Pekiştirmeli öğrenmede her yerde bulunan Bellman optimallik denkleminin arkasındaki matematik hakkında ne kadar bilginiz var?

AlphaStar ve AlphaGO oyunlarında, pekiştirmeli öğrenme dünyaca ünlü bir başarıya ulaştı. Bu başarıların arkasındaki temel, Markov Karar Sürecini (MDP) çözmek için kullanılan Bellman Optimality Equation'dur.
Bellman denkleminin pekiştirmeli öğrenmede (RL) her yerde olduğu söylenebilir ve bu denklemin matematiksel temelini anlamak, RL algoritmasının çalışma prensibini anlamak için gereklidir. Markov karar sürecini çözmek için Amerikalı uygulamalı matematikçi Richard Bellman (Richard Bellman) tarafından önerildi.
Metin, matematiksel titizliği kaybetmeden anlaşılması kolay olan bu denklemin ardındaki matematiksel temele ayrıntılı bir giriş sağlar.
İyi makaleler takdir edilir, aşağıdaki tercüme edilmiş orijinal metinler sizinle paylaşılır:
AlphaStar ve AlphaGO oyunlarında, pekiştirmeli öğrenme dünyaca ünlü bir başarıya ulaştı. Bu başarıların arkasındaki temel, Markov karar süreçlerini (MDP) çözmek için kullanılan Bellman optimallik denklemidir.
Bellman Optimality Denklemi
Bellman optimallik denklemi, dinamik programlama (DP) algoritması ile çözülebilen özyinelemeli bir denklemdir.Bu denklemi çözerek, optimal değer fonksiyonu ve optimal strateji bulunabilir.
1. Bu makaleye dahil edilecek matematiksel semboller
-
S durum uzayı anlamına gelir.
-
V, değer işlevi anlamına gelir.
-
V *, optimum değer işlevini temsil eder.
-
V (s), durum s olduğunda değer fonksiyonunun değerini temsil eder.
-
stratejiyi belirtir.
-
* optimum stratejiyi temsil eder.
-
(s), durum s olduğunda stratejisi tarafından gerçekleştirilen eylemi döndürür.
-
P, geçiş olasılığı matrisini temsil eder.
-
A, olası tüm eylemler kümesini temsil eder.
2. Ön bilgi
Makalenin anlaşılmasını kolaylaştırmak için elimden gelenin en iyisini yapmaya çalışsam, ancak uzunluğu ile sınırlı ve aynı zamanda analizin titizliğini sağlamak için hala okuyucunun aşağıdaki ön koşullara sahip olduğunu varsayıyorum:
-
Markov Karar Süreci (MDP)
-
Bellman denklemi ve bu denklemi çözmek için yinelemeli yöntemin nasıl kullanılacağı
-
RL temeli, değer fonksiyonu, ödül, strateji, indirim faktörü vb. Kavramlar
-
Lineer Cebir
-
Vektör türetme
Üç, Bellman denkleminin ana noktalarını anlamak için
RL ve MDP hakkında biraz araştırma yaptıysanız, böyle bir ifadeyle karşılaşmış olmalısınız: "Her MDP için, her zaman diğer tüm stratejilerden daha iyi veya eşit olan en az bir strateji vardır."
Sutton ve Barto'nun klasik ders kitaplarında ve David Silver'ın ders dizilerinde bu ifadeleri okumak veya duymak çok sezgisel ve apaçık görünüyor. Bununla birlikte, daha derinlemesine çalışmalı ve bunun neden daha spesifik bir şekilde söylendiğini anlamalıyız (tabii ki, yazar matematiksel olarak özeldir, ancak sezgisel olarak sezgiseldir). Bu nedenle bu yazımda aşağıdaki teoremleri matematiksel olarak ispatlayacağım:
Herhangi bir sınırlı MDP için, optimal bir strateji vardır * ve diğer tüm olası stratejiler bu stratejiden daha iyi olmayacaktır.
En iyi stratejiyi aramadan önce, strateji dizisini anlamamız gerekir. Yani, bir stratejinin (1) başka bir stratejiden (2) daha iyi olduğunu ne zaman düşünürüz?
Durum uzayındaki her durum için, bu durumda 1 kullanılarak türetilen değer fonksiyonunun değeri, bu durumda 2 kullanılarak türetilen değer fonksiyonunun değerinden büyük veya ona eşitse, o zaman 1 stratejisinin 2 stratejisinden daha iyi olduğu söylenebilir. Matematiksel olarak şu şekilde yazılabilir:
Stratejiler arasında karşılaştırma
Artık stratejileri nasıl karşılaştıracağımızı bildiğimize göre, her zaman diğer tüm stratejilerden daha iyi bir strateji olduğunu kanıtlamamız gerekiyor. Bellman optimal operatörünün L-sonsuz norm metriğiyle gerçek sayıların tam metrik uzayında kapalı bir eşleme olduğunu kanıtlayarak bu noktayı kanıtlamak için Banach'ın sabit nokta teoremini kullanacağız. Bu nedenle, önce sabit nokta probleminden ve Cauchy dizisinin tam metrik uzayından bahsediyoruz.
