, her bir sütundaki eksik değerlerin sayısını kontrol etmek için bir satır ekleyebilirsiniz. Uygulanan işlev aşağıdaki gibidir:
Bu, eğitim seti ve test setindeki özelliklerin benzerliğini hızlı bir şekilde kontrol etmenizi sağlayan çok kullanışlı bir yöntemdir. Ancak tek bir değere sahip olmak istiyorsanız, eğitim seti ile test seti arasındaki tanışma derecesini iyi anlayabilirsiniz. Daha sonra rakip doğrulama yöntemini kullanın. Bu kelime dağarcığı kulağa korkutucu gelebilir, ancak teknolojiyi anladıktan sonra çok basit. Tartışmalı doğrulama aşağıdaki adımları içerir:
Büyük bir veri kümesi oluşturmak için eğitim ve test veri setlerini birleştirin
Tüm eğitim satırlarında hedef özelliği 0 olarak ayarlayın
Hedef özelliği tüm test satırlarında 1 ile doldurun (bunun ne yaptığını daha sonra bileceksiniz)
Verilerden hiyerarşik kıvrımlar oluşturun (uygulamayı sklearn'de doğrudan kullanabilirsiniz)
LightGBM modelini veya diğer modelleri eğitim katına yerleştirin ve doğrulama katını doğrulayın
Tüm veri seti üzerinde doğrulama tahminleri yapın ve ROC eğrisini hesaplayın (alıcı çalışma karakteristik eğrisinin altındaki alan). Bu alanı hesaplamak için bu uygulamayı kullanıyorum.
0.5'lik ROC eğrisinin altındaki alan, modelin sütun eğitimi ve test satırları arasında ayrım yapamayacağı anlamına gelir, bu nedenle iki veri seti benzerdir. Alan 0,5'ten büyükse, model eğitim ve test setleri arasında bazı farklılıklar görebilir, bu nedenle modelinizin test sırasında tahminler yapabilmesini sağlamak için verileri derinlemesine incelemeye değer.
Bu tekniğe hakim olmanıza yardımcı olacak aşağıdaki iki çekirdeği buldum:
-
https://www.kaggle.com/tunguz/adversarial-santander
-
https://www.kaggle.com/pnussbaum/adversarial-cnn-of-ptp-for-vsb-power-v12
Neden ağaç temelli bir modelle başlamalısınız?
Başlangıçta doğru modeli belirlemek önemlidir ve yarışmaya ilk katılmaya başladığınızda çok kafa karıştırıcı olabilir. Yapılandırılmış verilerle uğraştığınızı ve model oluşturmaya girmeden önce verilerin dahili bilgilerini almak istediğinizi varsayalım. Yeni bir yarışmaya girdiğinizde, verileri LightGBM veya XGBoost modeline atmak çok uygundur. Hepsi ağaç temelli kaldırma modelleridir ve çok yorumlanabilir ve anlaşılması kolaydır. Her ikisi de segmentasyonunu çizme fonksiyonunu sağlar.Bu fonksiyon çok kullanışlıdır, maksimum derinlik = yaklaşık 3 olan bir ağaç yaratır ve model segmentasyonu için kullanılan özellikleri baştan doğru bir şekilde görüntüleyebilirsiniz.
Lightgbm.Booster.feature_importance yöntemi, model için en önemli özellikleri verir; bu, modelin belirli bir özellik (önemli tür = "segmentasyon") veya belirli bir özellik üzerindeki her bölme üzerinde kaç bölünme yaptığıdır. Ne kadar bilgi elde edildiği açısından (önemli tür = "elde edilen"). Özelliklerin önemini görmek, anonim veri kümelerinde özellikle yararlıdır. Bu veri kümelerinde, en iyi 5 özelliği edinebilir ve özelliklerin ne olabileceğini anlayabilir ve model için önemlerini anlayabilirsiniz. Bu, özellik mühendisliğine büyük ölçüde yardımcı olabilir.
