League of Legends takım savaşlarını nasıl yönetiyor? AI, karar vermenize yardımcı olur (kaynaklarla)

Kaynak: Heart of the Machine
Bu makale hakkında 2450 Word, önerilen okuma 5 dakika.
Bu makale AI yapay zeka teknolojisi aracılığıyla League of Legends ekibinin karar verme düzeyini iyileştirmenin yollarını tanıtıyor.
League of Legends, zımni takım çalışması gerektiren çok oyunculu bir savaş oyunudur. Sürekli değişen savaşta, doğru kararın nasıl alınacağı çok önemlidir. Son zamanlarda, veri analisti Philip Osborne, ekibin League of Legends'taki karar verme düzeyini iyileştirmek ve onu açık kaynak olarak sunmak için yapay zeka teknolojisini kullanma yöntemi önerdi. Bu yöntem yalnızca çok sayıda gerçek oyunun istatistiksel sonuçlarını ifade etmekle kalmaz, aynı zamanda mevcut oyuncunun tercihlerini de sayar.

Proje üç bölümden oluşmaktadır, MOBA oyunu "League of Legends" savaşını bir Markov karar süreci olarak modellemeyi ve ardından en iyi kararı bulmak için pekiştirmeli öğrenmeyi uygulamayı amaçlamaktadır.Bu karar aynı zamanda oyuncunun tercihlerini de dikkate alır ve basit "skor tahtası" istatistiklerinin ötesine geçer.
Yazar, modelin her bir parçasını herkesin veri işleme ve model yapısını daha iyi anlayabilmesi için Kaggle'a yükledi:
ilk kısım:
https://www.kaggle.com/osbornep/lol-ai-model-part-1-initial-eda-and-first-mdp
ikinci kısım:
https://www.kaggle.com/osbornep/lol-ai-model-part-2-redesign-mdp-with-gold-diff
üçüncü bölüm:
https://www.kaggle.com/osbornep/lol-ai-model-part-3-final-output
Şu anda bu proje hala devam ediyor ve oyunlarda karmaşık makine öğrenimi yöntemlerinin neler yapabileceğini göstermeyi umuyoruz. Bu oyunun skoru, aşağıdaki şekilde gösterildiği gibi basit bir "skor tahtası" istatistiksel sonucu değildir:

Motivasyon ve hedefler
League of Legends, takım rekabetine dayalı bir video oyunudur.Her oyunda ikmal ve öldürme için yarışacak iki takım (her takımda beş oyuncu) vardır. Bir avantaj elde etmek, oyuncuyu rakibinden daha güçlü kılar (daha iyi ekipman elde etmek ve daha hızlı yükseltme yapmak) ve bir tarafın avantajı artmaya devam ederse, kazanma şansı da artacaktır. Bu nedenle, sonraki oyun ve oyunun yönü önceki oyuna ve duruma bağlıdır ve son taraf diğer tarafın üssünü yok edecek ve oyunu kazanacaktır.
Bunun gibi öncül durumlara dayalı modelleme yeni değil; araştırmacılar yıllardır bu yöntemi basketbol gibi sporlara nasıl uygulayacaklarını düşünüyorlar (https://arxiv.org/pdf/1507.01816.pdf). Bu sporlarda pas, top sürme, faul yapma vb. Gibi bir dizi hareket bir tarafın gol atmasına veya puan kaybetmesine neden olacaktır. Bu tür bir araştırma, basit skor istatistiklerinden (basketbolda bir oyuncu gol atar veya bir oyuncu bir maçta bir kafa kazanır) daha ayrıntılı bilgi sağlamayı ve takımın zaman içinde bir dizi olay olarak modellendiğinde nasıl çalışması gerektiğini düşünmeyi amaçlamaktadır.
Bu şekilde modelleme, League of Legends gibi oyunlar için daha önemlidir, çünkü bu tür oyunlarda oyuncular, birliklerini doldurup öldürdükten sonra ekipman ve yükseltmeler alabilirler. Örneğin, ilk öldürmeyi yapan bir oyuncu, daha güçlü ekipman satın almak için fazladan altın para kazanabilir. Bu ekipmanla, oyuncu daha güçlü hale gelir ve daha fazla kafa kazanır ve takımını nihai zafere götürene kadar böyle devam eder. Bu tür bir liderliğe "kartopu" denir çünkü oyuncu avantaj biriktirmeye devam eder, ancak çoğu durumda oyuncunun oyunda olduğu takımın baskın taraf olması gerekmez.Canavarlar ve takım çalışması daha önemlidir.
