Yüz Serisi 2: Balıkçı yüzlerinin matematiksel ilkesi ve tanıma süreci
Fisher'in doğrusal ayırt edici özelliği, balıkçı yüzleri olarak yüz tanımaya uygulanır.
1. Fikirlerin tanıtımı
Fisher Linear Discriminant (FLD) olarak da adlandırılan Lineer Discriminant Analysis (Linear Discriminant Analysis, LDA), örüntü tanıma için klasik bir algoritmadır ve Belhumeur tarafından 1996 yılında örüntü tanıma ve yapay zeka alanında tanıtılmıştır. Doğrusal diskriminant analizinin temel fikri, önemli sınıflandırma bilgilerinin çıkarılması ve özellik uzay boyutlarının sıkıştırılması etkisini elde etmek için yüksek boyutlu desen örneklerini düşük boyutlu optimal vektör uzayına projelendirmektir.Projeksiyondan sonra, desen örneklerinin yeni alt uzayda en büyük sınıfa sahip olması sağlanır. Sınıflar arası en küçük mesafe, yani model uzayda en iyi ayrılabilirliğe sahiptir.
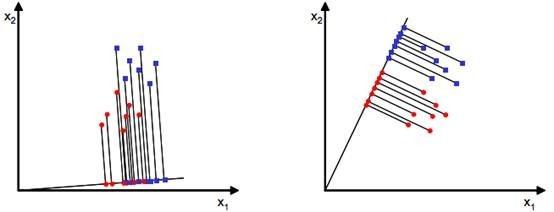
LDA, denetimli öğrenmeye sahip bir boyut azaltma teknolojisidir. Bu, PCA'dan farklıdır. PCA, örnek kategorilerinin çıktılarını dikkate almayan, denetimsiz bir boyutluluk azaltma tekniğidir. Aşağıdaki iki boyut azaltma yöntemine bakın.

Yukarıdaki resim iki projeksiyon yöntemi sunmaktadır, hangisi standartlarımızı daha iyi karşılayabilir? Sağ görüntünün yansıtma etkisinin sol görüntünün etkisinden daha iyi olduğu sezgisel olarak görülebilir, çünkü projeksiyondan sonra sağ görüntünün siyah ve mavi örnekleri daha yoğunlaşır ve mesafe açıktır. Soldaki resim, sınırda verilerle örtüşüyor. Yukarıdakiler LDA'nın ana fikridir.Elbette, pratik uygulamalarda verilerimiz birden çok kategoriden oluşur.Orijinal verilerimiz genellikle iki boyutludan fazladır ve yansıtılan veriler genellikle düz bir çizgi değil, düşük boyutlu bir hiper düzlemdir. .
İki, LDA iki sınıflandırma türevi
Veri kümemizin D = {(x1, y1), (x2, y2), ..., (xm, ym)} olduğunu varsayalım, burada herhangi bir xi örneği n boyutlu bir vektördür, yi {1,2}. Nj'yi (j = 1,2) j tipi örnek sayısı olarak tanımlarız, Xj j tipi örneklerin kümesidir ve j j tipi örneklerin ortalama vektörüdür ve j j tipi örneklerin kovaryans matrisi olarak tanımlanır. .
Şimdi, orijinal özelliklerin sayısının çok fazla olduğunu hissediyoruz ve d boyutlu özellikleri tek bir boyuta indirgeyerek, kategorinin düşük boyutlu verilere "açıkça" yansıtılmasını, yani bu boyutun her bir numunenin değerini belirleyebilmesini sağlamak istiyoruz. kategori.
Bu nedenle, aşağıdaki örnekler, kategorileri ayırt etmek için iki boyutlu bir düzlemde bir noktanın düz bir çizgi üzerinde izdüşümüne dayanmaktadır.
1. Sezgisel yargı, projeksiyondan sonra merkez noktanın mesafesidir
İki kategorinin projeksiyondan sonra ayrılıp ayrılamayacağına dair sezgisel izlenimimiz, iki kategorinin merkez noktalarının (ortalama değerler) birbirinden çok uzak olduğu yönündedir.
Bu izdüşümü gerçekleştirebilecek en iyi vektörün w (d boyutu) olduğu varsayılırsa, örnek x (d boyutu) 'nun w üzerine izdüşümü aşağıdaki formülle hesaplanabilir:

Burada elde edilen y'nin değeri 0/1 değeri değil, x'in çizgiye yansıtıldığı noktadan orijine olan mesafedir.
Her kategorinin ortalaması:

X'den w'ye projeksiyondan sonraki örnek noktalarının ortalama değeri:
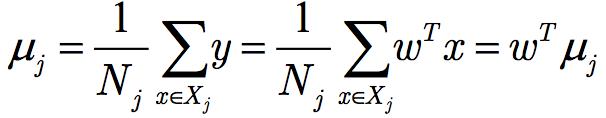
En iyi düz çizgi (w) nedir? İlk olarak, projeksiyondan sonra iki tür örneğin merkez noktalarını ayırabilen düz çizginin iyi bir düz çizgi olduğunu bulduk. Niceliksel ifade şu şekildedir:
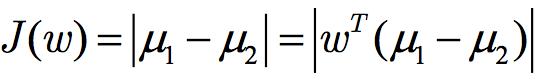
J (w) ne kadar büyükse o kadar iyidir.
2) Projeksiyondan sonra örnek noktaların kohezyonunu da dikkate almanız gerekir
Yukarıdaki J (w) çalışabilir mi? Aşağıdaki resme bakın:

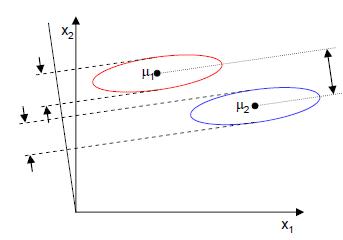
Numune noktaları elips içinde eşit olarak dağıtılır ve yatay eksen x1 üzerine yansıtıldığında, daha büyük bir merkez noktası aralığı J (w) elde edilebilir, ancak büyük örtüşme nedeniyle, x1 numune noktalarını ayıramaz. Dikey eksen x2 üzerine yansıtılan, J (w) küçük olmasına rağmen, numune noktaları ayrılabilir. Bu nedenle, numune noktaları arasındaki kohezyonu da dikkate almak gerekir, kohezyon ne kadar büyükse, numune noktaları o kadar fazla bölünür.
Bu nedenle, bir metriği, hash değerini (dağılım) göz önünde bulundururuz ve öngörülen sınıfın hash değerini hesap ederiz:

Karma değerin geometrik anlamı, numune noktalarının kohezyon prosedürüdür.Değer ne kadar büyükse, o kadar çok dağınıktır ve tam tersi, o kadar tutarlıdır.
Ve projeksiyondan sonraki örnek noktalarının tatmin edeceğini umuyoruz: Farklı sınıfların örnek noktaları ne kadar çok ayrılmışsa, aynı tür o kadar iyi, yani iki tür örnek arasındaki ortalama fark ne kadar büyükse, hash değeri o kadar iyi ve küçükse o kadar iyidir. Bu nedenle, birlikte ölçmek için J (w) ve S'yi kullanabiliriz ve son ölçüm formülü:


onların arasında:
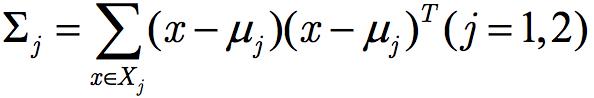
Bu formül çok tanıdık geliyor mu? Dağılım matrisleri adı verilen örnek sayısına atanan kovaryans matrisi eksik değil mi?
Sınıf içi diverjans matrisi Sw'ı şu şekilde tanımlayın:

Sınıflar arası diverjans matrisi Sb'yi şu şekilde tanımlayın:

Nihai hedef ifade şudur:

3. Lagrangian yöntemi ile çözümleme
Türetmeden önce, paydayı normalleştirmek gerekir, çünkü normalleştirme olmadan, w'nin herhangi bir indirgeme veya genişlemesi doğru olacaktır ve w belirlenemez. Yapmak

, Lagrange çarpanını ekledikten sonra türevi bulun:

Matris hesabı kullanılır ve wTSww, türetme ararken basitçe Sww2 olarak ele alınabilir.
Sw tersine çevrilebilirse, türev sonucun her iki tarafını da çarpın

, Almak

Bu sonuç, w'nin bir matris olduğunu gösterir

Özvektörler.
Bu formüle Fisher doğrusal ayrımcılık denir.
Tekrar gözlemleyelim ve Sb'nin formülünü bulalım

O zaman 1-2 ve w aynı yönde olduğundan, o zaman:

Nihai özdeğer formülünü şu şekilde ikame etmek:

W'nin herhangi bir genişlemesi veya daralması sonucu etkilemediğinden, her iki taraftaki bilinmeyen sabitler elimine edilerek elde edilebilir:

Bu noktada, en iyi yönü w bulmak için sadece orijinal numunenin ortalamasını ve varyansını elde etmemiz gerekiyor. Bu, Fisher tarafından 1936'da önerilen doğrusal diskriminant analizidir.
Son iki boyutlu örneğin projeksiyon sonucu:
Üçüncüsü, LDA çoklu kategorisi

Veri kümemizin D = ((x1, y1), (x2, y2), ..., ((xm, ym))) olduğunu varsayalım, burada herhangi bir xi örneği n boyutlu bir vektör, yi {C1, C2,. .., Ck}. Nj (j = 1,2 ... k) 'yi j tipi örneklerin sayısı, Xj (j = 1,2 ... k) olarak j tipi ve j (j = 1, 2 ... k), j-inci tip numunenin ortalama vektörüdür ve j (j = 1,2 ... k), j-inci tip numune için kovaryans matrisi olarak tanımlanır. LDA'daki iki sınıflandırma formülü, birden çok kategoriye kolayca genişletilebilir.
Düşük boyuta çok sınıflı bir projeksiyon olduğumuzdan, bu zamanda yansıtılan düşük boyutlu uzay düz bir çizgi değil, bir hiper düzlemdir. Öngördüğümüz düşük boyutlu uzayın boyutunun d olduğunu varsayarsak, karşılık gelen taban vektörü (w1, w2, ... wd) ve temel vektörlerden oluşan matris, bir n × d matris olan W'dir.
Bu noktada, optimizasyon hedefimiz şöyle olmalıdır:

onların arasında:
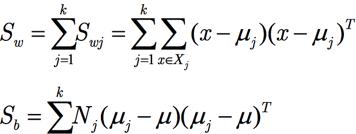
Sb'nin iki kategorili duruma göre değiştirilmesi gerekiyor. Başlangıçta, iki ortalama noktanın karmasını ölçüyordu, ancak şimdi, numunenin merkezine göre her bir ortalama nokta türünün karmasını ölçüyor. i'yi örnek noktalar olarak ele almaya benzer şekilde, ortalamanın kovaryans matrisidir.Belirli bir kategoride daha fazla örnek noktası varsa, ağırlık daha büyük olacaktır ve Ni / N ile temsil edilebilir, ancak J (w) katlara duyarlı olmadığından, Ni'yi kullan.
Hem WTSbW hem de WTSwW matrislerdir, skaler değildir ve skaler bir fonksiyon olarak optimize edilemez. Aşağıdaki forma geçelim:
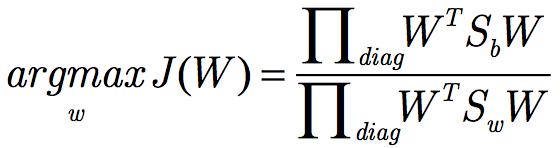
Ana diyagonal elemanların ürünü ile değiştirin

