Bu makale, makine öğrenimi ve veri biliminin karar ağacını anlamanızı sağlar
Bu makale, orijinal başlığı olan AI Araştırma Enstitüsü tarafından derlenen teknik bir blogdur:
Makine Öğrenimi ve Veri Bilimi için Karar Ağaçları Kılavuzu
Yazar | George Seif
Tercüme | Yao Xiuqing
Düzeltme | Soslu Armut Terbiyesi | Ananas Kız
Orijinal bağlantı:
https://towardsdatascience.com/a-guide-to-decision-trees-for-machine-learning-and-data-science-fe2607241956
Karar ağacı, oldukça yorumlanabilir ve birçok görevde çok iyi performans gösteren çok güçlü bir makine öğrenimi modelidir. Makine öğrenimi modelindeki karar ağacının özelliği, açık bilgi temsili yapısında yatmaktadır. Karar ağacı tarafından eğitim yoluyla öğrenilen "bilgi", doğrudan hiyerarşik bir yapı oluşturur. Bilgi yapısı, uzman olmayanların bile kolayca anlayabileceği şekilde depolanır ve görüntülenir.

Hayatta karar ağacı
Hayatınızı belirlemek için daha önce karar ağaçlarını kullanmış olabilirsiniz. Örneğin, bu hafta sonu hangi etkinlikleri yapmanız gerektiğine karar verin. Bu, arkadaşlarınızla dışarı çıkmaya veya hafta sonunu yalnız geçirmeye istekli olup olmadığınıza bağlı olabilir; her iki durumda da kararınız hava durumuna da bağlıdır. Hava güzelse arkadaşlarınızla futbol oynayabilirsiniz. Yağmur yağarsa sinemaya gideceksin. Arkadaşınız hiç görünmezse, hava nasıl olursa olsun, video oyunları oynamayı seçeceksiniz!
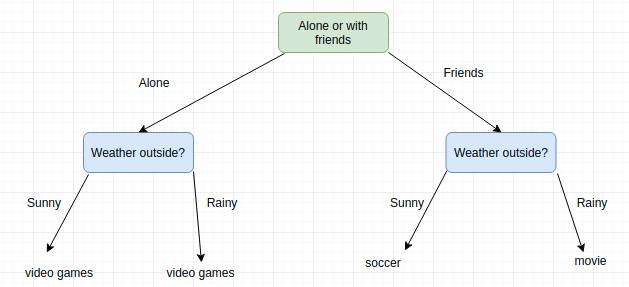
Bu, gerçek hayattaki karar ağacı uygulamasına bir örnektir. Bir dizi sıralı, hiyerarşik kararı simüle etmek için bir ağaç oluşturduk ve sonunda bazı sonuçlar elde ettik. Ağacı küçük tutmak için oldukça "ileri" bir karar seçtiğimizi unutmayın. Örneğin, hava için 25 derece güneşli, 25 derece yağmur, 26 derece güneşli, 26 derece yağmur, 27 derece güneşli gibi birçok olası seçeneği belirlersek ağacımız çok büyük olacaktır. ! Kesin sıcaklık gerçekten biraz alakalı, sadece dışarı çıkıp çıkamayacağımızı bilmek istiyoruz.
Makine öğreniminde karar ağaçları kavramı aynıdır. Bir dizi seviyeden oluşan bir karar ağacı oluşturmak ve sınıflandırma veya regresyon tahmini gibi nihai sonucu vermek istiyoruz. Karar, yüksek sınıflandırma ve gerileme doğruluğu elde etmeyi hedeflerken ağacı olabildiğince küçültmek için seçilir.
Makine öğreniminde karar ağaçları
İki adımda bir karar ağacı modeli oluşturun: indüksiyon ve budama. Tümevarım, ağacı oluşturma şeklimizdir, yani verilerimize dayanarak tüm hiyerarşik karar sınırlarını belirleriz. Eğitim karar ağaçlarının doğası gereği, aşırı uyuma eğilimli olabilirler. Budama, gereksiz yapıyı karar ağacından çıkarmak, aşırı uyuma karşı mücadelenin karmaşıklığını etkin bir şekilde azaltmak ve yorumlamayı kolaylaştırmaktır.
Giriş
Üst düzey bir bakış açısından, bir karar ağacı oluşturmanın 4 ana adımı vardır:
Eğitim veri setinden başlayarak, veri setinde bazı özellik değişkenleri, sınıflandırma veya regresyon çıktısı olmalıdır.
