CVPR 2020 için seçilen meydan okuma kağıdı hakkında ne yazdınız?

Yazar | Megvii Araştırma Enstitüsü
[CSDN editörünün notu] Bu makale, CVPR 2020'nin içerdiği makalelerin yorumudur. Derin özellik öğrenimi için Çember Kaybı önerir ve kayıp işlevini, optimizasyona benzerlik perspektifinden iki temel öğrenme paradigması (sınıflandırma öğrenme ve örnek çift öğrenme) altında resmi olarak birleştirir. Daha fazla genelleme yoluyla, Circle Loss daha esnek bir optimizasyon yaklaşımı ve daha net bir yakınsama hedefi elde eder, böylece öğrenilen özelliklerin ayrımcılık yeteneğini geliştirir; aynı formülü kullanır, iki temel öğrenme paradigmasında, üç özellik öğrenme görevinde (insan Yüz tanıma, yaya yeniden tanıma, ince taneli görüntü alma), on veri setinde çok rekabetçi bir performans elde etti.

Sınıf etiketlerini kullanan ve etiketleri öğrenmek için pozitif ve negatif örnekleri kullanan derin özellik öğrenimi için iki temel paradigma vardır. Sınıf etiketleri kullanılırken, numune ile ağırlık vektörü arasındaki benzerliği optimize etmek için genellikle bir sınıflandırma kaybı fonksiyonu (softmax + çapraz entropi gibi) kullanmak gerekir; numune çifti etiketleri kullanılırken, ölçüm kaybı fonksiyonu (üçlü kayıp gibi) genellikle numuneyi optimize etmek için kullanılır. Benzerlik.
Bu iki öğrenme yöntemi arasında temel bir fark yoktur ve hedefleri sınıf içi benzerliği en üst düzeye çıkarmak ve sınıflar arası benzerliği en aza indirmektir. Bu açıdan bakıldığında, yaygın olarak kullanılan birçok kayıp işlevi (üçlü kayıp, softmax kaybı ve varyantları gibi) benzer optimizasyon modlarına sahiptir:
Optimize etmek ve azaltmak için bir benzerlik çifti oluşturacaklar. İçinde artış, azalmaya eşdeğerdir. Bu simetrik optimizasyon yöntemi, Şekil 1 (a) 'da gösterildiği gibi aşağıdaki iki soruna eğilimlidir.

Azaltma için yaygın olarak kullanılan optimizasyon yöntemleri ile azaltma için yeni önerilen optimizasyon yöntemleri arasında karşılaştırma
Optimizasyon esneklikten yoksundur
Cezalar kesinlikle eşittir. Başka bir deyişle, belirtilen kayıp fonksiyonu verildiğinde, gradyanın büyüklüğü açıktır ve her zaman aynıdır. Örneğin, Şekil 1 (a) 'da gösterilen A noktası, zaten çok küçüktür, ancak daha büyük bir eğime tabi olmaya devam edecektir. Bu fenomen verimsiz ve mantıksız.
Yakınsama durumu net değil
Optimizasyonla elde edilen karar sınırı (m marjdır). Bu karar sınırı, sınırdaki herhangi iki noktanın (ve gibi) eşit zorluk derecesini korumaya paraleldir.Bu karar sınırı, belirsiz bir yakınsama durumuna izin verir. Örneğin, ve her ikisi de hedefini karşılar, ancak ikisini karşılaştırırken, ikisi arasındaki ayrımın yalnızca 0,1 olduğunu, bu da özellik uzayının ayrılabilirliğini azaltır.