GPU kullanmasanız bile, LightGBM'nin eğitim hızının çok hızlı olduğunu göreceksiniz. Son olarak, bu iki model için mükemmel belgeler var ve yeni başlayanlar bunları öğrenirken herhangi bir sorun yaşamamalı.
Değerlendirme
Güvenilir bir model değerlendirme yöntemini nasıl kullanacağınızı bilmeden, rekabette en iyi performans gösteren modeli elde etmenin hiçbir yolu yoktur. Yarışmaya katılmadan önce resmi değerlendirme göstergelerini anlamak önemlidir. Gönderinizin nasıl değerlendirildiğini tam olarak öğrendikten sonra, eğitim ve doğrulamada resmi değerlendirme ölçütlerinin kullanıldığından emin olmalısınız (uygun bir uygulama yoksa kendi sürümünüzü kullanın). Değerlendirme göstergelerini güvenilir bir doğrulama setiyle birleştirmek, gönderim sırasında tekrarları önleyebilir ve hızlı ve sık sık test edilip doğrulanabilir. Lei Feng Ağı Lei Feng Ağı Lei Feng Ağı
Ek olarak, model değerlendirmesini ayarlamak için sonunda tek bir değer kullanmak istiyorsanız. Eğitim kaybını ve doğrulama kaybını veya doğruluk, geri çağırma oranı, F1 puanı, AUROC vb. Dahil olmak üzere bir dizi göstergeyi görüntüleyin. Bunlar gerçek ürünlerde çok faydalıdır, ancak oyunda istediğiniz şey bir sayıyı hızlıca görebilmektir ve "Bu model bir öncekinden daha iyi" deyin. Yine bu değerin resmi bir gösterge olması gerekiyor. Değilse, bunu yapmamak için iyi bir nedeniniz olmalıdır.
Yukarıdaki önerileri izlerseniz, sonuçları düzenli deneylerde izlemek için güvenilir bir yola ihtiyacınız vardır. Bir Docker kapsayıcısında çalışan MongoDB örneğini kullanmayı seviyorum. Değerlendirme komut dosyamın her yürütülmesinden sonra model, parametreler ve doğrulama puanı bu örneğe gönderilir. Her model için bir tablo (veya MongoDB'de koleksiyon) kaydediyorum. Birkaç deney yaptıktan sonra, hızlı göz atmak için kaydı MongoDB.archive dosyası ve bir csv dosyası olarak bilgisayarımın yerel dizinine indirdim. Kod orijinal metinde.
İşte bir açıklama: Kayıt sonuçlarının nasıl ele alınacağına dair farklı düşünce okulları var. Bu benim tercih ettiğim yöntem, ancak diğer veri bilimcilerin bununla nasıl başa çıktığını bilmek istiyorum!
Chirag Chadha, Dublin, İrlanda'daki UnitedHealth Group / Optum'da bir veri bilimcisi. Bu e-postayı onunla (chadhac@tcd.ie) LinkedIn ile iletişim kurmak için kullanabilir veya Kaggle ve GitHub'da takip edebilirsiniz.
Bu makalenin ilgili bağlantılarını ve referanslarını görüntülemeye devam etmek istiyor musunuz?
Tıklamak Bir kaggle yarışmasına nasıl başlanır] Şu adresi ziyaret edebilirsiniz:
https://ai.yanxishe.com/page/TextTranslation/1698
Başkan bugün şunları tavsiye ediyor: Yapay zeka tanıtımı, büyük veri ve makine öğrenimi hakkında ücretsiz eğitimler
Sınırlı bir süre için 35 birinci sınıf orijinal öğretici açıktır. Bu tür kitap listesi, tanınmış veri bilimi web sitesi KDnuggets'ın yardımcı editörü ve aynı zamanda kıdemli bir veri bilimcisi ve derin öğrenme teknolojisi meraklısı Matthew Mayo tarafından önerilmektedir. Çok sayıda makine öğrenimi ve veri bilimi alanına sahiptir. Bilimsel araştırma ve çalışma deneyimi.
Almak için bağlantıya tıklayın: https://ai.yanxishe.com/page/resourceDetail/417