Uyarlanabilir diferansiyel evrim aşırı öğrenme makinesine dayalı plaka tanıma algoritması
Wen Wu 1, 2, Qiao Longhui 1, He Peng 1
(1. Chongqing Posta ve Telekomünikasyon Üniversitesi, Chongqing 400065; 2. Chongqing Xinke Design Co., Ltd., Chongqing 400065)
Mevcut plaka tanıma algoritmalarındaki yavaş model eğitimi ve düşük karakter tanıma doğruluğu problemlerine yönelik olarak, uyarlanabilir diferansiyel evrim aşırı öğrenme makinesine dayalı bir plaka tanıma algoritması incelenmiştir. Plaka alanını algılamak için kenar algılama ve renk konumlandırmanın avantajlarını kapsamlı bir şekilde kullanın, ardından plaka alanını bölümlere ayırmak için geliştirilmiş dikey projeksiyon yöntemini kullanın ve son olarak, karakter tanıma için uyarlanabilir diferansiyel evrim aşırı öğrenme makinesini kullanın. Araştırma sonuçları, önerilen algoritmanın hızlı eğitim hızı ve yüksek karakter tanıma oranı avantajlarına sahip olduğunu ve karmaşık trafik sahnelerine uygulanabileceğini göstermektedir.
Plaka konumu; karakter segmentasyonu; dikey izdüşüm; karakter tanıma; uyarlamalı diferansiyel gelişim
Çin Kütüphanesi Sınıflandırma Numarası: TP391
Belge tanımlama kodu: Bir
DOI: 10.16157 / j.issn.0258-7998.2017.01.035
Çince alıntı biçimi: Wen Wu, Qiao Longhui, He Peng. Uyarlanabilir diferansiyel evrim aşırı öğrenme makinesine dayalı plaka tanıma algoritması.Elektronik Teknoloji Uygulaması, 2017, 43 (1): 133-136, 140.
İngilizce alıntı biçimi: Wen Wu, Qiao Longhui, He Peng. Kendi kendine uyarlanabilir evrimsel aşırı öğrenme makinesine dayalı plaka tanıma. Application of Electronic Technique, 2017, 43 (1): 133-136, 140.
0 Önsöz
Akıllı ulaşım sisteminin önemli bir parçası olan plaka tanıma sistemi, genellikle trafik koşullarını izlemek, araç davranışını denetlemek için kullanılır ve ayrıca otopark erişim yönetimi için de kullanılabilir. Plaka tanıma teknolojisi son on yılda büyük başarılar elde etmiş ve birçok pratik durumda uygulanmış olsa da, karmaşık sahnelerin görüntülerinden plakaları tanımak hala zor bir iştir.
Plaka tanıma genellikle üç bölümden oluşur: plaka konumu, karakter segmentasyonu ve karakter tanıma. Plaka konumu için iki ana uygulama yöntemi vardır: biri plaka alanının renk bilgisine dayanır ve plaka, plaka alanının belirli renk bilgisi kombinasyonuna göre yerleştirilir; diğeri, plaka alanının kenar bilgisine dayalı olarak kenar veya doku bilgisine dayanır. Alan, plakayı algılayacak kadar temiz. İlk yöntem, aydınlatma koşullarına ve kamera ayarlarına duyarlıdır ve ikinci yöntem, plaka şiddetli bir şekilde azaldığında, kenarları tespit edemeyecek ve konumlandırma hatasına neden olacaktır. Projeksiyon yöntemi, bağlı alan yöntemi ve şablon eşleştirme yöntemi, karakter segmentasyonu elde etmenin ana yollarıdır. Projeksiyon yöntemi, karakterlerin ışıktan kolayca etkilenen tam ve gürültüsüz olmasını gerektirir. Bağlantılı alan yöntemi, plakanın eğimine duyarlı değildir, ancak karakter kırılması ve karakter yapışması ile başa çıkmak için kullanılamaz. Yaygın olarak kullanılan karakter tanıma yöntemleri şunlardır: sinir ağı (BPNN ve CNN), SVM ve şablon eşleştirme yöntemi. Geleneksel sinir ağları ve SVM, karakter tanımada kullanıldığında yüksek bir doğruluk oranına sahiptir, ancak parametreler doğru seçilmezse, yavaş öğrenme hızı, aşırı uyum ve yerel optimizasyon gibi kusurlar ortaya çıkacaktır. Şablon eşleştirme yöntemi basit ve pratiktir, ancak karakterler deforme olduğunda veya sıkıştığında şablon eşleştirme yönteminin tanıma oranını azaltacaktır.