Giriş
Bu nedenle Megvii Araştırma Enstitüsü, farklı hızlarda öğrenmeye izin vermek ve öğrenmek için genelleme yaparak çok basit bir değişiklik yaptı.
Özellikle ve doğrusal fonksiyonlar olarak ve sırasıyla öğrenme hızını optimizasyon durumuna uyarlamak için uygulanır. Benzerlik puanı optimal değerden ne kadar saparsa, ağırlıklandırma faktörü o kadar büyük olur. Bu tür bir optimizasyonla elde edilen karar sınırı, bu arayüzün uzayda dairesel bir yay olduğunu kanıtlayabilmektedir.Bu nedenle, yeni önerilen bu kayıp fonksiyonuna, daire kaybı fonksiyonu olan Circle Loss adı verilmektedir.
Şekil 1 (a) 'dan indirgemenin esnek olmayan optimizasyona yol açması (A, B ve C'nin gradyanlarının tümü ve'ye eşittir) ve yakınsama durumunun net olmadığı (karar sınırında hem T hem de T kabul edilebilir) görülebilir; Circle Loss'a karşılık gelen Şekil 1 (b) 'de, azaltma eğimini dinamik olarak ayarlayacak ve böylece optimizasyon sürecini daha esnek hale getirecektir.
A durumu için çok küçüktür (ve zaten yeterince küçüktür), bu nedenle odak noktası artmaktır; B durumu için ise büyüktür (ve zaten yeterince büyüktür), bu nedenle odak noktası azaltmaktır. Ek olarak, bu makale ayrıca dairesel karar sınırındaki belirli T noktasının (yayın teğet noktası ve 45 derece köşegen) yakınsamaya daha elverişli olduğunu buldu. Bu nedenle, Circle Loss daha esnek bir optimizasyon yaklaşımı tasarlayarak daha net bir optimizasyon hedefine yol açtı.
Circle Loss çok basittir, ancak derin özellik öğrenimi için önemi çok önemlidir ve aşağıdaki üç yönüyle kendini gösterir:
1. Birleştirilmiş (genelleştirilmiş) bir kayıp işlevi. Birleşik benzerlik eşleştirme optimizasyonu perspektifinden, iki temel öğrenme paradigması (yani kategori etiketlerinin kullanımı ve örnekler kullanarak etiketlerin öğrenilmesi) için birleşik bir kayıp işlevi önerir;
2. Esnek optimizasyon yöntemi. Eğitim sırasında, gradyan geri yayılımı genliği ağırlığa göre ayarlayacak veya ayarlayacaktır. Yetersiz optimize edilmiş bu benzerlik puanlarına daha büyük bir ağırlıklandırma faktörü atanacak ve bu nedenle daha büyük bir güncelleme gradyanı elde edilecektir. Şekil 1 (b) 'de gösterildiği gibi, Circle Loss'da, A, B ve C'nin üç durumuna karşılık gelen optimizasyonlar farklıdır.
3. Açık bir yakınsama durumu. Bu dairesel karar sınırında, Circle Loss belirli bir yakınsama durumunu tercih eder (Şekil 1 (b) 'de T). Bu açık optimizasyon hedefi, özellik ayrımcılığını iyileştirmeye yardımcı olur.

Birleşik benzerlik optimizasyonu perspektifi
Derin özellik öğrenmenin optimizasyon amacı, maksimize etmek ve en aza indirmektir. İki temel öğrenme paradigmasında, iyi bilinen sofmax kaybı ve üçlü kayıp gibi kullanılan kayıp fonksiyonları genellikle oldukça farklıdır.
Örnek çiftleri arasındaki benzerlik (benzerlik çifti etiketleri durumunda) veya örnek ile sınıf temsili arasındaki benzerlik (kategori etiketleri durumunda) olsun, benzerlik hesaplamasının spesifik yöntemini umursamıyorum. Bu makale sadece böyle varsayımsal bir tanım yapmaktadır: özellik uzayında tek bir örnek x verildiğinde, x ile ilgili K sınıf içi benzerlik puanları olduğunu ve x ile ilişkili L sınıflar arası benzerlik puanları olduğunu varsayalım.
En üst düzeye çıkarma ve en aza indirme optimizasyon hedefine ulaşmak için, bu makale tüm ve çiftleri eşleştirmeyi önerir ve tüm benzerlik çiftlerini kapsamlı bir şekilde numaralandırarak ve ikisi arasındaki farkı azaltarak aşağıdaki birleşik kayıp işlevi elde edilir:

Bu formül, AM-Softmax kaybı gibi yalnızca küçük bir değişiklik ile ortak üçlü kaybı veya sınıflandırma kaybını elde etmek için düşürülebilir:

Veya üçlü kayıp:
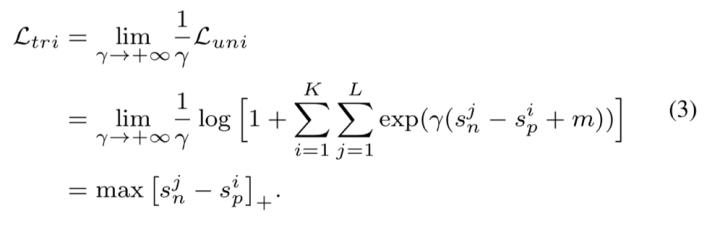

Çember Kaybı: Kendi hızınızda ağırlıklandırma yöntemi
Şimdilik (1) denklemindeki m marj terimini ve ağırlığı göz ardı edin ve yeni önerilen Çember Kaybını elde edin:

Yeniden tanımlamanın optimal değeri, ve s_n'nin optimal değeri; 'dir. Bir benzerlik puanı optimum değerden uzaklaştığında, Circle Loss daha büyük bir ağırlık atar ve böylece ona güçlü bir optimizasyon güncellemesi yapar. Bu nedenle, bu makale aşağıdaki tanımları kendi hızınıza göre verir:

Sınıf içi marj ve sınıflar arası marj
Circle Loss'taki optimize edilmiş kayıp fonksiyonundan farklıdır ve asimetriktir. Bu makale, marjları ve her biri için marjları tanımlar, böylece marjlı son Circle Loss elde edilebilir:

Karar sınırını türeterek, bu makale _n ve _p'yi daha ayrıntılı analiz eder. Basitlik uğruna, burada karar sınırının elde edildiği bir ikili sınıflandırma durumu var. Denklem (5) ve (6) 'ya göre karar sınırı elde edilebilir:

onların arasında .
Circle Loss'un 5 hiper parametresi vardır, yani ,,, ve. Toplayarak,,,. Denklem (7) şunlara indirgenebilir:
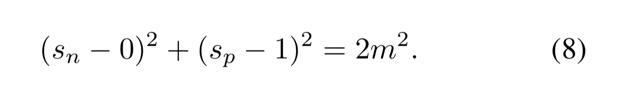
Denklem (8) ile tanımlanan karar sınırına bağlı olarak, Daire Kaybının başka bir yorumu yapılabilir. Amaç optimize etmektir ve. M parametresi karar sınırının yarıçapını kontrol eder ve bir gevşeme faktörü olarak kabul edilebilir.
Başka bir deyişle, Circle Loss bekler ve. Bu nedenle, sadece iki hiperparametre vardır, yani genişleme faktörü ve gevşeme faktörü.

Avantaj
Circle Loss'un gradyanları:
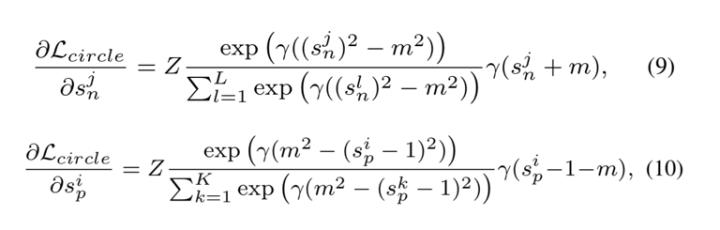
Şekil 2 (c), ikili sınıflandırmanın deneysel sahnesinde farklı m değeri ayarlarının gradyanını görselleştirir.Şekil 2 (a) ve (b) 'de üçlü kayıp ve AMSoftmax kaybının gradyanını karşılaştırarak, Circle Loss'un şu avantajlara sahip olduğunu görebiliriz: Dengeli optimizasyon s_n ve s_p üzerinde gerçekleştirilebilir, gradyan kademeli olarak zayıflar ve yakınsama hedefi daha net olacaktır.

Kayıp fonksiyonunun gradyanı: (a) üçlü kayıp; (b) AMSoftmax kaybı; (c) yeni önerilen Circle kaybı
Yukarıdaki şekildeki görselleştirme sonuçları, hem üçlü kaybın hem de AMSoftmax kaybının optimizasyon esnekliğinden yoksun olduğunu göstermektedir. (Soldaki resim) ve (sağdaki resim) ile ilgili gradyanları kesinlikle eşittir ve yakınsamada keskin bir düşüş (benzerlik çifti B) vardır. Örneğin, A'da, sınıf içindeki benzerlik puanı 1'e yakındır, ancak yine de büyük bir eğim vardır. Ek olarak, karar sınırı paraleldir ve bu da belirsiz bir yakınsamaya yol açar.
Buna karşılık, yeni önerilen Çember Kaybı, benzerlik puanı ile optimum değer arasındaki mesafeye göre benzerlik puanına dinamik olarak farklı gradyanlar atayabilir. A için (ve her ikisi de büyüktür), Circle Loss'un odak noktası optimizasyondur; B için, önemli bir düşüş nedeniyle, Circle Loss gradyanını azaltacak ve bu nedenle hafif bir optimizasyon uygulayacaktır.
Circle Loss'un karar sınırı daireseldir ve düz çizgi ile net bir teğet noktasına sahiptir ve bu teğet noktası açık bir yakınsama hedefi olacaktır. Bunun nedeni, aynı kayıp değeri için kesim noktasının sınıflar arası en küçük boşluğa sahip olması ve bakımı en kolay olmasıdır.
Deney
Bu makalede, Çember Kaybı, üç özellik öğrenme görevi (yüz tanıma, yaya yeniden tanıma ve ince taneli görüntü alma) üzerinde kapsamlı bir şekilde değerlendirilmektedir. Sonuçlar aşağıdaki gibidir:

Farklı omurga ağları ve kayıp fonksiyonları kullanılarak MFC1 veri setinde elde edilen tanıma sıra-1 doğruluğu (%)

ResNet34 omurga ağını kullanarak LFW, YTF ve CFP-FP'de yüz tanıma doğruluğu

IJB-C 1: 1 doğrulama görevinde gerçek kabul oranının (%) karşılaştırılması

Yayaların yeniden tanımlanması görevinde Çember kaybının değerlendirilmesi. R-1 doğruluğu (%) ve mAP (%) burada rapor edilir

CUB-200-2011, Cars196 ve Stanford Online Ürünlerindeki mevcut en iyi sonuçlarla bir karşılaştırma, işte R @ K (%)
Yukarıdaki üç görevde Circle Loss'un çok güçlü bir rekabet gücü gösterdiği görülebilir. Yüzde, sınıflandırma modunu kullanarak, Circle Loss, alandaki önceki en iyi yöntemleri (AM-Softmax, ArcFace gibi) geride bırakıyor; örnek çifti öğrenme yöntemlerini kullanarak ince taneli erişimde, Circle Loss bu alandaki önceki yöntemlerle karşılaştırılabilir. En yüksek yöntem (Multi-Simi gibi).
Geçmişte, bu iki paradigma altındaki kayıp fonksiyonu formlarının genellikle oldukça farklı olduğunu ve Circle Loss'un yukarıdaki performansı elde etmek için tam olarak aynı formülü kullandığını ve her parametrenin daha iyi yorumlanabilirliğe sahip olduğunu belirtmek gerekir.
Yakınsama durumunun analizi üzerine yapılan aşağıdaki deney, Circle Loss'un optimizasyon özelliklerini daha da ortaya koymaktadır.

Circle Loss yakınsaklık analizi
Şekil 3 koordinatlarda yakınsamadan önceki ve sonraki benzerlik durumunu gösterir. Bu makale iki duruma odaklanmaktadır:
Birincisi, yeşil dağınık noktalarla temsil edilen yakınsama sonrası durumdur;
İkinci olarak mavi birikim noktalarının yansıttığı karar yüzeyinden geçerken anın dağılım yoğunluğudur.
Şekil 3 (a) 'daki AMSoftmax ve (b)' deki Circle Loss teğet karar yüzeylerine sahiptir. Yakınsamadan sonra Circle Loss'un yakınsama durumunun daha yakın olduğu görülebilir. Dahası, bu durumların tümü karar verme yüzeyinden nispeten dar bir kanaldan geçer ve sonunda birleşir.
Bu fenomen, Circle Loss için (c) 'deki daha iyi parametreler kullanıldığında daha belirgin hale gelir. Bu gözlem, deneysel bir perspektiften Circle Loss'un Şekil 1'deki belirli bir yakınsama durumuna T eğiliminde olduğu tahminini ve teorik analizini doğrulamaktadır.
Orijinal metinde, önemli süper parametrelerin etkisini ve eğitim süreci boyunca değişen benzerlik sürecini analiz etmek için daha derinlemesine deneyler var. CVPR 2020 sözlü sunumu ve bildiri iletişiminden önce hızlı bir bakış için https://arxiv.org/pdf/2002.10857.pdf adresine gidebilirsiniz.
sonuç olarak
Bu makale, derin özellik öğrenimi hakkında iki derin anlayış geliştirdi. İlk olarak, üçlü kayıp ve yaygın olarak kullanılan sınıflandırma kaybı işlevleri dahil olmak üzere çoğu kayıp işlevi, birleşik bir dahili forma sahiptir.Tüm bunlar, sınıflar ve sınıflar arasındaki benzerliği, optimizasyon için benzerlik eşleşmelerine yerleştirir. İkinci olarak, benzerlik eşleştirmesi içinde, her benzerlik puanının ideal durumdan sapma derecesi göz önünde bulundurularak, onlara farklı optimizasyon güçleri verilmelidir.
Bu iki anlayışı birleştirdiğinizde Circle Loss elde edersiniz. Her benzerlik puanının farklı bir hızda öğrenmesine izin veren Circle Loss, derin özellik öğrenmeye daha esnek bir optimizasyon yolu ve daha net bir yakınsama hedefi sağlar; ve iki temel öğrenme paradigması sağlar (örnek çifti ve sınıflandırma öğrenme) Birleşik bir yorum ve birleşik bir matematiksel formül.
Circle Loss, yüz tanıma, yaya yeniden tanıma ve ince taneli görüntü alma gibi çeşitli derin özellik öğrenme görevlerinde son derece rekabetçi bir performans elde etti.
Kağıt bağlantısı:
https://arxiv.org/abs/2002.10857