İnsansız Sürüşte Evrişimli Sinir Ağı (CNN) Uygulaması
Bilgisayarla görme alanı olarak, insansız sürüşün algı kısmı kaçınılmaz olarak CNN'in rol oynadığı aşama haline geliyor. Bu makale, insansız sürüş teknolojisi serisinin sekizinci makalesi, insansız sürüş 3D algılama ve nesne tespitinde CNN (evrişimli sinir ağı) uygulamasına derinlemesine giriş.
CNN'e Giriş
Evrişimli Sinir Ağı (CNN), ses, görüntü ve video gibi sürekli değerli giriş sinyallerinde kullanım için uygun derin bir sinir ağıdır. Tarihi 1968'e kadar izlenebilir. Hubel ve Wiesel, hayvan görsel korteks hücrelerindeki girdi modellerinin yön seçiciliğini ve çeviri değişmezliğini keşfettiler ve bu çalışma onlara bir Nobel Ödülü kazandırdı. Zaman 1980'lere ilerliyor. Sinir ağı araştırmalarının derinleşmesiyle birlikte araştırmacılar, görüntü girdisindeki evrişim işleminin yerel alıcı alandaki girdiyi alan biyolojik vizyondaki nöronlara benzer olduğunu buldular, bu yüzden onu sinir ağına ekleyin. Üst kıvrım işlemi doğal bir şey haline geldi. Normal derin sinir ağı (DNN) ile karşılaştırıldığında, mevcut CNN özellikleri temel olarak şunları içerir:
-
Yüksek seviyeli bir nöron, yalnızca belirli düşük seviyeli nöronlardan girdi kabul eder.Bu düşük seviyeli nöronlar, genellikle bir dikdörtgen olmak üzere iki boyutlu bir uzayda bir mahallede bulunur. Bu özellik, biyolojik sinir ağlarındaki alıcı alan kavramından esinlenmiştir.
-
Aynı katmandaki farklı nöronların girdi ağırlıkları paylaşılır.Bu özellik, CNN modelinin parametre sayısını büyük ölçüde azaltmakla kalmayıp aynı zamanda eğitimi hızlandıran görsel girdideki çeviri değişmezliğini kullanmak olarak düşünülebilir.
CNN, özellikle sinir ağlarının yapısındaki görsel girdinin özellikleri için tasarlandığından, bilgisayarla görme alanındaki derin sinir ağları için en iyi seçimdir. 2012'de CNN, ImageNet'in dünya rekorunu kırdıktan sonra, görüntü tanıma rekabeti, bilgisayar görüşü alanı dünyayı sarsan değişikliklere uğradı. Bilgisayarla görme alanı olarak insansız sürüşün algı kısmı kaçınılmaz olarak CNN'in rol oynadığı aşama olur.
Sürücüsüz dürbün 3D algısı
İnsansız araç algısında, çevredeki ortamın 3 boyutlu modellenmesi en önemli şeydir. Lidar, yüksek hassasiyetli 3B nokta bulutları sağlayabilir, ancak yoğun 3B bilgi, kameraların yardımını gerektirir. İnsanlar üç boyutlu bir görsel deneyim elde etmek için iki göz kullanır ve aynı ilke, dürbün kameralarının 3D bilgi sağlamasına izin verir. İki kamera arasındaki mesafenin B olduğunu, uzaydaki bir P noktası ile iki kameranın oluşturduğu görüntü arasındaki farkın d ve kameranın odak uzaklığının f olduğunu varsayarsak, P noktasından kameraya olan mesafeyi şu şekilde hesaplayabiliriz:
Bu nedenle, z'yi elde etmek için 3B ortamı algılamak için, dürbün kameranın I_l ve I_r iki görüntüsünden d elde etmek gerekir. Olağan yöntem yerel görüntü eşleştirmeye dayanır:
Tek bir pikselin değeri kararsız olabileceğinden, çevreleyen pikselleri ve pürüzsüzlük hipotezini kullanmak gerekir d (x, y) d (x + , y + ) (hem hem de 'nin küçük olduğunu varsayarak), bu nedenle d değişimini çözün Bir küçültme problemi haline gelin:
Bu, optik akış görevinin çözmek istediği soruna çok benzer, ancak (Il, Ir), (It, It + 1) olur, bu nedenle aşağıda tanıtılacak algoritmalar her ikisi için de geçerlidir.
MC-CNN
Şimdi Eşleştirme Maliyetli CNN algoritmasına bir göz atalım.Bu algoritma, yukarıdaki denklemin sağ tarafındaki eşleştirme maliyetini hesaplamak için bir CNN kullanır.MC-CNN'nin ağ yapısı Şekil 1'de gösterilmiştir.