Yaygın olarak kullanılan diğer plaka tanıma algoritmalarıyla karşılaştırıldığında, bu makalede kullanılan yöntem aşağıdaki noktalarda iyileştirmeler yapmıştır: (1) Renk konumlandırma ve kenar algılama avantajlarının kapsamlı kullanımı, yöntemlerden birini tek başına kullanmanın eksikliklerinin üstesinden gelinmesi; (2) dikey Projeksiyon yöntemi geliştirildi, önce kaba bölümleme ve ardından karakter yapışması ve kırılması sorunlarını etkili bir şekilde çözen hassas bölümleme; (3) Modeli eğitmek için SaE-ELM kullanmak eğitim süresini kısaltır ve karakter tanıma oranını iyileştirir.
1 Plaka konumlandırma
Bu belge, plaka konumu için geliştirilmiş bir algoritma önermek için plakanın alanını, dokusunu, rengini, en boy oranını ve diğer özelliklerini birleştirir. Spesifik uygulama adımları aşağıdaki gibidir:
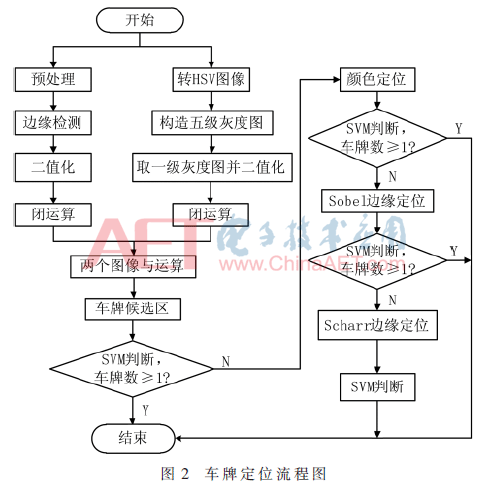
(1) Renkli plaka görüntüsünü Şekil 1 (a) 'da gösterildiği gibi girin, ön işlemden sonra gri resmi alın (Gauss bulanıklığı ve gri tonlama) ve ardından plaka görüntüsünün dikey kenarını elde etmek için Sobel operatörünü kullanın (ön egzoz delikleri nedeniyle, araba Yatay kenarların tespiti nihai bağlantı sonuçlarını etkiler) ve ardından kenar algılama görüntüsünü ikilileştirmek ve morfolojik kapatma işlemleri gerçekleştirmek için Otsu yöntemini kullanın. Şu anda, Şekil 1 (b) 'de gösterildiği gibi birçok plaka adayı alan elde edilebilir.
(2) Renkli girdi görüntüsünü HSV görüntüsüne dönüştürün Mevcut pikselin H, S ve V bileşenleri Tablo 1'de gösterilen maviye karşılık gelen H, S ve V bileşenlerini karşılıyorsa, gri değeri 255 olarak ayarlanır. Benzer şekilde, sarının her bir bileşeni karşılanırsa, gri değeri 200 olarak ayarlanır; beyazın her bileşeni karşılandığında gri değeri 150 olarak ayarlanır; siyahın her bileşeni karşılandığında gri değeri 100 olarak ayarlanır; diğerleri 0 olur. Oluşturulan beş seviyeli gri tonlamalı görüntü Şekil 1 (c) 'de gösterilmektedir. Sırayla her gri tonlamalı görüntüyü alın ve sırasıyla ikilileştirme ve kapatma işlemlerini gerçekleştirin. Mavi bileşeni örnek olarak alırsak, 255 eşiktir ve 255 dışındaki tüm gri değerler, Şekil 1 (d) 'de gösterildiği gibi mavi bileşen aday alanını elde etmek için 0'a ayarlanır ve diğer bileşenlerin işlenmesi analoji ile çıkarılabilir.

