Tekrarlayan sinir ağı geliştirme yöntemleri: dikkat mekanizması ve daha fazlası
Leifeng.com AI teknolojisi yorum notu: RNN'den bahsederken, düşündüğümüz en kolay uygulama LSTM + dikkatidir. Klasik bir ağ yapısı olarak LSTM'nin eski ve güçlü olduğu söylenebilir, diğer yandan dikkat mekanizması çok yaygın ve hatta bunun "elbette bir mesele" olduğunu bile düşünebiliriz. Ancak aslında, ağı geliştirmenin tek yolu dikkat mekanizması değildir. Distill.pub blogundaki bu makale, dikkat dahil olmak üzere çeşitli ağ geliştirme yöntemlerini incelememize götürür. Farklı yönlere odaklanırlar ve araştırmacıların / geliştiricilerin gerçek ihtiyaçlarına göre seçim yapmaları uygundur. Leifeng.com AI Technology Review aşağıdaki gibi derlenmiştir.
Tekrarlayan sinir ağı (RNN), derin öğrenme teknolojisinde çok önemli bir model türüdür ve sinir ağlarının metin, ses ve video gibi sıra verilerini işlemesine izin verir. İnsanlar, sekansı etiketlemek ve hatta sıfırdan yeni bir sekans oluşturmak için bir sekansı üst düzey bir anlayış moduna indirgemek için tekrarlayan sinir ağlarını kullanabilir.
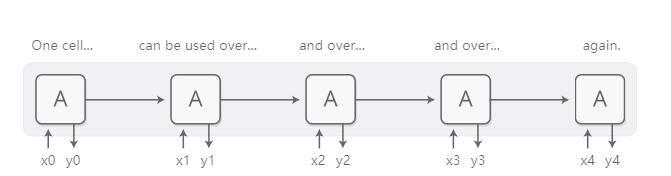
Temel RNN tasarım sürecinin zorlu uzun dizilerle uğraşması gerekir, ancak özel bir RNN varyantı-LSTM (uzun kısa süreli bellek, uzun kısa süreli bellek ağı) bu durumda iyi çalışabilir. İnsanlar bu modellerin çok güçlü olduğunu ve makine çevirisi, konuşma tanıma ve görüntü anlama (resimleri görme ve konuşma) dahil olmak üzere birçok görevde çok iyi sonuçlar elde edebildiğini fark ediyor. Bu nedenle, son birkaç yılda tekrarlayan sinir ağları yaygın olarak kullanıldı.
İnsanların tekrarlayan sinir ağları üzerine araştırmaları gittikçe derinleştikçe, giderek daha fazla insanın tekrarlayan sinir ağlarını geliştirmek için bazı yeni özellikleri kullanmaya çalıştığını gördük. Dört yöndeki gelişmeler özellikle heyecan vericidir:
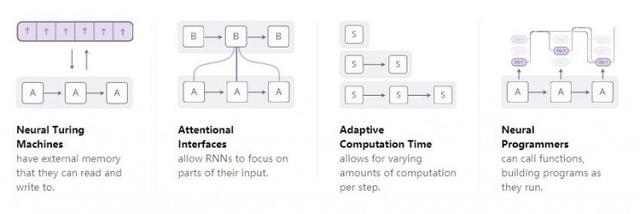
Bu teknolojilerin her biri sinir ağını büyük ölçüde geliştirdi. Bununla birlikte, gerçekten harika olan, bu teknolojilerin birleştirilip birlikte kullanılabilmesidir ve bu mevcut teknolojiler, geniş araştırma alanında sadece küçük bir tekne gibi görünmektedir. Ek olarak, hepsi aynı temel teknolojiye, dikkat mekanizmasına güveniyor.
Nöral Turing Makinesi
Nöral Turing makinesi, RNN'yi harici depolama birimi ile birleştirir. Bir vektör, bir sinir ağındaki doğal dilin tezahürü olduğundan, depolama birimindeki içerik bir dizi vektördür:
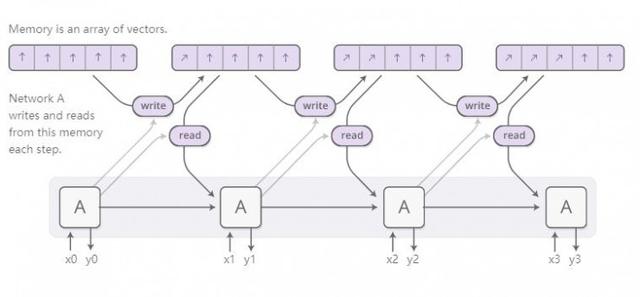
Peki Nöral Turing Makinesinin okunması ve yazılması nasıl çalışır? Asıl zorluk, onları farklılaştırmamız gerektiğidir. Özellikle, nerede okuyup yazacağımızı öğrenebilmemiz için onları okuduğumuz ve yazdığımız yerden ayırt edilebilir hale getirmemiz gerekiyor. Depolama adresleri temelde ayrık olduğundan, onları ayırt edilebilir hale getirmek çok zordur. Bu nedenle, Sinirsel Turing Makineleri çok akıllı bir çözüm benimsemiştir: her işlem adımında, depolama ünitesinin tüm pozisyonlarında okuyacak ve yazacaklar, ancak derecesi farklı.