Verileri bölümlere ayırmak için veri kümesindeki "en iyi özelliği" belirleyin; "en iyi özelliği" nasıl tanımladığımız hakkında daha fazla bilgi
Verileri, en iyi özellikleri içeren olası değerlerin alt kümelerine bölün. Bu bölümleme temel olarak ağaç üzerindeki düğümleri tanımlar, yani her düğüm, verilerimizdeki belirli bir özelliğe dayalı bir bölümleme noktasıdır.
3. adımda oluşturulan veri alt kümesini kullanarak yinelemeli olarak yeni ağaç düğümleri oluşturun. Bölme / düğüm sayısını en aza indirirken bazı yöntemlerle maksimum doğruluğu optimize ettiğimiz bir noktaya ulaşana kadar bölünmeye devam ediyoruz.
Adım 1 basit, sadece veri setinizi toplayın!
Adım 2 için, kullanılacak özellikleri seçmek için genellikle açgözlü bir algoritma ve maliyet işlevini en aza indirmek için belirli bir segmentasyon yöntemi kullanılır. Bir saniye düşünürsek, karar ağacını oluştururken ayırma, özellik uzayını bölmeye eşdeğerdir. Yinelemeli olarak farklı bölme noktalarını deneyeceğiz ve ardından en düşük maliyetli bölme noktasını seçeceğiz. Elbette sadece veri setimiz kapsamında bölme gibi bazı akıllıca şeyler yapabiliriz. Bu bizi, kalitesiz olan bu bölünmüş noktaları test etmek için hesaplamaları israf etmekten kurtaracaktır.
Regresyon ağaçları için, maliyet fonksiyonumuz olarak basit bir kare farkı kullanabiliriz:
Y temel olgumuzdur ve Y-hat tahmin edilen değerimizdir; toplam hatayı elde etmek için veri setindeki tüm örnekleri topluyoruz. Sınıflandırma için Gini endeksini kullanıyoruz:
Burada pk, belirli bir tahmin düğümünde k kategorisinin eğitim örneklerinin oranıdır. İdeal olarak, düğümün hata değeri sıfır olmalıdır, bu da her bölünmenin% 100 oranında tek bir sınıflandırma çıktısı vereceği anlamına gelir. Bu tam olarak istediğimiz şeydir, çünkü karar sınırının bir tarafında veya diğer tarafında olsak da, o belirli karar düğümüne ulaştığımızda çıktımızın ne olduğunu biliyoruz.
Veri setimizde tek bir sınıflandırmaya sahip olma kavramına bilgi kazancı denir. Aşağıdaki örneğe bir göz atın.

Her çıktının girdi verilerine dayalı olarak kategorileri karıştırdığı bir bölüm seçersek, aslında hiçbir bilgi elde edemeyiz; belirli bir düğümün, yani bir özelliğin, sınıflandırma verilerimiz üzerinde herhangi bir etkisi olup olmadığını bilmiyoruz! Öte yandan, segmentasyonumuz her çıktı kategorisinin yüksek bir yüzdesine sahipse, bize belirli bir çıktı vermek için belirli özellik değişkenleri hakkında özel bir yolla segmentasyon hakkında bilgi elde ettik!
Şimdi ağacımız binlerce dala sahip olana kadar bölmeye, ayırmaya ve ayırmaya devam edebiliriz ... ama bu iyi bir fikir değil! Karar ağacımız çok büyük, yavaş olacak ve eğitim veri setimizi aşacak. Bu nedenle, ağaç yapımını durdurmak için önceden tanımlanmış bazı durdurma kriterleri belirleyeceğiz.
En yaygın durdurma yöntemi, her yaprak düğüme atanan eğitim örneklerinin sayısı için minimum bir sayı kullanmaktır. Sayı, belirli bir minimum değerin altındaysa, bölünme kabul edilmez ve düğüm, son yaprak düğüm olarak kabul edilir. Tüm yaprak düğümlerimiz son düğümler olursa, eğitimi durdurun. Daha küçük bir minimum sayı, size daha ince segmentasyon ve daha fazla bilgi sağlar, ancak aynı zamanda eğitim verilerinizi aşırı kullanmak da kolaydır. Dakika sayısı çok küçükse, erken bırakabilirsiniz. Bu nedenle minimum, her sınıfta kaç örnek beklendiğine bağlı olarak genellikle veri seti ayarına bağlıdır.
