"Doom" oyununda eğitim Ajanı olan TensorFlow'a dayalı pekiştirmeli öğrenim
Lei Feng.com: Bu makalenin orijinal başlığı TensorFlow ile Güçlendirme öğrenimidir, yazar Justin Francis ve tam metni Lei Feng'in altyazı grubu tarafından derlenmiştir.
Tercüme / Lin Lihong Wen Jiatu
Redaksiyon / Julia
Bitirme / Fan Jiang
Derin takviye öğrenme (Veya gelişmiş öğrenme) ustalaşması zor bir alandır. Çeşitli kısaltılmış isimler ve öğrenme modelleri arasında, pekiştirmeli öğrenme problemlerini çözmenin en iyi yolunu bulmak bizim için hala zordur. Pekiştirmeli öğrenme teorisi yeni değil. Aslında, pekiştirmeli öğrenme teorisinin bir kısmı 1950'lerin ortalarına kadar izlenebilir. Pekiştirmeli öğrenmede tamamen acemiyseniz, pekiştirmeli öğrenmenin temellerini öğrenmek için bir önceki makalem olan "Takviyeli Öğrenmeye Giriş ve OpenAI Spor Salonu" okumanızı öneririm.
Derin takviyeli öğrenme, çok sayıda gradyanın güncellenmesini gerektirir. TensorFlow gibi bazı derin öğrenme araçları, bu gradyanları hesaplarken özellikle yararlıdır. Derin pekiştirmeli öğrenmenin ayrıca durumu daha soyut olması için görselleştirmesi gerekir.Bu bağlamda, evrişimli sinir ağları en iyi performansı gösterir. Lei Feng.com'un bu çevirisinde, 3D oyun Doom'daki ("Doom") tıbbi paket koleksiyonunun ortamını çözmek için Python, TensorFlow ve takviye öğrenme kütüphanesi Gym'i kullanacağız.Kodun tam sürümünü ve kurulması gereken bağımlılıkları elde etmek istiyoruz. Bu makale için lütfen GitHub depomuzu ve Jupyter Not Defterimizi ziyaret edin.
Çevresel algılama
Bu ortamda, oyuncu çok aşındırıcı suda duran bir kişi gibi hareket edecek ve ilaç kitlerini toplayıp güvenli bir şekilde ayrılmanın bir yolunu bulması gerekecektir.
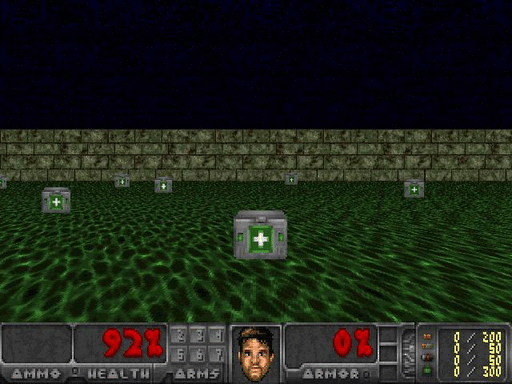
Şekil 1. Justin Francis tarafından sağlanan ortam
Bu sorunu çözebileceğimiz bir takviye öğrenme yöntemi, kıyaslama algoritmalarıyla birleştirilmiş pekiştirmeli öğrenmedir. Bu pekiştirme daha basit olacak, yalnızca mevcut çevresel davranıştan durum ve ödül verilerini gerektirecek. Takviye aynı zamanda Strateji gradyan yöntemi , Çünkü yalnızca temsilcinin stratejisini değerlendirir ve günceller. Strateji, temsilcinin mevcut durumda göstereceği davranıştır. Örneğin, oyun pongunda (masa tenisi oynamaya benzer) basit bir strateji şudur: Eğer top belirli bir açıda hareket ederse, o zaman en iyi davranış, bu açıya karşılık gelen bölmeyi hareket ettirmektir. Belirli bir durumda en iyi stratejiyi değerlendirmek için evrişimli sinir ağlarını kullanmanın yanı sıra, belirli bir duruma göre uzun vadeli ödülleri değerlendirmek veya tahmin etmek için aynı ağı kullanırız.
Önce Spor Salonu ile çevremizi tanımlayacağız
Temsilcinin öğrenmesine izin vermeden önce, buna rastgele seçilen bir ajanı gözlemlemek için bir kriter olarak bakarız Açıkçası, daha öğrenecek çok şeyimiz var.
