Spark Streaming Stream Processing Project 7-Spark Streaming Actual Combat 2
Durum 4: Spark Streaming gerçek savaşında pencere işlevlerinin kullanımı:
Pencere mekanizması: Bir zaman periyodu içindeki veri işleme düzenli olarak gerçekleştirilir ve zaman periyodu çakışabilir.Aşağıdaki şekle bakın:
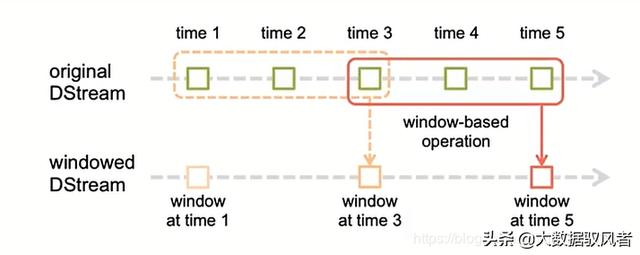

pencere uzunluğu: pencerenin uzunluğu, yukarıdaki şekildeki pencerenin uzunluğu 3'tür;
pencere aralığı: pencere aralığı, yukarıdaki şekildeki pencere aralığı 2'dir.
Bu iki parametre, daha önce bahsedilen parti boyutu ile ilgilidir. Pencereyi kullanarak, belirli bir aralıktaki verileri ne sıklıkla hesaplayabiliriz, örneğin, önceki 10 dakikadaki verileri her 10 saniyede bir hesaplayabiliriz (veriler kesinlikle örtüşecektir).
/ Her 10 saniyede bir son 30 saniyelik veriyi azaltın val windowedWordCounts = pairs.reduceByKeyAndWindow ((a: Int, b: Int) = > (a + b), Saniye (30), Saniye (10))
Örnek 5: Gerçek Kıvılcım Akışı savaşında kara liste filtreleme:
Gereksinimler: Belirtilen verileri veri akışından filtreleyin
Aşağıdaki erişim günlüğü (DStream) varsa:
20180808, zhangsan
20180808, lisi
20180808, wangwu
Kara liste tablosu (RDD):
Zhangsan
lisi
Kara listedeki adları filtreledikten sonra, yalnızca 20180808, wangwu çıktı
Fikirler:
İlk olarak, erişim günlüğünde (DStream) aşağıdaki işlemleri yapın:
== > (zhangsan: 20180808, zhangsan) (lisi: 20180808, lisi) (wangwu: 20180808, wangwu) anahtar / değer olarak yazılır, burada anahtar ad ve değer orijinal erişim günlüğüdür
Ardından kara listede (RDD) benzer işlemleri yapın:
== > (zhansan: doğru) (lisi: doğru)
Sonra kullanırız sol yönden katılım , Aşağıdaki sonuçları alın:
(Zhangsan:]
(Lisi:]
(Wangwu:]
Son olarak, yalnızca doğru olan ikincisini filtrelememiz gerekir ve gerisi istediğimiz sonuçtur.
org.apache.spark.SparkConf dosyasını içe aktar org.apache.spark.streaming. {Seconds, StreamingContext} dosyasını içe aktarın / ** * @yazar YuZhansheng * @desc kara liste filtreleme * @create 2019-02-2015:33 * / nesne TransformApp { def main (değiştirgeler: Dizi): Birim = { val sparkConf = new SparkConf (). setMaster ("yerel"). setAppName ("TransformApp") // StreamingContext'in oluşturulması iki parametre gerektirir: SparkConf ve toplu iş aralığı val ssc = new StreamingContext (sparkConf, Seconds (5)) // Bir kara liste oluşturun val blacks = Liste ("zhangsan", "lisi") val blacksRDD = ssc.sparkContext.parallelize (siyahlar) .map (x = > (x, doğru)) val satırları = ssc.socketTextStream ("localhost", 6789) val clicklog = lines.map (x = > (x.split (",") (1), x)). dönüşümü (rdd = > { rdd.leftOuterJoin (blacksRDD) .filter (x = > x._2._2.getOrElse (yanlış)! = doğru) .map (x = > x._2._1) }) clicklog.print () ssc.start () ssc.awaitTermination () } }
Test: Verileri göndermek için istemcide nc -lk 6789 komutunu kullanın ve doğrulama için konsol tarafından yazdırılan sonucu görün.
Örnek 6: Spark Streaming, kelime frekansı istatistikleri işlemini tamamlamak için SparkSQL'i entegre eder
Önce bağımlılıkları ekleyin
< ! - SparkSQL bağımlılığı-- > < bağımlılık > < Grup kimliği > org.apache.spark < /Grup kimliği > < artifactId > spark-sql_2.11 < / artifactId > < versiyon > $ {spark.version} < / version > < /bağımlılık >
Test: Verileri göndermek için istemcide nc -lk 6789 komutunu kullanın ve doğrulama için konsol tarafından yazdırılan sonucu görün.
+ ---- + ----- +
| kelime | toplam |
+ ---- + ----- +
| ds | 2 |
| e | 1 |
| d | 1 |
| a | 2 |
| olarak | 1 |
+ ---- + ----- +
(Bu vaka, çalışırken daha fazla günlük yazdıracaktır.)