Hangi sesli asistanın en çok "yabancı dil" bildiğini biliyor musunuz?
En yerelleştirilmiş ses asistanının hangisi olduğunu biliyor musunuz? Vocalize.ai adlı bir yapay zeka girişimi test yaptı, Google, Apple ve Amazon gibi akıllı ses asistanlarını karşılaştırdı ve bazı ilginç şeyler buldu.

Örneğin, üç ses asistanı Amerikan aksanı ve Hint aksanıyla İngilizceyi çok iyi tanıyabilir, ancak Siri ve Alexa'nın doğruluğu, Çince aksanları tanıdıklarında büyük ölçüde azalır.
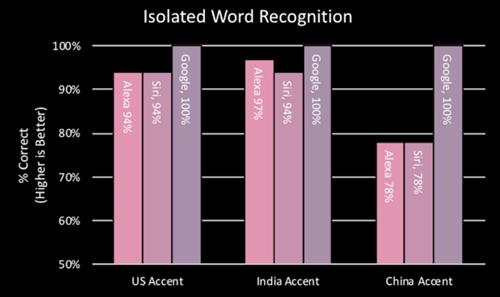
Ses asistanları için, aynı dilin farklı aksanlarını tanımak zaten bir zorluktur ve yeni bir dil "öğrenmek" daha da zordur.
Örneğin, bu sonbahara kadar, Samsungun Bixbyi Almanca, Fransızca, İtalyanca ve İspanyolcaya destek ekleyecek. Bu seslerin toplamı 600 milyondan fazla kullanıcıya ulaştı; Microsoftun Cortananın İspanyolca ve Fransızcayı desteklemesi uzun yıllar aldı. Ve Portekizce.
Yapay zekanın büyük atılımlar yaptığı ve hızla geliştiği günümüzde, ses asistanlarının gelişimi neden bu kadar yavaş?
Bir sesli asistanın yeni bir sesi desteklemesi neden bu kadar zor?
Sesli asistanların esas olarak bir dili "öğrenmesi" gerekir İki ana konu: ses tanıma ve ses sentezi.
Ses tanıma iki kısma ayrılır: İlk adım konuşmayı metne dönüştüren konuşma tanımadır. İkinci adım anlamsal anlamadır. İlgili teknoloji esas olarak doğal dil işlemedir.
Derin öğrenmenin atılımı, yapay zekanın son yıllarda hızla gelişmesinin önemli bir nedenidir. Şu anda, konuşma araştırması alanı esas olarak derin sinir ağlarını kullanıyor - insan sinirleri gibi, sürekli olarak kendi kendine öğrenip ilerleyebilen hiyerarşik bir matematiksel işlev.

Bu zaten çok büyük bir gelişme. Geçmişte, otomatik konuşma işleme teknolojisi (ASR) ifadelerdeki kelime kombinasyonlarının olasılığını hesaplamak için çoğunlukla manuel olarak ayarlanmış istatistiksel modellere dayanıyordu.Derin sinir ağları sadece hata oranını düşürmekle kalmıyor, aynı zamanda insan denetimi ihtiyacını da büyük ölçüde önlüyordu.
Ancak temel dil anlayışı yeterli olmaktan uzaktır ve yerelleştirme hala büyük bir zorluktur. Bazı teknisyenler, şu anda ele alınacak niyete göre, yeni bir dilin bir sorgu anlama modülü oluşturmasının 30 ila 90 gün sürdüğünü ortaya çıkardı. Başlangıçta da belirtildiği gibi, aynı dilin aksanını tanımak bile büyük bir zorluktur.
Farklı diller daha farklıdır. Örneğin, dilbilgisi düzeyinde, sıfatlar genellikle İngilizce'de isimlerden önce görünür ve zarflar ya önce ya da sonra gelebilir. Sesli asistanlar için, "deniz yıldızı" kelimesi gibi karıştırılması kolaydır. Konuşmadan metne dönüştürme motoru, "yıldız" ı "balık" ın bir sıfatı olarak kolayca anlayabilir.