(3) Şekil 1 (e) 'yi elde etmek için Şekil 1 (b) ve Şekil 1 (d)' deki AND işlemini yapın, aday alanların sayısı büyük ölçüde azaltılır ve ardından plakanın alanı ve en boy oranı parçaları filtrelemek için kullanılabilir. Sahte plakalar için, SVM sınıflandırıcı nihayet, Şekil 1 (f) 'de gösterildiği gibi gerçek plakayı almak için her aday plakayı sınıflandıracak ve değerlendirecektir. Genel sahnedeki plaka için, plaka alanı yukarıdaki 3 adımdan sonra konumlandırılabilir. Ancak bazı özel sahneler için, adım (1) veya adım (2) farklı derecelerde başarısız olabilir ve bu da kötü nihai konumlandırma etkisine neden olabilir. Buradaki çözüm, aday plakaları değerlendirmek için SVM'yi kullanmaktır.SVM kararının sonucu 1'den büyükse, konumlandırma sona erer. Aksi takdirde, yeniden konumlandırma için renk konumlandırma veya kenar algılama kullanın.
Kapalı çalışma sırasında, plaka yanlışlıkla iki bölüme ayrılabilir. Bunun nedeni, plakada ikinci veya üçüncü konumda göze çarpmayan dikey kenarlara sahip bazı karakterler ("E", "1" vb.) Olmasıdır. Çözüm, plaka alanını genişletmek ve ardından genişletme alanını yeniden gerçekleştirmektir. Kenar algılama. Düşük ışıklı görüntüler için, Sobel operatörünün kullanılması, net olmayan veya eksik kenar çıkarma sorununa neden olabilir.Bunun yerine kenarları çıkarmak için Scharr operatörünü kullanabilirsiniz. Tam konumlandırma akış şeması Şekil 2'de gösterilmiştir. Bu yazıda kullanılan konumlandırma yöntemi birçok faktörü entegre eder ve iyi bir sağlamlığa sahiptir.
2 karakter segmentasyonu
2.1 İlk segmentasyon
Geleneksel projeksiyon yöntemi karakterleri böldüğünde, karakterlerin eksiksiz olması ve gürültü paraziti olmaması gerekir.Bu durumda, ikili görüntünün dikey izdüşüm eğrisi net tepe ve vadilere sahip olacaktır ve karakter bölümleme noktaları, tepe ve çukurların atlama konumlarına göre belirlenebilir. Gürültünün ve ışığın etkisinden dolayı, plakanın dikey izdüşümünün tepeleri ve çukurları çoğu zaman açık değildir Şekil 3, şiddetli gürültüye sahip plakayı ve dikey projeksiyon eğrisini göstermektedir.
Analizden sonra, karakterlerin izdüşüm eğrilerinin çoğu tek tepe noktaları, birkaçı çift tepe ve üçlü tepe noktasıdır, örneğin: H, M ve kırık karakterler çift tepe ve Sichuan üçlü tepe noktasıdır. Dikey projeksiyon yöntemini geliştirmek için bu özelliği kullanma adımları aşağıdaki gibidir:
(1) Plakanın ikili görüntüsünü yatay olarak tarayın ve karakter alanındaki atlama sayısının 14'ten az olmadığı deneyimine dayalı olarak üst ve alt kenarlıkları ve perçinleri kaldırın. CharWidth = 2charHeight tek karakter yüksekliği olan charHeight karakterini bulun.
(2) Plaka ikili görüntüsünü sütunlarda tarayın ve her sütundaki beyaz piksel sayısını sayın. Projeksiyon eşiği eşik değerini ayarlayın, dikey projeksiyonu tamamlayın ve projeksiyon sonucunu arrayTotal dizisine kaydedin.
(3) Karakter sınıfı oluşturun Karakter ve dinamik bağlantılı liste listCharacter Karakterin başlangıç noktası başlangıç olarak işaretlenir, merkez noktası centerPoint ve bitiş noktası da bitiş noktasıdır. Scan arrayTotal array, when arrayTotal > 0arrayTotal = 0, geçerli karakter genişlik = bitiş-başlangıç karakterini hatırlayın. Sırayla aşağıdaki adımları uygulayın: 2charWidth ise < Genişlik < 3charWidth, 2 karakterin birbirine yapıştırıldığı ve projeksiyonun orta noktasının bölmek için kullanıldığı anlamına gelir; 3charWidth ise < Genişlik < 4charWidth yapıştırılmış 3 karakterdir ve segmentasyonun konumu charWidth'e göre belirlenir. Genişlik + genişlik ise < charWidth, aynı zamanda iki karakter arasındaki boşluk (12/45) charWidth'den az ise karakterin kırıldığı ve karakterlerin birleştirilmesi gerektiği belirlenir. Genişlik ise < 0.5charWidth < genişlik, projeksiyon değeri 0.8char'dan büyük olan piksellerin sayısı Genişlik olarak yükseklik num'dir. Num, önceden ayarlanmış eşikten düşük olduğunda, mevcut karakter bir gürültü noktası olarak değerlendirilir, aksi takdirde "1" sayısı olarak değerlendirilir.