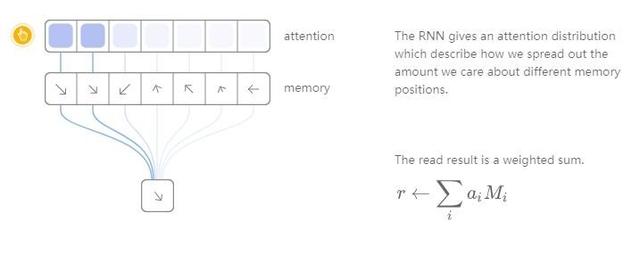
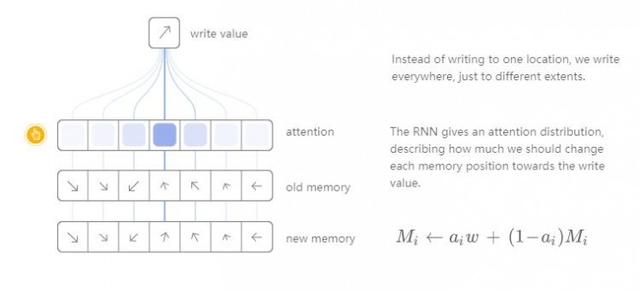
Örneğin, okuma işlemlerine odaklanalım. RNN, belirli bir okuma konumu belirtmez, ancak dikkatimizin farklı depolama konumlarına dağıtımını açıklayan bir "dikkat dağıtımı" üretir. Bu şekilde elde edilen okuma işleminin sonucu ağırlıklı bir toplamdır.
Benzer şekilde, depolama ünitesindeki çeşitli konumlara değişen derecelerde yazacağız. Her pozisyonda ne kadar yazdığımızı açıklamak için yine bir dikkat dağılımı kullanıyoruz. Bunu, depolama ünitesindeki her bir konumun yeni değerini eski depolama içeriği ile yeni yazılan değerin dışbükey bir kombinasyonu haline getirerek yapıyoruz ve eski depolama içeriği ile yeni değer arasındaki konum dikkat ağırlığına bağlıdır.
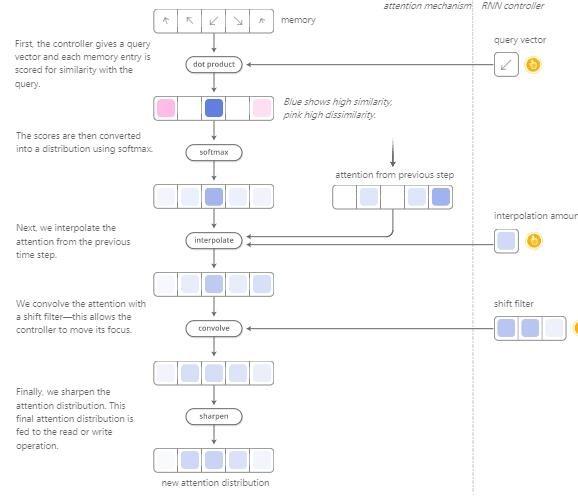
Ancak Nöral Turing Makinesi, dikkatin depolama biriminde nereye odaklanacağını nasıl belirler? Aslında, iki farklı yöntemin bir kombinasyonunu kullanırlar: içeriğe dayalı dikkat mekanizması ve konuma dayalı dikkat mekanizması. İçeriğe dayalı dikkat mekanizması, Nöral Turing makinesinin hafızasında arama yapmasına ve aradığı hedefle eşleşen konuma odaklanmasına izin verirken, konuma dayalı dikkat mekanizması dikkatin depolama birimindeki göreceli hareketini sağlar. Mümkünse Nöral Turing Makinesi çevrilebilir.
Bu okuma ve yazma yeteneği, Nöral Turing Makinesinin sinir ağları kategorisiyle sınırlı olmayan birçok basit algoritmayı çalıştırmasını sağlar. Örneğin, uzun bir sekansı bir depolama ünitesinde saklamayı öğrenebilirler ve ardından döngü işlemini tekrarlayabilirler. Yaptıklarında, ne yaptıklarını daha iyi anlamak için nerede okuma ve yazma işlemleri yaptıklarını görebiliriz:
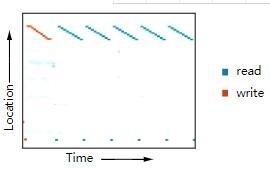
Konumunda daha deneysel sonuçlar görüntüleyebilirsiniz. Yukarıdaki şekil, tekrarlanan çoğaltma deneylerine dayanmaktadır.
Ayrıca, arama tablosu yöntemini taklit etmeyi ve hatta sayıları sıralamayı öğrenebilirler (bazı fırsatçı yöntemler benimsenmiş olsa da)! Öte yandan, sayıları toplamak veya çarpmak gibi bazı çok temel görevler karşısında bazen güçsüzdürler.
