İkinci turda en güçlü beyin "insan-makine savaşı" nın çekildiği Wu Enda, arkasındaki teknik ilkeleri ayrıntılı olarak açıklıyor
Xiaodu, insan-makine savaşında yüz tanıma düellosunun son turunda yüz tanıma konusunda iyi olmayan Wang Feng ile yüz yüze gelirse, oyunun anlamı tehlikeye atılırsa, o zaman ses tanımada ikinci tur insan-makine savaşı dün yapıldı. Sonunda sadece bir çekiliş olmasına rağmen, AI topluluğu için daha büyük bir öneme sahip gibi görünüyordu.
Bunun iki nedeni vardır: 1. En iyi rakipler olarak kabul edilir; 2. Sektör tarafından tanınan zorlu rekabet içeriği .
Rakiplere göre, bu kez Baidu Xiaodu'ya karşı, Şeref Salonu tarafından ses ayrımcılığındaki en iyi oyuncu olarak tanınan Sun Yiting'dir.Sesin ayrıntılarını ayırt etme yeteneği Şeref Salonunda benzersizdir. Sutopunu zeminde 0'dan 70 metreye kadar geçebilir. , Düştüğünde su topunun yüksekliğini doğru bir şekilde ayırt etmek. Bu, 70 metre uzunluğundaki bir ipte herhangi bir pozisyonu çekmeye eşdeğerdir ve ipin konumunu adım adım doğru bir şekilde belirleyebilir ki bu daha da zor.
Yarışmanın içeriğinde, mevcut ses izi tanıma alanında tanınan birkaç büyük zorluk var. Önce oyunun kurallarına bir göz atalım:
Konuk Jay Chou, 21 profesyonel koro üyesinden üç şarkıcı seçer ve onlarla canlı bir görüşme yapar. Çağrının kaydı parçalara ayrılır ve adam ve makine, bu "az önce konuşulan" peri masalı fragmanlarına dayanan sonraki koro performansında bir kez birlikte performans gösterir. Bu üç şarkıcıyı bulun.
Oyunun kurallarını okuduktan sonra, profesyoneller bile mevcut ses izi tanıma teknolojisinin daha zor olduğunu düşündü. Xtreme'in kurucu ortağı ve yapay zeka uzmanı Ma Ji, Leifeng.com'a şunları söyledi:
Ritim, ritim, temel frekans, hız vb. Gibi ses izi tanımayı etkileyen ses karakteristik parametreleri konuşurken ve şarkı söylerken tamamen farklıdır. Xiaodu için, eğitim modellemesini öğrenmek için kullanılan ses verileri ile son tanıma için ses verileri arasındaki biyolojik özelliklerde çok fazla fark olması yanlış yargılamaya yol açacaktır.
Düşük kaliteli ses verileri için, Xiaodu'nun şarkı söyleyen verileri güçlü gürültü paraziti altında tanıması gerçekten zordur.
Ses izi tanıma teknolojisine ilişkin önceki bilgilere dayanarak, Leifeng.com, Baidu Xiaodu'nun bu sefer ses izi tanıma alanında en az üç sorunla karşılaştığını buldu:
1. Normal konuşmayı toplayın, ancak şarkı söylemeyi ayırt etmeniz gerekir
Ses izi tanımanın temel ilkesinin aslında özellik değeri karşılaştırması olduğunu biliyoruz.Özellik değeri, bir özellik kitaplığı oluşturmak için önceden toplanan seslerden çıkarılır ve ardından tanımlanması gereken ses, özellik kitaplığındaki verilerle karşılaştırılır. Sorun, profesyonel bir koronun şarkı sesi ile normal konuşmanın ses özellikleri arasında açık bir fark olmasıdır.
Aslında profesyonel korolar için şarkı söylerken seslendirme kısmı geriye doğru, normal konuşmada seslendirme pozisyonu ileriye doğru, fiziksel olarak seslendirme pozisyonu farklı. Bu, makine öğrenimi algoritmalarının, öğrenme sırasında karşılaşılmayan örnekleri doğru bir şekilde işleyebilen güçlü bir "genelleme yeteneğine" sahip olmasını gerektirir.
Xiaodu başarılı bir şekilde ayırt etmek istiyorsa, aynı kişi arasındaki farkı daha az veriyle (yalnızca birkaç kelime) ayırt etme yeteneğine sahip olması gerekir.