Budama
Eğitim karar ağaçlarının doğası gereği, aşırı uyuma eğilimli olabilirler. Her düğüm için minimum örnek sayısı için doğru değeri ayarlamak zor olabilir. Çoğu durumda, minimum değeri çok küçük yapabiliriz, bu da birçok bölünmeye ve çok büyük karmaşık ağaçlara neden olur. Mesele şu ki, bu bölünmelerin çoğu sonunda gereksiz hale gelecek ve modelin doğruluğunu iyileştirmeyecektir.
Budama, bu bölünmüş fazlalığı, yani ağaçtaki gereksiz bölmeleri budamak için kullanılan bir tekniktir. Yüksek bir seviyeden başlayarak, budama, ağacın bir bölümünü katı bir karar sınırından daha yumuşak ve daha genel bir ağaca sıkıştırarak, ağacın karmaşıklığını etkili bir şekilde azaltır. Karar ağacının karmaşıklığı, ağaçtaki bölünmelerin sayısı olarak tanımlanır.
Basit ve verimli bir budama yöntemi, ağaçtaki her bir düğümü geçmek ve onu kaldırmanın maliyet işlevine etkisini değerlendirmektir. Fazla değişmezse, düzeltin!
Scikit Learn örneği
Scikit Learn'de yerleşik sınıflandırma ve regresyon karar ağacı sınıflarını kullanmak kolaydır! Önce veri setini yükleyin ve sınıflandırma için karar ağacımızı başlatın.

Scikit Learn ayrıca ağaçlarımızı graphviz kütüphanesini kullanarak görselleştirmemize izin verir. Öğrenmeyi basitleştirmek için karar düğümlerini ve segmentasyon modellerini görselleştirmeye yardımcı olacak bazı seçenekler sunar; bu, nasıl çalıştığını anlamak için çok yararlıdır! Aşağıda düğümleri işlev adına göre renklendireceğiz ve her düğümün sınıf ve işlev bilgilerini görüntüleyeceğiz.
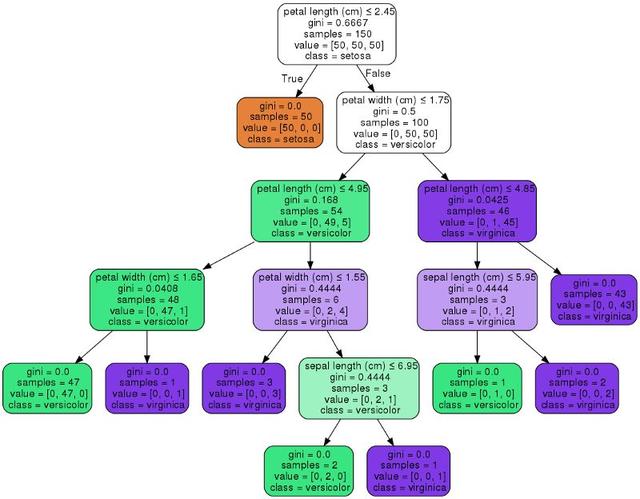
Scikit Learn'de karar ağacı modeli için çeşitli parametreler ayarlayabilirsiniz. Daha iyi sonuçlar elde etmek için bazı ilginç girişimler şunlardır:
-
max_depth: Düğümleri bölmeyi durduracağımız ağacın maksimum derinliği. Bu, derin bir sinir ağındaki maksimum katman sayısını kontrol etmeye benzer. Daha düşük bir değer, modelinizi daha hızlı yapar ancak doğru olmaz; daha yüksek bir değer size doğruluk sağlayabilir, ancak risk gereğinden fazla uyum sağlar ve yavaş olabilir.
-
min_samples_split: Bir düğümü bölmek için gereken minimum örnek sayısı. Karar ağacının bu yönünü tartıştık ve onu daha yüksek bir değere nasıl ayarlayacağımız, aşırı uyumu azaltmaya yardımcı olacaktır.
-
max_features: En iyi segmentasyon noktasını bulurken dikkate alınacak özelliklerin sayısı. Daha yüksek, muhtemelen daha iyi sonuçlar anlamına gelir, ancak eğitim daha uzun sürer.