En ilkel nöral Turing makinesi makalelerinin yayınlanmasından bu yana, ilgili alanlarda heyecan verici araştırma ilerlemeleri kaydeden çok sayıda makale ortaya çıktı. Nöral GPU, Nöral Turing Makinesinin sayı toplayıp çarpamaması sorununu çözer. Zaremba ve Sutskever ve diğerleri, nöral makine çevirisini eğitmek için en ilkel nöral Turing makinesinde kullanılan farklılaştırılabilir okuma ve yazma teknolojisinin yerini almak için pekiştirmeli öğrenmeyi kullandı. Nöral rastgele erişim belleği (NRAM), işaretçiler temelinde çalışır. Şu anda, bazı makaleler yığınların ve kuyrukların farklılaştırılabilir veri yapısını araştırmıştır. Bellek ağları, benzer sorunları çözmenin başka bir yoludur.
Nesnel anlamda, bu modellerin gerçekleştirebileceği birçok görev (sayıların nasıl ekleneceğini öğrenmek gibi) çok zor değildir. Geleneksel programlama teknikleri için bu görevlerin çocuk oyuncağı olduğu söylenebilir. Ancak sinir ağları diğer birçok sorunu çözebilir ve Neural Turing Machines gibi mevcut modellerin yetenekleri hala çok sınırlı ve tam olarak geliştirilmemiştir.
Kod
Bu modellerin birçok açık kaynak uygulama sürümü vardır. Neural Turing Machines'in açık kaynaklı uygulamaları arasında Taehoon Kim (Tensorflow sürümü, https://github.com/carpedm20/NTM-tensorflow), Shanwn (Theano sürümü, https://github.com/shawntan/neural-turing-machines), Fumin (Go sürümü, https://github.com/fumin/ntm), Kai Sheng (Torch sürümü, https://github.com/kaishengtai/torch-ntm), Snip (Lazanya sürümü, https: // github. com.tr / snipsco / ntm-lasagne) ve diğerleri. Nöral GPU kodu açık kaynaklıdır ve TensorFlow model kitaplığına dahil edilmiştir (https://github.com/tensorflow/models/tree/master/neural_gpu). Bellek ağlarının açık kaynaklı uygulamaları arasında Facebook (Torch / Matlab sürümü, https://github.com/facebook/MemNN), YerevaNN (Theano sürümü, https://github.com/YerevaNN/Dynamic-memory-networks-in-Theano bulunur. ), Taehoon Kim (TensorFlow sürümü, https://github.com/carpedm20/MemN2N-tensorflow) ve diğerleri.
Dikkat mekanizması
Bir cümleyi tercüme ederken, o anda çevrilmiş olan kelimeye özellikle dikkat ederiz. Bir kaydı yazıya döktüğümüzde, yazmaya çalıştığımız bölümü dikkatlice dinleriz. Benden oturduğum odayı tarif etmemi isterseniz, onu tarif ederken çevredeki nesnelere bakacağım.
Sinir ağları, tüm ortamda elde edilen bilgilerin bir kısmına odaklanarak aynı davranışı elde etmek için dikkat mekanizmasını kullanır. Örneğin, bir RNN, başka bir RNN'nin çıktısını işleyebilir. Her zaman adımında, dikkat mekanizmasına sahip RNN, farklı konumlardaki başka bir RNN'nin içeriğine dikkat edecektir.
Dikkat mekanizmasının ayırt edilebilir olmasını istiyoruz, böylece neye odaklanacağımızı öğrenebiliriz. Bunu yapmak için Nöral Turing Makinesi ile aynı teknolojiyi kullanıyoruz: tüm pozisyonlara dikkat ediyoruz, ancak dikkatin derecesi farklı.
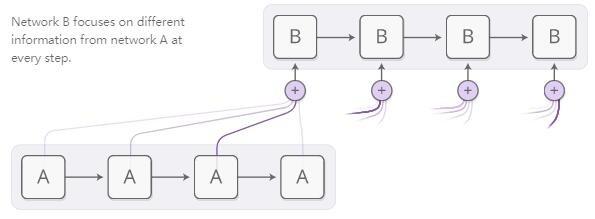
Dikkat dağıtımı, genellikle içeriğe dayalı dikkat mekanizmaları tarafından oluşturulur. Çalıştırmak için kullandığımız RNN, odaklanmak istediği yeri tanımlayan bir arama terimi oluşturacaktır. Arama terimiyle ne kadar iyi eşleştiğini açıklayan bir puan oluşturmak için her öğe arama terimiyle çarpılacaktır. Bu puan, dikkat dağılımını oluşturmak için Softmax işlevine girdi olarak kullanılacaktır.