Şekil 1 MC-CNN ağ yapısı
Bu ağın girdisi, iki resimden oluşan küçük bir parçadır ve çıktı, iki parçanın eşleşmeme olasılığıdır, bu da bir maliyet işlevine eşdeğerdir.İki eşleştiğinde, 0'dır ve eşleşmediğinde mümkün olan maksimum 1'dir. Belirli bir resim konumu için olası d değerlerini araştırarak ve en küçük CNN çıktısını bularak, bu kısmi ofset tahmini elde edilir. MC-CNN algoritması daha sonra aşağıdaki son işlemeyi gerçekleştirir:
-
Çapraz tabanlı maliyet toplama: Temel fikir, tahminin kararlılığını ve doğruluğunu iyileştirmek için benzer değerlerle bitişik piksellerin ofsetlerinin ortalamasını almaktır.
-
Yarı küresel eşleme: Temel fikir, bitişik noktaların çevirisinin benzer olması, yumuşatma kısıtlamaları eklenmesi ve ofsetin optimal değerini bulması gerektiğidir.
-
Enterpolasyon ve resim sınırı düzeltmesi: doğruluğu artırın ve boşlukları doldurun.
Nihai algoritma etkisi aşağıdaki gibidir:

Şekil 2 MC-CNN'nin algoritma etkisi
MC-CNN, CNN kullanmasına rağmen, eşleşme derecesinin hesaplanmasıyla sınırlıdır.İlerleyen aşamada yumuşatma kısıtlamaları ve optimizasyon önemlidir.CNN'yi tek adımda kullanmak mümkün müdür? FlowNet tam da bunu yapar.
FlowNet
Uçtan uca bir model yapısı elde etmek için, özellik çıkarma, eşleştirme puanlama ve global optimizasyon gibi özellikleri uygulamak için CNN kullanmak gerekir. FlowNet, kodlayıcı-kod çözücü çerçevesini benimser ve bir CNN'yi iki kısma ayırır: daralma ve genişleme.

Şekil 3 Kodlayıcı-kod çözücü çerçevesi
Daraltma bölümünde, FlowNet iki olası model yapısı önerir:
-
FlowNetSimple: İki resmi yığınlayın ve bunları bir "doğrusal" CNN'ye girin ve çıktı, her pikselin ofsetidir. Bu modelin zayıflığı, hesaplama açısından pahalı olması ve her pikselin çıktısının bağımsız olması nedeniyle global optimizasyon yöntemlerini dikkate alamamasıdır.
-
FlowNetCorr: Önce iki resmin özelliklerini ayrı ayrı çıkarın, ardından iki dalı bir korelasyon katmanı aracılığıyla birleştirin ve aşağıdaki evrişimli katman işlemine devam edin. Bu korelasyon katmanının hesaplanması, öğrenilen özellik ağırlıklarına sahip olmaması dışında, evrişim katmanınınkine benzer, ancak iki daldan elde edilen gizli katman çıktısı çarpılır ve toplanır.