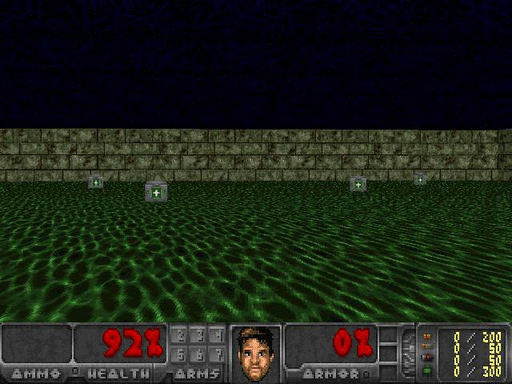
Şekil 2. Justin Francis tarafından sağlanan rastgele temsilci
Öğrenme ortamımızı kurmak
Pekiştirmeli öğrenme, öğrenme olarak kabul edilir Monte Carlo yöntemi , Bu, bu aracının tüm davranış boyunca veri toplayacağı ve davranış sona erdikten sonra hesaplamaya başlayacağı anlamına gelir. Örneğimizde, onu eğitmek için birden fazla davranış toplayacağız. Ortam eğitim verilerimizi boş olarak başlatacağız ve ardından eğitim verilerimizi aşamalı olarak ekleyeceğiz.
Daha sonra sinir ağımızı eğitme sürecinde kullanılacak bazı hiperparametreleri tanımlıyoruz.
Alfa, öğrenme oranımızdır ve gama, ödül indirim oranıdır. Ödül indirimleri, temsilcinin ödül geçmişine göre gelecekteki olası ödülleri değerlendirmenin bir yoludur. Ödül indirim oranı sıfır olma eğilimindeyse, Temsilcinin gelecekteki ödülleri dikkate almadan yalnızca mevcut ödüllere dikkat etmesi gerekir. Belirli bir davranış altında bir dizi ödülü değerlendirmek için basit bir işlev yazabiliriz, aşağıdaki kod:
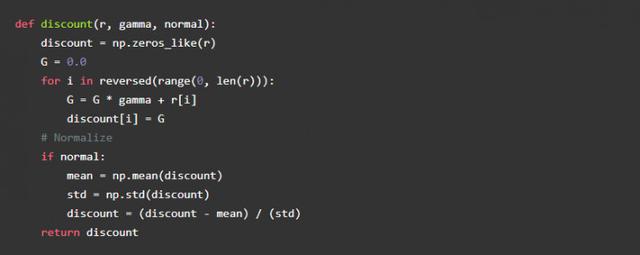
Ödülü hesaplayın:
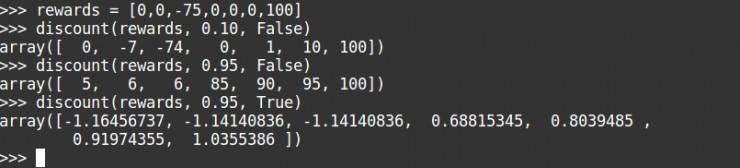
Bu yüksek iskonto oranlarını görebilirsiniz, arkasında büyük ödüller olduğu için ortadaki büyük olumsuz ödüller göz ardı edilir. Ödül aralığımızın belirli bir aralıkta kalmasını sağlamak için indirim ödüllerimize de düzenleme ekleyebiliriz. Bu, kıyamet ortamını çözmede çok önemlidir.
Belirli bir durumda, değer fonksiyonumuz her zaman indirim ödülüne yaklaşmaya çalışacaktır.
Evrişimli bir sinir ağı oluşturun
Bir sonraki adımda, durumu almak için evrişimli bir sinir ağı oluşturacağız ve ardından ilgili eylemin olasılık ve durum değerini vereceğiz. Seçilebilecek üç eylemimiz olacak: ileri, geri sola ve sağa. Bu yaklaşık stratejinin ayarı, görüntü sınıflandırıcıyla aynıdır, ancak fark, girdinin bir sınıfın güvenini temsil etmesidir ve çıktımızın belirli bir eylemin güvenini temsil etmesidir. Takviyeli öğrenme kullanan büyük görüntü sınıflandırma modelleriyle karşılaştırıldığında, basit sinir ağları daha iyi olacaktır.
Daha önce kullanılan iyi bilinen DQN algoritmasına benzer olan convnet'i kullanacağız. Sinir ağımız, sıkıştırılmış boyutu 84X84 piksel olan bir görüntü girecek ve 16 evrişimli 4 açıklıklı 8X8 çekirdek ve ardından 32 evrişimli 4 açıklık üretecektir. 8X8 çekirdeği, tamamen bağlı 256 seviyeli bir nöronla biter. Evrişimli katman için, görüntünün boyutunu büyük ölçüde azaltacak olan VALID dolgusu kullanacağız.
Hem yaklaşık stratejimiz hem de değer stratejimiz, değerlerini hesaplamak için aynı evrişimli sinir ağını kullanır.
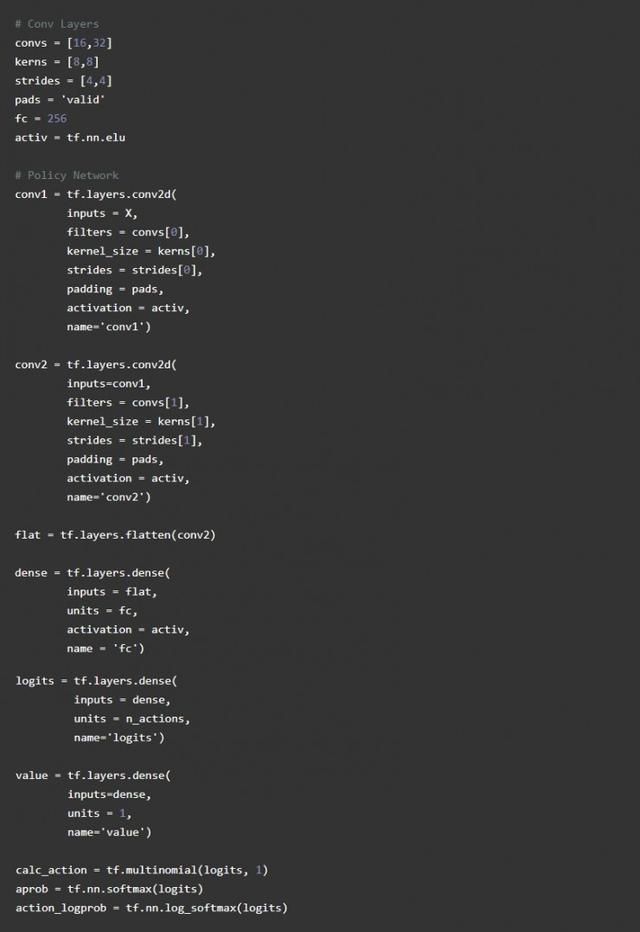
Derin öğrenmede, ağırlık başlatma çok önemlidir. Tf.layers varsayılan olarak ağırlıkları başlatmak için xavier başlatma olarak bilinen glorot uniform intializer'ı kullanacaktır. Ağırlıkları başlatmak için çok büyük bir sapma kullanırsanız, Aracıda bir sapma olur ve çok küçük bir sapma kullanırsanız, performans son derece rastgele olur. İdeal durum, başlangıçta rastgele davranmak ve ardından ödülü en üst düzeye çıkarmak için ağırlığın değerini yavaşça değiştirmektir. Pekiştirmeli öğrenmede buna keşif ve madencilik denir, çünkü başlangıçta temsilci rastgele bir keşif ortamı gibi davranacak ve ardından her güncellemede olası davranışı yavaşça iyi ödüller kazanabilecek eyleme doğru hareket ettirecektir. tarafından.
Performansı hesaplayın ve iyileştirin
Şimdi modeli oluşturduk ama öğrenmeye nasıl başlarız? Çözüm basit. Eylemlerimizin güvenini artırmak için sinir ağının ağırlığını değiştirmek istiyoruz ve değişim miktarı, değerimizi doğru bir şekilde nasıl tahmin edeceğimize dayanıyor. Genel olarak kayıplarımızı en aza indirmemiz gerekiyor.
TensorFlow üzerinde uygulandığında, strateji kaybımızı hesaplamak için sparse_softmax_cross_entropy işlevini kullanabiliriz. Seyrek, davranış etiketimizin tek bir tam sayı olduğu ve günlüklerin son etkin olmayan politika çıktımız olduğu anlamına gelir. Bu fonksiyon softmax ve log kaybını hesaplar. Bu, yürütülen eylemin güvenini 1'e ve kaybı 0'a yakın hale getirir.
Ardından, çapraz entropi kaybını, indirimli ödül ile yaklaşık değerimiz arasındaki farkla çarpıyoruz. Değer kaybımızı hesaplamak için ortak ortalama hata kaybını kullanırız. Ardından, toplam kaybımızı hesaplamak için kayıpları topladık.
Eğitim Temsilcisi
Şimdi Ajanı eğitmeye hazırız. Sinir ağına girmek için mevcut durumu kullanırız, tf.multinomial işlevini çağırarak eylemimizi alırız ve ardından eylemi belirler ve durumu, eylemi ve gelecekteki ödülleri koruruz. Yeni durum2'yi mevcut durumumuz olarak kaydediyoruz ve bu adımları sahne sonuna kadar tekrarlıyoruz. Ardından durumu, eylemi ve ödül verilerini yeni bir listeye ekliyoruz ve ardından bu girdileri toplu işi değerlendirmek için ağa kullanacağız.