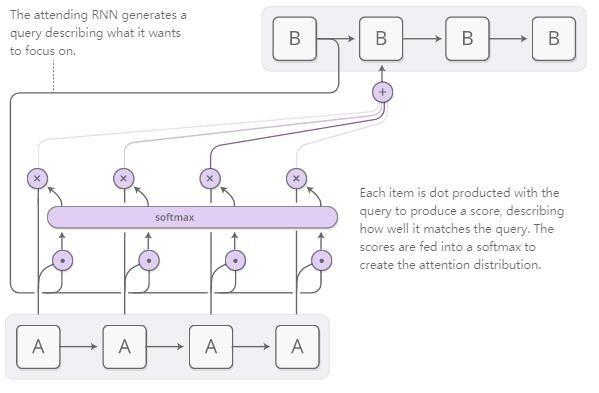
Dikkat mekanizmasının RNN'ler arasında uygulandığı bir senaryo makine çevirisidir. Geleneksel bir diziden diziye (Seq2Seq) model, tüm girdiyi tek bir vektöre indirmeli ve ardından çeviri sonucunu elde etmek için tekrar genişletmelidir. Dikkat mekanizması, RNN'nin girişi işlemesini sağlayarak gördüğü her kelimenin bilgisini iletir ve ardından dikkati çıktıyı oluşturan RNN'deki ilgili kelimelere odaklanır.
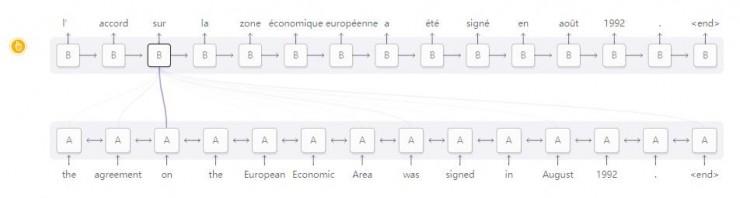
RNN'ler arasındaki bu tür dikkat mekanizmasının birçok başka uygulama senaryosu vardır. Konuşma tanımada kullanılabilir, böylece bir RNN ses bilgisini işleyebilir ve sonra başka bir RNN buna göz atabilir ve sese karşılık gelen metni oluştururken ilgili kısımlara odaklanabilir.

Bu dikkat mekanizmasının diğer uygulamaları metin ayrıştırmayı içerir Bu zamanda, dikkat mekanizması modelin bir ayrıştırma ağacı oluştururken sözcükleri taramasına izin verir. Diyalog modelleme görevinde dikkat mekanizması, modelin yanıt metnini oluştururken diyalogdan önce ilgili gereksinimlerin içeriğine odaklanmasını sağlar.
Dikkat mekanizması, evrişimli sinir ağları ile tekrarlayan sinir ağları arasındaki arayüzde de kullanılabilir. Buradaki dikkat mekanizması, RNN'nin her adımda görüntüdeki farklı konumlara dikkat etmesini sağlar. Bu dikkat mekanizmasının popüler uygulama senaryosu "resimlere bak ve konuş" dur. İlk olarak, evrişimli bir ağ, yüksek seviyeli özellikleri çıkarmak için görüntüyü işler; daha sonra görüntünün bir açıklamasını oluşturmak için bir RNN çalıştırır. Açıklamadaki her kelimeyi oluşturduğunda, RNN, görüntünün ilgili kısmının evrişimli sinir ağı tarafından yorumlanmasına odaklanacaktır. Bu süreci aşağıdaki şekilde görselleştirebiliriz:

Daha genel olarak, çıktıda tekrarlayan bir yapıya sahip bir sinir ağı ile arayüz oluşturmak istediğimizde, dikkat arayüzünü kullanabiliriz.
İnsanlar dikkat arayüzünün çok yönlü ve güçlü bir teknoloji olduğunu ve giderek daha yaygın olarak kullanıldığını görüyor.
Uyarlanabilir hesaplama süresi
Standart bir RNN, her zaman adımında aynı sayıda hesaplama yapar. Bu sezgisel görünmüyor. Elbette, uğraşmamız gereken sorun daha karmaşık hale geldiğinde, insanlar bunun hakkında daha fazla düşünmeli mi? Ek olarak, standart RNN, işlem uzunluğu n ila O (n) olan dizilerin zaman karmaşıklığını da sınırlar.
Uyarlanabilir hesaplama süresi, RNN'nin her adımda farklı sayıda hesaplama yapmasına izin veren bir yöntemdir. Genel fikir çok basittir: RNN'nin her adımda çok adımlı hesaplamalar yapmasına izin verir.
Ağın kaç adımın sayılması gerektiğini öğrenmesi için adım sayısının farklılaştırılabilir olmasını istiyoruz. Bunu başarmak için kullandığımız tekniğin aynısını kullanıyoruz: Kesikli sayıda adım çalıştırmak yerine, yürüttüğümüz adım sayısı için bir dikkat dağılımı kullanıyoruz. Çıktısı, her adımın çıktısının ağırlıklı bir kombinasyonudur.
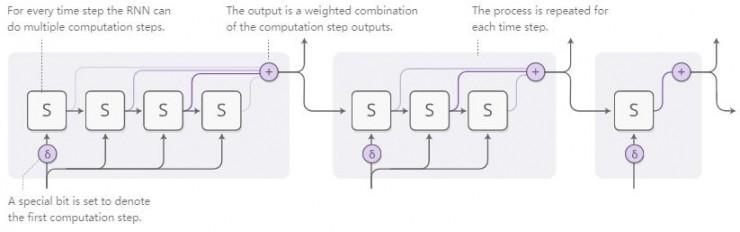
Yukarıdaki resim ayrıca bazı ayrıntıları görmezden geliyor. Aşağıdaki şekil, bir seferde üç hesaplama adımının eksiksiz bir şematik diyagramıdır:
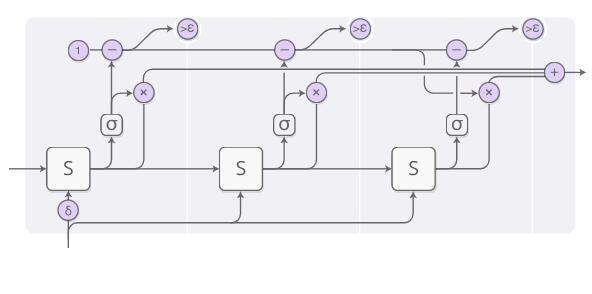
Bu şekilde açıklanan hesaplama süreci biraz karmaşıktır, bu yüzden adım adım analiz edelim. Yüksek seviyede, hala RNN çalıştırıyoruz ve ağırlıklı bir durum kombinasyonu çıkarıyoruz:
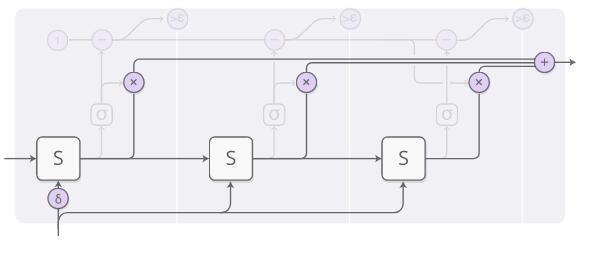
Her hesaplama adımının ağırlığı, bir "tampon nöron" tarafından belirlenir. RNN'nin durumunu gözlemleyebilen ve tampon ağırlığı verebilen sigmoid bir nörondur.Bu aşamada durmamız gereken olasılık olarak düşünebiliriz.
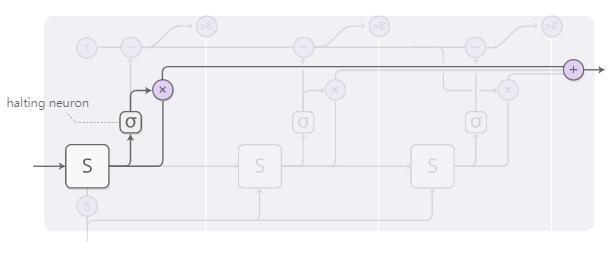
Tampon ağırlığı için toplam bütçe üst limitimiz 1'dir ve ardından aşağıdaki şeklin en üst satırındaki hesaplama sürecine göre (1'den başlayıp her adımda karşılık gelen değeri çıkararak) hesaplıyoruz. Epsilon'dan daha küçük olduğunda, hesaplamayı durdururuz.
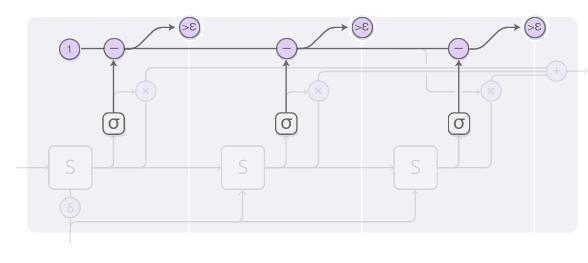
Durduğumuzda, tampon bütçesi dışında henüz hesaplanmamış bazı parçalar olabilir, çünkü epsilon'dan daha düşük olduğunda hesaplamayı durduracağız. Bu durumla nasıl başa çıkmalıyız? Teknik olarak ileride hesaplanmaya devam edebilecek bir adım veriliyor ve şimdi hesaplamak istemiyoruz, bu yüzden mevcut durumu son adım olarak tanımlıyoruz.
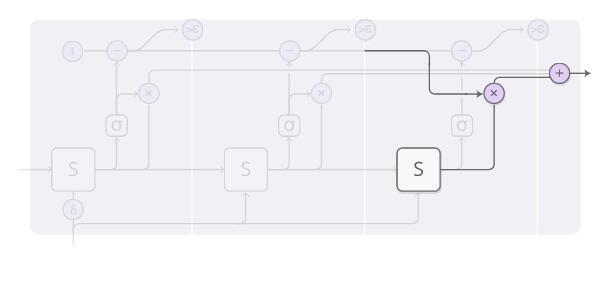
Uyarlanabilir bir hesaplama zaman modeli eğittiğimizde, modelin kümülatif hesaplama zamanını cezalandırmak için kayıp fonksiyonuna bir "düşünme maliyeti" ekleyebiliriz. Bu öğe ne kadar büyük olursa, hesaplama süresinin kısalması nedeniyle performans o kadar azalacak ve uzlaşma sağlanacaktır.