-
min_impurity_split: Ağaç genişletmenin erken durması için eşik. Düğümün kirliliği eşikten yüksekse, düğüm bölünecektir. Bu, aşırı uyum (yüksek değerler, küçük ağaçlar) ve yüksek doğruluk (düşük değerler, büyük ağaçlar) ile mücadeleyi dengelemek için kullanılabilir.
-
ön sıralama: Yerleştirilen verilerdeki en iyi bölünmenin keşfedilmesini hızlandırmak için verilerin önceden tahsis edilip edilmeyeceği. Her özelliğin verilerini önceden sıralarsak, eğitim algoritmamız ayırma için uygun değeri daha kolay bulacaktır.
Karar ağaçlarının pratik uygulaması için teknikler
Karar ağaçlarının probleminize uygun olup olmadığını belirlemenize yardımcı olabilecek bazı avantajları ve dezavantajları ve bunları nasıl etkili bir şekilde uygulayacağınıza dair bazı ipuçları:
avantaj:
-
Anlaması ve açıklaması kolay. Her düğümde, modelimizin tam olarak hangi kararı verdiğini görebiliriz. Uygulamada, doğruluğumuzun ve hatalarımızın nereden geldiğini, modelin ne tür verileri iyi işleyebileceğini ve çıktının özdeğerlerden nasıl etkilendiğini tam olarak anlayabileceğiz. Scikit Learn'ün görselleştirme aracı, karar ağaçlarını görselleştirmek ve anlamak için mükemmel bir seçimdir.
-
Çok az veri hazırlığı gereklidir. Birçok makine öğrenimi modeli, standardizasyon gibi çok sayıda veri ön işleme gerektirebilir ve karmaşık düzenlilik yöntemleri gerektirebilir. Öte yandan, bazı parametreler ayarlandıktan sonra karar ağacı kutunun dışında kullanılabilir.
-
Çıkarım için bir ağaç kullanmanın maliyeti, ağacı eğitmek için kullanılan veri noktalarının sayısının yalnızca logaritmasıdır. Bu çok büyük bir avantaj çünkü daha fazla veriye sahip olmanın çıkarım hızımız üzerinde çok büyük bir etkiye sahip olmadığı anlamına geliyor.
Dezavantajları:
-
Eğitimin doğası gereği, karar ağaçlarında aşırı uyum çok yaygındır. Ağacın bu kadar çok özelliğe bölünmesi gerekmemesi için genellikle PCA gibi bir tür boyutluluk azaltma işlemi yapılması önerilir.
-
Aşırı uyum durumuna benzer şekilde, karar ağacı da veri setinin çoğunluğunu oluşturan kategoriye karşı önyargılı olmaya eğilimlidir. Bununla birlikte, belirli sınıfları dengelemek her zaman iyi bir fikirdir (sınıf ağırlıkları, örnekleme veya özel kayıp fonksiyonları gibi).
Önerilen Kaynaklar
Makine öğrenimi için Scikit Learn kullanımı hakkında daha fazla bilgi edinmek istiyorsanız, uygulamalı öğrenme, özellikle de uygulamalı kodlama ve pratik için Scikit-Learn ve TensorFlow ile Uygulamalı Makine Öğrenimi kitabını kullanmanızı öneririm!
Öğrenmeye hazır?
Beni Twitter'da takip edin, en yeni ve en büyük yapay zeka, teknoloji ve bilim hakkında her şeyi gönderiyorum!
Bu makalenin ilgili bağlantılarını ve referanslarını görüntülemeye devam etmek ister misiniz?
Bağlantıya uzun basın ve alt kısmı açmak veya tıklamak için tıklayın [Bu makale, makine öğrenimi ve veri biliminin karar ağacını anlamanıza yardımcı olur]:
https://ai.yanxishe.com/page/TextTranslation/1323
AI Araştırma Enstitüsü heyecan verici içerikleri günlük olarak güncelliyor ve daha heyecan verici içerikler izliyor: Lei Feng Wang Lei Feng Wang Lei Feng Wang
Dilbilim Perspektifinden Kelime Gömme Modeli Üzerine
Derin ağın ardındaki matematik
Drone görüntülerinde hedef tespiti için derin öğrenme nasıl uygulanır
Python gelişmiş teknikler: tek satır kod ile bellek kullanımını yarı yarıya azaltın
Çevirmenizi bekliyorum: