Evrişimli sinir ağlarında görüntü bölütlemenin evrimsel tarihi: R-CNN'den Mask R-CNN'ye
Wang Xiaoxin Medium'dan derlendi
Qubit Üretildi | Genel Hesap QbitAI
Evrişimli sinir ağı (CNN) yalnızca görüntüleri sınıflandırmak için kullanılamaz, aynı zamanda görüntü bölümleme görevlerinde geniş bir uygulama alanına sahiptir.
Dhruv Parthasarathy, derin öğrenme teknolojisinde uzmanlaşmış bir sağlık hizmetleri şirketi olan Athelas için çalışıyor. Daha iyi sonuçlar elde etmek için belirli görüntü bölümleme görevlerinde evrişimli sinir ağlarının nasıl uygulanacağını anlatan Medium'da bir blog yazısı yayınladı.
Aşağıdaki içerik Parthasarathy makalesinden derlenmiştir:
Derin öğrenmenin yaratıcısı Geoff Hinton ve lisansüstü öğrencileri Alex Krizhevsky ve Ilya Sutskever, 2012 ImageNet Büyük Ölçekli Görsel Tanıma Yarışmasını kazandığından beri, Convolutional Neural Network (CNN), görüntü sınıflandırması için altın standart haline geldi. O zamandan beri, evrişimli sinir ağı gelişiyor ve şimdi ImageNet veri kümesindeki 1000 günlük nesne kategorisini ayırt etmede insanları geride bıraktı.
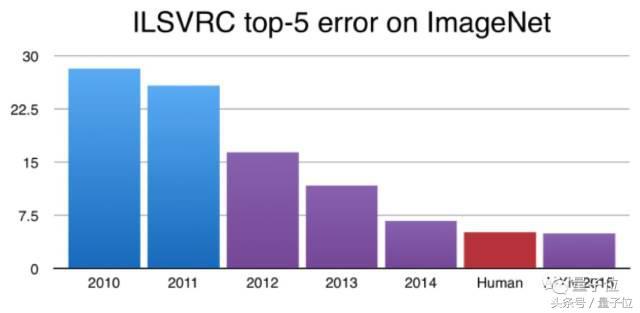
Şekil 1: CNN, ImageNet mücadelesinde insanları geride bıraktı Şekildeki y ekseni, ImageNet tanımanın hata oranıdır.
Ağ sınıflandırmasının sonuçları tatmin edici olsa da, insanın gerçek yaşamındaki görsel anlayış, görüntü sınıflandırmasından çok daha karmaşık ve çeşitlidir.

şekil 2: ImageNet sınıflandırma mücadelesinde kullanılan resim örneği: Görüntünün kenarları sağlam ve sadece bir nesne var.
Sınıflandırma görevinde, bir görüntünün genellikle yalnızca tek bir odak nesnesi vardır ve görev, bu nesnenin kategorisini söylemektir. Ancak gerçek dünyada, genellikle birden fazla nesne göreceğiz ki bu daha karmaşık bir görevdir.

resim 3: Gerçek hayattaki sahneler genellikle birçok farklı ve birbiriyle örtüşen nesnelerden, arka planlardan ve eylemlerden oluşur.
Karmaşık bir durumda, genellikle birden çok örtüşen nesne ve farklı arka planlar vardır.Bu farklı nesneleri sınıflandırmanın yanı sıra nesneler arasındaki sınırları, farklılıkları ve ilişkileri de belirlemeliyiz.

Şekil 4: Görüntü bölütlemede görev, görüntüdeki farklı nesneleri sınıflandırmak ve nesne sınırlarını belirlemektir.
Evrişimli sinir ağları bu karmaşık görevin üstesinden gelmemize yardımcı olabilir mi? Daha karmaşık görüntüler için, görüntüdeki farklı nesneleri ve bunların sınırlarını ayırt etmek için evrişimli sinir ağlarını kullanabilir miyiz? Ross Girshick ve meslektaşları, olumlu bir cevap vermek için son yıllarda araştırma çalışmalarını kullandılar.
Bu makalenin amacı
Bu makale, nesne algılama ve görüntü bölümleme için bazı temel teknolojileri tanıtacak ve ağ durumunun gelişim sürecini anlayacaktır.
Spesifik olarak, bu sorunu ilk çözen R-CNN ağını ve daha sonra geliştirilen Hızlı R-CNN ve Daha Hızlı R-CNN'yi tanıtacağız. Ayrıca bu nesne algılama teknolojisini genişleten ve piksel düzeyinde segmentasyon teknolojisi sağlayan Facebook Research grubunun yakın zamanda yayınladığı bir makale olan Mask R-CNN ağını da tanıtacağız. Bu makalede alıntılanan makaleler şunlardır:
1. R-CNN: https://arxiv.org/abs/1311.2524
2. Hızlı R-CNN: https://arxiv.org/abs/1504.08083
3. Daha hızlı R-CNN: https://arxiv.org/abs/1506.01497
4. Maske R-CNN: https://arxiv.org/abs/1703.06870
2014: R-CNN-nesne algılama için CNN kullanmanın kaynağı

Şekil 5: R-CNN ağının nesne algılama algoritması, görüntüyü analiz edebilir ve görüntüdeki ana nesnenin konumunu ve kategorisini belirleyebilir.
Toronto Üniversitesi'ndeki Hinton Laboratuvarı'nın araştırma çalışmasından esinlenerek, Berkeley'deki Kaliforniya Üniversitesi'nden Profesör Jitendra Malik liderliğindeki ekip, şimdi kaçınılmaz görünen bir soruyu gündeme getirdi:
Krizhevsky ve diğerleri tarafından önerilen ağ modelinin genelleştirilmesi nesne algılamaya uygulanabilir mi?
Nesne algılama teknolojisi, bir görüntüdeki farklı nesneleri işaretleyen ve sınıflandıran bir görevdir. Nesne algılama zorluğu PASCAL VOC'de Ross Girshick, Jeff Donahue ve Trevor Darrel'den oluşan ekip, bu sorunun Krizhevsky'nin araştırma sonuçlarıyla çözülebileceğini buldu.
Yazdılar:
Bu makale ilk olarak, daha basit HOG özelliklerine dayalı bir sistemle karşılaştırıldığında, evrişimli sinir ağlarının PASCAL VOC üzerindeki nesne algılama performansını önemli ölçüde artırabildiğini göstermektedir.
Daha sonra, Bölgeleri CNN'lerle (R-CNN) mimarisinin nasıl çalıştığına daha derinlemesine bakacağız.
R-CNN'yi anlayın
R-CNN'in amacı, görüntüyü analiz etmek, görüntüdeki ana nesneyi doğru bir şekilde tanımlamak ve nesnenin belirli konumunu sınırlayıcı kutu aracılığıyla işaretlemektir.
giriş: görüntü
Çıktı: Görüntüdeki her nesnenin sınırlayıcı kutusu ve etiketi
Ancak bu sınırlayıcı kutuların boyutunu ve konumunu nasıl belirleyeceğiz? R-CNN ağı, aşağıdaki işlemlerle sezgisel olarak gerçekleştirebileceğimiz bir görevi yerine getirir: Görüntüye birden çok çerçeve yerleştirin ve bunlardan herhangi birinin belirli bir nesneye karşılık gelip gelmediğini belirleyin.

Resim 6: Aynı dokuya, renge veya yoğunluğa sahip komşu pikselleri bulmak için birden çok kenarlık boyutunu seçerek arayın.
R-CNN ağı, bu sınırlayıcı kutuları veya bölge tekliflerini oluşturmak için seçici bir arama yöntemi kullanır. Şekil 6'da, seçici arama, görüntüyü farklı boyutlardaki çerçeveler aracılığıyla analiz eder ve her bir görüntü bloğu için, nesneleri tanımlamak için bitişik pikselleri doku, renk veya yoğunluğa göre birleştirmeye çalışır.
Seçmeli arama hakkında daha fazla bilgi edinmek için lütfen okuyun:

Şekil 7: Bir dizi bölgesel öneri oluşturduktan sonra, R-CNN ağı, bu görüntü bloklarının geçerli alanlar olup olmadığını belirlemek için her görüntü bloğunu AlexNet ağının geliştirilmiş bir sürümüne geçirecektir.
Bir bölge önerisi oluşturduktan sonra, R-CNN ağı bölgeyi standart bir kareye deforme eder ve onu geliştirilmiş AlexNet ağına girer.Özel adımlar Şekil 7'de gösterilmiştir. AlexNet, ImageNet 2012 yarışmasındaki en iyi ağdır ve R-CNN bundan ilham almıştır.
CNN'nin çıktı katmanında, R-CNN ağı, görüntünün bir nesne olup olmadığını ve ne olduğunu belirleyebilen destek vektör makinesi (SVM) yöntemini de uygular.
Sınırlayıcı kutuyu geliştirin
Şimdi, nesneyi sınırlayıcı kutuda bulabiliriz, ancak sınırlayıcı kutuyu nesnenin gerçek boyutuna sığdırmak için küçültebilir miyiz? Evet, bu bir R-CNN ağı kurmanın son adımıdır. R-CNN ağı, daha yakın sınırlayıcı kutu koordinatlarını elde etmek için bölge önerisinde basit bir doğrusal regresyon işlemi gerçekleştirir ve R-CNN ağının nihai çıktı sonucunu alır. Regresyon modelinin girdisi ve çıktısı:
giriş: Nesneye karşılık gelen görüntü alt bölgesi.
Çıktı: Alt alandaki nesnenin yeni sınırlayıcı kutu koordinatları.
Bu nedenle, R-CNN ağı aşağıdaki adımlarla özetlenmiştir:
1. Sınırlayıcı kutu için bir dizi bölgesel öneri oluşturun;
2. Önceden eğitilmiş AlexNet ağı, çerçevedeki görüntünün geçerli bir alan olup olmadığını belirlemek için kullanılır ve son olarak, çerçevedeki görüntü kategorisini belirlemek için destek vektör makinesi algoritması kullanılır;
3. Çerçeve görüntüsünün kategorisini belirledikten sonra, daha dar çerçeve koordinatlarının çıktısını almak için doğrusal bir regresyon modeli uygulanır.
2015: Hızlı R-CNN-Hızlandırma ve R-CNN'yi basitleştirme

Şekil 8: Ross Girshick, R-CNN ve Fast R-CNN'i icat etti ve Facebook Research bilgisayarla görme teknolojisinin gelişimini teşvik etmeye devam ediyor.
R-CNN ağının performansı çok iyi, ancak aslında eğitilmesi çok yavaş. Bunun birkaç nedeni var:
1. Tek bir görüntünün her alan önerisinin AlexNet ağı tarafından değerlendirilmesi gerekir ve her karar yaklaşık 2000 ileri yayılım gerektirir.
2. Bu ağ, üç farklı modeli ayrı ayrı eğitmelidir: görüntü özelliklerini çıkarmak için bir CNN ağı, kategoriyi belirlemek için bir sınıflandırıcı ve sınırı azaltmak için bir regresyon modeli. Bu ağları bu şekilde eğitmek zordur.
2015 yılında, R-CNN ağının ilk yazarı Ross Girshick, bu iki sorunu çözdü ve yeni ağ Fast R-CNN'i icat etti. Şimdi Fast R-CNN ağının ana yeniliklerini anlamaya geldik.
İnovasyon 1: Yatırım Getirisi Havuzlamasını Tanıtın
CNN'in ileri geçişi sırasında Girshick, her görüntünün birden çok bölgesinin her zaman birbiriyle örtüştüğünü fark etti ve bu da aynı CNN hesaplamasını 2000 kata kadar birçok kez çalıştırmamıza neden oldu. Onun yeniliği basit: Her görüntü üzerinde yalnızca bir kez bir CNN işlemi çalıştırıp ardından 2000 ileri yayılma sürecinde bu hesaplamanın sonuçlarını paylaşmanın bir yolunu bulabilir misiniz?

Şekil 9: RoIPool katmanında, her görüntünün tam bir ileri yayılma süreci oluşturulur ve ilgili her bölgenin dönüştürme özellikleri elde edilen ileri yayılma işleminden çıkarılır.
Bu, Fast R-CNN ağı tarafından RoIPool (İlgi Bölgesi Havuzlama) teknolojisi ile yapılan yeniliktir. Yenilik, RoIPool katmanının görüntü alt bölgesinde CNN ağının ileri yayılma sürecini paylaşmasıdır. Şekil 9'da, karşılık gelen bölgeler, her bölgenin CNN özet özelliklerini elde etmek için CNN özellik haritasından seçilir. Daha sonra, maksimum havuzlama işlemi genellikle her bölgedeki birincil soyut özellikleri birleştirmek için kullanılır. Bu nedenle, orijinal görüntünün 2000 kez yerine yalnızca bir ileri yayılma işlemi gerçekleştirdik.
İnovasyon noktası 2: Tüm modelleri tek bir ağa entegre edin

Şekil 10: Hızlı R-CNN, evrişimli bir sinir ağını, bir sınıflandırıcıyı ve azaltılmış sınırları olan bir regresyon modelini tek girişli çift çıkışlı bir ağa entegre eder.
Fast R-CNN'nin ikinci yeniliği, evrişimli sinir ağlarının, sınıflandırıcıların ve sınırlayıcı kutu regresyon modellerinin tek bir modelde ortak eğitimidir. R-CNN'de görüntü özelliklerini çıkarmak için evrişimli sinir ağları kullanıyoruz, nesneleri sınıflandırmak için vektör makinelerini ve sınırlayıcı kutuları azaltmak için regresyon modellerini destekliyoruz, ancak Hızlı R-CNN yukarıdaki üç işlevi elde etmek için tek bir ağ modeli kullanıyor .
Şekil 10, Hızlı R-CNN ağ işleminin şematik bir diyagramıdır. Hızlı R-CNN, nesne kategorilerinin çıktısını almak için SVM sınıflandırıcısını CNN çıktı katmanında softmax işleviyle değiştirir. Aynı zamanda, CNN çıktı katmanına, sınırlayıcı kutu koordinatlarının çıktısını almak için kullanılan doğrusal bir regresyon katmanı da eklenir. Böylece tek bir ağ, gerekli bilgiyi verebilir.
Tüm modelin girdisi ve çıktısı:
giriş: Birden çok alan önerisi içeren resim.
Çıktı: Daha sıkı sınırlayıcı kutuya sahip her bölge için nesne kategorisi.
2016: Daha hızlı R-CNN-Bölgesel önerileri hızlandırıyor
Fast R-CNN'nin performansı büyük ölçüde iyileştirilmiş olsa da, hala bir eksiklik var - bölge önericisi. Yukarıda bahsedildiği gibi, bir görüntüdeki bir nesnenin konumunu saptamak için ilk adım, test edilecek bir dizi rastgele çok ölçekli sınırlayıcı kutu veya bölge üretmektir. Fast R-CNN'de, oldukça yavaş bir süreç olan ve tüm sürecin kısa bir tahtası olarak kabul edilen bu bölgeleri oluşturmak için seçici arama yöntemi kullanılır.

Şekil 11: Microsoft Research'ün baş araştırmacısı Sun Jian, Faster R-CNN ağ ekibinin lideridir.
2015 yılının ortalarında Ren Shaoqing, He Yuming, Ross Girshick ve Sun Jian'dan oluşan bir Microsoft Araştırma ekibi, çerçeve oluşturma sürecindeki hesaplama miktarını neredeyse sıfıra indiren "Daha Hızlı R-CNN" adlı bir ağ yapısı keşfetti.
Daha Hızlı R-CNN'nin yeniliği, bölge önerisinin CNN'deki ilk evrişimli katman boyunca ileriye doğru yayılma sürecindeki görüntü özelliklerine bağlı olmasıdır. Öyleyse neden seçici arama algoritmasını ayrı ayrı çalıştırma ve aynı CNN sonuçlarını birden çok bölge önerilerinde yeniden kullanma şeklini değiştirmiyorsunuz?

Şekil 12: Daha Hızlı R-CNN'de, bölge önerisini ve nesne sınıflandırmasını uygulamak için tek bir CNN ağı kullanılır.
Bu tam olarak daha hızlı R-CNN ekibinin başardığı şeydir. Şekil 12, bölge önerisini ve nesne sınıflandırmasını uygulamak için tek bir CNN ağının nasıl kullanılacağını açıklar. Bu şekilde, yalnızca bir CNN ağının eğitilmesi gerekiyor ve gerekli bölgesel önerileri almak için neredeyse hiç hesaplama çabası harcamıyoruz. Yazar makaleye şunları yazdı:
Fast R-CNN ağındaki bölge detektörü tarafından kullanılan evrişim özellik haritasının bölge önerileri oluşturmak için de kullanılabileceğini ve böylelikle bölge önerilerinin hesaplama karmaşıklığını neredeyse sıfıra indirdiğini gözlemledik.
Modelin girdisi ve çıktısı:
giriş: Resim (bölge önerisine gerek yoktur).
Çıktı: Görüntüdeki nesnenin kategori ve sınırlayıcı kutu koordinatları.
Bölgeler nasıl oluşturulur
Ardından, Daha Hızlı R-CNN'nin bu bölge önerilerini CNN özelliklerinden nasıl ürettiğine bakalım. Daha hızlı R-CNN, CNN özelliklerinin üzerine bir Tam Evrişimli Ağ (FCN) ekleyerek Bölge Teklif Ağı (Bölge Teklif Ağı) olarak adlandırılan bir ağ oluşturur.
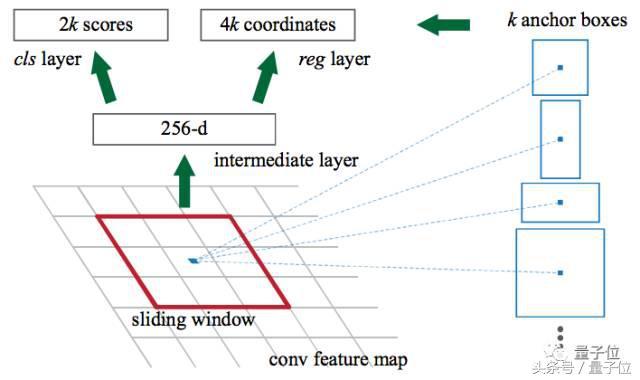
Şekil 13: Bölgesel öneri ağı, sırayla CNN özellik haritasında bir pencere kaydırır. Her pencere konumunda, ağ, her bağlantı noktasında bir puan ve bir sınırlayıcı kutu çıkarır. Bu nedenle, toplam 4k sınırlayıcı kutu koordinatı vardır; burada k, bağlantı noktalarının sayısıdır.
Bölgesel teklif ağı, bu sınırlayıcı kutuların nesneler içerme olasılığını, CNN özellik haritası üzerinde pencereleri sırayla kaydırarak ve her pencerede k olası sınırlayıcı kutu ve puanlar çıkararak değerlendirir. Bu k sınırları neyi temsil ediyor?

Şekil 14: Genel olarak, karakterli sınırlar genellikle dikey dikdörtgenlerdir. Bu tür boyutlarda konumlar oluşturarak bölgesel bir öneri ağının oluşturulmasına rehberlik etmek için bu sağduyu kullanabiliriz.
Sezgisel olarak, görüntüdeki nesnelerin belirli ortak en boy oranlarına ve boyutlarına uyması gerektiğini biliyoruz. Örneğin, insan şekillerine uyan bazı dikdörtgen kutular oluşturmak istiyoruz. Bu şekilde, çok dar bir sınırlayıcı kutuyla karşılaşıldığında, bir insan nesnesi olasılığı göz ardı edilebilir. Bu şekilde, çapa kutusu adı verilen k boyutunda evrensel bir en boy oranı oluşturuyoruz. Bu tür her bir bağlantı kutusu için, buna karşılık olarak bir sınırlayıcı kutu koordinatı ve her konum için bir puan veririz.
Bu bağlantı kutuları dikkate alındığında, bu alan için önerilen ağın girdi ve çıktıları şunlardır:
giriş: CNN özellik haritası.
Çıktı: Her bağlantı noktasının sınırlayıcı kutusu. Sınırlayıcı kutudaki görüntünün bir nesne olarak olasılığı, çıktı puanı ile temsil edilir.
Ardından, nesne sınıflandırmasını elde etmek ve sınırlayıcı kutuyu daraltmak için, yalnızca hedef nesne olabilecek her bir sınırlayıcı kutuyu Hızlı R-CNN'ye iletiriz.
2017: Piksel düzeyinde segmentasyon için Mask R-CNN-Extended Faster R-CNN

Şekil 15: Görüntü segmentasyonunun özel amacı, piksel seviyesindeki bir sahnede farklı nesnelerin kategorilerini belirlemektir.
Şimdiye kadar, bir görüntüdeki farklı nesneleri bulmak için sınırlayıcı kutuları etkili bir şekilde kullanmak için CNN özelliklerini birçok ilginç şekilde nasıl kullanacağımızı öğrendik.
Sadece sınırla sınırlı olmak yerine her nesnenin kesin piksellerini bulmak için bu teknikleri daha da genişletebilir miyiz? Bu problem, klasik görüntü segmentasyon problemidir. He Yuming ve Girshick gibi araştırmacılar, bu sorunu keşfetmek için Facebook'un yapay zeka araştırma departmanında Mask R-CNN adlı bir ağ yapısı kullandılar.

Şekil 16: Facebook'un yapay zeka araştırma bölümünde bir araştırmacı olan He Yuming, Mask R-CNN ağının ana yazarı ve Fast R-CNN'in ortak yazarıdır.
Fast R-CNN ve Faster R-CNN'ye benzer şekilde, Mask R-CNN'nin temel fikri basit ve sezgiseldir: Daha hızlı R-CNN, nesne algılamada çok iyi çalışır, bu yüzden onu genişletebilir ve piksel düzeyinde segmentasyona uygulayabiliriz ?

Şekil 17: Mask R-CNN'de, bir maske (segment çıkışı) oluşturmak için Faster R-CNN'nin CNN özelliğinin üstüne bir Tam Evrişimli Ağ (Tam Evrişimli Ağ) eklenir. Ağın maske çıktısının nesne sınıflandırıcı ve Faster R-CNN ağının sınırlayıcı kutu regresyon ağına paralel olarak nasıl uygulandığına özellikle dikkat edin.
Maske R-CNN, belirli bir pikselin nesnenin parçası olup olmadığını belirtmek için bir ikili maske çıkarmak için Daha Hızlı R-CNN ağına bir dal ekler. Şekil 17'deki beyaz dal, CNN özellik haritasındaki tamamen evrişimli bir ağdır.
Modelin girdisi ve çıktısı:
giriş: CNN özellik haritası.
Çıktı: Pikselin nesneye ait olduğu tüm konumlarda 1'li ve diğer konumlarda 0'lı bir matris vardır.Bu kurala ikili maske adı verilir.
Ancak Mask R-CNN ağının yazarı, bu eğitimin beklendiği gibi ilerlemesi için küçük bir ayarlama yapmak zorunda kaldı.
RoiAlign: Sonucu daha doğru hale getirmek için RoIPool'u yeniden hizalayın

Şekil 18: Görüntü, RoIPool teknolojisini atar ve onu RoIAlign teknolojisinden geçirir, böylece RoIPool tarafından seçilen özellik haritası alanı orijinal görüntünün alanına daha doğru bir şekilde karşılık gelir. Bu gereklidir, çünkü piksel düzeyinde bölümleme, koordinatları belirlemek için sınırlayıcı kutuları kullanmaktan daha ince piksel hizalaması gerektirir.
Mask R-CNN'nin yazarı, orijinal Faster R-CNN ağ yapısında, RoIPool tarafından seçilen özellik haritası alanının orijinal görüntünün alanıyla biraz hizasız olduğunu buldu. Görüntü bölütleme, kare belirleme sürecinden farklı olan piksel düzeyinde özgüllük gerektirdiğinden, bu doğal olarak yanlışlığa yol açar.
Yazar, daha doğru hizalama elde etmek için RoIPool yöntemini ayarlayarak bu sorunu akıllıca çözdü.Bu ayarlanmış yönteme RoIAlign yöntemi denir.

Şekil 19: Orijinal görüntünün ilgilendiği bölgeyi özellik haritası ile nasıl doğru bir şekilde eşleştirebiliriz?
128x128 boyutunda bir resmimiz ve 25x25 boyutunda bir özellik haritamız olduğunu varsayalım. Orijinal görüntünün sol üst köşesindeki 15x15 piksel alanını özellik haritasında temsil etmek istersek, bu pikselleri özellik haritasından nasıl seçebiliriz?
Özgün görüntüdeki her pikselin özellik haritasında 25/128 piksele karşılık geldiğini biliyoruz. Orijinal görüntüden 15 piksel seçmek için, özellik haritasında 15 * (25/128) = 2.93 piksel seçiyoruz.
RoIPool'da, ondalık noktadan sonraki kısmı atacağız ve sadece 2 piksel seçeceğiz, bu da hafif bir yanlış hizalamaya neden olacaktır. Ancak, RoIAlign'de bu tür terk edilmekten kaçınıyoruz. Bunun yerine, 2.93 pikseldeki bilgileri doğru bir şekilde elde etmek için çift doğrusal enterpolasyon kullanıyoruz. Bu, büyük ölçüde RoIPool yönteminin neden olduğu piksel yanlış hizalamasını önler.
Mask R-CNN bu maskeleri oluşturduktan sonra, harika bir şekilde doğru bir segmentasyon oluşturmak için bunları daha Hızlı R-CNN çıktı katmanının nesne kategorileri ve sınırlayıcı kutuları ile birleştirir.

Şekil 20: Mask R-CNN, görüntülerdeki nesneleri segmentlere ayırabilir ve sınıflandırabilir.
Geleceğe bakış
Geçtiğimiz üç kısa yılda, Krizhevsky ve diğerlerinin R-CNN'sinden sürekli geliştirmeden sonra Mask R-CNN'nin harika segmentasyon etkisinin nasıl elde edileceğini, görüntü bölütleme üzerine araştırmayı gördük.
Tek tek, Mask R-CNN tarafından sunulan sonuçlar, elde edilemeyen büyük bir adım gibi görünüyor. Ancak, umarım bu makale sayesinde bu sonuçların aslında yıllarca süren sıkı çalışma ve ekip çalışmasının getirdiği sezgisel ve aşamalı iyileştirmelerin birikimi olduğunu anlayabilirsiniz. R-CNN, Hızlı R-CNN, Daha Hızlı R-CNN ve son Maske R-CNN, her fikir bir sıçrama ilerlemesi değildir, ancak bu ilerlemeleri ekledikten sonra, son Maske R-CNN getirmiştir. Olağanüstü ve harika etki, mevcut bilgisayar görme teknolojisini insanın görsel yeteneğine yaklaştırdı.
Beni özellikle heyecanlandıran şey, R-CNN ağından Mask R-CNN ağına geçmenin yalnızca üç yıl sürmesi. Daha fazla finansman, daha fazla ilgi ve daha fazla destekle, bilgisayar görüşü üç yıl içinde nasıl gelişecek? bekleyelim ve görelim.
CNN'in görüntü segmentasyonundaki ilerlemesini ve arkasındaki ilkeleri daha derinlemesine anlamak istiyorsanız, makalenin başında bahsettiğimiz dört makaleyi unutmayın:
1. R-CNN: https://arxiv.org/abs/1311.2524
2. Hızlı R-CNN: https://arxiv.org/abs/1504.08083
3. Daha hızlı R-CNN: https://arxiv.org/abs/1506.01497
4. Maske R-CNN: https://arxiv.org/abs/1703.06870
Ve makalede bahsedilen seçici arama:
İşe Alım
Editörleri, muhabirleri, operasyonları ve diğer pozisyonları işe alıyoruz. Çalışma yeri Pekin, Zhongguancun'da. Ziyaretinizi dört gözle bekliyoruz ve yükselen yapay zeka dalgasını yaşıyoruz.
İlgili ayrıntılar için lütfen şu yanıtı verin: resmi hesabın diyalog arayüzünde "İşe Alım".
Bir şey daha...
Bugün AI dünyasında başka nelere dikkat etmeye değer? Yapay zeka endüstrisini ve tüm ağımızdan toplanan araştırma eğilimlerini görmek için QbitAI genel hesap görüşme arayüzünde "bugün" yanıtını verin. Yeniden doldur ~