Li Li: Evrişimli Sinir Ağını ayrıntılı olarak açıklayın
Bu makale serisi, derin öğrenme geliştiricilerine yöneliktir ve ilginç ve özel bir görev olan Image Caption Generation aracılığıyla basit bir şekilde derin öğrenme bilgilerini sunmayı ummaktadır. Bu makale serisi, CNN, RNN / LSTM, Attention, vb. Gibi birçok popüler derin öğrenme modelini içerir. Bu makale altıncıdır. Metinde hepsi Mavi kısım Ayrıntılara bağlantılar için orijinal metni okuyabilirsiniz.
Daha sonra, çok önemli bir sinir ağı-evrişimli sinir ağını tanıtacağız. Bu tür bir sinir ağı, bilgisayar görüşü alanında büyük başarı elde etti ve ayrıca doğal dil işleme gibi diğer alanlarda da iyi uygulamalara sahip. Derin öğrenmenin çok dikkat çekmesinin nedenlerinden biri, Alex ve arkadaşları tarafından uygulanan AlexNet'in (derin evrişimli sinir ağı) LSVRC-2010 ImageNet yarışmasında çok iyi sonuçlar elde etmesidir. O zamandan beri, evrişimli sinir ağları ve bunların varyantları görüntüyle ilgili çeşitli görevlerde yaygın olarak kullanılmaktadır.
Burada CNN'i tanıtmak için esas olarak Sinir Ağları ve Derin Öğrenme ve cs231n kurslarına atıfta bulunacağım.Her iki bölümde de teori ve kod bulunacaktır. İlki theano kullanılarak uygulanacak, ikincisi ise önceki bölümde tanıtılan otomatik gradyan kullanılarak uygulanacaktır. Aşağıda ilk olarak Michael Nielsen'in bir bölümü tanıtılmaktadır (aslında, bu esas olarak bir çeviridir ve sonra kendi anlayışımı biraz daha ekler).
Önceki kelimeler
Okuyucu bir önceki bölümde kodu denediyse ve 3 katmanlı ve 5 katmanlı tam bağlı sinir ağının parametrelerini ayarladıysa, sinir ağının ne kadar çok katmanı olursa, parametreleri (hiperparametreler) ayarlamanın o kadar zor olduğunu göreceğiz. Ancak parametreler iyi ayarlanmışsa, derin ağın etkisi gerçekten sığ ağın etkisinden daha iyidir (bu yüzden derin öğrenmeye dahil olmak istiyoruz). Yani derin öğrenmede şu söz vardır: "Üç sınır bir buluşsal yöntem kadar iyi değildir ve üç buluşsal yöntem bir numara kadar iyi değildir". Geçmişte makine öğrenimi yapmak, özellik mühendisliği artı parametre ayarlamasıydı, ancak artık parametreleri ayarlamak kaldı. Ağ yapısı, parametre başlatma, öğrenme_ hızı, yineleme sayısı, vb. Nihai sonucu etkileyecektir. İlgilenen öğrenciler, cs231n'nin Github kaynağı olan Michael Nielsen e-kitabının ilgili bölümlerine ve "Neural Networks: Tricks of the Trade" kitabına bakabilir, sadece kitabın adına bakın.
Ama "Evrişimli Sinir Ağı" konusuna dönelim.
CNN'e Giriş
Önceki bölümlerde, el yazısı rakam tanıma (MNIST) problemini çözmek için sinir ağlarını kullandık. Tamamen bağlı bir sinir ağı kullanıyoruz, yani önceki katmandaki her nöron bir sonraki katmandaki her nörona bağlanır.Önceki katmanda m ve sonraki katmanda n düğüm varsa, o zaman toplam m * n kenarlar (bağlantı). Bağlantı yöntemi aşağıdaki şekilde gösterilmiştir:
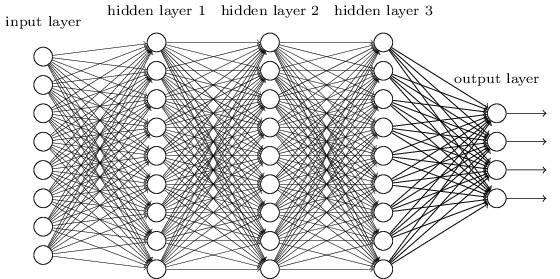
Spesifik olarak, girdi görüntüsünün her pikseli için, gri değerini karşılık gelen nöronun girdisi olarak kullanırız. 28 × 28 görüntü için ağımızda 784 giriş nöronu vardır. Ardından, ilgili sayıyı doğru bir şekilde tahmin etmesi için bu ağın ağırlıklarını ve önyargılarını eğitiyoruz.