Uyarlanabilir hesaplama süresi çok yeni bir fikir, ancak bunun ve benzer fikirlerin çok önemli olduğuna inanıyoruz.
Kod
"Uyarlanabilir bilgi işlem süresi" modeli için tek açık kaynak kodu Mark Neumann'ın sürümü (TensorFlow sürümü, https://github.com/DeNeutoy/act-tensorflow) gibi görünüyor.
Sinir Ağı Programcısı
Sinir ağları birçok görevde çok iyi performans gösterir, ancak bazı temel şeyleri yapmak da zordur. Örneğin, aritmetik sinir ağları için çok zordur ve sıradan hesaplama yöntemleri için kolaydır. Sinir ağlarını sıradan programlama yöntemleriyle entegre etmenin bir yolu varsa, en büyük kazan-kazan durumu elde edilecektir.
Sinir ağı programcısı bu sorunu çözmenin bir yoludur. Bu sorunu çözmek için programlar oluşturmayı öğrenecek. Aslında, doğru program örnek şablonlarına ihtiyaç duymadan bu tür programları oluşturabilir. Belirli bir görevi tamamlamak için bir araç olarak bir programın nasıl üretileceğini öğrenecektir.
Makaledeki asıl model, SQL benzeri bir program sorgu formu oluşturarak bu soruyu yanıtlamaktadır. Bununla birlikte, bu ortamdaki çok sayıda ayrıntı, onu biraz karmaşık hale getirir. Öyleyse, aritmetik bir ifade veren ve onu değerlendirmek için bir model oluşturan biraz daha basit bir model hayal ederek başlayabiliriz.
Oluşturulan program bir işlemler dizisidir. Her işlem, geçmiş işlemin çıktısına ilişkin bir işlem olarak tanımlanır. Bu nedenle, bir işlem "işlemin çıktısının iki adım öncesine ve işlemin çıktısının bir adım öncesine eklenmesine" benzer olabilir. Bu, atanan ve okunan değişkenlere sahip bir programdan çok bir Unix borusu gibidir.
Program, kontrolör RNN tarafından her seferinde bir işlem tarafından oluşturulur. Her adımda, kontrolör RNN, bir sonraki işlemin ne olması gerektiğinin olasılık dağılımını çıkaracaktır. Örneğin, bu olasılık simüle etmek için kullanılabilir: İlk adımda toplama yapmak istediğimizden oldukça emin olabiliriz ve sonra ikinci adımda çarpma mı yoksa bölme mi yapmamız gerektiğine karar vermek zor olacaktır, vb ...

Artık ortaya çıkan operasyonların dağılımı tarafımızca değerlendirilebilir. Her adımda bir işlem yapmıyoruz, ancak tüm işlemleri aynı anda yürütmek için yaygın olarak kullanılan dikkat tekniğini kullanıyoruz ve ardından bu işlemleri bir ağırlık olarak yapma olasılığımıza göre tüm çıktıların ortalamasını alıyoruz.
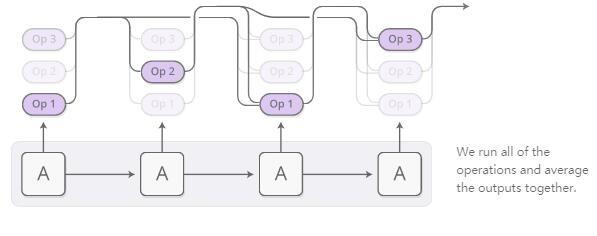
Türevi bu işlemlerle tanımlayabildiğimiz sürece, programın çıktısı olasılıksal olarak farklıdır. Daha sonra, bir kayıp fonksiyonu tanımlayabilir ve doğru cevabı veren bir program oluşturmak için sinir ağını eğitebiliriz. Bu şekilde, sinir ağı programcısı doğru program örnekleri olmadan program oluşturmayı öğrenir. Tek izleme bilgisi, programın üretmesi gereken dönüş değeridir.
Bu, sinir ağı programcısının temel fikridir, ancak makaledeki sürüm, aritmetik ifadeler hakkında değil, tablolarla ilgili soruları yanıtlar. Aşağıda bazı pratik ipuçları da vereceğiz:
-
Çoklu veri türleri: Sinir ağı programcısındaki birçok işlem, skaler değerlerin yanı sıra diğer veri türlerini de işler. Bazı işlemler, seçili tablo sütunlarının veya seçili hücrelerin çıktısını alır. Yalnızca aynı türdeki çıktılar birleştirilebilir.
-
Referans girişi: Sinir ağı programcılarının "Kaç şehrin nüfusu 1 milyondan fazla?" Gibi bir cevap vermelidir. Bu tür soruları cevaplamayı kolaylaştırmak için, bazı işlemler ağın cevapladıkları sorudaki sabitlere veya sütunlara başvurmasına izin verir. isim. Bu referans, bir işaretçi ağı gibi dikkat mekanizması nedeniyle oluşur.