(4) Bağlantılı liste karakterine karakter yazmak için (3) numaralı adımı tekrarlayın. Çapraz sınırın sağ ucuna ve listCharacter'deki karakter sayısı 7'den az olmayana kadar.
2.2 Hassas segmentasyon
Yukarıdaki adımlar, plaka karakterlerinin ön segmentasyonunu tamamlar ve karakter kırılması ve yapışma sorununu çözer. Bununla birlikte, plakanın sol ve sağ kenarlarından hala parazit vardır, bu nedenle plakanın sol ve sağ kenarları, plaka karakterlerinin başlangıç ve bitiş konumları değildir. Bu nedenle, doğru segmentasyonu tamamlamak için karakter koordinat değerini önceki bilgilere göre değiştirmek gerekir. Spesifik süreç aşağıdaki gibidir:
(1) listCharacter'de N karakter sayısını ve karşılık gelen Wi genişliğini sayın ve ortalama değeri Wa ve genişliğin standart sapması Ws'yi bulun.
Wi memnun değilse | Wi-Wa | < Ws, listCharacter'den kaldırın, kalan karakterler için Wa ve Ws'yi bulun ve tüm Wi karşılayana kadar döngü yapın | Wi-Wa | < Ws, ardından Wa şu anda istatistiksel standart karakter genişliğidir.
(2) İlk bölme karakterini Cmin (Wa'dan en küçük farkı olan karakter) seçin. Standart plaka karakterlerinin genişliği ve aralığı gibi önceki bilgilere göre (tek karakter genişliği 45 mm, yükseklik 90 mm, boşluk genişliği 10 mm, ikinci ve üçüncü karakter aralığı 34 mm, kalan karakter aralığı 12 mm) Wa hesaplayın P'nin standart genişliğe oranı (formül (3) 'te gösterildiği gibi). Bu orana göre, plaka karakter düzenlemesindeki Cmin seri numarasını belirlemek için Tablo 2'deki Cmin'in merkez noktasının koordinat aralığı hesaplanır.
(3) Cmin merkez noktasını referans noktası olarak ve Wa'yı ölçek olarak kullanarak, Tablo 2'ye göre tüm karakterlerin başlangıç ve bitiş koordinatlarını hesaplayın ve ardından tüm koordinat bilgilerini listCharacter'e yeniden yazın ve karakterlerin hassas segmentasyonu bu koordinat değerleri ile tamamlanabilir . Segmentasyon etkisi Tablo 3'te gösterilmektedir.


3 Karakter tanıma
3.1 SaE-ELM
Aşırı öğrenme makinesi, Huang Guangbin tarafından önerilen tek gizli katmanlı ileri beslemeli sinir ağına dayanan yeni bir öğrenme yöntemidir. Bu yöntemin eğitimden önce yalnızca gizli katman düğümlerinin sayısını ayarlaması ve yürütme işlemi sırasında rastgele girdi ağırlıkları ve gizli katman sapmaları oluşturması (yinelemeli olarak yenilemeye ve ayarlamaya gerek yoktur) ve son olarak karmaşık problemi Moore-Penrose genelleştirilmiş matrisin tersine dönüştürmesi gerekir. Ağın girdi ağırlıkları ve gizli katmanın önyargı vektörü parametreleri rastgele oluşturulduğundan, eğitimli ELM modelinin optimuma ulaşacağının garantisi yoktur.