Daha önce tasarladığımız sinir ağı çok iyi çalışıyor: MNIST el yazısı tanıma veri setinde% 98'den fazla doğruluk elde ettik. Ancak düşünürseniz, görüntüleri tanımak için tamamen bağlı bir ağ kullanmak biraz garip. Çünkü bu ağ yapısı görüntünün mekansal yapısını dikkate almıyor. Örneğin, uzayda çok yakın veya çok uzak olan pikselleri aynı şekilde ele alır. Bu boşlukların kavramı [örneğin, 7 karakter belirli bir yatay yönde bazı piksellere sahip olacaktır ve aynı gri değer, üst yataydır] ağ tarafından eğitim verilerinden çıkarılmalıdır [ancak eğitim verileri yeterli değilse ve görüntü yoksa Orta normalizasyonda, eğitim verilerinin yatay 7'si görüntünün solunda görünürse ve test verileri sağ alt köşeye 7 yazarsa, ağ böyle bir özelliği öğrenemeyebilir]. Öyleyse neden bu uzamsal yapıları dikkate almak için bir ağ yapısı tasarlayamıyoruz? Bu fikir, aşağıda tartışacağımız CNN fikridir.
Bu sinir ağı uzamsal yapıyı kullanır, bu nedenle görüntü sınıflandırması için çok uygundur. Bu yapının eğitilmesi de çok hızlıdır, bu nedenle daha derin bir ağı da eğitebilir. Şu anda çoğu görüntü tanıma, derin evrişimli sinir ağlarını ve bunların çeşitlerini kullanıyor.
Evrişimli sinir ağlarının üç temel fikri vardır: Yerel Rekabetçi Alan, ağırlık paylaşımı ve havuzlama. Onları tek tek tanıtalım.
Yerel algı alanı
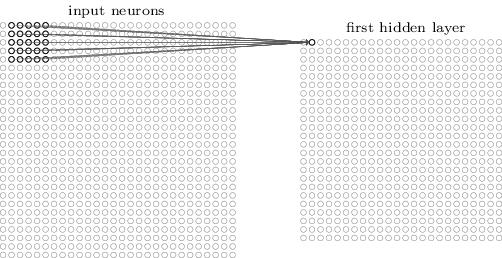
Daha önce gösterilen tamamen bağlantılı katmanda, girdi bir nöron sırası olarak tanımlanmıştır. Evrişimli ağda, girdiyi, aşağıdaki şekilde gösterildiği gibi, her biri bu pikseldeki resmin yoğunluğuna (gri değerine) karşılık gelen 28 × 28'lik iki boyutlu nöron ızgarası olarak kabul ediyoruz:

Her zamanki gibi, girdi piksellerini gizli katmandaki nöronlara bağlarız. Ancak artık girdinin her pikselini gizli katmandaki her nörona bağlamıyoruz. Aksine, girişleri küçük bir bitişik alana bağlarız.
Daha spesifik olarak, gizli katmandaki her bir nöron, giriş katmanının küçük bir alanına (örneğin, 25 piksel olan 5 × 5 bir alan) bağlanacaktır. Gizli Gizli katmandaki belirli bir nöron için, aşağıdaki şekilde gösterildiği gibi bağlanın:

Giriş görüntüsünün bu alanı, gizli katman nöronunun yerel algılama alanı olarak adlandırılır. Bu, küçük bir giriş pikselleri penceresidir. Her bağlantının bir önyargıya ek olarak öğrenilebilecek bir ağırlığı vardır. Bu yerel algılama alanını analiz etmek için nöronun kullanıldığını hayal edebilirsiniz.
Daha sonra bu yerel algısal alanı giriş görüntüsünün tamamı boyunca kaydırıyoruz. Her yerel algılama alanı için ona karşılık gelen gizli bir katman nöronu vardır. Daha somut göstermek için, önce sol üst köşedeki yerel algısal alanla başlıyoruz:

Sonra bu yerel algı alanını sağa kaydırıyoruz:
Benzetme yaparak, ilk gizli katmanı oluşturabiliriz. Girişimiz 28 × 28 ise ve 5 × 5 yerel ilgi alanı kullanılıyorsa, gizli katmanın 24 × 24 olduğunu unutmayın. Yalnızca 23 pikseli sağa ve aşağı hareket ettirebildiğimiz için, daha aşağı hareket etmek görüntü sınırının dışına çıkacaktır. [Unutmayın, bu tür bir evrişim sürecinden sonra görüntünün boyutunun değişmeden kalabilmesi için dolgu ve adım adımlarını daha sonra ekleyeceğiz]
Burada bir seferde bir piksel sağa / aşağı doğru hareketi gösteriyoruz. Aslında, aynı anda birden fazla pikseli de hareket ettirebiliriz [bu hareketin değerine adım adım denir]. Örneğin, aynı anda iki pikseli sağa / aşağı taşıyabiliriz. Bu makalede, deneme için yalnızca 1 adımı kullanıyoruz, ancak okuyucular, diğer insanların farklı adım değerleri kullanabileceğinin farkında olmalıdır.
Paylaşılan ağırlık
Daha önce belirtildiği gibi, her gizli katman nöronunun ağırlığı 5 × 5'tir. 24 × 24 gizli katmanlara karşılık gelen ağırlıklar aynıdır. Başka bir deyişle, gizli katmandaki j, kth nöron için çıktı aşağıdaki gibidir:
Burada , daha önce bahsettiğimiz sigmoid fonksiyon olabilecek aktivasyon fonksiyonudur. b paylaşılan önyargıdır ve Wl, m 5 × 5'in paylaşılan ağırlıklarıdır. ax, y, x, y'deki girdinin aktivasyonudur.
[Bu formülden, ağırlığın 5 × 5'lik bir matris olduğu ve farklı yerel algılama alanlarının bu parametre matrisini ve sapmasını kullandığı görülebilir]
Bu, bu gizli katmandaki tüm nöronların aynı özelliği algıladıkları, ancak resmin farklı konumlarında yer aldıkları anlamına gelir. Örneğin, bu ağırlık ve önyargı kümesi, dikey bir kenarı tanımlamak için belirli bir yerel algısal alan tarafından öğrenilir. Öyleyse, tahmin sırasında kenar nerede olursa olsun, belirli bir yerel algısal alan tarafından algılanacaktır. Daha soyut bir şekilde, evrişimli ağ, resmin konum değişikliğine çok iyi uyum sağlayabilir: kediyi resimdeki biraz hareket ettirin ve yine de onun bir kedi olduğunu bilir.
Bu nedenle, bazen giriş katmanından gizli katmana eşlemeye bir özellik haritası diyoruz. Özellik haritalamalarını tanımlayan ağırlıklara paylaşılan ağırlıkları ve önyargılara paylaşılan bais adı verilir. Bu ağırlık ve önyargı kümesi bir kernel veya filtreyi tanımlar.
Yukarıda açıklanan ağ yapısı yalnızca yerel bir özelliği algılayabilir. Resimleri tanımak için daha fazla özellik haritasına ihtiyacımız var. Tam bir evrişimli sinir ağını gizlemek, birçok farklı özellik haritasına sahip olacaktır:

Yukarıdaki örnekte 3 özellik haritamız var. Her eşleme 5 × 5 ağırlık ve bir önyargı ile belirlenir. Bu nedenle, bu ağ, bu 3 özellik görüntünün hangi yerel algısal etki alanında görünürse görünsün, 3 tür özelliği algılayabilir.
Basit olması için, yukarıda 3 özellik haritası gösterilmektedir. Gerçek evrişimli sinir ağında birçok özellik haritası kullanacağız. Erken evrişimli bir sinir ağı olan LeNet-5, MNIST rakamlarını tanımlamak için her biri 5 × 5 yerel algısal alan olan 6 özellik haritası kullandı. Yani yukarıdaki örnek LeNet-5'e çok yakın. Daha sonra geliştireceğimiz evrişimli katman 20 ve 40 özellik haritalarını kullanacaktır. Öncelikle modelin öğrendiği bazı özelliklere bakalım:

Bu 20 resim, 20 farklı özellik haritasına karşılık gelir. Her bir eşleme, yerel algılama alanının 5 × 5 ağırlıklarına karşılık gelen 5 × 5'lik bir görüntüdür. Daha beyaz (daha açık) renk, ağırlık ne kadar küçükse (genellikle negatiftir), bu nedenle karşılık gelen piksel bu özelliği tanımlamak için daha az önemlidir. Daha koyu (siyah) renk, ağırlık ne kadar büyük ve karşılık gelen pikselin o kadar önemli olduğunu gösterir.
Öyleyse, bu özellik haritalarından hangi sonuçları çıkarabiliriz? Açıktır ki, rastgele olmayan bir uzaysal yapı içerir. Bu, ağımızın bazı mekansal yapıları öğrendiğini gösteriyor. Ancak hangi özellikleri öğrendiğini söylemek zordur. Öğrendiklerimiz bir Gabor filtresi değil. Aslında, makinenin hangi özellikleri öğrendiğini anlamaya çalışan çok sayıda araştırma çalışması var. İlgileniyorsanız, Matthew Zeiler ve Rob Fergus tarafından yazılan 2013 Evrişimli Ağları Görselleştirme ve Anlama başlıklı makaleye başvurabilirsiniz.
Ağırlık ve önyargı paylaşmanın en büyük avantajı, ağ parametrelerinin sayısını büyük ölçüde azaltmasıdır. Her özellik haritası için, sadece 25 = 5 × 5 ağırlığa ve bir sapmaya ihtiyacımız var. Bu nedenle, bir özellik haritasının yalnızca 26 parametresi vardır. 20 özellik haritamız varsa, o zaman sadece 20 × 26 = 520 parametre vardır. Tamamen bağlı bir sinir ağı yapısı kullanırsak, gizli katmanın 30 nörona sahip olduğunu varsayarsak (bu çok değildir), o zaman 784 * 30 ağırlık parametresi, artı 30 önyargı, toplam 23.550 parametre vardır. Diğer bir deyişle, tam bağlı ağ, evrişimli ağdan 40 kat daha fazla parametreye sahiptir.
Elbette, iki ağın parametrelerini doğrudan karşılaştıramayız, çünkü iki model esasen farklıdır. Bununla birlikte, sezgisel olarak, evrişimli ağ, aynı etkiyi elde etmek için öteleme değişmezliği özelliklerine sahip olduğundan, daha az parametre de kullanabilir. Parametreler düştükçe, evrişimli ağın eğitim hızı da daha hızlıdır, böylece aynı bilgi işlem kaynaklarıyla daha derin bir ağı eğitebiliriz.
"Evrişim" sinir ağı, formül (1) 'deki işlemin "evrişim işlemi" olarak adlandırılmasıdır. Daha spesifik olmak gerekirse, toplamı formül (1) 'e evrişim olarak yazabiliriz: $ a ^ 1 = \ sigma (b + w * a ^ 0) $. * Burada çarpma değil, evrişim işlemi. Evrişimin ayrıntıları burada tartışılmayacaktır, bu yüzden anlamazsanız endişelenmeyin. Bu sadece evrişimsel sinir ağı adının kökenini açıklamak içindir. [İlgili okuyucuların colah'ın "Konvolüsyonları Anlamak" adlı blog gönderisine başvurmaları önerilir]
Havuzlama
Yukarıdaki evrişimli katmanlara ek olarak, evrişimli sinir ağları ayrıca havuz katmanları içerir. Havuzlama katmanı genellikle doğrudan evrişimli katmanın arkasına yerleştirilir Havuzlama katmanının amacı, evrişimli katmandan bilgi çıktısını basitleştirmektir.