Şekil 4 FlowNetSimple ve FlowNetCorr
FlowNet ağının küçülen kısmı yalnızca CNN hesaplamalarının miktarını azaltmakla kalmaz, aynı zamanda görüntü düzleminde bilgi toplama işlevi görür ve bu da çözünürlükte bir azalmaya yol açar. Bu nedenle "yukarı evrişim", FlowNet ağının genişleme kısmındaki çözünürlüğü artırmak için kullanılır.Burada sadece önceki katmanın düşük çözünürlüklü çıktısının değil, aynı zamanda Şekil 5'te gösterildiği gibi ağ kasılma bölümünde aynı ölçeğin gizli katman çıktısının da kullanıldığını unutmayın.
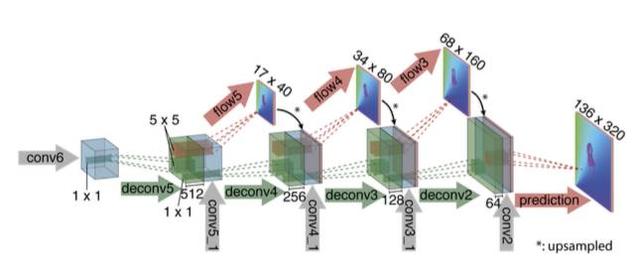
Şekil 5 FlowNet ağ genişletmesi
FlowNet algoritması, genel kamuya açık veri setlerinde iyi sonuçlar elde etti ve bunun çok hızlı olduğunu belirtmekte fayda var.
İnsansız nesne algılama
Nesne algılama teknolojisi, sürücüsüz algılamanın önemli bir parçasıdır. 2012'de görüntü sınıflandırmada CNN'nin atılımından bu yana, nesne algılama doğal olarak CNN uygulamasının bir sonraki hedefidir.CNN nesne algılama algoritmaları sonsuza dek ortaya çıkmaktadır. Tanıtmak için birkaç temsili algoritma seçiyoruz.
Daha hızlı R-CNN
CNN nesne tanıma alanında popüler hale gelmeden önce, olağan yaklaşım DPM (Deformable Parts Model) gibi çözümlere benzer: görüntünün uzamsal gradyanına dayalı HOG özellikleri gibi bir şablon olarak görüntüdeki yerel özelliklerin bir kombinasyonunu çıkarın; deformasyon, tıkanma ile başa çıkabilmek için Değişiklikleri beklerken, "elastik" bir yapı oluşturuyoruz, bu "sert" parçaları birleştiriyoruz ve sonunda nesnenin görünüp görünmediğini belirlemek için bir sınıflandırıcı ekliyoruz. Bu tür algoritmalar genellikle daha karmaşıktır, çok fazla deneyim gerektirir ve iyileştirilmesi ve optimize edilmesi daha zordur. CNN'in gelişi her şeyi değiştirdi.
R-CNN algoritma serisi, nesne tanıma problemini aşağıdakilere ayıran iki aşamalı bir algoritmadır:
-
Nesnenin olabileceği alanın seçimi: bir resim girin, içindeki nesnenin konumu ve boyutu için çok fazla olasılık olduğundan, onları bulmak için etkili bir yönteme ihtiyacımız var.Buradaki odak, alan sayısının belirli bir üst sınırı altında mümkün olduğunca çok denemektir. Tüm nesneleri bulmak için anahtar gösterge, geri çağırma hızıdır.
-
Aday alanın tanınması: Resimde dikdörtgen bir alan verildiğinde, içindeki nesneyi tanımlayın ve alan boyutunu ve en boy oranını düzeltin ve nesne kategorisini ve daha "daha dar" bir dikdörtgen çerçeve oluşturun. Buradaki odak noktası, tanımanın doğruluğu üzerinedir.
Algoritmanın genel mimarisini anladıktan sonra, algoritmanın özel uygulamasına bir göz atalım. Burada esas olarak R-CNN algoritma serisinin en son sürümünü açıklıyoruz: RPN (Bölge Teklif Ağı) ve Hızlı için yukarıdaki iki adıma karşılık gelen Daha Hızlı R-CNN R-CNN bundan sonra ayrı olarak tanıtılacaktır.
RPN
Nesnenin aday olabileceği bölgeye diyoruz ve RPN'nin (Bölge Teklif Ağı) işlevi, en verimli şekilde bir aday listesi oluşturmaktır. Şekil 6'da gösterildiği gibi, RPN seçimi CNN'ye dayalıdır Görüntü, çoklu (4 gibi) evrişimli katmanlardan çıkarılır Son evrişimli katman tarafından çıkan özellik haritası çıktısı, 3x3 döner pencere kullanılarak 256 veya 512 boyutuna bağlanır. Tamamen bağlı gizli katman, nihayet, biri nesne kategorisini çıkarırken diğeri nesnenin konumunu ve boyutunu çıkaran iki tam bağlantılı katmana ayrılır. Farklı nesne boyutları ve en boy oranlarını kullanabilmek için, her konumda toplam 9 tür için üç ölçek (128x128, 256x256, 512x512) ve üç en boy oranını (1: 1, 1: 2, 2: 1) düşünün. kombinasyon. Böyle bir 1000x600 resim (1000/16) × (600/16) × 9 20.000 pozisyon, boyut ve en-boy oranı kombinasyonunu dikkate alır.CNN hesaplamalarının kullanılması nedeniyle, bu adım fazla zaman almaz. Son olarak, fazlalık aday bölgeler, uzamsal örtüşme derecesine göre çıkarılır ve bir resim, yaklaşık 2000 olası nesne bölgesini elde edebilir.

