Microsoft'un açık kaynak derin öğrenme optimizasyon kitaplığı DeepSpeed, GitHub trend listesinde listelenmiştir
[Editörün notu] Son zamanlarda, derin öğrenme topluluğunda büyük bir olay meydana geldi: Microsoft Research, tarihteki en büyük doğal dil işleme modeli olduğu söylenen Turing doğal dil oluşturma modeli T-NLG'yi yayınladı. T-NLG'nin 17 milyar parametresi vardır ve performansı, BERT ve GPT-2 gibi diğer büyük ölçekli derin öğrenme dil modellerinden çok daha iyidir. Böylesine büyük ölçekli bir modeli eğitmek için ne kadar hesaplama gerektiğini hayal etmek zor. Microsoft bu haberi duyurduğunda, yeni bir paralel optimize edici ZeRO içeren T-NLG: DeepSpeed eğitiminin arkasındaki teknolojiyi de açıkladı.
Bu Perşembe gününden bu yana, DeepSpeed GitHub Trendler listesinde yer aldı ve şu ana kadar İlk 5'de kaldı, 1.500'den fazla yıldız kazandı ve yükselen bir trendi var.

Yazar | Jesus Rodriguez
Tercüman | Hilal Ay
Sıralama, sorumlu editör | Xi Yan
Üretildi | CSDN (CSDNnews)
DeepSpeed, ölçeği, hızı, kullanılabilirliği artırarak ve maliyetleri düşürerek mevcut GPU kümeleri nesli üzerinde 100 milyardan fazla parametre içeren derin öğrenme modellerini eğitebilir ve büyük modellerin eğitimini büyük ölçüde destekler. Aynı zamanda son teknoloji ile karşılaştırıldığında sistem performansı 5 kattan fazla iyileştirilebilir.
Microsoft'un tanıtımına göre, DeepSpeed kitaplığında, model ve veri paralelliği için gerekli kaynakları büyük ölçüde azaltabilen yeni bir paralel iyileştirici olan ZeRO (Sıfır Artıklık Optimize Edici) adlı bir bileşen var. Aynı zamanda, eğitilebilir parametrelerin sayısı büyük ölçüde artırılabilir. Araştırmacılar bu buluşları şimdiye kadarki en büyük kamusal dil modelini oluşturmak için kullandılar - Turing-NLG (Turing-NLG), parametreleri 17 milyara ulaşabilir, CSDN de daha önce ayrıntılı olarak bildirildi.
Derin öğrenme kütüphanesi olan T-NLG, DeepSpeed'in arkasındaki teknoloji nedir? Bu kitaplıkta bulunan yeni paralel optimize edici ZeRO'nun özel noktası nedir? Başlatıldıktan sonra neden yaygın bir ilgi gördü? Gelin bu projenin detaylarına daha yakından bakalım.
Önce DeepSpeed GitHub açık kaynak adresini yayınlayın: https://github.com/microsoft/DeepSpeed
Aşağıdaki çeviridir:

T-NLG: Tarihteki en büyük dil modeli
Doğal dil modelleri açısından, model ne kadar büyükse o kadar iyidir. T-NLG (Turing Natural Language Generation), Transformer'a dayalı üretken bir dil modelidir, bu nedenle açık metin görevlerini tamamlamak için sözcükler üretebilir. Bitmemiş cümleleri doldurabilmenin yanı sıra, doğrudan sorulara cevaplar üretebilir veya girdi belgesinin bir özetini verebilir. Doğal dil görevlerinde, model ne kadar büyükse, eğitim öncesi verilerin çeşitliliği ve kapsamlılığı o kadar iyi ve aşağı akış görevleri için daha az eğitim örneği olsa bile çeşitli alt görevlere genelleştirildiğinde performans o kadar iyi Böylece. Büyük bir çoklu görev modeli dili oluşturmak, bir dil görevi için yeni bir model eğitmekten daha kolaydır.