Son olarak, matrisin özdeğerlerini bulmaya gelir. İlk bul

Sonra W matrisini oluşturmak için ilk K özvektörlerini alın.
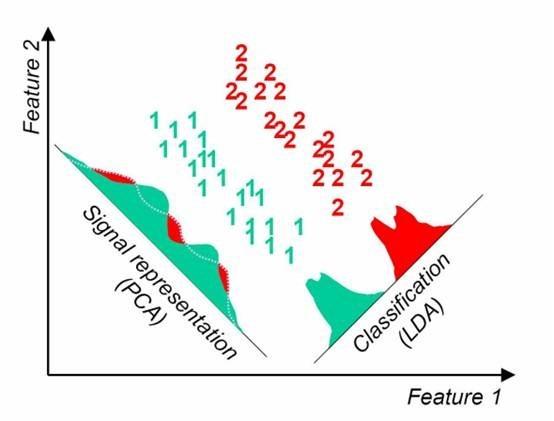
Beşinci, LDA ve PCA karşılaştırması
Boyut azaltma için LDA kullanılır PCA ile birçok benzerlik ve farklılık vardır, bu nedenle ikisi arasındaki benzerlikleri ve farklılıkları karşılaştırmaya değer.
İlk önce benzerliklere bakıyoruz:
1) Her ikisi de verinin boyutunu azaltabilir.
2) Her ikisi de boyutsallık indirgemede matris öz bileşimi fikrini kullanır.
3) Her ikisi de verilerin Gauss dağılımına uygun olduğunu varsayar.
Sonra farklılıklara bakarız:
1) LDA denetimli bir boyutluluk azaltma yöntemidir, PCA ise denetimsiz bir boyut azaltma yöntemidir.
2) LDA boyutsallığında azalma, en fazla k-1 kategorilerinin sayısına indirgenebilirken, PCA'da bu kısıtlama yoktur.
3) Boyut azaltma için kullanılmasının yanı sıra, LDA sınıflandırma için de kullanılabilir.
4) LDA, en iyi sınıflandırma performansına sahip projeksiyon yönünü seçerken, PCA örnek nokta projeksiyonunun en büyük varyansa sahip olduğu yönü seçer.
Bu, aşağıdaki görüntüden görülebilir: Belirli bir veri dağılımı altında, LDA boyutsallık azaltma için PCA'dan daha iyidir.
Altıncı, balıkçı yüz tanıma örneği

Yüz veritabanı (8 kişi)

Tüm yüzlerin ortalamasını bulun

Her yüzün ortalamasını bulun

Her eksi ortalama

Dağılım matrisi
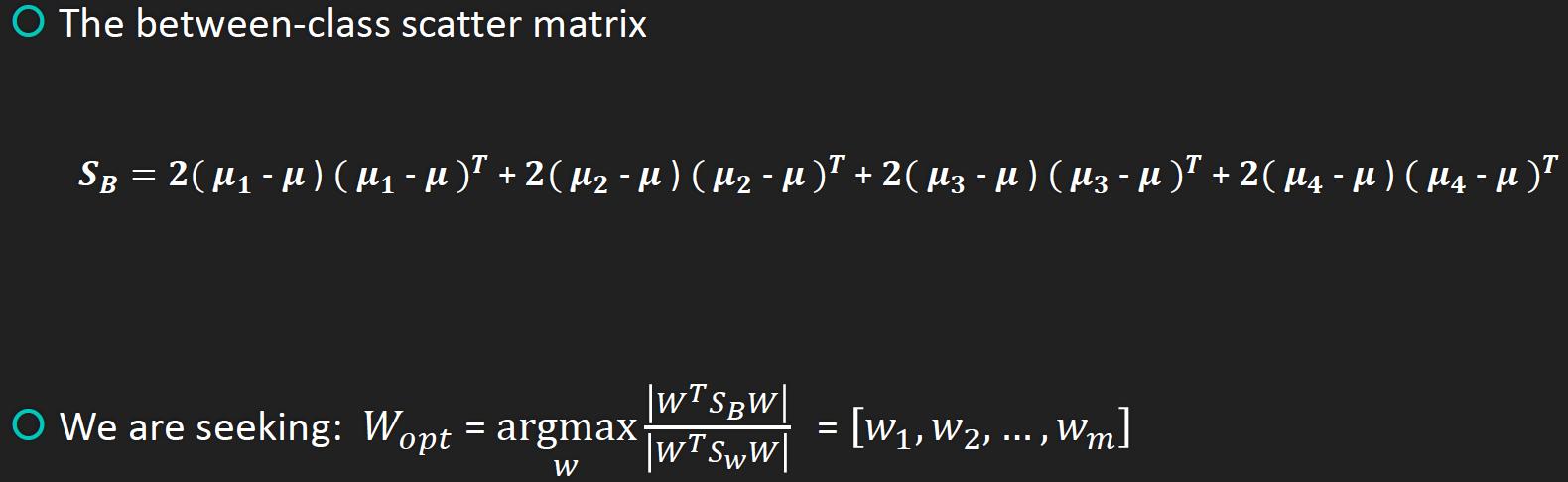
Sınıflar arası diverjans matrisi

Tekil olmayan, hesaplama özvektörü

Tekil, boyutluluğu azaltmak için PCA kullanın

ROC