Bu belge, plaka karakterlerini tanımak için SaE-ELM'ye dayalı yöntemi kullanır. Bu yöntem, ELM ağının girdi ağırlıklarını ve gizli katman sapmalarını optimize etmek için uyarlanabilir bir diferansiyel evrim algoritması kullanır.İlklendirmeden sonra, optimum parametreleri oluşturmak için "mutasyon çapraz seçim" döngüsünü gerçekleştirir. Ardından, test yoluyla en uygun gizli katman düğüm sayısını ayarlayın, gizli katman çıktısını hesaplamak için uygun bir etkinleştirme işlevi seçin ve çıktı ağırlığını hesaplamak için en küçük kare yöntemini kullanın. Deneysel doğrulama, bu yöntemin sadece ELM algoritma eğitiminin hızını korumakla kalmayıp, aynı zamanda daha iyi genelleme yeteneği ve doğruluğuna sahip olduğunu ve ELM modelinin rastlantısallığını önlediğini göstermektedir. S eğitim setinin N rastgele farklı örnek içerdiğini varsayalım, S = {(xj, tj) | xjRn, tjRm, j = 1,2, ..., N}, SaE- L gizli katman birimleri ile ELM algoritması yürütme adımları aşağıdaki gibidir:
(1) İlk olarak orijinal popülasyonu başlatın. Orijinal popülasyon, tüm girdi ağırlıklarını ve gizli katmanın sapmasını içeren bir NP grup vektörüdür. Her vektör grubu, denklem (4) 'de gösterildiği gibi ayrı bir vektör olarak kullanılır.
Bunlar arasında wi ve bi rastgele atanır, wi giriş ağırlığı ve bi gizli katman sapmasıdır (i = 1, 2, ..., L). L, gizli katman düğümlerinin sayısıdır, G evrimsel cebirdir, k = 1, 2, ..., NP, NP, NP = 10 olduğunda nüfus boyutunu temsil eder.
(2) Daha sonra gizli katman çıktı matrisi Hk, G, formül (5) ile hesaplanır ve çıktı ağırlık matrisi k, G formül (6) ile elde edilebilir.

(3) Daha sonra mutasyon işlemi ile mutasyona uğramış bireyin vk, G vektörünü elde edin.Mutasyon işlemi sırasında seçilecek 4 mutasyon stratejisi vardır, Tablo 4'te gösterildiği gibi. Pl ve G aracılığıyla, mutasyon stratejisinin uyarlanabilir seçimi gerçekleştirilebilir Pl ve G, G-inci nesil mutasyon işleminde "l" stratejisini kullanma olasılığını gösteren olasılık parametreleridir.

Varyasyon faktörü F, adım uzunluğunu kontrol etmek için kullanılır ve normal N (0.6, 0.3) dağılımına uyar. K, 0 ila 1 aralığında rastgele seçilir ve r1 ila r5, 1 ila NP arasında birbirine eşit olmayan rastgele tam sayılardır. Pl, G olasılık parametrelerinin güncelleme kuralları literatüre başvurabilir.Mutasyon işlemi tamamlandıktan sonra, mutasyon vektörü ve k, G çapraz çalıştırılarak test vektörü çaprazlama işlemi denklem (9) ile tamamlanır.
Bunlar arasında, jrand rastgele pozitif bir tam sayıdır, randj, 0 ile 1 arasında rastgele bir sayıdır ve çapraz geçiş olasılığı CR, N'nin (0.3, 0.1) normal dağılımına uyar. Modeli elde etmek için, maksimum yineleme sayısı optimum k, G'yi elde edene kadar mutasyonu, geçişi ve seçimi tekrarlayın ve çıktı ağırlığını formül (6) ile hesaplayarak modeli elde edin.