T-NLG ne kadar büyük? 17 milyar parametreye ek olarak, T-NLG modelinde 4256 gizli katman ve 28 dikkat kafası dahil olmak üzere 78 Transformer katmanı bulunur. Bu mimari, aşağıdaki şekilde gösterildiği gibi, büyük ölçekli doğal dil modelleri için ileriye doğru büyük bir sıçramayı temsil etmektedir:
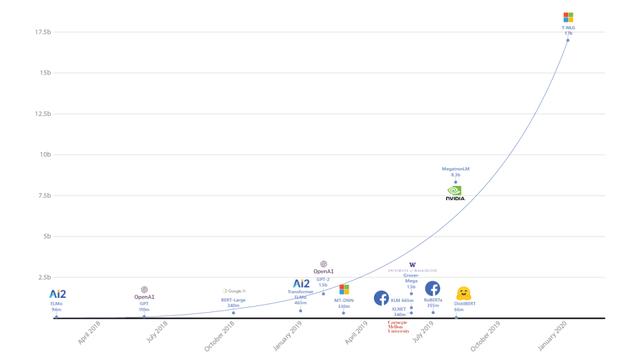
T-NLG'nin gücü yalnızca ölçek ve performansta değil, aynı zamanda eğitim sürecinde de yatıyor. Günümüz teknolojisiyle büyük ölçekli bir NPL modeli oluşturmak iyi olsa da, bu kadar büyük ölçekli bir modelin eğitiminin yüksek maliyeti çoğu kuruluşu engelleyecektir. Genişletilmiş eğitim süreci iki temel paralelleştirmeye dayanmaktadır: veri paralelliği ve model paralelliği. Veri paralelliğinin odak noktası, eğitimi tek bir düğüm / cihaz üzerinde genişletmek iken, model paralelliği eğitimi birden çok düğüm arasında dağıtmayı amaçlamaktadır. Ancak, her iki teknoloji de kendi zorluklarıyla karşı karşıyadır:
-
Veri paralelliği, her aygıtın bellek ayak izini azaltamaz: 1 milyardan fazla parametresi olan modellerde, 32 GB belleğe sahip GPU'lar bile bellek sorunlarıyla karşılaşacaktır.
-
Eğitim, ayrıntılı bilgi işlem ve pahalı iletişim gerektirdiğinden, model paralelliğinin tek bir düğümün ötesinde ölçeklendirilmesi zordur. Model paralel çerçevelerin çoğu zaman gerçek model mimarisine dayalı olarak çok sayıda kodu değiştirmesi gerekir.
Bu sorunların üstesinden gelmek için Microsoft Research, kendi optimize edicisini geliştirdi ve büyük ölçekli derin öğrenme modeli eğitiminin paralelleştirilmesini gerçekleştirdi.
ZeRO: Veri paralelliği ve model paralelliğinin avantajlarını hesaba katarak, sınırlamaların üstesinden gelmek
ZeRO (Zero Redundacy Optimizer), bellek ve genişletme verimliliğini en üst düzeye çıkarabilen bir optimizasyon modülüdür. T-NLG piyasaya sürülürken aynı zamanda Microsoft, ZeRO'nun arkasındaki ayrıntıları özetleyen bir araştırma raporu yayınladı. Kavramsal olarak, bu optimize edici, hem veri paralelliği hem de model paralelliği sınırlamalarının üstesinden gelmeyi amaçlamaktadır. ZeRO, OGP modelinin durumunu birden fazla paralel veri işlemine bölümlemek (kopyalamak yerine) için "ZeRO Tarafından Desteklenen Veri Paralel" adlı bir yöntem kullanır ve paralel veri süreçleri arasındaki bellek fazlalığını ortadan kaldırır; ve eğitimde Dinamik iletişim planı, veri paralel hesaplama granülerliğini ve iletişim hacmini sağlamak için süreçte kullanılır, böylece hesaplama / iletişimin verimliliğini sağlar. Veri paralelliğinin artmasıyla birlikte bu yöntem, modeldeki her bir aygıtın kapladığı belleği doğrusal olarak azaltabilir ve aynı zamanda normal veri paralelliği altında iletişim hacmini iletişim hacmine yakın tutabilir. Ek olarak, ZeRO tarafından desteklenen veriler, performansı daha da optimize etmek için geleneksel model paralel yöntemlerle birleştirilebilir.
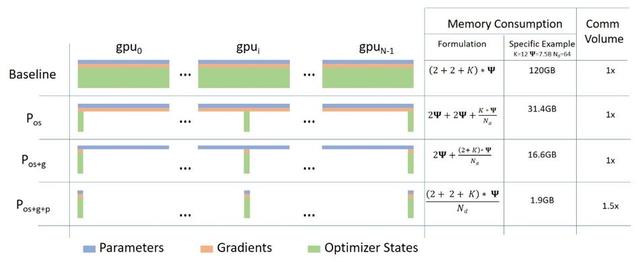
Bir algoritma perspektifinden ZeRO, optimize edici durumunun bölünmesine, gradyanın bölünmesine ve parametrelerin bölünmesine karşılık gelen üç ana aşamaya bölünmüştür.