Son paragraf korkutucu gelebilir, ancak her temel terimin anlamını anladığımızda, çok kolay ve sezgisel hale gelecektir. Bu yüzden korkmayın! Kalın yazılmış terimleri üst paragrafta tek tek tartışacağız. Korkularımızın üstesinden gelelim ve her kavramı aşağıdan yukarıya bir yaklaşımla öğrenelim:
1. Sabit nokta sorunuÇoğumuzun denklemlerin köklerini bulma sorununa aşina olduğuna inanıyorum. F (x) = 0 fonksiyonunun olduğu x noktasını buluruz. Sabit nokta probleminde, x noktasını f (x) = x olacak şekilde çözeriz.
Adından da anlaşılacağı gibi, x noktası sabit bir noktadır, yani f (x) fonksiyonu ona uygulansa bile, değeri değişmeyecektir. Başka bir g (x) = f (x) -x = 0 fonksiyonu oluşturarak, sabit nokta problemi bir denklemin köklerini bulma problemine dönüştürülebilir.
Aslında, bir denklemin kökünü bulma problemi, sabit bir nokta bulma problemine de geri dönüştürülebilir. Ancak (belirli koşullar altında) sabit nokta problemini çözmek daha kolaydır, bu da sabit nokta problemini çok ilginç ve kullanışlı hale getirir (hesaplama yükünden tasarruf sağlar).
Sabit nokta problemini çözmek için, başlangıç değeri olarak rastgele bir x seçin ve f (x) 'i sonsuz bir şekilde tekrar tekrar uygulayın. "Fonksiyon yakınsak" ise, sabit nokta problemine bir çözüm bulacaksınız.
Matematiksel olarak konuşursak, bu çok basit, önce bir notasyon sunalım:
Fn (x) notasyonu, fonksiyonun x noktasında sürekli olarak n kez uygulanması anlamına gelir.
Şimdi, eğer işlev yakınsaksa, belirli bir değere, örneğin x * 'e yakınsaması gerekir. Aşağıdaki argüman, bu x * değerinin gerçekten de sabit nokta probleminin çözümü olduğunu göstermektir:
Rasgele bir x0 değeri seçelim ve f (.) Fonksiyonunu x * elde etmek için sonsuza kadar uygulayalım ve ardından aşağıdaki şekilde gösterildiği gibi sabit nokta problemini çözmek için kullanalım:
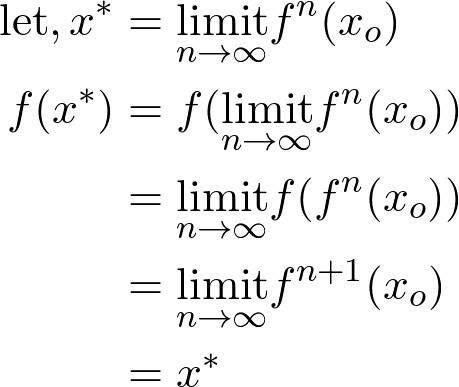
Sabit nokta problemlerini çözün
Bunun arkasındaki sezgi basittir, eğer bir fonksiyon belirli bir noktada birleşirse, o yakınsama noktasındaki fonksiyonun değeri yakınsama noktasının kendisidir. Bu nedenle, bu yakınsama noktası sabit noktadır.
Aşağıdaki kod aracılığıyla fonksiyonun sabit bir noktaya yakınsadığı deneyimlerden de gözlemlenebilir, kod bağlantısı aşağıdaki gibidir:
-
https://gist.github.com/TimeTraveller-San/8e37399d4740928a258f395413bde2e7/raw/c48fecd50fa29634eea144917f92787c3ccd7bf3/Fixed%20point%20problem.ipynb
Bir metrik uzay yalnızca bir metriğin tanımlandığı bir koleksiyondur ve bir metrik, koleksiyondaki herhangi iki öğe arasındaki mesafeyi tanımlar. Örneğin, Öklid uzayı bir metrik uzaydır ve mesafesi Öklid mesafesi olarak tanımlanır. Bu nedenle, metrik uzay M (X, d) olarak ifade edilebilir, burada X bir küme ve d bir metriktir. Bir metrik d aşağıdaki dört özelliği karşılamalıdır:
Birlik: d (x, x) = 0
Negatif olmama: d (x, y) > 0
Simetri: d (x, y) = d (y, x)
Üçgen eşitsizliği: d (x, z) d (x, y) + d (y, x)
3. Cauchy dizisiMetrik uzay (X, d) için, X (x1, x2, x3 .... xn) kümesindeki elemanların dizisi Cauchy dizisidir, eğer herhangi bir pozitif gerçek sayı için, aşağıdaki denklemin olduğu şekilde bir N tamsayısı vardır Kurulmuş:
Cauchy dizisi
Buradaki matematiksel açıklama biraz karmaşıktır ve yeterince sezgisel değildir (ancak gerçek tanım böyledir). Basit bir deyişle, bir dizi metrik uzay elemanları belirli bir noktada birleşiyorsa (belirli bir noktaya sonsuz derecede yakınlarsa), bu dizi Cauchy dizisidir.
4. Metrik Boşluğu TamamlayınX kümesindeki öğelerden oluşan olası her Cauchy dizisi, X kümesindeki öğelere yakınlaşırsa, metrik uzay (X, d) tamamlanır. Başka bir deyişle, set öğelerinden oluşan her bir Cauchy dizisinin sınırına karşılık gelen öğe de sete aittir, bu nedenle "tam" olarak adlandırılır.
5. Sıkıştırılmış görüntüMetrik uzay (X, d) elemanlarında tanımlanan fonksiyon (operatör veya harita), sabit bir varsa sıkıştırılmış bir görüntüdür (veya sıkıştırıcıdır).