Şekil 6 Bölge Teklif Ağı
Hızlı R-CNN
Aday bölge sınıflandırma aşamasında, Şekil 7'nin sağ kısmında gösterildiği gibi, tamamen bağlı bir sinir ağı kullanıyoruz:
Soldaki özellik çıkarma bölümü, CNN hesaplama sonuçlarını RPN'de yeniden kullanabilir, bu da hesaplama süresinden büyük ölçüde tasarruf sağlar ve saniyede 5-17 kare hıza ulaşabilir.

Şekil 7 Hızlı R-CNN
MS-CNN
Daha Hızlı R-CNN algoritması ünlü olmasına rağmen, insansız sürüş gibi nesnelerin ölçeğinin büyük ölçüde değiştiği sahnelerde iyileştirme için hala yer vardır.Çok ölçekli CNN (MS-CNN) bu sorunu çözme girişimidir. CNN'nin hiyerarşik yapısı, havuz katmanının varlığından dolayı doğal olarak farklı ölçeklerle karşılık gelen bir ilişki oluşturur. Öyleyse neden nesnelerin algılanmasını farklı CNN katmanlarına koymuyorsunuz? MS-CNN'nin fikri budur.
Nesne aday bölgelerini seçme aşamasında, MS-CNN, Şekil 8'deki ağ yapısını kullanır. CNN ağındaki evrişimli katman, büyük bir ağacın "omurgası" olarak kabul edilirse, o zaman üç conv3, conv4 ve conv5'te olduğunu görürüz. Evrişim katmanından sonra, ağ "dal" büyümüştür, her "dal" belirli bir ölçek aralığından sorumlu olan bir algılama katmanına bağlanmıştır, böylece birden fazla "dal" birlikte daha geniş bir nesne ölçeğini kapsayabilir. , Hedefimize ulaşmak için.
Aday bölge tanıma aşamasında, önceki aşamadaki birden çok algılama katmanının çıktı özelliği haritalarının bir alt ağa girilmesine izin verdik. İşte birkaç önemli ayrıntı:

Şekil 8 MS-CNN
-
İlk katman, özellik haritasının çözünürlüğünü iyileştirmeyi ve özellikle küçük ölçekli nesneler için nesne algılamanın doğruluğunu sağlamayı amaçlayan "Ters Evrişim" dir.
-
Ters Evrişim'den sonra, nesne özelliklerini (yeşil kutu) çıkarırken, aynı zamanda nesnenin (mavi kutu) etrafındaki bilgileri de çıkarır. Bu "bağlam" bilgisi açıkça tanıma doğruluğunu iyileştirmeye yardımcı olur.
Genel olarak, Daha Hızlı R-CNN ile karşılaştırıldığında, MS-CNN, özellikle KITTI veri setindeki yayalar ve bisikletler gibi nesnelerin ölçeği değiştiğinde, büyük ölçüde geliştirilmiş tanıma doğruluğu avantajına sahiptir. Ancak daha hızlı R-CNN hala hız avantajına sahiptir.