2. Koro seslendirmedeki fark çok küçüktür ve birbirini etkiler
Şu anda, ses izi tanıma teknolojisi ile tam olarak çözülemeyen önemli bir sorun, çevresel gürültü girişimiyle mücadele etmek ve aynı anda birden fazla kişinin konuşması durumunda sesleri tanımaktır. Olay yerindeki ortam gürültüsüne ek olarak, her koro üyesi ses verirken diğer bazı insanların seslerine az çok karışacaktır.

Ek olarak, ses izi tanımada yüz tanımaya benzer bir "ikiz problem" vardır - sesin yakınsama etkisi . Konuk Jay Chou'nun koroda seçtiği kişilerin ses farkı çok küçüktür ve kantatın kendisi düzgün ve uyumlu bir sese ihtiyaç duyar, bu da tanımlama zorluğunu daha da artırır - herkes koroyu daha iyi hale getirmek için telaffuz alışkanlıklarını kasıtlı olarak değiştirecektir. İyi sonuçlar.
3. Ses klibi eksik ve çok kısa
İnsanlar telaffuz ettiğinde, ortak eklemlenme etkisi vardır, yani bir cümle öncesi ve sonrası bağlanan konuşma her zaman birbirini etkiler ve bu özellikler makine tarafından veriye dayalı bir şekilde modele öğrenilir.
Bu yarışmada ses, sürekli olmayan bir sinyal olarak özel olarak işlenir ve bazı kişilerin telaffuz alışkanlıklarının zarar görmesi muhtemeldir, bu da Xiaodu robotunun orijinal konuşmacıyı çıkarmasını ve temsil etmesini zorlaştırır.
Makine öğrenimi algoritmaları için, konuşma süresi ne kadar uzun olursa, o kadar etkili özellikler yakalanacaktır.Konuşma çok kısaysa, tanıma oranı büyük ölçüde düşecektir.Bu, ses izi tanıma alanındaki kısa vadeli konuşma ses izi doğrulama problemidir. Programa müdahale edildikten sonra kaydedilen ses klibinde, tüm ses 10 kelimeyi geçmez ve etki süresi 3 saniyeden azdır. Bu, Xiaodu'nun algoritmasına büyük zorluk getiriyor - muhbirlerin kısa, aralıklı sesinden karakterize edilebilen kişisel bilgileri daha etkili bir şekilde çıkarması gerekiyor.

Bu makale şimdilik insanlar için bu koşulların zorluğunu tartışmayacaktır, çünkü Sun Yiting'in ses tanıma yeteneği edinilmiş eğitim yoluyla kazanılmamıştır ve yetenek baskın faktördür. Tek başına makine için, bu aynı zamanda eşi görülmemiş bir zorluktur ve Baidu'nun konuşma tanıma teknolojisi direktörü Gao Liang'ı defalarca dudak ısırma ve yerinde kaşlarını çatmaktan muzdarip kılar.

Xiaodu'nun iki ayrımcılık hatasının arkasında ne oldu?
Sonunda, üç halkanın iki tarafı 1: 1 çekilişle sonuçlandı. İnsan oyuncu Sun Yiting de ikinci şarkıcıyı başarılı bir şekilde tanımladı ve Xiaodu yalnızca üçüncü şarkıcıyı başarıyla tanımladı. İlginç bir şekilde, hem insan hem de makine hataları ilk kez ayırt ettiğinde, yanlış cevaplar beklenmedik şekilde tutarlıydı. Xiaodu ilk iki başarısızlık ve bir başarıda neler yaşadı? Baidu'nun yapay zeka teknolojisi araştırmalarından sorumlu çekirdek uzman, Leifeng.com'un gizemini ortaya çıkardı.
Wu Enda, " Bu insan-makine savaşından önce, modelimizi eğitmek için 20.000 kişinin verilerini ve 5.000 saatten fazla eğitim süresini kullandık. "

[Wu Enda ve Lin Yunqing, gösterinin arkasındaki ilkeleri açıklıyor]
İki model arasındaki "farklılıklar"
Wu Enda, bu yarışmada Xiaodu'nun ses tanıma gerçekleştirmek için ses izi tanıma alanında iki set klasik algoritma kullandığını, birinin DNN ivektör sistemine dayandığını ve diğerinin uçtan uca derin sinir ağına dayalı hoparlör özellikleri olduğunu söyledi. Ayıkla. Aynı anda iki sistemin kullanılması, hoparlörün özelliklerini farklı açılardan çıkarabilir ve sonunda iki modeli birleştirerek sistemin sağlamlığını etkili bir şekilde artırabilir (Sağlamlık).
Aslında, her iki modelin de üç tanımlamada iki kez doğru şekilde tanımlandığını, ancak iki modelin sonuçları bir araya getirildiğinde bunun yerine yalnızca doğru olanın nihayet belirlendiğini söyledi. Ana neden, tanımlamanın zor olması ve ilk iki turda iki grup algoritma modelinin "sapması" olmasıdır.
Wu Enda, ilk modelin bir veya üç tur için doğru değerlendirildiğini, ikinci modelin iki veya üç tur için doğru değerlendirildiğini söyledi.İki modelde "sapma" olduğunda hangi algoritmanın daha "güvenli" olduğunu söyledi. Kimin cevabı. Bu, insanların matematik sorularını alırken iki tür problem çözme fikri kullandıkları ve farklı yanıtları çözdükleri zamana benzer.Kısa zaman nedeniyle, yalnızca "nispeten güvenilir" bir yanıt seçebilirler.

Her iki modelin de haklı olduğunu itiraf etti, ancak nihai sonucun sadece bir doğru olduğunu, bu gerçekten biraz "şanssız" (şanssız) ve belli bir olasılık sorunu var. Ancak optimizasyon için yer görüyor.Gelecekte, kapsamlı hesaplamalar için daha fazla sayıda model kullanmak gibi daha iyi yöntemler kullanmayı umuyorum.
Uyarlanabilir ayarlama yoluyla şarkı söylemeyi tanıma
Baidu Xiaodu'nun konuşma sesiyle şarkı söylemeyi nasıl "anladığı" birçok insanı şaşırttı. Baidu'nun Derin Öğrenme Laboratuvarı (IDL) direktörü Lei Feng.com'a şunları söyledi:
İlk adımda, temel eğitim için büyük miktarda standartlaştırılmış veri kullanacağız ve temel bir model alacağız. Bu özel bir işlem değil. Örneğin, 20.000 kişinin ses verilerini aldığımızda, hepsi sesli arama motorundan çıkarılır. Bunlar aracılığıyla Data çok iyi bir model yetiştirebiliriz.
Bu temelde rap şarkı söyleme gibi özel durumlarda 1000 kişinin sesleri gibi küçük bir miktar topluyoruz. Yarışmadan önce, şarkı içeriği olduğunu biliyorduk, ancak hangi şarkıyı söyleyeceğimizi bilmiyorduk, bu yüzden modeli eğitmek için bazı şarkılar topladık, böylece model konuşma ve şarkı söyleme arasındaki ses farkını daha doğru tanıyabilsin.
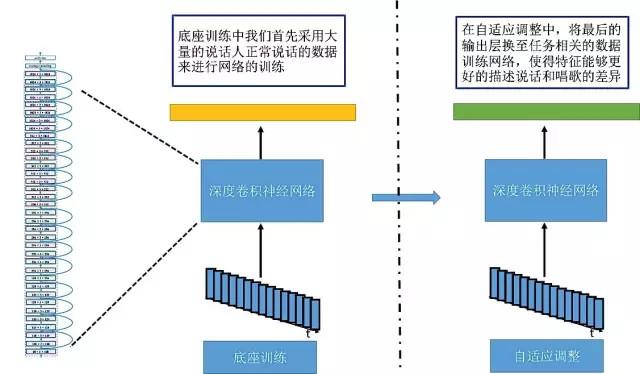
[DNN-ivector algoritması şarkı söylemeyi nasıl ayırt eder]
Aynı anda konuşan gürültü ve birden fazla kişi nasıl çözülür?
Arka plan gürültüsü sorununun nasıl çözüleceğiyle ilgili olarak Wu Enda, modelin eğitimi sırasında genellikle bazı arka plan gürültü verilerinin kasıtlı olarak eklendiğini ve iki ses parçasını üst üste bindirerek yeni bir gürültülü konuşma elde edebileceğimizi söyledi. Derin sinir ağımız eğitildiğinde, arka plan gürültüsü sorunu bir dereceye kadar çözülebilir.