Projenin amacı basit: Oyunun önceki durumuna göre bir sonraki en iyi adımı hesaplayıp ardından gerçek oyun verilerine dayanarak nihai kazanma yüzdesini artırabilir miyiz?
Ancak bir oyunda oyuncunun kararını etkileyen pek çok faktör vardır ve bunu tahmin etmek o kadar da kolay değildir. Ne kadar veri toplanırsa toplansın, oyuncular her zaman herhangi bir bilgisayardan daha fazla bilgi alacak (en azından şimdilik!). Örneğin, bir oyunda oyuncular süper seviyede oynayabilir veya anormal oynayabilir veya belirli bir oyun tarzını tercih edebilir (genellikle seçtikleri kahramana göre tanımlanır). Bazı oyuncular doğal olarak daha agresif hale gelir ve öldürmeyi sever, bazı oyuncular ise daha pasif olur ve büyümeye devam eder. Bu nedenle, oyuncuların önerilen oyun stilini tercihlerine göre ayarlamalarına izin vermek için modeli daha da geliştirdik.
"Yapay zeka" modelini yapın
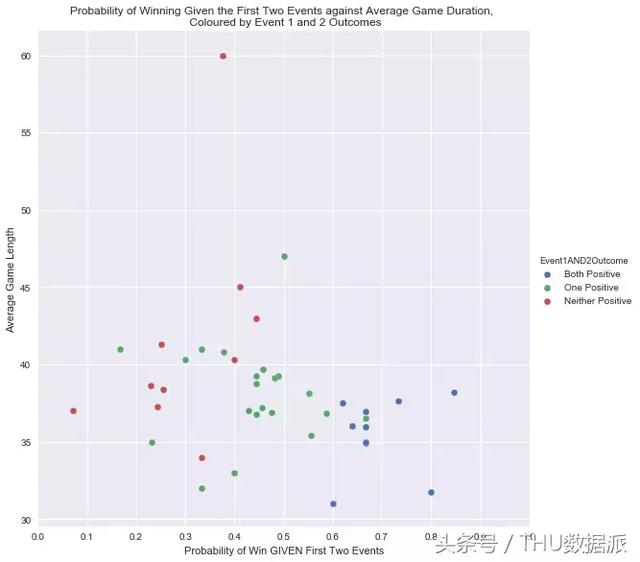
İlk bölümde, bazı giriş niteliğinde istatistiksel analizler yaptık. Örneğin, takım oyunda birinci ve ikinci piyonları oluşturuyorsa, aşağıdaki şekilde gösterildiği gibi kazanma olasılığını hesaplayabiliriz.
Projemizin basit istatistiksel yapay zekanın ötesine geçmesini sağlayan iki bileşen var:
- İlk olarak model, oyun konseptini önceden hayal etmeden hangi eylemlerin en iyi olduğunu öğrenir.
- İkinci olarak, oyuncunun modelin çıktısını etkileyen kararlar için tercihini anlamaya çalışır.
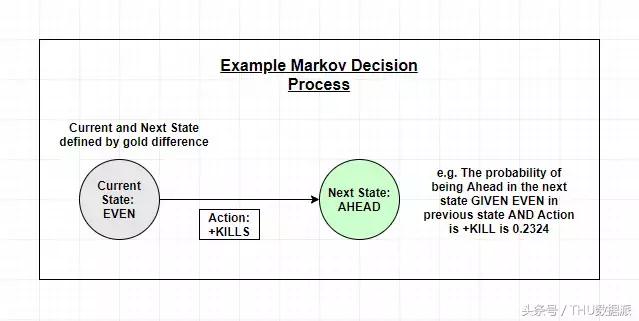
Markov karar sürecini tanımlıyoruz ve oyuncu tercihlerini toplama yöntemi, model öğrenme ve çıktının içeriğini belirleyecektir.
Eşleştirme istatistiklerine dayalı olarak Markov karar sürecini ön işleme ve oluşturma.