3.2 Karakter tanıma
İlk olarak, karakter boyutu 20 × 40 olarak birleştirilir ve ardından yönlü gradyan histogramı karakter özelliklerini çıkarmak için kullanılır (birim 10 × 10, blok boyutu 20 × 20, blok adım boyutu 5 × 5 ve her birime karşılık gelen vektör 9 boyutlu), Daha sonra 180 boyutlu bir girdi özelliği vektörü elde edilebilir. Ardından 3 karakter sınıflandırıcıyı eğitmek için SaE-ELM'yi kullanın. Çince karakter sınıflandırıcı, 400 gizli katman düğümü ve 31 çıkış düğümü kullanarak ilk karakteri tanımlamak için kullanılır. Harf sınıflandırıcı, 300 gizli katman düğümü ve 24 çıkış düğümü kullanarak ikinci karakteri tanımlamak için kullanılır. Alfasayısal sınıflandırıcı, 300 gizli katman düğümü ve 34 çıkış düğümü kullanarak kalan 5 karakteri tanımlamak için kullanılır. Eğitim için 4.000 karakter (1435 Çince karakter, 1.000 sayı ve 1.565 İngilizce karakter) kullanılarak 2.50 GHz CPU, 2 GB bellek ve vs2013 programlamaya sahip bir ana bilgisayarda test edilmiştir. Eğitim süresi 144 saniyedir (eğitim En uzun süre). Test için 500 karakter alın, burada ayrı bir test, Çince karakter sınıflandırıcısının tanıma oranı% 96,5, alfanümerik sınıflandırıcının tanıma oranı% 97,5 ve harf sınıflandırıcının tanıma oranı% 98,0'dır. Tablo 5'ten görülebileceği gibi, tanıma oranının BP sinir ağı ve SVM'den çok farklı olmaması durumunda, SaE-ELM'ye dayalı plaka karakter tanıma eğitim süresini büyük ölçüde kısaltmakta ve karakter tanıma hızını artırmaktadır. Bu makaledeki algoritma gerçek karmaşık senaryolara uygulanabilir ve test sonuçları Şekil 4'te gösterilmektedir.


4. Sonuç
Birçok testten sonra, yukarıdaki yöntem, çeşitli karmaşık sahnelerde plakaları etkili bir şekilde tanımlayabilir. Bununla birlikte, önerilen yöntemin öncülü, renkli görüntüyü gri tonlamaya dönüştürmektir.Gelecekte, renkli görüntünün doğrudan işlenmesi düşünülebilir.Terminal, görüntü toplama işini tamamlar ve daha sonra bulut platformu aracılığıyla, nispeten karmaşık görüntü hesaplama kısmı çoklu bölümlere ayrılır. İki sunucuda eşzamanlı işlem. Çince karakterlerin ve benzer karakterlerin tanınma doğruluğunu geliştirmek için model eğitimi için derin öğrenmeyi kullanmayı da düşünebilirsiniz. Plaka tanıma teknolojisinin gelişimi, araç izleme, trafik izleme, otopark erişim yönetimi ve diğer alanlardaki gelecekteki uygulamaları için iyi bir temel oluşturmuştur.
Referanslar
TIAN B.Hiyerarşik ve ağa bağlı araç gözetimi: Bir anket.IEEE Aktarım Aktarım Sist., 2015, 16 (2): 557-580.
SHI X, ZHAO W, SHEN Y. Renkli görüntü işlemeye dayalı otomatik plaka tanıma sistemi Bilgisayar Bilimi Ders Notları, 2005, 3483 (4): 1159-1168.
ZHENG D, ZHAO Y, WANG J. Araç plakası konumunun verimli bir yöntemi Pattern Recog. Lett., 2005, 26 (15): 2431-2438.
Zhang Xuehai, Plaka Karakter Segmentasyon Yönteminin Araştırılması ve Gerçekleştirilmesi Chengdu: Southwest Jiaotong Üniversitesi, 2010.
Gan Ling, Lin Xiaojing. Bağlantılı alan çıkarımına dayalı plaka karakter bölümleme algoritması Bilgisayar simülasyonu, 2011, 28 (4): 336-339.
Mu Lijuan, Ji Yan.Plaka karakterlerinin segmentasyonunda yeni şablona dayalı algoritma uygulaması Bilgisayar Mühendisliği ve Uygulamaları, 2012, 48 (19): 191-196.
HONG T, GOPALAKRISHNAM A K.Lisans plakası çıkarma ve MSER ve BPNN.Knowledge and Smart Technology'ye (KST) dayalı bir Tayland aracının tanınması, 20157. Uluslararası Konferans, Chonburi, 2015: 48-53.
NEJATI M, MAJIDI A, JALALAT M.Kenar histogram analizi ve sınıflandırıcı topluluğuna dayalı plaka tanıma.2015 Signal Processing and Intelligent Systems Conference (SPIS), Tahran, 2015: 48-52.
HUANG G B, WANG D H, LAN Y. Extreme learning machines: a survey. International Journal of Machine Learning and Cybernetics, 2011, 2 (2): 107-122.
CAO J, LIN Z, HUANG G B.Kendine uyarlanabilir evrimsel aşırı öğrenme makinesi. Sinir Süreci. Lett., 2012, 36 (3): 285-305.