1. Optimize Edici Durum Bölümleme (Pos): Veri paralelliği sırasında, bellek kullanımı 4 kat azalır ve iletişim hacmi değişmeden kalır.
2. Gradyan Bölümünü Artırın (Poz + g): Veri paralelliği gerçekleştirilirken, bellek kullanımı 8 kat azalır ve iletişim hacmi değişmeden kalır.
3. Parametre (Parametre) bölümünü artırın (Poz + g + p): Bellek kullanımındaki azalma, veri paralellik derecesi (Nd) ile doğrusal bir ilişkiye sahiptir. Örneğin, 64 GPU'ya bölme (Nd = 64) belleği 64 kat azaltacaktır. İletişim hacmi kabul edilebilir bir şekilde% 50 artacaktır.
ZeRO'nun ilk uygulaması, dağıtılmış eğitim için açık kaynak kitaplığına zaten dahil edilmiştir.

DeepSpeed: Model eğitim performansı 10 kat arttı
Microsoft'un DeepSpeed'i, büyük ölçekli derin öğrenme modellerinin eğitimini optimize etmeye adanmış yeni bir açık kaynaklı çerçevedir. Mevcut sürüm, ZeRO'nun ilk uygulamasını ve diğer optimizasyon yöntemlerini içerir. Bir programlama bakış açısından, DeepSpeed PyTorch üzerine inşa edilmiştir ve basit bir API sağlar.Mühendisler, sadece birkaç kod satırı ile eğitim paralelleştirme tekniklerini kullanabilir. DeepSpeed, paralelleştirme, karma hassasiyet, gradyan biriktirme ve kontrol noktası belirleme gibi büyük ölçekli eğitimin tüm zorluklarını özetler, bu nedenle geliştiricilerin yalnızca model oluşturmaya odaklanmaları gerekir.
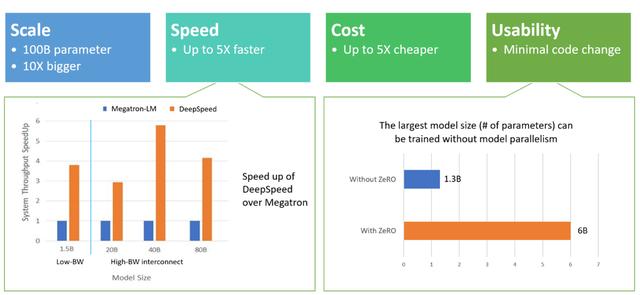
İşlevsel bir bakış açısından, DeepScale aşağıdaki dört açıdan mükemmel performansa sahiptir:
-
Ölçek: DeepSpeed tarafından sağlanan sistem desteği, diğer eğitim optimizasyon çerçevelerinden 10 kat daha hızlı olan 100 milyara kadar parametreye sahip modelleri çalıştırabilir.
-
Hız: İlk testte, DeepSpeed diğer kitaplıkların 4-5 katı bir çıktı gösterdi.
-
Maliyet: DeepSpeed kullanarak bir model eğitmenin maliyeti diğer yöntemlerden üç kat daha düşüktür.
-
Kullanım kolaylığı: DeepSpeed'in PyTorch modelini yeniden düzenlemesine gerek yoktur, yalnızca birkaç satır kod kullanılabilir.
Derin öğrenme topluluğu için Turing-NLG önemli bir kilometre taşıdır. Microsoft, açık kaynak DeepSpeed ve ZeRO'nun ilk uygulaması aracılığıyla büyük ölçekli derin öğrenme modellerini eğitme eşiğini düşürdü ve ayrıca daha eksiksiz konuşma uygulamaları uygulamamıza yardımcı olabilir.
Orijinal bağlantı:
https://towardsdatascience.com/microsoft-open-sources-zero-and-deepspeed-the-technologies-behind-the-biggest-language-model-in-5fc70e331b2d
Bu makale CSDN tarafından derlenmiştir, lütfen yeniden basım kaynağını belirtin.