Sinir ağı programcıları, sinir ağlarının program üretmesinin tek yolu değildir. Diğer bir iyi yöntem, birçok ilginç görevi yerine getirebilen, ancak denetleyici bilgi olarak doğru programı gerektiren sinir ağı programcısı-yorumlayıcısıdır.
Geleneksel programlama ve sinir ağları arasındaki boşluğu doldurmak için bu genel alanın çok önemli olduğuna inanıyoruz. Sinir ağı programcısı kesinlikle nihai çözüm olmasa da, ondan öğrenilecek birçok önemli ders olduğuna inanıyoruz.
Kod
Soru ve cevap için sinir ağı programlayıcısının en son sürümü (https://openreview.net/pdf?id=ry2YOrcge) yazarı tarafından açık kaynaklıdır ve bir TensorFlow modeli (https://github.com/tensorflow/models) olarak edinilebilir. / ağaç / ana / neural_programmer). Sinir ağı programcısı-yorumlayıcısının ayrıca Ken Morishita (https://github.com/mokemokechicken/keras_npi) tarafından yazılmış bir Keras sürümü vardır.
Genel kavrayış
Bir bakıma bir kağıt parçası tutan bir insan, kağıtsız bir insandan çok daha akıllıdır. Matematiksel sembolleri olan bir kişi çözemediği problemleri çözebilir. Bilgisayarları kullanmak inanılmaz başarılar elde etmemizi sağlar, aksi takdirde yeteneklerimizin çok ötesinde olurlar.
Genel olarak konuşursak, birçok ilginç zeka biçimi, insanın yaratıcı buluşsal sezgisi ile dil veya denklemler gibi bazı daha sezgisel ve somut medya arasındaki etkileşim gibi görünmektedir. Bazen araç, bizim için bilgileri depolayan, hata yapmamızı engelleyen veya sıkıcı bilgi işlem görevleri gerçekleştiren nesnel bir şeydir. Diğer durumlarda, ortam, zihnimizde manipüle ettiğimiz bir modeldir. Her halükarda, bu zeka için gereklidir.
Son zamanlarda, makine öğreniminin sonuçları, sinir ağlarının sezgisini diğer şeylerle birleştirerek bu tada sahip olmaya başladı. Yöntemlerden biri, insanların "sezgisel arama" dediği şeydir. Örneğin, AlphaGo'nun, Go'nun nasıl çalıştığına dair bir modeli var ve oyunun sinir ağı sezgisinin rehberliğinde nasıl oynanacağını araştırıyor. Benzer şekilde, DeepMath matematiksel ifadeleri manipüle etmek için sezgiyi karakterize etmek için sinir ağlarını kullanır. Bu makalede bahsettiğimiz "geliştirilmiş RNN", genelleme yeteneklerini geliştirmek için RNN'leri özel olarak tasarlanmış medyaya bağlamanın başka bir yoludur.
Medyayla etkileşim doğal olarak "bir dizi eylemde bulunmayı, gözlem yapmayı ve ardından başka eylemlerde bulunmayı" içerir. Burada büyük bir zorlukla karşı karşıyayız: Hangi eylemin yapılması gerektiğini nasıl öğreneceğiz? Bu, pekiştirici bir öğrenme problemine benziyor ve kesinlikle bu yaklaşımı benimseyebiliriz. Ancak, pekiştirmeli öğrenme teknolojisi aslında sorunun en karmaşık versiyonudur ve bu çözümün kullanılması zordur. Dikkat mekanizmasının inceliği, tüm eylemleri farklı derecelerde bazı pozisyonlarda gerçekleştirerek bu sorunu çözmemizi kolaylaştırmasıdır. Bunun nedeni, Nöral Turing Makineleri gibi depolama yapıları tasarlayabilmemizdir, böylece ince işlemler gerçekleştirebilir ve sorunu azaltabiliriz. Pekiştirmeli öğrenme, tek bir çözüm yolunu seçmemizi ve ondan öğrenmeye çalışmamızı sağlar. Dikkat mekanizması, seçilen her kesişme noktasında tüm yönlerde eylemler gerçekleştirir ve son olarak her yolun sonuçlarını birleştirir.
Dikkat mekanizmasının temel dezavantajlarından biri, her adımda "aksiyon" almamız gerektiğidir. Nöral Turing Makinesinde depolama biriminin artırılması gibi işlemler yapacağımız için bu, hesaplama maliyetinin doğrusal olarak artmasına neden olacaktır. Akla gelebilecek çözüm, dikkat modelinizi seyrek hale getirmektir, böylece depolama biriminin yalnızca bir parçası üzerinde işlem yapmanız gerekir. Ancak, bu yine de zordur çünkü dikkat modelinizi depolama biriminin içeriğine bağlı hale getirmek isteyebilirsiniz ve bunu yapmak, her bir depolama birimine bakmanıza neden olur. Örneğin bu sorunu çözmek için sağduyulu bazı ön çalışmalar olduğunu gözlemledik, ancak keşfedilecek çok iş var gibi görünüyor. Doğrusal olmayan zaman karmaşıklığında böyle bir dikkat mekanizması çalışmasını gerçekten yapabilirsek, bu model çok güçlü hale gelecektir!