Ortamın gürültü tabanı ile karşılaştırıldığında, ses izi tanımanın daha zor problemi, aynı anda birden fazla kişinin konuşmasıdır. İki (daha fazla) kişi aynı anda konuştuğunda ve seslerinin tını ve frekansı benzer olduğunda, makinenin hangisini duymak istediğini ve hangisinin gürültü olduğunu ayırt etmesi zordur. Yıllar süren evrimin ardından insan kulağı, istenmeyen sesleri otomatik olarak engelleyebilen "kokteyl partisi efekti" adı verilen büyülü bir yetenek kazanmıştır.
Baidu'nun konuşma tanıma teknolojisi başkanı Li Xiangang, yanıt olarak,
Mevcut derin öğrenme veya ilgili teknolojiler söz konusu olduğunda, aynı mikrofon tarafından yakalanan aynı anda birden fazla kişinin verilerini işlemek gerçekten zordur ve hala zorlanmaya değer birçok yer vardır. Ancak gerçek uygulama senaryoları açısından, bu sorunu daha iyi çözebilecek başka yöntemler de vardır, örneğin gelişmiş konumlandırma Bir kişinin ses kaynağını bulmak için iki kulağı olması gibi, pratik uygulamalarda hedef ses kaynağını geliştirmek için birden fazla mikrofon kullanabiliriz. Ses, böylece hedef ses kaynağını ve çevredeki gürültüyü daha iyi ayırt edebilirsiniz.
Wu Enda Leifeng.com'a verdiği demeçte, Baidunun kısa süre önce CESte piyasaya sürdüğü Little Fish robotunun, çok kişili konuşma sorununu bir dereceye kadar çözebilecek 2 mikrofonla donatıldığını ve gelecekte 4, 7 ve hatta 4 mikrofon kullanılabileceğini söyledi. Sorunla başa çıkmak için daha fazla mikrofon.
Buradan, 21 şarkıcı koro şeklinde seslendirmesine rağmen, program grubunun herkesi "çok planlı bir şekilde" yüksek yönlü bir türle donattığını, bu da karşılıklı ses paraziti sorununu olabildiğince önlemek için bulduk. .

Yarışmanın sonuçlarına bakılırsa, Xiaodu ilk iki seferin kim olduğunu belirleyemese de ve program grubundaki bazı "tavuk hırsızları", tanımlamanın zorluğunu vurgulamak için bir koro adını kullandı, çünkü aslında her oyuncu ayrı bir mikrofonla donatıldı, Xiaodu Elde edilen ses verileri neredeyse tek başına kaydetmeyle aynı olabilir. Ancak genel olarak, çeşitli faktörlerin neden olduğu ses izi tanımanın zorluğu sektördeki herkes için açıktır ve sözde teknik ideallerin yanı sıra, Baidu'nun beyninin "kasları gösterme" hedefine ulaşılmıştır.
Yapay zekanın gelişmesiyle birlikte bu tür "insan-makine savaşları" ileride daha sık sahnelenebilir.İnsan zekası yeteneğinin sınırını kısa sürede yükseltmek neredeyse zor, ancak makine ilerlemesi için hala çok yer var. İnsanlar insan-makine savaşına bakarken sadece "kimin kimi yeneceğini" önemserse, bir gün insan-makine savaşı anlamını yitirecektir.
O yıl ilk buharlı tren icat edildiğinde, bazı insanlar trenin vagondaki bir vagon kadar hızlı olmadığı ve treni alay edenler nihayet tarih tarafından alay konusu oldu. Makine kazandığı için hüsrana uğramamıza gerek yok ve insanların zaferi için tezahürat yapmamıza gerek yok. Araçlar uzayda insanların bir uzantısı haline geldi. Gelecekte, yapay zeka da insan duyularının bir uzantısı ve insan-makine savaşının anlamı olarak görülmelidir. İnsanların ve makinelerin ayrımında yatmıyor. Daha büyük önem, insanların insan zekası ve makinelerinin mevcut sınırlarını doğru bir şekilde tanımasını sağlamaktır. Ancak bu şekilde AI endüstrisinin olumlu gelişimini teşvik edebilir.
Sonraki Cuma, tekrar çıkan "Kardeş Su" Wang Yuheng ve Xiaodu Robot'un hala görüntü tanımada rekabet ettikleri söylendi. Üst düzey gözlem ve beyin gücü ve dünya standartlarında yapay zeka ile insanlar arasında ne tür kıvılcımlar çarpışacak? Görülmeye devam ediyor. Leifeng.com size raporlar ve teknik analizler sunmaya devam edecek ve daha fazla insanın yalnızca kazanmaya veya kaybetmeye odaklanmayacağını umacaktır.