Şekil 9 MS-CNN
SSD
Daha Hızlı R-CNN'nin hızı önceki R-CNN'ye göre büyük ölçüde iyileştirilmiş olsa da, yine de gerçek zamanlı gereksinimleri karşılamıyor. Single Shot Detector (SSD), gerçek zamanlı çalışabilen ve daha iyi doğruluğa sahip bir algoritmadır ve son zamanlarda oldukça popüler olmuştur. SSD, nesnenin konumunu, boyutunu ve en-boy oranını ayırarak, çeşitli olası nesne koşullarını verimli bir şekilde hesaplamak için CNN kullanarak ve böylece nesneleri yüksek hızda algılama amacına ulaşarak kayan pencere fikrini takip eder.

Şekil 10 Tek Atış Dedektörü
Şekil 10'da gösterildiği gibi SSD, alt seviye görüntü özelliği çıkarımı yapmak için VGG-16 ağını kullanır.Aday bölgelerin oluşturulması, görüntü ölçeklendirilmesi ve özellik haritası örnekleme adımlarını iptal ederek tek adımda nesne konumu ve sınıflandırması belirlenir ve yüksek hızlı nesneler elde edilir. Algılama algoritması.
SSD, VGG ağı temelinde kademeli olarak daha küçük bir evrişimli katman ekler.Farklı ölçeklerdeki bu evrişimli katmanlar, nesnelerin konum ofsetini ve sınıflandırmasını belirlemek için 3x3 evrişimli çekirdek kullanır, böylece SSD farklı boyutları algılayabilir Nesneler.
sonuç olarak
Bilgisayarla görme alanı olarak, insansız sürüşün algı kısmı kaçınılmaz olarak CNN'in rol oynadığı aşama haline geliyor. CNN'nin insansız sürüşte uygulaması temel olarak 3B algılama ve nesne algılamayı içerir. 3B algıda kullanılan ağlar arasında MC-CNN ve FlowNet bulunur ve nesne algılamada kullanılan ağlar, Daha Hızlı R-CNN, MSCNN ve SSD'yi içerir. Bu makale, çeşitli ağların avantajlarını ve dezavantajlarını ayrıntılı olarak tanıtmaktadır ve bir ağ seçerken size yardımcı olacağını umuyorum.
Yazar hakkında:
Wu Shuang, eski Baidu Araştırma Enstitüsü'nün Silikon Vadisi Yapay Zeka Laboratuvarı'nda kıdemli araştırma bilimcisi ve ABD Ar-Ge Merkezi'nin kıdemli mimarıdır. Araştırma alanları arasında bilgisayar ve biyolojik vizyon, İnternet reklamı algoritmaları ve konuşma tanıma yer alır ve NIPS gibi uluslararası konferanslarda makaleler yayınlanmıştır.
Wang Jiang, Baidu Araştırma Enstitüsü'nün Silikon Vadisi Derin Öğrenme Laboratuvarında kıdemli bir araştırma bilimcisi. Microsoft ve Google Araştırma Enstitüsü'nde stajyerlik yapmış, çalışmaları görüntü alma sistemlerinde, yüz tanıma sistemlerinde ve Google ile Baidu'nun büyük ölçekli derin öğreniminde yaygın olarak kullanılmıştır.
PerceptIn'in kurucu ortağı Liu Shaoshan. California Üniversitesi, Irvine'den Bilgisayar Bilimi alanında doktora, akıllı algılama hesaplama, sistem yazılımı, mimari ve heterojen hesaplama araştırma alanı. Now PerceptIn, esas olarak SLAM teknolojisine ve bunun akıllı donanıma uygulanması ve optimizasyonuna odaklanıyor.
[Orijinali okuyun] Sürücüsüz teknoloji ile ilgili makale dizisini edinin:
-
İnsansız Sürüş Teknolojisinde Optik Radar (LiDAR) Uygulaması
-
ROS tabanlı insansız sürüş sistemi
-
Bilgisayarla görmeye dayalı insansız sürüş algılama sistemi
-
Spark ve ROS'a dayalı dağıtılmış insansız sürüş simülasyon platformu
-
İnsansız sürüşte GPS ve atalet sensörlerinin uygulanması
-
Sürücüsüz sürüşte pekiştirmeli öğrenme uygulaması
-
İnsansız sürüşte CNN uygulaması
Daha heyecan verici makaleler için, 2017 "Programcı" a abone olmak için lütfen aşağıdaki QR kodunu tarayın (İOS, Android ve basılı sürüm dahil)