Grafiksel makine öğrenimi: herkesin anlayabileceği algoritma ilkeleri

Kaynak: Heart of the Machine
Bu makale hakkında 2271 kelime , Okumanız tavsiye edilir 5 dakika
Bu makale bir blog gönderisinin içeriğini düzenler ve okuyucular, bu resimlere dayanarak görünüşte gelişmiş makine algoritması öğrenimini anlayabilir.

Makine öğrenimi konusu o kadar yaygın hale geldi ki, herkes onun hakkında konuşuyor, ancak çok az insan bunu tam olarak anlayabilir. İnternetteki mevcut makine öğrenimi makalelerinden bazıları belirsiz, fazla teorik veya yapay zeka, veri bilimi ve gelecekteki çalışmaların büyüsünü kapsıyor.
Bu nedenle, bu makalenin yazarı vas3k, okuyucuların kısa bir dil ve net grafik içerikle makine öğrenimini anlamasını kolaylaştırıyor. Makale, belirsiz ve zor teorik girişin yanı sıra, makine öğrenimindeki pratik problemlere, etkili çözümlere ve anlaşılması kolay teorilere odaklanıyor. İster programcı ister yönetici olun, bu makale tam size göre.
AI'nın kapsamı
Yapay zeka hangi alanları içerir ve onunla çeşitli teknik terimler arasındaki ilişki nedir? Aslında, birden fazla yargı yöntemimiz var ve AI kategorilerinin bölünmesi benzersiz olmayacak.Örneğin, en "yaygın" bilgi aşağıdaki şekilde gösterildiği gibi olabilir.
Düşünebilirsin:
- Yapay zeka, biyoloji veya kimyaya benzer eksiksiz bir bilgi alanıdır;
- Makine öğrenimi, yapay zekanın çok önemli bir parçası, ancak tek kısmı değil;
- Sinir ağı, şu anda çok popüler olan bir tür makine öğrenimidir, ancak yine de başka mükemmel algoritmalar vardır;

Ancak, derin öğrenme tüm sinir ağları mı? Açıktır ki, örneğin, türevlenemeyen bileşenlere dayanan ilk derin öğrenme modeli olan Zhou Zhihua'nın derin ormanı olmak zorunda değildir. Bu nedenle, aşağıdaki çiçek kitabındaki daha bilimsel bir bölüm olabilir:

Makine öğreniminin altında, temsilin kendisini araştırmak için makine öğrenimini kullanmanın tüm yöntemlerini özetleyen temsil öğrenme olmalıdır. Veri özelliklerinin manuel olarak tasarlanmasını gerektiren geleneksel makine öğrenimi ile karşılaştırıldığında, bu yöntemler yararlı veri özelliklerini kendi başlarına öğrenebilir. Derin öğrenmenin tamamı, aynı zamanda, katmanlı bir model aracılığıyla basit temsillerden karmaşık temsiller oluşturan bir tür temsil öğrenimidir.
Makine öğrenimi yol haritası
Tembel iseniz, işte referansınız için eksiksiz bir teknik yol haritası.

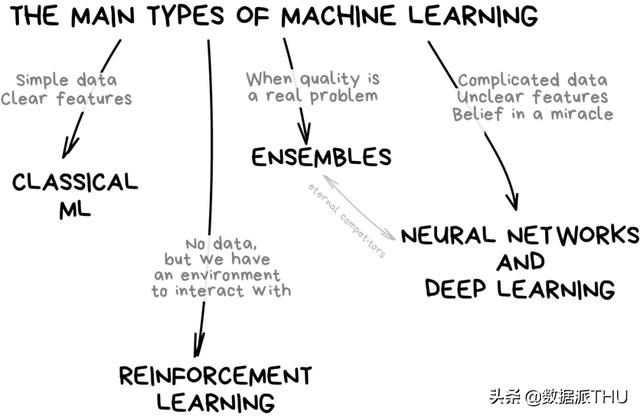
Mevcut genel sınıflandırmaya göre, makine öğrenimi esas olarak dört kategoriye ayrılmıştır:
- Klasik makine öğrenimi;
- Takviye öğrenme
- Sinir ağı ve derin öğrenme;
- Entegrasyon yöntemi
Klasik makine öğrenimi
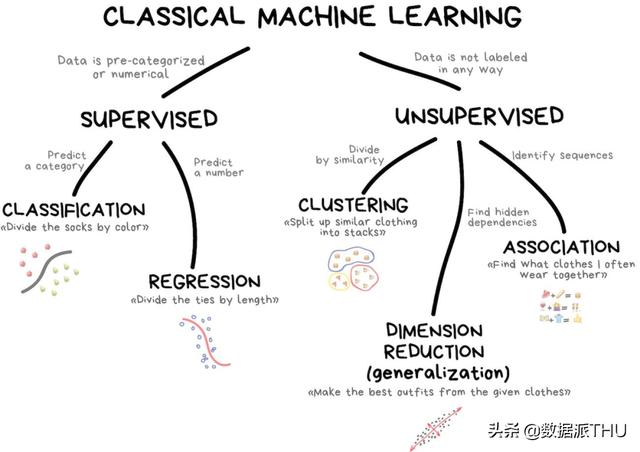
Klasik makine öğrenimi genellikle iki kategoriye ayrılır: denetimli öğrenme ve denetimsiz öğrenme.
Denetimli öğrenme
Sınıflandırmada, model her zaman bir öğretmene, yani karşılık gelen özelliğin bir açıklamasına ihtiyaç duyar, böylece makine bu açıklama öğrenmeye dayalı olarak daha fazla sınıflandırma gerçekleştirebilir. Her şey sınıflandırılabilir, kullanıcıları ilgi alanlarına göre sınıflandırabilir, makaleleri dile ve konuya göre sınıflandırabilir, müziği türe göre sınıflandırabilir ve e-postayı anahtar kelimelere göre sınıflandırabilir.
Spam filtrelemede, Naive Bayes algoritması son derece yaygın olarak kullanılmaktadır. Aslında, Naive Bayes bir zamanlar en zarif ve pratik algoritma olarak kabul edildi.

Destek vektör makinesi (SVM), en popüler klasik sınıflandırma yöntemidir. Ayrıca var olan her şeyi sınıflandırmak için kullanılır: fotoğraflarda, belgelerde vb. Bitkilerin görünümü. Destek vektör makinesinin arkasındaki fikir de çok basit: Aşağıdaki şekli örnek olarak alın, veri noktaları arasında en büyük marjla iki çizgi çizmeye çalışır.

Denetimli öğrenme gerilemesi
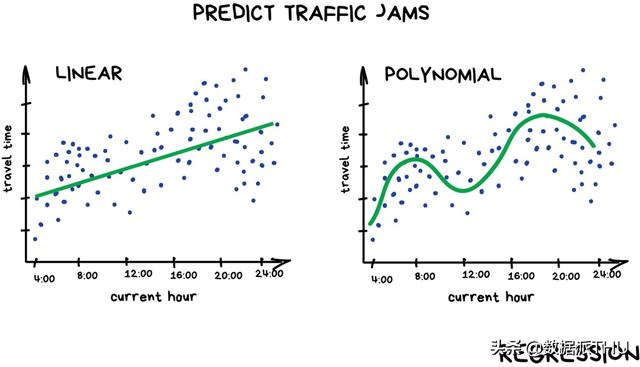
Regresyon temelde sınıflandırmadır, ancak tahminin konusu bir kategoriden ziyade bir sayıdır. Örneğin, kilometreye göre hesaplanan araba fiyatları, zamana göre hesaplanan trafik, şirket büyümesine göre hesaplanan pazar talebi vb. Tahmin zamana bağlı olduğunda, regresyon çok uygun bir seçimdir.
Denetimsiz öğrenme
Denetimsiz öğrenme ancak 1990'larda icat edildi. "Hedefi bilinmeyen özelliklere göre bölümlere ayırmak ve makine en iyi yolu seçer" olarak tanımlanabilir.
Denetimsiz öğrenme kümeleme
Kümeleme, önceden tanımlanmış sınıflar içermeyen bir sınıflandırmadır. Örneğin, tüm renklerinizi hatırlamadığınızda çorapları renge göre sınıflandırın. Kümeleme algoritmaları, belirli özellikler aracılığıyla benzer nesneleri bulmaya ve bunları bir kümede birleştirmeye çalışır.

Denetimsiz öğrenme boyutunda azalma
İnsanlar her zaman soyut şeyleri kullanmak için parçalı özelliklerden daha uygundur. Örneğin, üçgen kulaklı, uzun burunlu ve büyük kuyruklu tüm köpekleri iyi bir soyut kavram olan "çoban köpeği" içinde birleştirin.
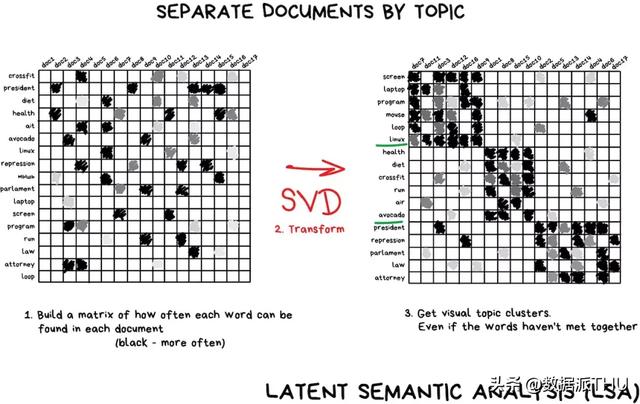
Diğer bir örnek ise bilim ve teknoloji ile ilgili makalelerin daha teknik terimlere sahip olması ve siyasetçilerin isimlerinin siyasi haberlerde en yaygın olanı olmasıdır. Bu karakteristik kelimelerin ve makalelerin potansiyel alaka düzeylerini korumak için yeni bir özellik oluşturmasını istiyorsak, SVD iyi bir seçimdir.
Denetimsiz öğrenme-ilişkilendirme kuralı öğrenme
Alışveriş sepetlerinin analizi, otomatik pazarlama stratejileri vb. Örneğin, bir müşteri kasiyere altı şişe birayla yürürse, yoluna biraz fıstık mı koymalı? Serbest bırakılırsa, bu müşteriler satın almaya ne sıklıkla gelecek? Bira fıstığı mükemmel bir eşleşme ise, bunun gibi başka hangi şeyler eşleştirilebilir?

Gerçek hayatta, her büyük perakendecinin kendine özel çözümleri vardır ve teknolojik olarak en gelişmiş olanları bu "öneri sistemleri" dir.
Entegrasyon yöntemi
"Birlik güçtür", bu eski söz, makine öğrenimi alanındaki "entegre yöntemler" in temel fikrini iyi ifade eder. Toplu yöntemlerde, güçlü bir yöntemde birleştirilebilecekleri umuduyla genellikle birden çok "zayıf model" eğitiyoruz. Çeşitli klasik makine öğrenimi yarışmaları gibi, gradyan artırma ağaçları, rastgele ormanlar vb. Gibi neredeyse en iyi sonuçları verenlerin hepsi entegre yöntemlerdir.
Genel olarak, entegrasyon yönteminin "birleştirme yöntemi" üç ana türe ayrılabilir: İstifleme, Torbalama ve Yükseltme.
Aşağıdaki şekilde gösterildiği gibi, Yığınlama genellikle heterojen zayıf öğrencileri dikkate alır. Zayıf öğrenciler önce paralel olarak eğitilebilir ve daha sonra farklı zayıf modellerin tahmin sonuçlarına dayalı olarak nihai bir tahmin sonucu çıkarmak için onları bir "meta model" aracılığıyla birleştirebilir. .

Torbalama yöntemi genellikle homojen zayıf öğrenenleri dikkate alır.Bu zayıf öğrenciler, birbirlerinden bağımsız olarak paralel olarak öğrenilir ve belirli bir deterministik ortalama alma sürecine göre birleştirilir. Tüm zayıf öğrencilerin karar ağacı modelleri olduğunu varsayarsak, ortaya çıkan Torbalama rastgele bir ormandır.

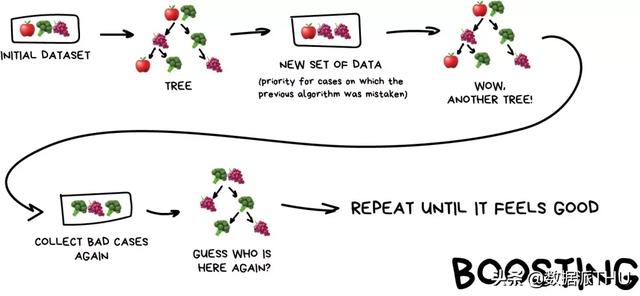
Boosting yöntemi genellikle homojen zayıf öğrenenleri dikkate alır, ancak fikri "böl ve fethet" dir. Sırayla bu zayıf öğrenenleri uyarlanabilir bir yöntemle öğrenir ve sonraki zayıf model, önceki zayıf model tarafından yanlış sınıflandırılan verileri öğrenmeye odaklanır.
Bu, "böl ve yönet" etkisini elde etmek için verilerin bir kısmına odaklanan farklı zayıf sınıflandırıcılara eşdeğerdir. Aşağıda gösterildiği gibi Boosting, farklı modelleri seri olarak birleştiren bir paradigmadır. Ünlü XGBoost ve LightGBM kitaplıklarının veya algoritmalarının tümü Boosting yöntemlerini kullanır.
Şimdi, Naive Bayes'den Boosting yöntemlerine kadar, klasik makine öğreniminin ana dalları zaten mevcut. Okuyucular daha sistematik ve ayrıntılı bir anlayış istiyorlarsa, Li Hang'ın "İstatistiksel Öğrenme Yöntemleri" ve Zhou Zhihua'nın "Makine Öğrenimi" en iyi iki Çince dersidir.
Tabii ki bu blogda yazar, pekiştirmeli öğrenme ve derin öğrenme vb. Konuları da tanıtıyor. İçerik, yapay zeka ile ilgilenen ve ana dallarla ilgisi olmayan okuyucular için çok uygun.Resimin görüntüsü ile çok iyi bir bilim olarak değerlendirilebilir. Metin. Bu basit ve anlaşılması kolay anlatımla ilgileniyorsanız, blogda ayrıntılı olarak okuyabilirsiniz.
Referans bağlantısı: https://vas3k.com/blog/machine_learning/
-Bitiş-
Tsinghua-Qingdao Veri Bilimi Enstitüsü'nün resmi WeChat kamu platformunu takip edin " AI Veri Pastası "Ve kız kardeş numarası" Veri Pastası THU "Daha fazla ders avantajı ve kaliteli içerik elde edin.