İlk ağırlık başlangıcımıza göre, temsilcimiz nihayet ortamı ortalama 1200 ödül ile yaklaşık 200 eğitim döngüsünde çözmelidir. OpenAI'nin bu ortamı çözme standardı, 100'den fazla denemede 1.000 ödül almaktır. Temsilcinin daha fazla antrenman yapmasına izin verilir ve ortalama 1700'e ulaşabilir, ancak bu ortalamayı geçecek gibi görünmüyor. Bu, 1000 eğitim döngüsünden sonra benim temsilcim:

Şekil 3. 1000 defadan sonra Justin Francis şunları sağlar:
Ajanın güvenini daha iyi test etmek için, durumu sinir ağına girmeniz ve çıktıyı herhangi bir görüntü çerçevesinde gözlemlemeniz gerekir. Burada, bir duvarla karşılaştığında, temsilci sağa doğru gerçekleştirmenin en iyi eylemi olduğuna% 90 güveniyor. Bir sonraki görüntü sağda olduğunda, temsilci ilerlemenin en iyisi olduğuna dair% 61 güvene sahip. aksiyon.
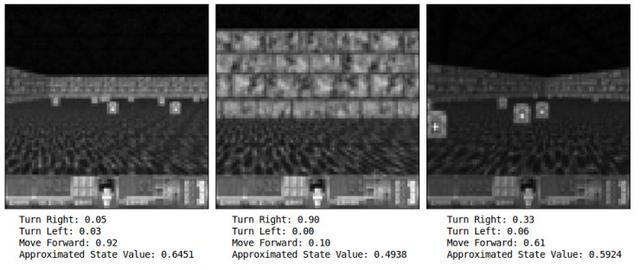
Şekil 4. Durum karşılaştırması, Justin Francis'in izniyle
Dikkatlice düşünürseniz,% 61'lik güvenin bariz iyi bir hareket olduğunu düşünebilirsiniz, bu o kadar da iyi değil ve haklısınız. Temsilcimizin esas olarak duvarlardan kaçınmayı öğrendiğinden şüpheleniyorum ve Temsilci yalnızca hayatta kalan ödülleri aldığı için, özellikle tıbbi kiti almaya çalışmıyor. Eldeki tıbbi çantayı almak hayatta kalma süresini uzatacaktır. Bazı açılardan, bu Ajanın tamamen zeki olduğunu düşünmezdim. Ajan sola dönüşü neredeyse görmezden geldi. Temsilci basit bir strateji kullandı, zaten kendi kendini öğreniyor ve oldukça etkilidir.
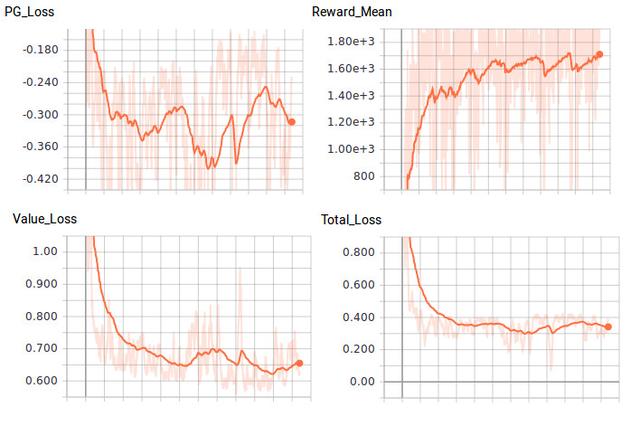
Şekil 5. Kayıp ve ödül karşılaştırması, Justin Francis tarafından sağlanmıştır
Bir adım daha ileri
Şimdi, politika gradyan yöntemlerinin temellerini anladığınızı umuyorum. Daha iyi Aktör-Eleştirmen yöntemi, A3C veya PPO, bunlar politika gradyanı yönteminin ilerlemesini destekleyen temel taşlarıdır. Geliştirilmiş model, durum geçişlerini, işletim değerlerini veya TD hatalarını dikkate almaz ve ayrıca kredi tahsisi sorunları ile başa çıkmak için de kullanılabilir. Bu sorunları çözmek için birden fazla sinir ağına ve daha akıllı eğitim verilerine ihtiyaç vardır. Hiper parametreleri ayarlamak gibi performansı iyileştirmenin birçok yolu vardır. Bazı küçük değişikliklerle, daha fazla Atari oyun problemini çözmek için aynı ağı kullanabilirsiniz. Git dene ve nasıl çalıştığını gör!
Lei Feng.com (Orijinal yazarın notu: Bu makale O'Reilly ve TensorFlow arasındaki bir işbirliğidir. Editoryal bağımsızlık beyanımıza bakın.)
Orijinal adres: https://www.oreilly.com/ideas/reinforcement-learning-with-tensorflow