Konuşmayı metne dönüştürüp anladıktan sonra, sesli asistanın da insan sesiyle cevap vermesi gerekir.
Geleneksel konuşma sentezi teknolojisi temelde bir sentez motoru ve önceden girilmiş bir konuşma veri tabanı içerir Sentez motoru, metni konuşmaya dönüştürmek için konuşma veri tabanında eşleşen telaffuzları bulmak için bilgisayar yazılımı kullanır. Ancak bu "yapay ses" çok tutarsız ve kulağa doğal değil. Daha fazla kelimeyi kapsamak için, geleneksel konuşma veritabanları genellikle çok büyüktür.
Mevcut konuşma sentezi teknolojisi, sesleri yeniden oluşturmak ve ardından bunları kelimeler ve cümleler halinde birleştirmek için matematiksel modeller kullanan TTS (Metinden Konuşmaya) olarak adlandırılır. En son TTS, "eğitim" sürecinde daha güçlü hale gelebilecek derin öğrenmeyi de beraberinde getiriyor.
Şu anda, konuşma tanıma ve anlamsal anlama ile karşılaştırıldığında, konuşma sentezi teknolojisi çok daha olgun. Çin'deki büyük internet şirketleri de operasyonlarında sıklıkla konuşma sentezi teknolojisini kullanır.
Başlıca ses asistanları hangi dilleri destekliyor?
Google Asistan
Google'ın sesli asistanı çoğu dili destekler. Şu anda 80 ülkede 30 dili desteklemektedir.
2018'de Google Asistan tarafından geçildikten sonra, Apple'ın Siri'si Şu anda desteklenen dillerin sayısı ikinci sırada. 36 ülkede 21 dil içerir:
Microsoft'un Cornata
- Basitleştirilmiş Çince
- İngilizce (Avustralya, Kanada, Yeni Zelanda, Hindistan, Birleşik Krallık, Amerika Birleşik Devletleri)
- Fransızca (Kanada, Fransa)
- Almanca
- İtalyan
- Japonca
- Portekiz Brezilyası)
- İspanyolca (Meksika, İspanya
Amazon'un Alexa'sı
- İngilizce (Avustralya, Kanada, Hindistan, Birleşik Krallık ve Amerika Birleşik Devletleri)
- Fransızca (Kanada, Fransa)
- Almanca
- Japonca (Japonya)
- İspanyolca (Meksika, İspanya)
Samsung'un Bixby'si
- ingilizce
- Çince
- Almanca
- Fransızca
- İtalyan
- Koreli
- İspanyol
Gelecekte nasıl gelişecek?
Konuşma tanıma, anlamsal anlama ve konuşma sentezi alanlarında, ilerlemelerinin ana nedeni derin öğrenmenin tanıtılmasıdır.
Gelecekte, makine öğrenimine daha fazla güvenmek, konuşma alanında araştırma yapmak için daha büyük yardımcı olabilir.
Yapay zeka şirketi Clinc'in başkan yardımcısı Himi Khan, "Çoklu dil desteğinin işlenmesine farklı gramer kuralları eşlik ediyor. Bu aynı zamanda şu anda ana zorluklardan biridir. Konuşma işleme modeli bu gramer kurallarını dikkate almalı ve bunlara uyum sağlamalıdır" dedi. İşleme modeli, cümleleri toplar ve bir anlamda dilbilgisini tanır ve dilbilgisinin nasıl yorumlanacağını belirlemek için kurallar oluşturarak, konuşma parçası etiketleme gerçekleştirir. "

Efsanevi Babil Kulesi, Tanrı insan dilini bozduğu için askıya alındı
Gelecekte, gerçek bir sinir ağı yığını varsa - dil kitaplıklarına, anahtar kelimelere ve sözlüklere çok fazla güvenmeyen bir sistem varsa, dile odaklanma, yerleştirme işleminden sonra kelime gömme ve bağlantı modeline dönüştürülebilir. Ardından, "neredeyse tüm dillerde konuşma tanımaya uygulanabilir."
Bu sadece bir araştırma yönü. Ancak genel olarak, manuel olarak tanımlanan tanıma modellerine çok fazla güvenmek yerine, makine öğrenimi için bir külliyat olarak büyük miktarda gerçek konuşmayı kullanmak, sesli asistanların daha "akıllı" olmalarına etkili bir şekilde yardımcı olabilir.