AI Modeli II: Para kazanma verimliliğini tanıtın
İlk modelin sonuçlarından, hem olumsuz hem de olumlu olayların gelecekte kümülatif bir etkisi olabileceğini düşünmediğimizi fark ettim. Diğer bir deyişle, mevcut MDP (Markov Karar Süreci) olasılığı, zaman noktasından önce veya sonra gerçekleşebilir. Oyunda bu yanlıştır. Geride kaldıktan sonra öldürmek, kuleleri almak ve askerleri ikmal etmek zorlaşacak, bunu dikkate almalıyız. Bu nedenle, durumu yeniden tanımlamak için takımlar arasında para oyununun etkinliğini tanıtıyoruz. Mevcut hedef, tanımlanmış bir duruma sahip bir MDP oluşturmaktır.Bu durum, olayların sırası veya takımın geride veya önde olması olabilir. Altın para farkını aşağıdaki kategorilere ayırıyoruz:
- Eşit: 0-999 altın para farkı (takım üyesi başına ortalama 0-200)
- Biraz geride / önde: 1.000-2.499 (ekip üyesi başına ortalama 200-500)
- Arkada / önde: 2.5004.999 (ekip üyesi başına ortalama 5001.000)
- Çok geride / çok ileride: 5.000 (ekip üyesi başına ortalama 1.000+)
Ayrıca herhangi bir olayın meydana gelmediği durumu da göz önünde bulundurmalı ve her dakika bir olayın meydana gelmesini sağlamak için bunu "yok" olayı olarak sınıflandırmalıyız. Bu "hiçbiri" olayı, bir takımın erken oyunda altın para kazanmada daha iyi olan takımları onları öldürmeye (veya minyonları öldürmeye) gerek kalmadan ayırt etmek için oyunu ertelemeye karar verdiği anlamına gelir. Ancak, bunu yapmak veri miktarını büyük ölçüde artıracaktır. Çünkü mevcut eşleşmeleri eşleştirmek için 7 kategori ekledik, ancak daha genel eşleşmelere erişebilirsek, veri miktarı yeterli. Daha önce de belirtildiği gibi, aşağıdaki adımları özetleyebiliriz:
Ön işlem
- Öldürme sayısını, kule sayısını, canavarlar ve altın para arasındaki farkı girin.
- "Adres" i kimlik özelliğine dönüştürün.
- Oyunun tüm eski sürümlerini kaldırın.
- Altın sikkelerdeki farktan başlayarak, toplam, etkinliğin zamanına, eşleşen kimliğe ve bir öncekiyle tutarlı olan takıma bağlıdır.
- (Yardımcı) kafa sayısını, tek sayıları ve kule sayısını sona ekleyin, her olay için bir sıra oluşturun ve olayları zamana göre sıralayın (ortalama kişi sayısı).
- Her maçtaki olayların sırasını görüntülemek için "olay sıra numarası" özelliğini ekleyin.
- Kafalar, kuleler, canavarlar veya "hiçbiri" etkinlikleri dahil olmak üzere hattaki her etkinlik için birleşik bir "etkinlik" özelliği oluşturun.
- Her eşleştiğinde, bir satıra dönüştürülür ve şimdi her olay bir sütunla temsil edilir.
- Sütunları birleştirmek ve mavi takım kazancını negatif kırmızı takım kazanımı olarak değerlendirmek için sadece kırmızı takımın bakış açısını düşünün. Aynı zamanda kırmızı takımın maç uzunluğunu ve sonuçlarını artırın.
- Tüm boş değerleri (yani, önceki adımda sona eren oyun) eşleşen oyun sonuçlarıyla değiştirin, böylece tüm satırlardaki son etkinlik, eşleşen sonuç olur.
- MDP'ye dönüştürülür, burada P (X_t | X_t-1) her olay numarası ile altın sikkeler arasındaki farkla tanımlanan durum arasındaki tüm olay türleri için kullanılır.
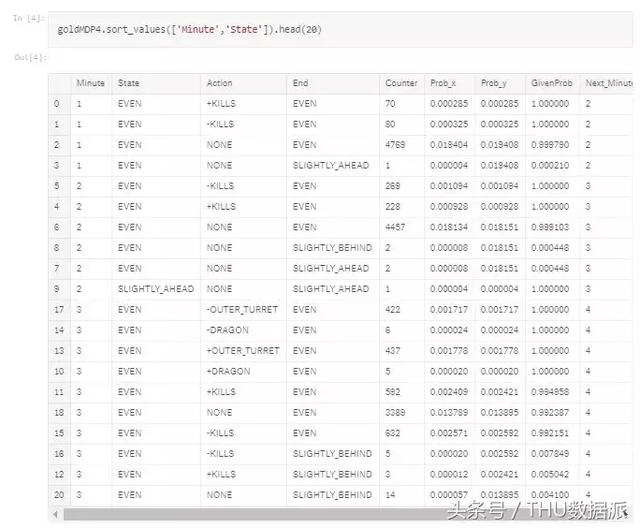
Markov karar süreci çıktısı
Basit model V6 kodunu kullanın
Modelin son hali kısaca şu şekilde özetlenmektedir:
- Parametreleri tanıtın
- Başlangıç durumunu başlat, olayı başlat, işlemi başlat
- MDP'de tanımlanan ilk teklife veya oluşma olasılığına göre rastgele seçim işlemine göre
- Aksiyon kazandığında veya kaybettiğinde biter
- Etkinlikte gerçekleştirilen eylemleri ve nihai sonucu (galibiyet / mağlubiyet) takip edin
- Son sonuçta kullanılan güncelleme kurallarına göre işlemi güncelleyin
- Yukarıdaki adımları x kez tekrarlayın
Ödül tercihlerini tanıtın
İlk olarak, model kodunu ödülü iade hesaplamasına dahil edecek şekilde ayarlıyoruz. Ardından, modeli çalıştırdığımızda, ödülü sıfıra eşitlemek yerine belirli davranışlar için bir önyargı getirdik.
- İlk örnekte, bir eylemin olumlu bir değerlendirmesi yapılırsa ne olacağını gösterdik;
- İkinci örnekte, bir eylemi olumsuz olarak değerlendirdiğinizde ne olduğunu gösterir.
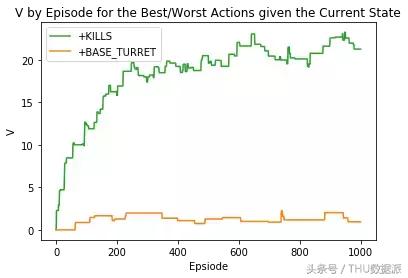
"+ KILLS" eyleminin çıktısını olumlu olarak değerlendirirsek
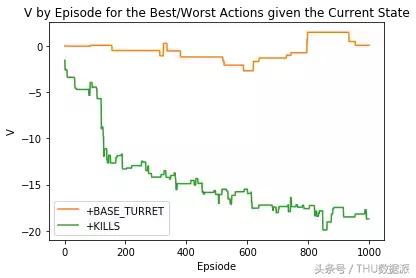
"+ KILLS" eyleminin çıktısını olumsuz olarak değerlendirirsek
Daha gerçekçi oyuncu tercihleri
Şimdi oyuncunun gerçek tercihlerine yaklaşmaya çalışabiliriz. Bu durumda, aşağıdaki iki kurala uymaya izin vermek için bazı ödülleri rastgele seçtik:
- Oyuncular herhangi bir yenilemeyi kaçırmak istemez
- Oyuncular, öldürmek yerine birliklerini yenilemeye öncelik verir
Bu nedenle, kafalar ve ikmal askerleri için ödüllerimiz minimum değer -0.05'tir ve diğer eylemler için ödüller -0.05 ile 0.05 arasında rastgele oluşturulur.
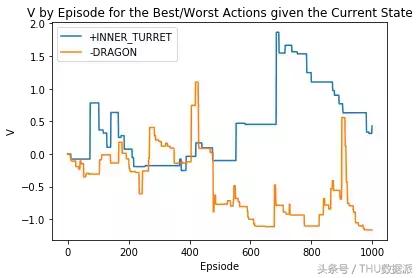
Oyuncu ödüllerini rastgele seçtikten sonra çıktı
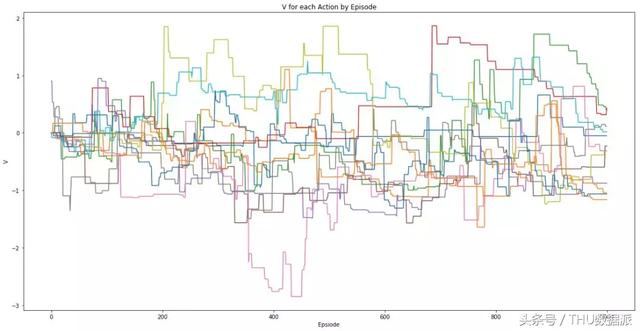
Oyuncunun tüm eylemlerinin ödüllerini rastgele hale getirdikten sonra elde edilen çıktı
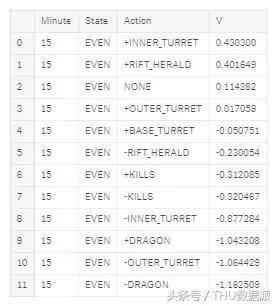
Nihai çıktı, mevcut altın para fark durumu ve dakikaya göre her bir eylemin değerini gösterir.
Ödüller hakkında özet ve oyuncu geri bildirimi
Bazı özellikleri fazla basitleştirdim ("öldürme" gibi aslında tura sayısını temsil etmiyor) ve verilerin normal bir eşleşmeyi temsil etmesi olası değil. Bununla birlikte, umarım bu makale ilginç bir kavramı açıkça gösterebilir ve daha fazla insanı bu alanın gelecekteki yönünü tartışmaya teşvik edebilir.
İlk olarak, uygulamadan önce yapılması gereken önemli iyileştirmeleri listeleyeceğim:
- Tüm oyuncu topluluğunu temsil edebilecek daha fazla veriyi kullanarak MDP'yi hesaplayın (sadece rekabetçi oyunları değil).
- Modelin verimliliğini artırın ve hesaplama süresini daha makul bir aralıkta kontrol edin. Monte Carlo'nun zaman alıcı olduğu biliniyor, bu nedenle daha verimli algoritmalar keşfedeceğiz.
- Sonuçları daha da iyileştirmek için daha gelişmiş parametre optimizasyonu kullanın.
- Prototip oyuncuların daha gerçekçi ödül sinyalleri hakkındaki geri bildirimlerini yakalayın ve haritalayın.
Modelin çıktısını etkilediğimiz için ödüller getirdik, ancak nasıl ödül alırız? Birkaç yöntemi göz önünde bulundurabiliriz, ancak önceki araştırmama dayanarak, en iyi yöntemin hem eylemin bireysel niteliğini hem de dönüşümün kalitesini içeren bir ödülü düşünmek olduğunu düşünüyorum.
Bu gittikçe daha karmaşık hale geliyor ve bunu bu makalede genişletmeyeceğim, ancak kısacası, bir sonraki en iyi kararın son duruma bağlı olduğu oyuncular için kararları eşleştirmek istiyoruz. Örneğin, bir takım oyuncular rakibi yok ederse, ejderhayı almaya gidebilirler. Modelimiz bir sıradaki olayların olasılığını hesaba katmıştır, bu nedenle oyuncunun kararını da aynı şekilde düşünmeliyiz. Bu fikir, geri bildirimin nasıl daha ayrıntılı olarak haritalandırılacağını açıklayan "DJ-MC: Müzik Çalma Listesi Önerisi için Güçlendirme-Öğrenme Aracısı" başlıklı bir makaleden gelmektedir.
Geri bildirimin toplanma şekli, modelimizin ne kadar başarılı olabileceğini belirler. Bence nihai hedefimiz, oyuncunun bir sonraki kararı için en iyi gerçek zamanlı tavsiyeyi sağlamaktır. Bu şekilde oyuncular, oyun verilerine göre hesaplanan en iyi birkaç karar (kazanarak sıralanır) arasından seçim yapabilir. Oyuncunun tercihlerini daha iyi anlamak ve anlamak için oyuncunun seçimleri birden fazla oyunda izlenebilir. Bu aynı zamanda sadece kararın sonucunu izleyemeyeceğimizi değil, aynı zamanda oyuncunun niyetini de tahmin edebileceğimiz (örneğin, oyuncu kuleyi sökmeye çalıştı ama öldürüldü) ve hatta daha gelişmiş analizler için bilgi sağlayabileceğimiz anlamına geliyor.
Elbette bu tür düşünceler takım üyeleri arasında fikir ayrılıklarına neden olabilir ve ayrıca oyunu daha az heyecanlı hale getirebilir. Ancak bu tür düşünmenin düşük veya normal seviyedeki oyuncular için faydalı olabileceğini düşünüyorum, çünkü bu seviyedeki oyuncuların oyun kararlarını net bir şekilde iletmesi zor. Bu aynı zamanda "tümör" oyuncularının belirlenmesine de yardımcı olabilir, çünkü takım, oylama sistemi aracılığıyla fikirleri birleştirmeyi umuyor ve ardından "tümör" oyuncularının takım planına uyup uymadığı ve takım arkadaşlarını görmezden gelip gelmediği görülebiliyor.
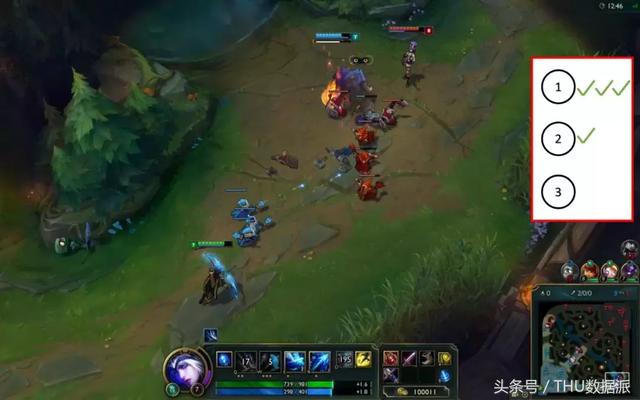
Gerçek zamanlı oyun ortamında model önerisi oylama sistemi örneği
Orijinal bağlantı:
https://towardsdatascience.com/ai-in-video-games-improving-decision-making-in-league-of-legends-using-real-match-statistics-and-29ebc149b0d0