Derin Evrişimli Sinir Ağı Evrim Geçmişi ve Yapı İyileştirme Bağlamı-40 sayfalık tam yorum

Xinzhiyuan önerilir
Kaynak: SigAI
Yazar: AI çalışma ve uygulama platformu
Yeniden basılan editör: Jiang Lei
Xin Zhiyuan Rehberi LeCun'un 1989'da ilk gerçek evrişimli sinir ağını önermesinin üzerinden 29 yıl geçti. AlexNet ağının 2012'de ortaya çıkmasından bu yana, evrişimli sinir ağı son 6 yılda hızla gelişti ve birçok problemde en iyi sonuçları elde etti ve çeşitli derin öğrenme teknolojilerinin en yaygın kullanılanıdır. Bu yazıda, evrişimli sinir ağlarının tüm gelişim sürecini gözden geçirip özetleyeceğim.

Erken sonuçlar
Evrişimsel sinir ağı, çeşitli derin sinir ağlarının en yaygın kullanılanıdır.Makine görmesinin birçok probleminde en iyi sonuçları elde etmiştir.Ayrıca doğal dil işleme ve bilgisayar grafikleri alanlarında da başarıyla uygulanmıştır. .
İlk gerçek evrişimli sinir ağı 1989'da LeCun tarafından önerilmiş ve daha sonra geliştirilmiştir.El yazısıyla yazılmış karakter tanıma için kullanılmıştır ve çeşitli derin evrişimli sinir ağlarının yaratıcısıdır. Daha sonra, ilk günlerde LeCun tarafından önerilen üç evrişimli ağ yapısını tanıtıyoruz.
Literatürün ağı, evrişimli bir katman ve tamamen bağlantılı bir katmandan oluşur.Ağın girişi, 16x16 normalize edilmiş bir görüntüdür ve çıktı, ortada 3 gizli katman bulunan 0-9 arası 10 sınıftır. Bu ağın yapısı aşağıdaki şekilde gösterilmektedir:

Bu makale, ağırlık paylaşımı ve özellik haritası kavramlarını ortaya koymaktadır.Bu kavramlar günümüze kadar kullanılmaktadır ve evrişimli katmanın prototipidir. Ağ 1 giriş katmanı, 1 çıkış katmanı ve 3 gizli katmandan oluşur. Gizli katmanlar H1 ve H2 evrişimli katmanlardır ve H3 tamamen bağlantılı bir katmandır. Ağın etkinleştirme işlevi tanh (hiperbolik tanjant) işlevini kullanır ve kayıp işlevi, Öklid mesafesinin ortalaması olan ortalama kare hata işlevini kullanır. Ağın ağırlıkları, tekdüze dağıtılmış rastgele sayılarla başlatılır, eğitim sırasında parametre gradyan değerlerinin hesaplanması, bir geri yayılma algoritması kullanır ve gradyan değerlerinin güncellenmesi, bir çevrimiçi rastgele gradyan iniş yöntemini kullanır.
Literatürdeki ağ yapısı literatüre benzer olup, posta kodlarının tanımlanmasında kullanılır ve% 9 ret oranı koşulunda hata oranı% 1'dir. Ağın girişi 28x28 bir resimdir ve çıktı 100-9 sınıftır. Tüm ağ 4 gizli katmana sahiptir, bunların arasında H14 5x5 evrişimli çekirdek ve çıktı 424x24 özellik görüntüsüdür. H2, aşağı örnekleme katmanıdır ve H1'in çıktı sonucu, 412x12 görüntü elde etmek için 2x2 aşağı örneklenir. H3, 12 adet 5x5 evrişimli çekirdeğe sahiptir ve çıktı 128x8 görüntüdür.Burada, çıktı görüntüsünün her kanalının çok kanallı evrişimi yalnızca önceki katmanın çıktı görüntüsünün bazı kanallarına etki eder.Bu yöntem neden kullanılır? Bunun iki nedeni vardır: 1. Parametreleri azaltın, 2. Bu asimetrik kombinasyon ve bağlantı yöntemi, çeşitli birleşik özellikleri çıkarmak için faydalıdır. H2 ve H3 arasındaki bağlantı ilişkisi aşağıdaki şekilde gösterilmektedir:

H4, aşağı örnekleme katmanıdır ve H3'ün çıktı görüntüsü, 124x4 özellik görüntüsü elde etmek için 2x2 aşağı örneklenir. Son olarak, çıktı katmanı H4 karakteristik görüntüsünü alır ve 10 kategorinin olasılığını verir.
Literatür ağı, ilk geniş çapta dolaşan evrişimli ağ olan LeNet-5 ağıdır.Tüm ağın yapısı aşağıdaki şekilde gösterilmiştir:
Aşağıdakiler, LeNet-5'e dayalı bir el yazısı rakam tanıma durumudur:

Bu ağın girişi 32x32'lik bir görüntüdür. Tüm ağda 2 hacim katmanı, 2 havuz katmanı, 2 tam bağlı katman ve bir çıktı katmanı vardır Çıkış katmanında 10 dijital sınıfı temsil eden 10 nöron vardır. Evrişimsel katman C1, 6 adet 28x28 çıktı görüntüsü oluşturmak için gri görüntü üzerinde hareket eden 6 adet 5x5 evrişim çekirdeğine sahiptir. Havuzlama katmanı S2, C1'in çıktı görüntüsü üzerinde hareket eder, 2x2 havuzlama gerçekleştirir ve 614x14 çıktı görüntüsü üretir. Evrişimsel katman C3, 165x5 evrişim çekirdeğine sahiptir ve her bir evrişim çekirdeği, 1610x10 çıktı görüntüsü oluşturmak için önceki katmanın çıktı görüntüsünün kanalının bir parçası üzerinde hareket eder. C3 ve S2 arasındaki bağlantı ilişkisi aşağıdaki şekilde gösterilmektedir:

Havuzlama katmanı S4, 16 adet 5x5 çıktı görüntüsü elde etmek için C3'ün çıktı görüntüsü üzerinde 2x2 havuzlama gerçekleştirir. Tamamen bağlı C5 katmanı 120 düğüme sahiptir ve tam bağlı katman F664 düğüme sahiptir.
Ağın aktivasyon işlevi tanh işlevini, kayıp işlevi ortalama kare hata işlevini kullanır ve eğitim sırasında stokastik gradyan iniş yöntemi ve geri yayılma algoritması kullanılır.
Yüz tanıma, yüz tanıma ve karakter tanıma gibi çeşitli sorunlar için erken evrişimli ağlar kullanıldı. Ancak ana akım yöntem haline gelmedi, ana nedenler gradyanın ortadan kalkması, eğitim numunelerinin sayısının sınırlandırılması ve hesaplama gücünün sınırlandırılmasıdır. Gradyan kaybolması sorunu daha önce keşfedilmişti Derin sinir ağlarının eğitilmesinin zor olduğu sorun için literatür analiz edildi, ancak verilen çözümler ana akım haline gelmedi.
Derin Evrişimli Sinir Ağı
Mevcut ana akım derin evrişimli sinir ağlarının özelliklerinin derinlemesine analizinden ve karşılaştırılmasından önce, ImageNet 2012 test veri setindeki her bir ağın doğruluğunu ve üç boyutun ağ parametrelerini ve hesaplama karmaşıklığını analiz edeceğiz.Okuyucuların mevcut ana akım ağının bir analizine sahip olacağını umuyoruz. Yapının genel bir anlayışı var. Aşağıda gösterildiği gibi:

Derin evrişimli ağların büyük gelişimi 2012 yılında AlexNet ağı ile başladı. Bundan sonra, çeşitli iyileştirilmiş ağlar sürekli olarak önerildi.Ardından, çeşitli tipik ağ yapılarını tanıtacağız.
AlexNet ağı
Modern derin evrişimli sinir ağı, derin evrişimli sinir ağının yaratıcısı olan AlexNet ağından kaynaklandı. Önceki evrişimli ağ ile karşılaştırıldığında bu ağın en önemli özelliği seviyenin derinleşmesi ve parametre ölçeğinin büyütülmesidir. Ağ yapısı aşağıda gösterilmiştir:

Bu ağda 5 evrişimli katman vardır, bunlardan bazılarını alt örnekleme için bir maksimum havuz katmanı izler ve son olarak 3 tamamen bağlı katman vardır. Son katman, ImageNet atlasındaki 1000 görüntü sınıflandırmasına karşılık gelen, toplamda 1000 düğüm içeren softmax çıktı katmanıdır. Ağdaki hacim temel katmanının bir kısmı, bağımsız hesaplama için 2 gruba ayrılmıştır; bu, GPU paralelleştirmesine yardımcı olur ve hesaplama miktarını azaltır.
Bu ağın iki ana yeniliği vardır: 1. Yeni aktivasyon fonksiyonu ReLU, 2. Bırakma mekanizması. Bırakma yöntemi, eğitim sırasında uyumak için bazı nöronları rastgele seçmektir ve bazı nöronlar ağın optimizasyonuna katılır, bu da aşırı uyumu azaltmak için bir düzenlilik rolü oynar.
Ağın giriş görüntüsü, renkli üç kanallı bir görüntüdür. İlk evrişimli katman 96 set 11x11 evrişim çekirdeğine sahiptir ve evrişim işleminin adım boyutu 4'tür. Buradaki evrişim çekirdeği 2 boyutlu değil 3 boyutludur. Her kanal 3 evrişim çekirdeğine karşılık gelir (bu nedenle bu bir dizi evrişim çekirdeğidir). Spesifik uygulama, harekete geçmek için 32 boyutlu evrişim çekirdeği kullanmaktır. RGB kanalı ve ardından üç sonuç görüntüsünü ekleyin. Aşağıdaki şekil, 3 giriş kanallı dinamik evrişim sürecini, her evrişimli katman parametresi grubu için 3 evrişim çekirdeğinden oluşan 2 grup ve 2 çıkış sonucu kanalını göstermektedir.

İkinci evrişimli katman, iki gruba ayrılmış 256 grup 5x5 evrişimli çekirdeğe sahiptir, yani her grupta 128 kanal grubu ve her grupta 48 evrişim çekirdeği vardır. Üçüncü evrişimli katman 384 grup 3x3 evrişimli çekirdeğe sahiptir ve her grup 256 evrişim çekirdeğine sahiptir. Dördüncü evrişim katmanı, iki gruba ayrılmış 384 grup 3x3 evrişim çekirdeğine sahiptir, yani her grup 192 kanala sahiptir ve her grup 192 evrişim çekirdeğine sahiptir. Beşinci evrişim katmanı 256 grup, 3x3 boyutunda evrişim çekirdeğine sahiptir, iki gruba ayrılmıştır, yani her grup 128 gruptur ve her grup 192 evrişim çekirdeğine sahiptir.
Bu ağ, etkinleştirme işlevi olarak geleneksel sigmoid veya tanh işlevini kullanmaz, ancak yeni bir ReLU işlevi türü kullanır:

Türev, sgn işaret fonksiyonudur. ReLU işlevi ve türevinin hesaplanması basittir ve hem ileri hem de geri yayılmada hesaplama miktarını azaltır. Zaman fonksiyonunun türev değeri 1 olduğu için gradyan kaybolması problemi bir dereceye kadar çözülebilir ve eğitim sırasında yakınsama hızı daha hızlıdır. O zamanlar, fonksiyonun değeri 0 idi, bu da bazı nöronların çıktı değerini 0 yaptı, bu da ağı daha seyrek hale getirdi, bu da L1 düzenlemesine benzer bir rol oynadı ve ayrıca bir dereceye kadar aşırı uyumu azaltabilirdi.
ZFNet ağı
Literatür, evrişimli ağın etkisini analiz etmek ve ağın iyileştirilmesine rehberlik etmek için evrişimsel ağ katmanını ters evrişim (ters çevrilmiş evrişim) yoluyla görselleştirme yöntemi önermektedir.AlexNet ağı temelinde daha iyi bir ZFNet ağı elde edilir .
Makale, AlexNet temelinde bazı ayrıntılı değişiklikler yaptı ve ağ yapısında çok fazla ilerleme yok. Makalenin en büyük katkısı, sinir ağının katmanlarının ne yaptığını ve hangi rolü oynadığını ortaya çıkarmak için görselleştirme teknolojisini kullanmaktır. Sinir ağının neden bu kadar iyi sonuçlar elde ettiğini bilmiyorsanız, daha iyi bir model bulmak için yalnızca sürekli deneylere güvenebilirsiniz. Eğitim süreci sırasında özelliklerin evrimini görselleştirmek ve olası sorunları bulmak için çok katmanlı bir ters evrişim ağı kullanılır; aynı zamanda, tıkanan görüntü bölümünün sınıflandırma sonuçları üzerindeki etkisine göre, sınıflandırma görevi için girdi bilgilerinin hangi kısmının daha önemli olduğu tartışılır. Aşağıdaki şekil tipik bir ters evrişim ağının şematik diyagramıdır:

ZFNet ağ yapısı aşağıdaki şekilde gösterilmektedir:

AlexNet'in temel yapısını korurken, ZFNet, belirli bir evrişim katmanının evrişim çekirdeğinin boyutunu ayarlamak için evrişimsiz ağ görselleştirme teknolojisini kullanır. İlk katmanın evrişim çekirdeği 11 * 11'den 7 * 7'ye düşürülür. Adım 4'ten 2'ye düşürüldü ve Top5'in hata oranı AlexNet'inkinden% 1.7 daha düşük.
GoogLeNet ağı
Literatür, GoogLeNet ağı (Inception-V1) adlı bir yapı önermektedir. AlexNet'in ortaya çıkmasından sonra, görüntü görevleri için çok sayıda gelişmiş ağ yapısı ortaya çıkmıştır.Genel olarak konuşursak, iyileştirmenin ana fikri, derinlik ve genişlik dahil olmak üzere ağın boyutunu artırmaktır. Bununla birlikte, doğrudan ağ ölçeğini artırmak iki sorunla karşı karşıya kalacaktır: Birincisi, aşırı uydurmanın ağ parametreleri artırıldıktan sonra ortaya çıkması daha olasıdır.Bu sorun, eğitim örnekleri sınırlı olduğunda daha belirgindir. Diğer bir problem ise hesaplamadaki artış. GoogLeNet, yukarıdaki iki sorunu çözmeye kararlıdır.
GoogLeNet, Google tarafından 2014 yılında önerildi ve ana yeniliği Başlangıç mekanizması, yani görüntülerin çok ölçekli işlenmesidir. Bu mekanizmanın bir yararı, modelin parametre sayısının büyük ölçüde azaltılmasıdır Yöntem, bir Başlangıç modülü oluşturmak için birden çok evrişim çekirdeğini ve farklı ölçeklerdeki havuz katmanlarını entegre etmektir. Tipik Başlangıç modülü yapısı aşağıda gösterilmiştir:

Yukarıdaki şekildeki modül, 3 grup evrişim çekirdeği ve bir havuzlama ünitesinden oluşur.Önceki katmandan giriş görüntüsünü birlikte kabul ederler.Üç boyutta evrişim çekirdeği ve maksimum havuzlama işlemi vardır.Giriş görüntüsünü paralel olarak işlerler. , Ve sonra çıktı sonuçlarını kanallara göre birleştirin. Evrişim işlemi tarafından kabul edilen girdi görüntüleri aynı boyutta olduğundan ve evrişim dolgu olduğundan, çıktı görüntüleri aynı boyuttadır ve kanala göre doğrudan birleştirilebilir.
Teorik bir bakış açısından, Başlangıç modülünün amacı, büyük boyutlu bir seyrek matrisi daha küçük boyutlu bir matrisle değiştirmektir. Yani, ikisinin benzer performansa sahip olmasını sağlamak için büyük evrişimli çekirdeklerin yerine bir dizi küçük evrişim çekirdeği kullanılır.
Yukarıdaki şekildeki evrişim işleminde, giriş görüntüsünün kanal sayısı çok fazla, hesaplama miktarı çok fazla ve evrişim çekirdeğinin parametreleri çok fazla ise, bu nedenle veri boyutluluğunu azaltmak gerekir. Tüm evrişim ve havuzlama işlemleri, boyut azaltma için 1x1 evrişimi kullanır, yani görüntü kanallarının sayısını azaltır. 1x1 evrişim görüntünün yüksekliğini ve genişliğini değiştirmediğinden, sadece kanal sayısını değiştirir.
GoogleNet ağ yapısı aşağıda gösterilmektedir:
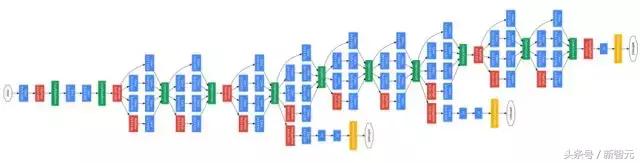
GoogleNet, ILSVRC 2014 yarışmasında% 6,67'lik ilk 5 hata oranıyla sınıflandırma görevinde birinci oldu. Önceki AlexNet benzeri ağ ile karşılaştırıldığında, GoogleNet'in ağ derinliği 22 katmana ulaştı ve parametre sayısı AlexNet'in 1 / 12'sine düşürüldü.Çok iyi ve çok pratik bir model olduğu söylenebilir.
Ağ parametrelerini azaltmak için yazar iki girişimde bulundu: Birincisi, tamamen bağlı olan son katmanı kaldırmak ve onu genel ortalama havuzlama ile değiştirmek. Tamamen bağlı katman, AlexNet'teki parametrelerin neredeyse% 90'ını kaplar ve aşırı oturmaya neden olur.Tamamen bağlı katman kaldırıldıktan sonra, model eğitimi daha hızlıdır ve fazla uydurma azalır. Tamamen bağlı katmanın küresel ortalama havuzlama katmanıyla değiştirilmesi uygulaması Ağda Ağ (bundan böyle NIN olarak anılacaktır) kağıdından ödünç alır. İkincisi, GoogleNet'te dikkatlice tasarlanmış Başlangıç modülünün parametrelerin kullanım verimliliğini artırmasıdır. Bu kısım da NIN fikrinden yararlanmaktadır. Görüntü açıklaması, Başlangıç modülünün kendisinin büyük bir ağdaki küçük bir ağa benzediğini ve yapısının büyük bir ağ oluşturmak için tekrar tekrar yığınlanabileceğidir. İnternet. Ancak GoogleNet, şube ağları ekleyerek NIN'den bir adım daha ileri gidiyor.
VGG ağı
VGG ağı, 2014 yılında tanınmış Oxford Üniversitesi Görsel Geometri Grubu tarafından önerildi ve ILSVRC 2014 sınıflandırma görevinde ikinci (GoogleNet birinci sırada) ve konumlandırma görevinde birincilik kazandı. Aynı zamanda, VGGNet çok genişletilebilir ve diğer görüntü verilerine geçişin genelleştirilmesi çok iyidir. VGGNet'in yapısı çok basittir, tüm ağ aynı boyutta evrişim çekirdek boyutu (3x3) ve havuzlama boyutu (2x2) kullanır. Şimdiye kadar, VGGNet hala sık sık görüntü özelliklerini çıkarmak için kullanılmaktadır ve görüş alanındaki çeşitli görevlerde yaygın olarak kullanılmaktadır.
VGG ağının ana yeniliği, küçük boyutlu bir evrişim çekirdeğinin kullanılmasıdır. Tüm evrişimli katmanlar 3x3 evrişim çekirdeklerini kullanır ve evrişimin adım boyutu 1'dir. Evrişimden sonra görüntünün boyutunun değişmemesi için görüntü her iki yanında 1 piksel ile doldurulur. Tüm havuz katmanları, adım boyutu 2 olan 2x2 çekirdek kullanır. Tam bağlantılı katman, sırasıyla 4096, 4096 ve 1000 düğüm dahil olmak üzere 3 katmana sahiptir. Tam olarak bağlanan son katman dışında, tüm katmanlar ReLU aktivasyon işlevini kullanır. Aşağıdaki şekil VGG16'nın yapısını göstermektedir:

Alexnet ile karşılaştırıldığında, VGG aşağıdaki iyileştirmeleri yaptı:
1. LRN katmanını kaldırın, yazar LRN'nin derin evrişimli ağdaki rolünün deneyde açık olmadığını buldu
2. Daha büyük boyutlu bir evrişim çekirdeğini simüle etmek için daha küçük bir sürekli 3x3 evrişim çekirdeği kullanılır.Örneğin, 2 ardışık 3x3 evrişim katmanı 5x5 evrişim katmanının alıcı alanına ulaşabilir, ancak gerekli parametreler daha fazla olacaktır. Daha azı, iki 3x3 evrişimli çekirdeğin 18 parametresi (sapma terimine bakılmaksızın), 5x5 evrişimli çekirdeğin ise 25 parametresi vardır. Sonraki artık ağlar bu özelliği sürdürdü.
Artık ağ
Artık Ağ, derin ağları eğitmedeki zorluk sorununu çözmek için Artık Temsillere uymak için Kısayol Bağlantıları kullanır ve ağ katmanlarının sayısını benzeri görülmemiş bir ölçeğe genişletir.Yazar, ImageNet verileri hakkında rapor verir. Sette 152 katmanlı bir artık ağ kullanılmıştır. Derinlik, VGG ağının 8 katıdır ancak karmaşıklığı daha düşüktür. ImageNet test setinde% 3,57'lik ilk 5 hata oranına ulaşır.Bu sonuç ILSVRC2015 sınıflandırma görevini kazandı. Bir ve yazar ayrıca CIFAR-10 veri setindeki 100 katmanlı ve 1000 katmanlı artık ağı da analiz etti. VGG19 ağı ile ResNet34-Plain ve ResNet34-redisual ağları arasındaki karşılaştırma aşağıdaki gibidir:

Önceki deneyimler, ağın katman sayısının artırılmasının ağın performansını artıracağını kanıtlamıştır, ancak belirli bir ölçüde arttıktan sonra, katmanlar arttıkça sinir ağının eğitim hatası ve test hatası artacaktır ki bu, aşırı uydurma ile aynı şey değildir. Aşırı uydurma sadece test setindeki büyük bir hatadır Bu soruna bozulma denir.
Yazar, bu sorunu çözmek için derin artık ağ adı verilen bir yapı tasarladı.Bu ağ, katman bağlantılarını atlayarak ve kalıntıları yerleştirerek çok fazla katmanın neden olduğu sorunları çözer. Bu yaklaşım, karayolu ağından ( Highway Networks) 'ün tasarım felsefesi LSTM'ye benzer. Bu yapının prensibi aşağıdaki şekilde gösterilmektedir:

Aşağıdaki literatür, artık ağın mekanizmasını analiz etmektedir. Aşağıdaki sonuçlar çıkarılmıştır: Artık ağ, tek bir ultra derin ağ değil, örtülü olarak entegre edilmiş ağların sayısını tanımlamak için kullanılan çeşitlilik kavramını tanıtan çoklu ağların örtük entegrasyonudur. Tahminde, artık ağın davranışı toplu öğrenmeye benzer; eğitim sırasındaki gradyan akış yönü analiz edildi ve örtük topluluğun çoğunun nispeten sığ ağlardan oluştuğu bulundu.Bu nedenle, kalan ağ gradyan kaybolma sorununu çözemez. .
Kalan ağın entegre özelliklerini daha da kanıtlamak ve katmanlararası yapının bir bölümünü silmenin ağın doğruluğu üzerindeki etkisini belirlemek için, yazar katmanları silmek için bir deney yaptı.İki deney grubu vardır.İlk grup tek bir katmanı silmektir. İkinci grup, aynı anda birden fazla katmanı silmektir. Karşılaştırma için yazar, artık ağı ve VGG ağını kullanır. Deneysel sonuçlar, tek tek katmanlar dışında, tek bir katmanı silmenin, kalan ağın doğruluğu üzerinde çok az etkiye sahip olduğunu kanıtlamaktadır. Buna karşılık, VGG ağının tek bir katmanını silmek, doğrulukta keskin bir düşüşe neden olacaktır. Bu sonuç, artık ağın birden çok ağın entegrasyonu olduğu sonucunu doğrular.
Üçüncü deney grubu, ağın yapısını değiştirmek ve katmanların sırasını ayarlamaktır. Deneyde yazar, yolun bir bölümünü etkileyecek olan belirli katmanların sırasını bozdu. Spesifik yöntem, birden fazla katman çiftinin pozisyonlarını rastgele değiştirmektir ve bu katmanlar tarafından alınan girdi, üretilen çıktı verileriyle aynı boyuttadır. Benzer şekilde, ayarlanan katmanların sayısı arttıkça, hata oranı da sorunsuz bir şekilde yükselir ve bu, ikinci deney grubunun sonuçlarıyla tutarlıdır.
Ancak yazar, yazarın açıklamasının biraz abartılı olduğunu düşünüyor. Sıradan entegre öğrenme algoritması anlamında, her zayıf öğrenci birbirinden bağımsızdır ve buradaki her ağ bazı katmanları paylaşır.Aşırı durumlarda, bir katman dışında, diğer katmanlar aynıdır. Ek olarak, bu ağlar aynı anda eğitilir ve aynı örnekleri kullanır.
GoogleNet-Inception-Benzeri ağ geliştirme serisi
Başlangıç-V2 (GoogleNet-BN)
Yazar, GoogleNet'in temel yapısına göre iyileştirmeler yaptı ve Top1'in hata oranı buna göre% 2 azaltıldı ve aşağıdaki iyileştirmeler yapıldı:
1. BN katmanı eklendi ve Dahili Değişken Kaymasını (dahili nöron veri dağılımı değişir) azaltıldı, böylece her katmanın çıktısı N (0, 1) Gauss değerine normalleştirildi.
2. VGG'yi Öğrenmek Başlangıç modülündeki 5x5'i iki 3x3 dönüşüm ile değiştirin, bu sadece parametre sayısını azaltmakla kalmaz, aynı zamanda hesaplamayı da hızlandırır.
Başlangıç-V3
Inception-V3'ün en önemli iyileştirmelerinden biri, 7x7 evrişim çekirdeğini iki tek boyutlu evrişime (1x7, 7x1) ayıran evrişim çekirdeğinin çarpanlara ayrılmasıdır. Aynısı, dediğimiz 3x3 (1x3, 3x1) için de geçerlidir. Aşağıdaki şekilde gösterildiği gibi asimetrik ayrışma. Bunu yapmak, hesaplamayı hızlandırabilir ve parametre ölçeğini azaltabilir ve 1 konvolüsyonu 2 konvolüsyona bölebilir, bu da ağın derinliğini daha da artırır ve ağın doğrusal olmama durumunu artırır.
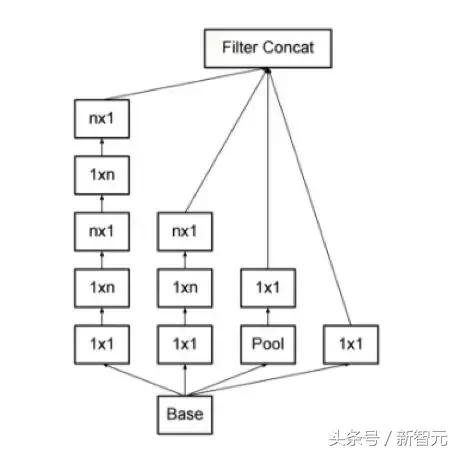
Ek olarak, yazar bu eğitim optimizasyon algoritmasını da geliştirdi:
1. AdaGrad'ı geliştirerek, RMSProp için yeni bir parametre optimizasyon yöntemi önerilmiştir. RMSprop, Geoff Hinton tarafından önerilen uyarlanabilir bir öğrenme hızı yöntemidir. AdaGrad, önceki tüm gradyan karelerini biriktirecek ve RMSprop yalnızca karşılık gelen ortalamayı hesaplar, böylece AdaGrad algoritmasının öğrenme hızındaki hızlı düşüş problemini hafifletebilir. Deneyler, RMSProp'un dışbükey olmayan koşullarda sonuçları daha iyi optimize ettiğini göstermektedir.
AdaGrad'ın yinelemeli formülü şöyledir:

RMSProp'un yinelemeli formülü şöyledir:

2. Modeli kısıtlayan ve çıktı etiketine gürültü ekleyerek modelin aşırı uyum derecesini azaltan bir düzenlilik yöntemi olan Etiket Yumuşatma stratejisi benimsenmiştir.
Başlangıç-V4
V3 sürümü ile karşılaştırıldığında, Inception-v4, Inception modüllerinin sayısını artırdı ve tüm ağ daha derin hale geldi.
Xception
Xception, Google for Inception v3'ün bir başka iyileştirmesidir. Esas olarak, esas olarak ağın karmaşıklığını artırmadan modelin etkisini iyileştiren orijinal Inception v3'teki evrişim işleminin yerini almak için Derinlemesine Ayrılabilir Evrişim'i kullanır. Derinliğe Göre Ayrılabilir Evrişim nedir? Genel olarak, bir dizi özellik haritasındaki evrişim, üç boyutlu bir evrişim çekirdeği gerektirir, yani, evrişim çekirdeğinin uzamsal korelasyonu ve kanallar arasındaki korelasyonu aynı anda öğrenmesi gerekir. Xception, hacmin tabanına bir grup stratejisi ekleyerek, modelin teorik hesaplamasını büyük ölçüde azaltan ve daha az doğruluk kaybına neden olan, öğrenme kanalları arasındaki uzamsal korelasyonu ve korelasyonu öğrenme görevlerini ayırır.
Xception ağ yapısı aşağıdaki şekilde gösterilmektedir:

Başlangıç-ResNet v1 / v2
Yazar, Inception-v3 ve Inception-v4'e dayalı artık ağ fikrini birleştirdi ve sırasıyla Inception-ResNet-v1 ve Inception-ResNet-v2 olmak üzere iki model elde etti. Yalnızca sınıflandırma doğruluğu iyileştirilmez, aynı zamanda eğitim kararlılığı da geliştirilir.
Inception-ResNet-v2'nin ağ yapısı aşağıdaki şekilde gösterilmektedir:

NASNet
Bu kağıt, Google beyin tarafından üretilmiştir. Bu, makinenin otomatik olarak küçük bir veri seti (CIFAR-10 veri seti) üzerinde tasarım yapmasına olanak tanıyan, önceki makale NAS-Sinirsel Mimari Arama ile Güçlendirilmiş Öğrenme'ye dayanan çığır açan bir gelişmedir. CNN ağı ve tasarlanan ağı yapmak için aktarım öğrenme teknolojisinin kullanımı ImageNet veri setine iyi bir şekilde aktarılabilir, doğrulama seti% 82,7'lik bir tahmin doğruluğuna ulaşır ve ayrıca diğer bilgisayarla görme görevlerine (hedef tespiti gibi) aktarılabilir. . Bu ağın özellikleri:
1. NAS belgelerinin temel mekanizmasına devam edin ve pekiştirmeli öğrenme yoluyla otomatik olarak ağ yapıları oluşturun.
2. ResNet ve Inception gibi olgun ağ topolojilerinin kullanımı, ağ yapısı optimizasyonu için arama alanını azaltır Büyük ölçekli ağlar, öğrenme verimliliğini artırmak için doğrudan çok sayıda homojen modül tarafından istiflenir.
3. Mimari araması CIFAR-10 üzerinde gerçekleştirildi ve en iyi mimari ImageNet görüntü sınıflandırmasına ve COCO nesne tespitine taşındı.
Aşağıdaki şekil AutoML tarafından tasarlanan Blok yapısını göstermektedir:

VGG-Artık Benzeri ağ iyileştirme serisi
WRN (geniş artık ağ)
Yazar, modelin derinliği arttıkça, gradyan geri yayıldığında, her bir kalıntı bloğun ağırlığının içinden akmasının garanti edilmediğine, dolayısıyla bir şeyler öğrenmenin zor olduğuna inanmaktadır.Bu nedenle, tüm eğitim süreci boyunca, Yalnızca birkaç kalıntı modül yararlı ifadeleri öğrenebilir ve kalan modüllerin çoğu pek kullanışlı değildir. Bu nedenle yazar, modelin performansını daha etkili bir şekilde iyileştirmek için daha sığ ancak daha geniş bir model kullanmayı ummaktadır.
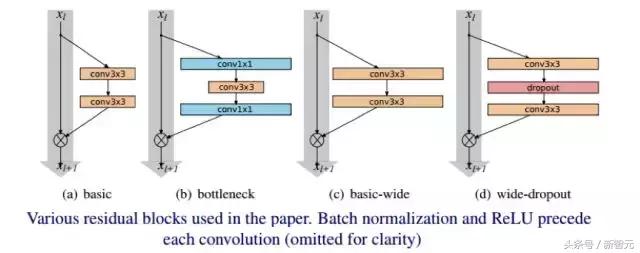
ResNet'in orijinal yazarı tarafından CIFAR-10 için kullanılan ağ, üç Artık Blok içerir, evrişim kanallarının sayısı 16, 32, 64 ve ağın derinliği 6 * N + 2'dir. Burada WRN yazarı 16, 32 ve 64'ten sonra bir k katsayısı eklemiştir. Yani yazar Kalan Blok evrişim kanallarının sayısını artırarak modeli genişletir, böylece N küçük tutulabilir. Değer, ağ iyi sonuçlar elde edebilir.
CIFAR-10 ve CIFAR-100 arasındaki performans karşılaştırması:

Yukarıdaki deneyler, modelin genişliğini artırmanın tek başına modelin performansını artırdığını göstermektedir. Ancak genişliğin derinlikten daha iyi olduğu tam olarak varsayılamaz, ancak ikisi eşleştiğinde daha iyi sonuçlar elde edebilirler.
ResNeXt
Yazarın ResNeXt'i önermesinin ana nedeni şudur: model doğruluğunu iyileştirmenin geleneksel yöntemleri ağı derinleştirmek veya genişletmektir, ancak hiperparametrelerin sayısı arttıkça (kanal sayısı, evrişim çekirdeğinin boyutu vb.), Ağ tasarımının zorluğu ve Hesaplama ek yükü de artacaktır. Bu nedenle, bu yazıda önerilen ResNeXt yapısı, parametrelerin karmaşıklığını artırmadan doğruluğu artırabilir.
Bu makale, VGG istifleme fikrini ve Inception'ın bölünmüş dönüştürme-birleştirme fikrini de kullanan ResNeXt ağını önermektedir, ancak ölçeklenebilirlik nispeten güçlüdür ve bu, temelde modelin karmaşıklığını değiştirmeden veya azaltmadan doğruluk oranını artırdığı düşünülebilir. . İşte bir isim kardinalite, orijinal yorum, aşağıdaki şekil (a) (b) kardinalite = 32'de gösterildiği gibi, dönüşüm kümesinin boyutudur:
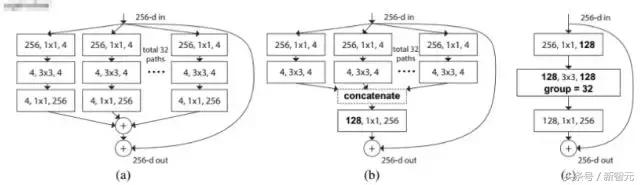
Aşağıdaki sonuçlar deneyler aracılığıyla verilmektedir:
1. ResNeXt'in ResNet'ten daha iyi olduğunu ve Kardinalite ne kadar büyükse etki o kadar iyi olduğunu kanıtlayın
2. Kardinaliteyi artırmak, modelin genişliğini veya derinliğini artırmaktan daha iyidir
O zaman, son teknoloji sonuç elde edildi. Daha sonra diğer ağ yapıları tarafından aşılmasına rağmen, Facebook son zamanlarda görüntü tanıma teknolojisinde yeni bir atılım yaptı. ResNeXt 101-32x48d'ye dayanarak, ImageNet testinin doğruluğu bir rekora ulaştı. % 85.4! (Model eğitimi için 3,5 milyar resim ve 17.000 konu etiketi kullanan ölçek emsalsizdir !!! Yazar burada herhangi bir sonuç çıkarmaz, kendiniz anlayabilirsiniz ...)
DenseNet
DenseNet, yoğun bağlantılara sahip evrişimli bir sinir ağıdır. Bu ağda, herhangi iki katman arasında doğrudan bir bağlantı vardır, yani ağın her katmanının girişi, önceki tüm katmanların çıktılarının birleşimidir ve bu katman tarafından öğrenilen özellik haritası da doğrudan iletilecektir. Sonraki tüm katmanlar girdi olarak kullanılır. DenseNet'in avantajlarından biri, ağın daha dar olması ve parametrelerin daha az olmasıdır.Nedenin büyük bir kısmı yoğun bloğun tasarımından kaynaklanmaktadır.Daha sonra yoğun bloktaki her bir evrişimli katmanın çıktı özelliği haritalarının sayısının çok az olduğundan (100'den az) bahsedilecektir. ), diğer ağlar gibi yüzlerce veya binlerce genişlik yerine. Aynı zamanda, bu bağlantı yöntemi özelliklerin ve gradyanların aktarımını daha etkili hale getirir ve ağın eğitilmesi daha kolaydır. Aşağıda, DenseNet'in şematik bir diyagramı verilmiştir:

DenseNet, ağ parametrelerinin ölçeğini etkili bir şekilde azaltabilir, fazla uydurma etkisini azaltabilir ve küçük veri setlerini öğrenmek için çok etkilidir. Ancak, ortadaki özellik haritalarının çıktısı çok katmanlı Concat'ın sonucu olduğu için, ağın eğitim ve test sırasında bellek kullanımında belirgin bir avantajı yoktur ve hesaplama miktarı önemli ölçüde azalmaz!
MobileNet
MobileNets, Google tarafından cep telefonları gibi gömülü cihazlar için önerilen hafif ve derin bir sinir ağıdır. Ağ tasarımının özü olan Ayrılabilir Evrişim, daha düşük performans pahasına parametre ve hesaplama miktarını etkili bir şekilde azaltabilir. Ayrılabilir Evrişim, geleneksel evrişim işlemini iki aşamalı bir evrişim işlemiyle değiştirir: Aşağıdaki şekilde gösterildiği gibi Derinlik yönünde evrişim ve Noktasal evrişim:

Şekilden açıkça görülebileceği gibi, giriş görüntüsü üç kanallı olduğu için Derinlemesine dönüşümün filtre sayısı sadece 3 olabilirken, geleneksel evrişim yönteminde toplam 93x3 filtre olacaktır.
Sonraki MobileNet-v2 esas olarak artık yapıyı ekledi ve bant genişliği kullanımını optimize etmek ve gömülü cihazlarda performansı daha da iyileştirmek için Derinliksel evrişimden önce bir Noktasal evrişim katmanı ekledi. Ayrılabilir evrişim aşağıdaki şekilde gösterilmiştir:

Derin sinir ağı optimizasyon stratejilerinin özeti
Daha sonra, klasik ağların iyileştirme önlemlerinin önceki ağlarda tanıtıldığı evrişimli sinir ağlarının çeşitli iyileştirme önlemlerini tanıtacağız. Evrişimli sinir ağları için iyileştirme önlemleri esas olarak şu yönlerdedir: evrişimli katman, havuzlama katmanı, aktivasyon işlevi, kayıp işlevi, ağ yapısı, düzenleme teknolojisi vb. Optimizasyon algoritması, ağın eğitimi için çok önemlidir ve bunları burada ayrı ayrı listeliyoruz.
Evrişimli katman
Evrişim katmanında birkaç iyileştirme vardır: aşağıda tanıtılan evrişim çekirdeğinin minyatürleştirilmesi, 1x1 evrişim, Ağda Ağ, Başlangıç mekanizması, çarpanlara ayırma, ters evrişim işlemi vb.
Ağda Ağ'ın ana fikri, evrişimli katmanın doğrusal filtresini küçük ölçekli bir sinir ağıyla değiştirmektir.Bu belgede, küçük ağ, çok katmanlı bir algılayıcı evrişimli ağdır. Bu küçük ağın doğrusal evrişim işlemlerinden daha güçlü bir tanımlama yeteneğine sahip olduğu açıktır.
Evrişim çekirdeğinin minyatürleştirilmesi artık genel kabul gören bir görüş haline geldi ve VGG ağında tanıtıldı. 1x1 evrişim, kanal boyutunun azaltılması için kullanılabilir ve ayrıca evrişimli ağın herhangi bir boyuttaki giriş görüntülerini kabul edebilmesini ve piksel piksel tahmin yapabilmesini sağlamak için tam evrişimli ağlar için de kullanılabilir. Başlangıç mekanizması GoogLeNet ağında tanıtıldı ve burada tekrar edilmeyecek.
Evrişim işlemi, bir görüntünün ve bir matrisin ürününe dönüştürülebilir. Ters evrişime aynı zamanda devredilmiş evrişim de denir. İşleyişi, bu sürecin tam tersidir. İleriye doğru yayılmada, sol çarpım matrisi aktarılır ve geriye doğru yayılmada Matrisi sola doğru çarpın. Buradaki ters evrişimin sinyal işlemedeki ters evrişim ile aynı şey olmadığına dikkat edin, sadece orijinal çıktı görüntüsü ile aynı boyutta bir görüntü elde edebilir, evrişim işleminin ters işlemini değil. Ters evrişim işleminin, daha sonra tanıtılacak olan evrişimli ağın görselleştirilmesi; tam evrişimli ağda yukarı örnekleme, görüntü oluşturma vb. Gibi bazı pratik kullanımları vardır. Ters evrişim işlemi, evrişim işlemi ile elde edilen çıktı görüntüsünü evrişim matrisinin soluyla çarparak orijinal görüntü ile aynı boyutta bir görüntü elde edebilir.
Havuz tabakası
Havuz katmanındaki iyileştirmeler temel olarak şu şekildedir: L-P havuzlama, hibrit havuzlama, rastgele havuzlama, Uzamsal piramit havuzlama ve ROI havuzlama.
Aktivasyon fonksiyonu
Geleneksel sigmoid ve tanh fonksiyonlarına ek olarak, derin evrişimli sinir ağlarında çeşitli yeni aktivasyon fonksiyonları ortaya çıkmıştır.Başlıca olanlar: ReLU, ELU, PReLU, vb. İyi sonuçlar elde etmiştir. Bunların arasında ReLU ve geliştirilmiş tipi ciltte yer almaktadır. Ürün ağlarında yaygın olarak kullanılmaktadır.
Kayıp işlevi
Kayıp işlevi de önemli bir gelişme noktasıdır. Öklid mesafe kaybına ek olarak, çapraz entropi, kontrast kaybı, menteşe kaybı, vb. Sırayla kullanılır.
Bazı karmaşık görevlerde, çok görevli bir kayıp kaybı işlevi görünür. Tipik hedef tespit algoritmaları, yüz tanıma algoritmaları, görüntü segmentasyon algoritmaları, vb. Bu kayıp fonksiyonları, yüz tanıma ve hedef tespit ile ilgili inceleme makaleleri serisinde tanıtılmıştır ve burada tekrarlanmayacaktır.
Ağ yapısı
Buradaki ağ yapısı, topolojik yapıyı ve katmanların kullanımını ifade eder. Artık ağ ve DenseNet gibi bağlantı ilişkilerinin iyileştirilmesi önceki bölümde tanıtıldı.
Kısaca Fully Convolutional Networks, FCN, standart evrişimli ağ temelinde yapılan bir değişikliktir.Standart evrişimli ağın tam bağlantılı katmanını, görüntü bölütleme ve derinlik tahmini ihtiyaçlarını karşılamak için bir evrişimli katmanla değiştirir. Orijinal görüntünün her pikselinin tahmini. Genel olarak, tam evrişimli ağın son birkaç evrişimli katmanı 1x1 evrişim çekirdeği kullanır. Evrişim ve aşağı örnekleme katmanları, görüntü boyutunun küçültülmesi ile sonuçlandığından, orijinal girdi görüntüsü ile aynı boyutta bir görüntü elde etmek için, giriş görüntüsü ile aynı boyutta tahmini bir görüntü elde etmek üzere yukarı örnekleme elde etmek için bir ters evrişim katmanı kullanılır.
Farklı katmanların evrişim çekirdekleri, görüntünün bilgilerini farklı ölçeklerde tanımlayan farklı alıcı alanlara sahiptir. Çok ölçekli işleme aynı zamanda yaygın bir evrişimli ağ yöntemidir. Farklı evrişimli katmanların çıktı görüntülerini işleme için tek bir katmanda toplamak, görüntünün çok ölçekli bilgilerini çıkarabilir. Tipik yöntemler arasında GoogLeNet, SSD, Cascade CNN ve DenseBox bulunur.
Normalleştirme tekniği
Sinir ağının eğitim süreci sırasında, her katmanın parametreleri yineleme ilerledikçe değişmeye devam edecek ve bu, sonraki katmanın girdi verilerinin dağılımının değişmeye devam etmesine neden olacaktır.Bu soruna dahili değişken kayma denir. Eğitim sırasında her katman, girdi verilerinin dağıtımına uyum sağlamalıdır; bu, yinelemeli süreçteki öğrenme oranını ve ince başlangıç ağırlık parametrelerini ayarlamamızı gerektirir. Bu sorunu çözmek için, sinir ağının her katmanının giriş verilerini normalleştirmemiz gerekiyor. Çözümlerden biri, önceki katmanın giriş verilerini toplu olarak normalleştirmek ve ardından işlenmek üzere bir sonraki katmana göndermek için kullanılan ağdaki özel bir katman olan Toplu Normalleştirme'dir. Sinir ağının eğitim sürecini hızlandırabilir.
optimizasyon
Standart mini kesikli stokastik gradyan iniş yöntemine ek olarak, aşağıda ayrıca tanıtılan birçok deneyde ve pratik uygulamalarda daha iyi sonuçlar elde eden gradyan iniş yönteminin bazı geliştirilmiş versiyonları vardır.
AdaGrad, gradyan iniş yönteminin en doğrudan iyileştirmesi olan uyarlanabilir bir gradyan, yani adaptif gradyan algoritmasıdır. Tek fark, AdaGrad'ın önceki yinelemeler sırasında geçmiş gradyan değerlerine göre öğrenme oranını ayarlamasıdır. AdaDelta algoritması da gradyan iniş yönteminin bir varyantıdır. Gradyan değeri, her yinelemede parametrenin güncellenmiş değerini oluşturmak için de kullanılır. Adam algoritmasına uyarlanabilir moment tahmini denir. Gradyan teriminden iki m ve v vektörü oluşturur ve başlangıç değeri 0'dır. NAG algoritması, Nesterov tarafından önerilen bir dışbükey optimizasyon yöntemidir. Standart gradyan iniş yönteminin ağırlık güncelleme formülüne benzer şekilde, NAG algoritması, başlangıç değeri 0 olan bir v vektörü oluşturur. RMSProp algoritması aynı zamanda standart gradyan iniş yönteminin bir varyantıdır. Gradyan değerinden bir vektör oluşturur ve onu 0 olarak başlatır.
Parametre başlatma ve momentum terimleri, algoritmanın yakınsaması için çok önemlidir ve literatür bu iki faktörü analiz eder. Bakış açısı, derin sinir ağlarının ve tekrarlayan sinir ağlarının eğitim optimizasyon problemleri için, ağırlığın başlangıç değeri ve momentum teriminin hem önemli hem de her ikisinin de vazgeçilmez olmasıdır. Başlangıç değeri yanlış ayarlanmışsa, momentum terimi kullanılsa bile iyi bir etkiye yakınsamak zor olacaktır; Öte yandan, başlangıç değeri iyi ayarlanmış ancak momentum terimi kullanılmamışsa yakınsama etkisinden ödün verilecektir.
Teorik açıklama
Evrişimli ağlar genellikle derin bir seviyeye sahiptir ve üzerinde katı ve ayrıntılı analizler yapmak zordur. Ağın uygulaması ve tasarımıyla karşılaştırıldığında, teorisi ve çalışma mekanizması hakkında nispeten az sayıda analiz ve açıklama vardır. Evrişimli ağın çalışma mekanizmasını net bir şekilde analiz edebilir ve evrişimsel işlemi görsel olarak gösterebilirsek, evrişimli ağı anlamak ve ağın tasarımı için büyük önem kazanacaktır.
Çok katmanlı evrişimli sinir ağının teorik açıklaması ve analizi iki yönden gelir. İlk yön, matematiksel bir perspektiften analiz, ağın temsil yeteneğinin matematiksel analizi ve haritalama özellikleri; ikinci yön, çok katmanlı evrişimli ağ ile insan beyni görsel sistemi arasındaki ilişkinin incelenmesidir. İkisi arasındaki ilişkiyi analiz etmek yararlıdır
1.
2.
Makine vizyonu
AdaBoostCascade CNNDenseBoxFemaleness-NetMT-CNN
R-CNNSPPFast R-CNNFaster R-CNNYOLOSSDR-FCNFPN

5LERENLMRM33F1EN1NM1

FCN
FCNAlexNet31x1

DeepLab3atrousatrous

SegNetsoftmax

max
SobelCannySobel
DeepEdge
1.Canny
2.4
3.2
4.
5.


DeepContourpositive-sharing loss

Holistically-Nested

İşleme akışı şu şekildedir:
1.
2.

RGB

RGB
RGB

3SPPSPPImageNet
ImageNetVGG
Multi-Domaindomain-specific
Grafikler
3
2D3D
3DO-CNN3D3D3D

Navier-Stokes

42

GramGram

Leon Gram


High Dynamic RangeHDRHDR
HDRLDRLow Dynamic RangeHDR1.LDR2.HDR1
HDR3LDRHDRHDR3HDR

Doğal dil işleme
max
WMT 14--GoogleLSTM
CaffeAlexNet200MBVGG500MBapp
GPU
AlexNet1/9VGG-161/13
deep compression3123
BNN
XNOR
XNORXNOR1/3258
Referanslar:
.LeCun, B.Boser, J.S.Denker, D.Henderson, R.E.Howard, W.Hubbard, and L.D.Jackel. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1989.
Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Handwritten digit recognition with a back-propagation network. In David Touretzky, editor, Advances in Neural Information Processing Systems 2 (NIPS*89), Denver, CO, 1990, Morgan Kaufman.
Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, november 1998.
H. Rowley, S. Baluja, and T. Kanade. Neural Network-Based Face Detection. In:Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, CA, USA: IEEE Computer Society, 1996. 203-208
H. Rowley, S. Baluja, and T. Kanade. Rotation Invariant Neural Network-Based Face Detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Santa Barbara, CA, USA: IEEE Computer Society, 1998. 38-44
S Lawrence, C L Giles, Ah Chung Tsoi, Andrew D Back.Face recognition: a convolutional neural-network approach.1997, IEEE Transactions on Neural Networks.
P. Y. Simard, D. Steinkraus, and J. C. Platt, Best practices for convolutional neural networks applied to visual document analysis. in null. IEEE, 2003.
X. Glorot, Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. AISTATS, 2010.
Alex Krizhevsky, Ilya Sutskever, Geoffrey E.Hinton. ImageNet Classification with Deep Convolutional Neural Networks.
G.E.Hinton, N.Srivastava, A.Krizhevsky, I.Sutskever, and R.R.Salakhutdinov. Improving neural networks by preventing coadaptation of feature detectors. arXiv:1207.0580, 2012.
Nair, V. and Hinton. Rectified linear units improve restricted Boltzmann machines. In L. Bottou and M. Littman, editors, Proceedings of the Twenty-seventh International Conference on Machine Learning (ICML 2010).
Zeiler M D, Fergus R. Visualizing and Understanding Convolutional Networks. European Conference on Computer Vision, 2013.
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions, Arxiv Link:
K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition. 2015, computer vision and pattern recognition.
Lin, Min, Qiang Chen, and Shuicheng Yan. Network in network. arXiv preprint arXiv:1312.4400
Zeiler M D, Krishnan D, Taylor G W, et al. Deconvolutional networks. Computer Vision and Pattern Recognition, 2010.
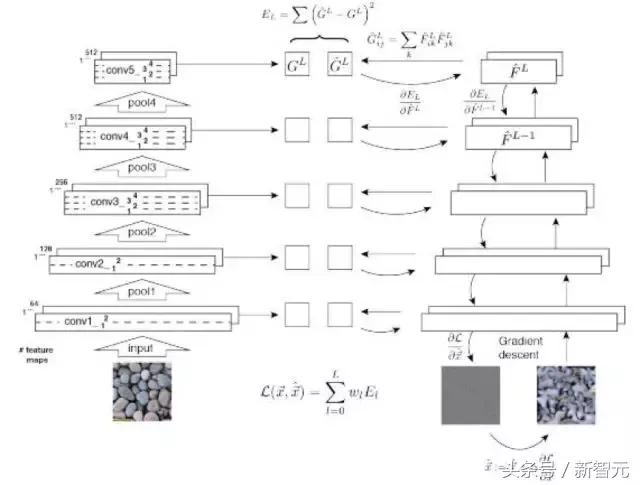
Stephane Mallat. Understanding deep convolutional networks. 2016, Philosophical Transactions of the Royal Society A.
Aravindh Mahendran, Andrea Vedaldi. Understanding Deep Image Representations by Inverting Them. CVPR 2015.
K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV. 2014.
Ross Girshick. Fast R-CNN. 2015, international conference on computer vision.
Anelia Angelova, Alex Krizhevsky, Vincent Vanhoucke, Abhijit Ogale, Dave Ferguson. Real-Time Pedestrian Detection With Deep Network Cascades.
Haoxiang Li, Zhe Lin, Xiaohui Shen, Jonathan Brandt, Gang Hua. A convolutional neural network cascade for face detection. 2015, computer vision and pattern recognition
Lichao Huang, Yi Yang, Yafeng Deng, Yinan Yu. DenseBox: Unifying Landmark Localization with End to End Object Detection. 2015, arXiv: Computer Vision and Pattern Recognition
Shuo Yang, Ping Luo, Chen Change Loy, Xiaoou Tang. Faceness-Net: Face Detection through Deep Facial Part Responses.
Yi Sun, Xiaogang Wang, Xiaoou Tang. Deep Convolutional Network Cascade for Facial Point Detection. 2013, computer vision and pattern recognition.
Kobchaisawat T, Chalidabhongse T H. Thai text localization in natural scene images using Convolutional Neural Network. Asia-Pacific Signal and Information Processing Association, 2014 Annual Summit and Conference (APSIPA). IEEE, 2014: 1-7.
Guo Q, Lei J, Tu D, et al. Reading numbers in natural scene images with convolutional neural networks. Security, Pattern Analysis, and Cybernetics (SPAC), 2014 International Conference on. IEEE, 2014: 48-53.
Xu H, Su F. A robust hierarchical detection method for scene text based on convolutional neural networks. Multimedia and Expo (ICME), 2015 IEEE International Conference on. IEEE, 2015: 1-6.
Cireşan D C, Meier U, Gambardella L M, et al. Convolutional neural network committees for handwritten character classification. Document Analysis and Recognition (ICDAR), 2011 International Conference on. IEEE, 2011: 1135-1139.
Long J, Shelhamer E, Darrell T, et al. Fully convolutional networks for semantic segmentation. Computer Vision and Pattern Recognition, 2015.
I. Sutskever, J. Martens, G. Dahl, and G. Hinton. On the Importance of Initialization and Momentum in Deep Learning. Proceedings of the 30th International Conference on Machine Learning, 2013.
Hyeonwoo Noh, Seunghoon Hong, Bohyung Han. Learning Deconvolution Network for Semantic Segmentation. 2015, international conference on computer vision.
L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L.Yuille. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. 2016.
Vijay Badrinarayanan, Alex Kendall, Roberto Cipolla. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.
R. Girshick, J. Donahue, T. Darrell, J. Malik. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, May. 2015.
Wei Shen, Xinggang Wang, Yan Wang, Xiang Bai, Zhijiang Zhang. DeepContour: A deep convolutional feature learned by positive-sharing loss for contour detection. 2015 computer vision and pattern recognition.
Saining Xie, Zhuowen Tu. Holistically-Nested Edge Detection. 2015. international conference on computer vision.
Gedas Bertasius, Jianbo Shi, Lorenzo Torresani. DeepEdge: A multi-scale bifurcated deep network for top-down contour detection. 2015, computer vision and pattern recognition
Gatys L A, Ecker A S, Bethge M. Image Style Transfer Using Convolutional Neural Networks. CVPR 2016.
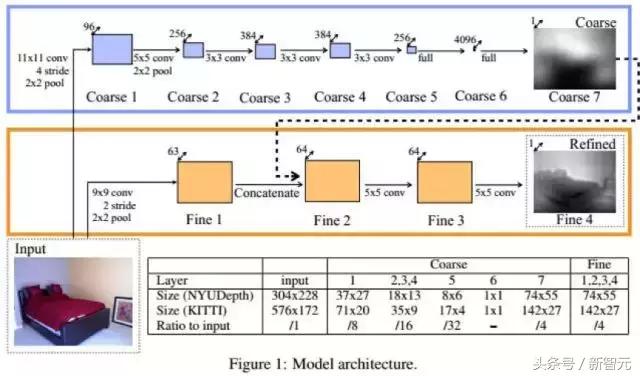
David Eigen, Christian Puhrsch, Rob Fergus. Depth Map Prediction from a Single Image using a Multi-Scale Deep Network. 2014, neural information processing systems.
David Eigen, Rob Fergus. Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-scale Convolutional Architecture. 2015, international conference on computer vision.
Naiyan Wang, Dityan Yeung. Learning a Deep Compact Image Representation for Visual Tracking. 2013, neural information processing systems.
Naiyan Wang, Siyi Li, Abhinav Gupta, Dityan Yeung. Transferring Rich Feature Hierarchies for Robust Visual Tracking. 2015, arXiv: Computer Vision and Pattern Recognition.
Hyeonseob Nam, Bohyung Han. Learning Multi-domain Convolutional Neural Networks for Visual Tracking. 2016, computer vision and pattern recognition.
Lijun Wang, Wanli Ouyang, Xiaogang Wang, Huchuan Lu. Visual Tracking with Fully Convolutional Networks. 2015, international conference on computer vision.
Chao Ma, Jiabin Huang, Xiaokang Yang, Minghsuan Yang. Hierarchical Convolutional Features for Visual Tracking. 2015, international conference on computer vision.
Yuankai Qi, Shengping Zhang, Lei Qin, Hongxun Yao, Qingming Huang, Jongwoo Lim, Minghsuan. Hedged Deep Tracking. 2016, computer vision and pattern recognition.
Luca Bertinetto, Jack Valmadre, Joao F Henriques, Andrea Vedaldi, Philip H S Torr. Fully-Convolutional Siamese Networks for Object Tracking. 2016, european conference on computer vision.
David Held, Sebastian Thrun, Silvio Savarese. Learning to Track at 100 FPS with Deep Regression Networks. 2016, european conference on computer vision.
Pengshuai Wang, Yang Liu, Yuxiao Guo, Chunyu Sun, Xin Tong. O-CNN: octree-based convolutional neural networks for 3D shape analysis. 2017, ACM Transactions on Graphics.
Mengyu Chu, Nils Thuerey. Data-Driven Synthesis of Smoke Flows with CNN-based Feature Descriptors. 2017, ACM Transactions on Graphics
Xiao Li, Yue Dong, Pieter Peers, Xin Tong. Modeling surface appearance from a single photograph using self-augmented convolutional neural networks. 2017, ACM Transactions on Graphics.
Nima Khademi Kalantari, Ravi Ramamoorthi. Deep high dynamic range imaging of dynamic scenes. 2017, ACM Transactions on Graphics.
Leon A Gatys, Alexander S Ecker, Matthias Bethge. Texture synthesis using convolutional neural networks. 2015, neural information processing systems.
Omry Sendik, Daniel Cohenor. Deep Correlations for Texture Synthesis. 2017, ACM Transactions on Graphics
Michael Gharbi, Jiawen Chen, Jonathan T Barron, Samuel W Hasinoff, Fredo Durand. Deep Bilateral Learning for Real-Time Image Enhancement. 2017, ACM Transactions on Graphics.
Jonathan Tompson, Kristofer Schlachter, Pablo Sprechmann, Ken Perlin. Accelerating Eulerian Fluid Simulation With Convolutional Networks. 2016,international conference on machine learning.
Peiran Ren,Yue Dong,Stephen Lin,Xin Tong,Baining Guo. Image based relighting using neural networks. 2015,international conference on computer graphics and interactive techniques.
Richard zhang, Jun-Yan Zhu, Phillip Isola, XinYang Geng, Angela S. Lin, Tianhe Yu, Alexei A. Efros. Real-Time User-Guided Image Colorization with Learned Deep Priors.
Yoon Kim. Convolutional Neural Networks for Sentence Classification. 2014, empirical methods in natural language processing.
Xiang Zhang, Junbo Zhao, and Yann LeCun. Character-level convolutional networks for text classification. arXiv preprint arXiv:1509.01626, 2015.
Rie Johnson and Tong Zhang. Effective use of word order for text categorization with convolutional neural networks. arXiv preprint arXiv:1408.5882, 2014.
Phil Blunsom, Edward Grefenstette, Nal Kalchbrenner, et al. A Convolutional neural network for modelling sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. 2015.
Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, Yann N. Dauphin. Convolutional Sequence to Sequence Learning. 2017.
S. Ioffe and C. Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv preprint arXiv:1502.03167 (2015).
Duchi, E. Hazan, and Y. Singer. Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. The Journal of Machine Learning Research, 2011.
D. Kingma, J. Ba. Adam: A Method for Stochastic Optimization. International Conference for Learning Representations, 2015.
T. Tieleman, and G. Hinton. RMSProp: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning.Technical report, 2012.
M. Zeiler. ADADELTA: An Adaptive Learning Rate Method. arXiv preprint, 2012.
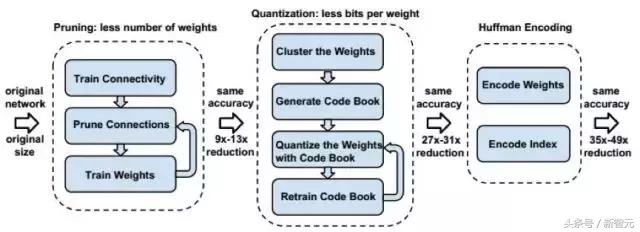
Han, Song, Pool, Jeff, Tran, John, and Dally, William J. Learning both weights and connections for efficient neural networks. In Advances in Neural Information Processing Systems, 2015.
Song Han, Huizi Mao, William J Dally. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. 2016, international conference on learning representations.
Matthieu Courbariaux, Itay Hubara, Daniel Soudry, Ran Elyaniv, Yoshua Bengio. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1. 2016,arXiv: Learning.
Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, Ali Farhadi. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. 2016, european conference on computer vision.
Topluluğa katıl
Xinzhiyuan AI teknolojisi + endüstri topluluğunun işe alımında, AI teknolojisi + endüstrisiyle ilgilenen öğrenciler küçük bir WeChat asistanı hesabı ekleyebilirler: aiera2015_3 Gruba katılın; incelemeyi geçtikten sonra sizi gruba katılmaya davet edeceğiz. Topluluğa katıldıktan sonra, grup açıklamalarını değiştirmeniz gerekir (isim-şirket-pozisyon; profesyonel grup incelemesi katıdır, lütfen anlayın).