Gelişmiş tekrarlayan sinir ağının ve dikkat mekanizmasının altında yatan teknoloji çok heyecan verici! Bu alanda daha fazla yeni teknoloji bekliyoruz!
Referanslar
1. LSTM Ağlarını Anlama ( Olah, C., 2015.
2. Neural Turing Machines Graves, A., Wayne, G. ve Danihelka, I., 2014. CoRR, Cilt abs / 1410.5401.
3. Gösterin, katılın ve anlatın: Görsel dikkat ile sinirsel resim yazısı oluşturma Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhutdinov, R., Zemel, RS ve Bengio , Y., 2015. arXiv preprint arXiv: 1502.03044, Cilt 2 (3), s. 5. CoRR.
4. Nöral GPU'lar Algoritmaları Öğreniyor Kaaiser, L. ve Sutskever, I., 2015. CoRR, Vol abs / 1511.08228.
5. Takviye Öğrenme Nöral Turing MakineleriZaremba, W. ve Sutskever, I., 2015. CoRR, Cilt abs / 1505.00521.
6. Neural Random-Access Machines Kurach, K., Andrychowicz, M. ve Sutskever, I., 2015. CoRR, Cilt abs / 1511.06392.
7. Sınırsız Hafıza ile Dönüştürmeyi Öğrenme Grefenstette, E., Hermann, K.M., Suleyman, M. and Blunsom, P., 2015. Advances in Neural Information Processing Systems 28, pp. 1828-1836. Curran Associates, Inc.
8. Yığınla Arttırılmış Tekrarlayan Ağlarla Algoritmik Modellerin Çıkarılması Joulin, A. ve Mikolov, T., 2015. Nöral Bilgi İşlem Sistemlerindeki Gelişmeler 28, s. 190-198. Curran Associates, Inc.
9. Bellek Ağları Weston, J., Chopra, S. ve Bordes, A., 2014. CoRR, Cilt abs / 1410.3916.
10. Bana Her Şeyi Sor: Doğal Dil İşleme için Dinamik Bellek Ağları Kumar, A., Irsoy, O., Su, J., Bradbury, J., English, R., Pierce, B., Ondruska, P., Gulrajani, I. ve Socher, R., 2015. CoRR, Cilt abs / 1506.07285.
11. Bahdanau, D., Cho, K. ve Bengio, Y., 2014. arXiv ön baskı arXiv: 1409.0473.
12. Listen, Attend and Spell Chan, W., Jaitly, N., Le, Q.V. and Vinyals, O., 2015. CoRR, Cilt abs / 1508.01211.
13. Yabancı dil olarak dilbilgisi Vinyals, O., Kaiser, L., Koo, T., Petrov, S., Sutskever, I. ve Hinton, G., 2015. Nöral Bilgi İşleme Sistemlerinde Gelişmeler, s. 2773 2781.
14. Sinirsel Konuşma Modeli Vinyals, O. ve Le, Q.V., 2015. CoRR, Cilt abs / 1506.05869.
15. Tekrarlayan Sinir Ağları Graves için Uyarlanabilir Hesaplama Süresi, A., 2016. CoRR, Vol abs / 1603.08983.
16. Sinir Programcısı: Gradient Descent Neelakantan, A., Le, Q.V. ve Sutskever, I., 2015. CoRR, Vol abs / 1511.04834 ile Gizli Programları Teşvik Etmek.
17. İşaretçi ağları Vinyals, O., Fortunato, M. ve Jaitly, N., 2015. Nöral Bilgi İşleme Sistemlerinde Gelişmeler, s. 2692-2700.
18. Nöral Programcı-TercümanlarReed, S.E. ve Freitas, N.d., 2015. CoRR, Cilt abs / 1511.06279.
19. Derin sinir ağları ve ağaç arama ile Go oyununda ustalaşmak Silver, D., Huang, A., Maddison, CJ, Guez, A., Sifre, L., Driessche, Gvd, Schrittwieser, J., Antonoglou, I. , Panneershelvam, V., Lanctot, M., Dieleman, S., Grewe, D., Nham, J., Kalchbrenner, N., Sutskever, I., Lillicrap, T., Leach, M., Kavukcuoğlu, K. , Graepel, T. ve Hassabis, D., 2016. Nature, Cilt 529 (7587), s. 484-489. Nature Publishing Group. DOI: 10.1038 / nature16961
20. Öncül Seçimi için DeepMath-Derin Dizi Modelleri Alemi, A.A., Chollet, F., Irving, G., Szegedy, C. ve Urban, J., 2016. CoRR, Vol abs / 1606.04442.
21. Hiyerarşik Dikkatli Hafızayla Etkili Algoritmaları Öğrenme Andrychowicz, M. ve Kurach, K., 2016. CoRR, Vol abs / 1602.03218.
Leifeng.com AI Technology Review tarafından derlenen damıtma yoluyla