Bilgi Grafiği - Python kodu ile metinden bilgi madenciliği yapmak için güçlü bir veri bilimi tekniği
Tam metin 6382 Kelimeler, tahmini öğrenme süresi 20 dakika

Kaynak: Unsplash Photography: Clem Onojeghuo
Genel Bakış
- Bilgi grafiği, veri bilimindeki en çekici kavramlardan biridir
- Bir bilgi grafiği oluşturmak için Wikipedia sayfalarından metinlerin nasıl kullanılacağını öğrenin
- Python'da bir bilgi grafiği oluşturmak için Python'daki popüler spaCy kitaplığını kullanın
Giriş
Söylemeye gerek yok, herkes Messi'yi tanıyor. Futbola dikkat etmeyenler bile ihtişamdaki en büyük oyuncuyu duymuşlardır. İşte Wikipedia sayfası:

Bu sayfa pek çok bilgi içeriyor! Yalnızca metin, çok sayıda köprü ve hatta ses klipleri yoktur. Web sayfasının tamamında pek çok alakalı ve potansiyel olarak faydalı bilgi vardır ve bunları gerçek hayata uygulama olanakları sonsuzdur.
Ancak küçük bir sorun var. Bu, makineler için ideal bir veri kaynağı değil, en azından şu anki haliyle.
Bu metin veri makinelerini okunabilir hale getirmenin bir yolunu bulabilir misiniz? Bu metin verileri, makineler tarafından kullanılabilecek ve bizim tarafımızdan kolayca yorumlanabilecek bir şeye dönüştürülebilir mi?
Cevap Evet. Veri bilimindeki en çekici kavramlardan biri olan Bilgi Grafiğini (KG) kullanabiliriz. Bilgi grafiğinin muazzam potansiyeli ve pratik uygulaması beni şok etti ve senin de benim gibi olacağına inanıyorum.
Bu makalede, bir bilgi grafiğinin ne olduğunu ve ne işe yaradığını anlayacaksınız.Daha sonra, kodun derinlemesine incelenmesi için Wikipedia'dan çıkarılan verilere dayalı bir bilgi grafiği oluşturacağız.
içindekiler
1. Bilgi grafiği nedir?
2. Bilgi grafikte nasıl temsil edilir?
Cümle bölümleme
Varlık çıkarma
İlişki çıkarma
3. Bir bilgi grafiği oluşturmak için metin verilerine güvenin

Bilgi grafiği nedir?
Öncelikle bir kavramı açıklığa kavuşturun: Bu makalede sıklıkla görülen "grafik" terimi histogramlara, pasta grafiklere veya çizgi grafiklere değil, insanlar, yerler, kuruluşlar ve hatta bir olay olabilen birbirine bağlı varlıkları ifade eder. .

Grafiğin düğümlerin ve kenarların bir kombinasyonu olduğu söylenebilir *.
Aşağıdaki verilere bir göz atın:

* Edge, düğümler arasındaki ilişkiyi temsil etmek için kullanılan düğümler arasındaki bağlantıdır.
Burada, düğüm a ve düğüm b iki farklı varlıktır ve düğümler kenarlarla birbirine bağlıdır. Şekil, oluşturabileceğimiz en küçük bilgi grafiğidir - buna üçlü (varlık-ilişki-varlık) da denir.
Bilgi grafiğinin birçok şekli ve boyutu vardır. Örneğin, Ekim 2019 itibarıyla Vikiveri'nin bilgi grafiğinde 59.910.568 düğüm bulunmaktadır.
Bilgi grafikte nasıl temsil edilir?
Bilgi grafikleri oluşturmaya başlamadan önce, bilgi veya bilginin bu grafiklere nasıl yerleştirildiğini anlamamız gerekir.
Bir örnekle açıklamak gerekirse: eğer düğüm a = Putin ve düğüm b = Rusya ise, uç büyük olasılıkla "Rusya Başkanı" olacaktır:
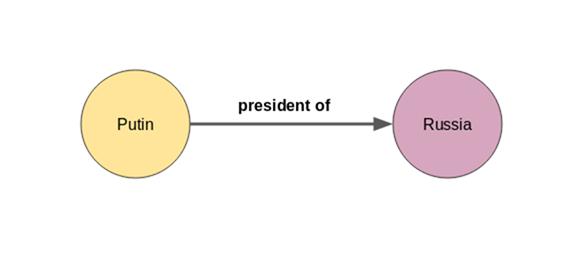
Bir düğüm veya varlığın birden fazla ilişkisi de olabilir. Putin sadece Rusya Devlet Başkanı değil, aynı zamanda Sovyet güvenlik ajansı KGB için de çalıştı. Fakat Putin hakkındaki bu yeni bilgiyi yukarıdaki bilgi grafiğine nasıl entegre edebilirim?
aslında gerçekten çok kolay. Yeni varlık "KGB" için başka bir düğüm eklemeniz yeterlidir:
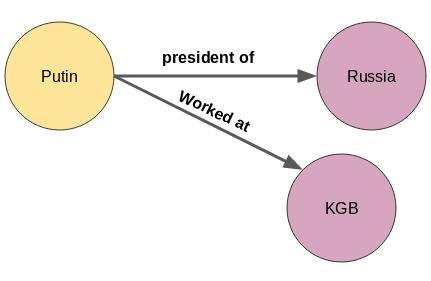
Yeni ilişki yalnızca ilk düğümde değil, aşağıda gösterildiği gibi bilgi grafiğindeki herhangi bir düğümde de eklenebilir:

Rusya, Asya-Pasifik Ekonomik İşbirliği (APEC) üyesidir
Varlıkları ve aralarındaki ilişkiyi belirlemek zor bir iş değildir. Bununla birlikte, bir bilgi grafiğini manuel olarak oluşturmak büyük miktarda bilgiyi işlemek zordur. Hiç kimse binlerce belgeye göz atmayacak ve ardından tüm varlıkları ve bunların ilişkilerini çıkaramayacak.
Bu nedenle, makine şüphesiz daha iyi bir seçimdir, yüzlerce dosyaya göz atmak onlar için çocuk oyuncağıdır. Ancak başka bir zorluk daha var - makineler doğal dili anlamıyor. Bu, Doğal Dil İşleme (NLP) teknolojisinin sırasıdır.
Metinden bir bilgi grafiği oluşturmak istiyorsanız, makinelerin doğal dili anlaması çok önemlidir. Bu, cümle bölütleme, bağımlılık ayrıştırma, konuşma bölümü etiketleme ve varlık tanıma gibi doğal dil işleme (NLP) teknolojileri kullanılarak sağlanabilir. Aşağıda daha ayrıntılı olarak tartışılacaktır.
Cümle bölütleme
Bir bilgi grafiği oluşturmanın ilk adımı, metni veya makaleyi cümlelere ayırmaktır. Ardından, yalnızca bir öznesi ve nesnesi olan cümleleri listeleyin. İşte örnek metin:
"En son tek erkekler sıralamasında Hintli tenisçi Sumit Nagal, kariyerinin en iyi sonucu olan 135'den 129'a altı basamak yükseldi. 22 yaşındaki oyuncu kısa süre önce kazandı. ATP Challenge Turnuvasını kazandı. 2019 US Open'da ilk kez sahneye çıktığında, Federer'e karşı Grand Slam'i kazandı. Nagar ilk grup maçı kazandı. (Hintli tenisçi Sumit Nagal, En son tek erkekler sıralamasında kariyerinin en iyisi 129'a 135 oldu. 22 yaşındaki oyuncu son zamanlarda ATP Challenger turnuvasını kazandı. 2019 ABD Açık'ta Federer'e karşı Grand Slam çıkışını yaptı. İlk seti Nagal kazandı.) "
Yukarıdaki paragrafı birkaç cümleye ayırıyoruz:
1. En son tek erkekler sıralamasında Hintli tenisçi Sumit Nagal (SumitNagal) 135 basamaktan 6 basamak yükselerek kariyerinin en iyi sonucu olan 129'a yükseldi. (Hintli tenisçi Sumit Nagal, son tek erkekler sıralamasında 135'ten altı sıra yükselerek kariyerinin en iyisi 129'a yükseldi.)
2. 22 yaşındaki oyuncu kısa süre önce ATP Challenge Şampiyonasını kazandı. (22 yaşındaki oyuncu kısa süre önce ATP Challenger turnuvasını kazandı)
3. 2019 ABD Açık'ta ilk kez sahneye çıktığında, Federer'e karşı Grand Slam'i kazandı. (Hemade, 2019 ABD Açık'ta Federer ile ilk Grand Slam karşılaşmasını yaptı.)
4. Nagar ilk grup maçları kazandı. (Nagalwon ilk sette.)
Bu dört cümle arasından ikinci ve dördüncü cümleleri seçeceğiz çünkü her cümle bir konu ve bir nesne içeriyor. İkinci cümlede "22 yaşında" konu, amaç ise "ATP Challenger turnuvası". Dördüncü cümlede konu "Nagal" ve "ilk küme" nesnedir:

Makinenin metni anlamasını sağlamak, özellikle birden fazla konu ve nesne olduğunda en büyük zorluktur. Yukarıdaki iki cümleyi örnek alarak, cümledeki nesneyi çıkarmak biraz zor. Bu soruna bir çözüm bulabilir misin?
Varlık çıkarma
Bir cümleden bir kelime varlığını çıkarmak zor bir iş değildir. Bunu konuşma bölümü (POS) etiketleri yardımıyla kolayca yapabiliriz. İsimler ve özel isimler bizim varlıklarımız olabilir.
Ancak, bir varlık birden fazla kelime içerdiğinde, yalnızca konuşma parçası etiketleri yeterli değildir. Cümleler arasındaki karmaşık ilişkileri analiz etmemiz gerekiyor. Önce cümlelerden birinin bağımlılık işaretini alalım. Bu görevi gerçekleştirmek için popüler spaCy kitaplığını kullanın:
ithal boşluk
nlp = spacy.load ('en_core_web_sm')
doc = nlp ("22 yaşındaki oyuncu kısa süre önce ATP Challenger turnuvasını kazandı.")
doc için tok için:
print (tok.text, "...", tok.dep_)
Çıktı:
Det
22 yıllık ... amod
- Punct
eski nsubj
son zamanlarda advmod
kazandı KÖK
ATP bileşik
Challenger bileşik
turnuva dobj
. Punct
Bağımlılık çözümleyicisine göre, bu cümledeki özne (nsubj) "eski" dir. İstediğimiz varlık bu değil. İstediğimiz "22 yaşındaki oyuncu".
"22 yıllık" bağımlılık etiketi amod'dur, yani (eski) 'nin değiştiricisi olduğu anlamına gelir.Bu nedenle, bu tür varlıkları çıkarmak için bir kural tanımlanmalıdır.
Böyle bir kural olabilir: özneyi / nesneyi ve onun değiştiricilerini çıkarın ve aralarındaki noktalama işaretlerini çıkarın.
Ama cümledeki nesneye (dobj) bakın. Bu bir "ATP Challenger turnuvası" yerine sadece bir "turnuva" dır. Bu cümlede değiştirici yoktur, sadece bileşik kelimeler vardır.
Bileşik kelimeler, farklı kelimelerin birleştirilmesiyle oluşan yeni terimleri ifade eder ve kaynak kelimelerden farklı anlamlara sahiptir. Bu nedenle, yukarıdaki kuralları güncelleyebiliriz - özne / nesneyi ve değiştiricilerini, bileşik kelimeleri ve aralarındaki noktalama işaretlerini çıkarabiliriz.
Kısacası, varlıkları çıkarmak için bağımlılık ayrıştırmasını kullanıyoruz.
İlişki ayıklayın
Varlık çıkarma işin sadece yarısıdır. Bir bilgi grafiği oluşturmak için çeşitli düğümleri (varlıkları) bağlamak için kenarlara ihtiyaç vardır. Bu kenarlar, düğümler arasındaki ilişkiyi temsil eder.
Önceki bölümdeki örneğe geri dönersek, bir bilgi grafiği oluşturmak için birkaç cümle seçin:

Bu iki cümlede özne ve nesne arasındaki ilişkiyi tahmin edebilir misiniz?
İki cümle aynı ilişkiye sahip - "kazandı". Bu ilişkileri nasıl çıkaracağınızı görün. Bağımlılık çözümü burada tekrar kullanılacaktır:
doc = nlp ("Nagal ilk seti kazandı.")
doc için tok için:
print (tok.text, "...", tok.dep_)
Çıktı:
Nagal ... nsubj
kazandı KÖK
the det
ilk ... amod
ayarla dobj
. Punct
İlişkiyi çıkarmak için, cümlenin içindeki fiil olan cümlenin kökü de bulunmalıdır. Bu nedenle, bu cümlede bulunan ilişki "kazandı" dır.
Son olarak bu iki cümlenin bilgi grafiği şu şekildedir:

Metin verilerinden bilgi grafiği oluşturun
Kod işleme zamanı! Jupyter Not Defterlerini (veya istediğiniz herhangi bir entegre geliştirme ortamı-IDE'yi) açın.
Sıfırdan bir bilgi grafiği oluşturmak için Wikipedia'da bulunan filmlerden bir dizi metin kullanın. 500'den fazla Wikipedia makalesinden yaklaşık 4300 cümle çıkardım. Her cümle iki varlık içerir - bir özne ve bir nesne. Bu cümleleri buradan indirebilirsiniz.
Hesaplamayı hızlandırabilen Google Colab kullanılması tavsiye edilir.
Kitaplığı içe aktar
yeniden ithal
pandaları pd olarak içe aktar
bs4'ü içe aktar
ithalat istekleri
ithal boşluk
spacy ithalat anlaşmazlığından
nlp = spacy.load ('en_core_web_sm')
spacy.matcher'dan ithalat Matcher
spacy.tokens'ten import Span
networkx'i nx olarak içe aktar
matplotlib.pyplot dosyasını plt olarak içe aktar
tqdm'den ithal tqdm
pd.set_option ('display.max_colwidth', 200)
% matplotlib satır içi
Verileri oku
Wikipedia cümlelerini içeren bir CSV dosyasını okuyun:
# wikipedia cümlelerini içe aktarın
candidate_sentences = pd.read_csv ("wiki_sentences_v2.csv")
candidate_sentences.shape
Çıktı: (4318, 1)
Birkaç örnek cümleye bakın:
candidate_sentences.sample (5)
Çıktı:

Cümlelerden birinin konusunu ve nesnesini kontrol edin. İdeal olarak, cümlede bir konu ve bir nesne bulunmalıdır:
doc = nlp ("geri çekilme süreci astm standardı d823 tarafından yönetilir")
doc için tok için:
print (tok.text, "...", tok.dep_)
Çıktı:

iyi! Yalnızca bir özne "süreç" ve bir nesne "standart" vardır. Diğer cümleleri de benzer şekilde kontrol edebilirsiniz.
Varlık çifti çıkarma
Bir bilgi grafiği oluşturmak için en önemli şey aralarındaki düğümler ve kenarlardır.
Bu düğümler, Wikipedia cümlelerinde görünen varlıklardır. Kenarlar, çeşitli varlıkları birbirine bağlayan ilişkilerdir. Bu unsurları denetimsiz bir şekilde çıkaracağız, yani cümlenin gramerine güveneceğiz.
Ana fikir, bir cümleye göz atarken karşılaşılan konuyu ve nesneyi çıkarmaktır. Bununla birlikte, başka zorluklar da vardır - varlık, "kırmızı şarap" gibi birden fazla kelimeye sahip olabilir ve bağımlılık ayrıştırıcısı, konu veya nesne olarak yalnızca tek bir kelimeyi işaretleyecektir.
Bu nedenle, yukarıda bahsedilen zorluğu çözerken özneyi ve nesneyi (yani varlığı) bir cümleden çıkarmak için aşağıda bir işlev oluşturulur. Kolaylık sağlamak için, kod birden çok bölüme ayrılmıştır:
defget_entities (gönderildi):
## parça 1
ent1 = ""
ent2 = ""
prv_tok_dep = "" Cümledeki önceki simgenin # bağımlılık etiketi
prv_tok_text = "" cümlede # önceki simge
prefix = ""
değiştirici = ""
################################################ ###########
nlp'de tok için (gönderildi):
## parça 2
# jeton bir noktalama işaretiyse, sonraki jetona geçin
tok.dep_! = "noktalama" ise:
# check: belirteç bileşik bir sözcüktür ya da değildir
tok.dep_ == "bileşik" ise:
prefix = tok.text
# önceki kelime de bir 'birleşik' ise, o zaman mevcut kelimeyi ona ekleyin
prv_tok_dep == "bileşik" ise:
prefix = prv_tok_text + "" + tok.text
# check: belirteç bir değiştiricidir veya değildir
tok.dep_.endswith ("mod") == Doğru ise:
değiştirici = tok.text
# önceki kelime de bir 'birleşik' ise, o zaman mevcut kelimeyi ona ekleyin
prv_tok_dep == "bileşik" ise:
değiştirici = prv_tok_text + "" + tok.text
## yığın 3
tok.dep_.find ("subj") == Doğru ise:
ent1 = değiştirici + "" + önek + "" + tok.text
prefix = ""
değiştirici = ""
prv_tok_dep = ""
prv_tok_text = ""
## yığın 4
tok.dep_.find ("obj") == Doğru ise:
ent2 = değiştirici + "" + önek + "" + tok.text
## yığın 5
# değişkenleri güncelle
prv_tok_dep = tok.dep_
prv_tok_text = tok.text
################################################ ###########
dönüş
Yukarıdaki fonksiyondaki kod bloğunu açıklamama izin verin:
Bölüm 1
Bu bölümde bazı boş değişkenler tanımladım. prv_tok_dep ve prv_tok_text önceki kelimeyi cümle içinde ve sırasıyla kendi bağımlılık işaretini kaydedecektir. Önek ve değiştirici, konu veya nesneyle ilişkili metni saklayacaktır.
Plaka 2
Ardından, cümledeki tüm etiketleri gözden geçirin. İlk önce, işaretin bir noktalama işareti olup olmadığını kontrol edin. Eğer öyleyse, onu görmezden geleceğiz ve bir sonraki jetona bakacağız. Etiket bir bileşik sözcüğün parçasıysa (bağımlılık etiketi = "bileşik"), "önek" değişkeninde saklanacaktır. Bir bileşik kelime, "Futbol Stadyumu" ("Futbol Stadyumu"), "Hayvansal Aşık" ("animallover") gibi yeni bir anlam kelimesi oluşturmak için birbirine bağlanan birden fazla kelimenin bir kombinasyonudur.
Bir cümle içinde bir özne veya nesneyle karşılaştığımızda, ona bu öneki ekleriz. "Güzel gömlek", "büyük ev" ve benzeri gibi aynı değiştiriciler.
3. Bölüm
Burada, eğer etiket konu ise, ent1 değişkenindeki ilk varlık olarak yakalanacaktır. Önek, değiştirici, prv_tok_dep ve prv_tok_text gibi değişkenler sıfırlanacaktır.
Bölüm 4
Burada etiket bir nesne ise ent2 değişkeninde ikinci varlık olarak yakalanacaktır. Önek, değiştirici, prv_tok_dep ve prv_tok_text gibi değişkenler yeniden sıfırlanacaktır.
Bölüm 5
Konu ve nesne cümlede yakalandıktan sonra, önceki etiketleri ve bunların bağımlı etiketlerini güncelleyeceğiz.
Bu işlevi bir cümle üzerinde test edin:
get_entities ("filmin 200 patenti vardı")
Çıktı:
Çok iyi, her şey beklendiği gibi görünüyor. Yukarıdaki cümlede "film" konu, "200 patent" konu.
Şimdi bu işlevi, verilerdeki tüm cümlelerin varlık çiftlerini çıkarmak için kullanabilirsiniz:
entity_pairs =
tqdm'de i için (candidate_sentences):
entity_pairs.append (get_entities (i))
Bu varlık çiftleri listesi bir Wikipedia cümlesindeki tüm özne-nesne çiftlerini içerir. Birkaçına bir göz atın:
varlık_ katları
Çıktı:

Bu varlık çiftlerinde "biz", "o", "o" ve benzeri gibi zamirler vardır. Bunları uygun isimler veya isimlerle değiştirmeyi umuyoruz. Belki get_entities () işlevi zamirleri filtrelemek için daha da geliştirilebilir. Şimdi şimdilik statükoyu koruyalım ve ilişki çıkarma kısmına girelim.
İlişki / yüklem çıkarma
Bu, bu makalenin çok ilginç bir parçası olacak. Varsayım, yüklemin aslında cümledeki ana fiil olduğudur.
Örneğin, "Altmış Hollywood müzikali 1929'da piyasaya sürüldü" cümlesinde, fiil aynı zamanda bu cümlede elde edilen üçlü yapının da yüklemi olan "yayınlandı".
Aşağıdaki işlev, cümleden böyle bir yüklemi yakalayabilir. SpaCy kitaplığının kural tabanlı eşleştirme işlevi burada kullanılır:
defget_relation (gönderildi):
doc = nlp (gönderildi)
# Matcher sınıf nesnesi
eşleştirici = Eşleştirici (nlp.vocab)
# kalıbı tanımlayın
desen =
matcher.add ("eşleştirme_1", Yok, kalıp)
eşleşmeler = eşleştirici (belge)
k = len (eşleşir) -1
span = doc
dönüş (span.text)
Fonksiyonda tanımlanan kalıp, cümle içindeki kök kelimeyi veya ana fiili bulmaya çalışır. Kök belirlendikten sonra kalıp, bunun bir edat ("hazırlık") veya işlev kelimesi olup olmadığını kontrol eder. Eğer öyleyse, kök kelimeye ekleyin.
Bu işlev şuna benzer:
get_entities ("John görevi tamamladı")
Çıktı: "tamamlandı
Tüm Wikipedia cümlelerinde ilişkiyi bulmak için aynı yöntemi kullanın:
ilişkiler =
Az önce çıkarılan en yaygın ilişkiye veya yüklemeye bir göz atın:
pd.Series (ilişkiler) .value_counts ()
Çıktı:

Sonuçlar, "A şimdi B'dir" ve "A, B idi (idi)" nin en yaygın ilişkiler olduğunu gösteriyor. Ancak, tüm temayla, yani "filmleri çevreleyen ekosistemle" daha yakından ilgili birçok ilişki vardır. Bazı örnekler "yapan", "yayınlanan", "üretilen", "yazılan" ve benzerleridir.
Bir bilgi grafiği oluşturun
Son olarak, çıkarılan varlıklardan (özne-nesne çiftleri) ve tahminlerden (varlıklar arasındaki ilişkiler) bir bilgi grafiği oluşturulur.
Varlıklar ve tahminlerden oluşan bir veri çerçevesi oluşturun:
# özneyi ayıkla
kaynak =
# nesneyi ayıkla
hedef =
kg_df = pd.DataFrame ({'kaynak': kaynak, 'hedef': hedef, 'kenar': ilişkiler})
Ardından, bu veri çerçevesinden bir ağ oluşturmak için networkx kitaplığını kullanın. Düğümler varlıkları temsil eder ve düğümler arasındaki kenarlar veya bağlantılar düğümler arasındaki ilişkileri temsil eder.
Yönlendirilmiş bir grafik olacak. Başka bir deyişle, herhangi bir bağlı düğüm çifti arasındaki ilişki çift yönlü değildir, sadece bir düğümden diğerine gider. Örneğin, "Can makarna yer":
# bir veri çerçevesinden yönlendirilmiş bir grafik oluşturun
G = nx.from_pandas_edgelist (kg_df, "kaynak", "hedef",
edge_attr = Doğru, create_using = nx.MultiDiGraph ())
Bu ağı tanımlayın:
plt.figure (figsize = (12,12))
pos = nx.spring_layout (G)
nx.draw (G, with_labels = True, node_color = 'skyblue', edge_cmap = plt.cm.Blues, pos = pos)
plt.show ()
Çıktı:

Bu beklediğimiz sonuç değil, ama yine de oldukça muhteşem görünüyor!
Ancak tüm ilişkileri gösteren bir harita oluşturuldu. Bu kadar çok ilişkiyi veya yüklemi bir grafikte görselleştirmeyi hayal etmek zor.
Bu nedenle, yalnızca bazı önemli ilişkileri görselleştirmeniz önerilir ve her seferinde tek bir ilişkiyle ilgilenirim. Şunlardan oluşan bir ilişkiyle başlayın:
G = nx.from_pandas_edgelist (kg_df, "kaynak", "hedef",
edge_attr = Doğru, create_using = nx.MultiDiGraph ())
plt.figure (figsize = (12,12))
pos = nx.spring_layout (G, k = 0.5) # k düğümler arasındaki mesafeyi düzenler
nx.draw (G, with_labels = True, node_color = 'skyblue', node_size = 1500, edge_cmap = plt.cm.Blues, pos = pos)
plt.show ()
Çıktı:

Bu daha net bir harita. Burada ok besteciyi gösteriyor. Örneğin A.R. Rahman ünlü bir müzik bestecisidir.Yukarıdaki grafikte "film müziği", "film müziği" ve "müzik" gibi varlıkları var.
Daha fazla ilişkiye bakın.
Yazı herhangi bir filmde önemli bir rol oynadığı için, "yazma" ilişkisinin grafiğini görselleştirmek istiyorum:
G = nx.from_pandas_edgelist (kg_df, "kaynak", "hedef",
edge_attr = Doğru, create_using = nx.MultiDiGraph ())
plt.figure (figsize = (12,12))
pos = nx.spring_layout (G, k = 0.5)
nx.draw (G, with_labels = True, node_color = 'skyblue', node_size = 1500, edge_cmap = plt.cm.Blues, pos = pos)
plt.show ()
Çıktı:

harika! Bu bilgi grafiği bize olağanüstü bilgiler veriyor. Javed Akhtar, Krishna Chaitanya ve Jaideep Sahni'nin hepsi tanınmış söz yazarları Bu harita bu ilişkiyi iyi bir şekilde yansıtıyor.
Başka bir önemli yüklemin bilgi grafiğine bir göz atın, yani "sürüm (yayınlanmıştır)":
G = nx.from_pandas_edgelist (kg_df, "kaynak", "hedef",
edge_attr = Doğru, create_using = nx.MultiDiGraph ())
plt.figure (figsize = (12,12))
pos = nx.spring_layout (G, k = 0.5)
nx.draw (G, with_labels = True, node_color = 'skyblue', node_size = 1500, edge_cmap = plt.cm.Blues, pos = pos)
plt.show ()
Çıktı:

Bu haritada pek çok ilginç bilgi görebiliriz. Örneğin, şu ilişki: "1980'lerde yayınlanan çeşitli aksiyon korku filmleri" ve "4844 ekranda gösterilen dövüş filmleri". Bunlar gerçekler ve bu harita bize bu gerçeklerin metinden gerçekten çıkarılabileceğini söylüyor. Bu harika!
Sonuç
Bu makalede, belirli bir metinden üçlü formda bilgi almayı ve bunu bir bilgi grafiği oluşturmak için kullanmayı öğrendik.
Ancak, yalnızca tam olarak iki varlığa sahip cümleleri kullanırız. Öyle olsa bile, çok fazla bilgi içeren bir bilgi grafiği oluşturulabilir, bu nedenle potansiyelini hayal edin!
Herkesi bu alandaki bilgi çıkarımını keşfetmeye ve daha karmaşık ilişki çıkarımlarını öğrenmeye teşvik ediyorum. Herhangi bir sorunuz varsa veya düşüncelerinizi paylaşmak istiyorsanız, lütfen mesaj bırakın.

Yorum Beğen Takip Et
Yapay zeka öğrenme ve geliştirmenin kuru mallarını paylaşalım
Yeniden yazdırıyorsanız, lütfen arka planda bir mesaj bırakın ve yeniden yazdırma şartnamelerine uyun