Daha spesifik olarak, bir havuz katmanı, evrişimli katmanın çıktısını girdi olarak alır ve daha kompakt (yoğunlaştırılmış) bir özellik haritası çıkarır. Örneğin, havuz katmanındaki her nöron, önceki evrişimli katmanın 2 × 2 alanının bilgisini çıkarır. Daha spesifik bir örnek, çok yaygın bir havuzlama işlemine Max-pooling denir. Max-Pooling'de bu nöron, aşağıdaki şekilde gösterildiği gibi 2 × 2 alanındaki en büyük aktivasyon değerini seçer:

Evrişimli katmanın çıktısının 24 × 24 olduğunu, ancak havuzlamadan sonra 12 × 12 olduğunu unutmayın.
Yukarıda bahsedildiği gibi, evrişimli katman genellikle çoklu özellik haritalarına sahiptir. Her özellik haritasında maksimum havuzlama işlemi gerçekleştireceğiz. Bu nedenle, bir evrişimli katman 3 özellik haritasına sahipse, evrişim artı maksimum havuzlama aşağıdaki şekle benzeyecektir:

Max-pooling'i, bu alanda belirli bir özelliğin görünüp görünmediğine önem veren bir sinir ağı olarak düşünebiliriz. Bu özelliğin göründüğü belirli konumu yok sayar. Sezgisel olarak, belirli bir özellik ortaya çıkarsa, bu özelliğin diğer özelliklere göre kesin konumu önemli değildir [kesin konum önemli değildir, ancak iki gözü ve burnu olan bir kediyi tanımlamak gibi yaklaşık konum önemlidir. Kaba bir göreceli konum ilişkisi, ancak gözleri küçük bir 2 × 2 alanda hafifçe hareket ettirmek bir kediyi tanımamızı etkilememelidir ve aynı zamanda görüntü çekim açısı değişiklikleri, bozulmaları vb. Sorunları da çözebilir]. Ve büyük bir avantaj, havuzlamanın özelliklerin sayısını azaltabilmesidir [2 × 2 maksimum havuzlama, özelliğin boyutunu orijinalin 1 / 4'ünü yapar], böylece sonraki katmanlardaki parametre sayısını azaltır.
Maksimum havuz, havuzlamanın tek yöntemi değildir. Diğer bir yaygın olanı L2 Pooling'dir. Bu yöntem, 2 × 2 alanının maksimum değerini almak değil, 2 × 2 alanın her bir değerinin karesini almak ve sonra toplayarak karekökü almaktır. Ayrıntılar farklı olsa da, fikir maks-havuzlamaya benzer: L2 Havuzlama aynı zamanda evrişimli katmandan gelen bilgileri sıkıştırmanın bir yöntemidir. Uygulamada, her iki yöntem de yaygın olarak kullanılmaktadır. Bazen insanlar başka havuzlama yöntemlerini de kullanır. Performans sağlamak için gerçekten farklı yöntemler denemek istiyorsanız, farklı havuzlama yöntemlerini denemek için doğrulama verilerini kullanabilir ve ardından en uygun yöntemi seçebilirsiniz. Ancak bu ayrıntıları burada tartışmayacağız. [Max-Pooling en çok kullanılanıdır ve hatta bazıları Pooling'in yararsız olduğunu düşünür. Derin öğrenmeyle ilgili bir sorun, birçok deneysel hilenin çok fazla teorik temele sahip olmaması, ancak ilk insanların bunları kullanması ve iyi çalışıyor gibi görünmeleridir (ancak veri setini değiştirmek gerekli olmayabilir), bu nedenle sonrakiler onları takip edecektir. Ama bu numaranın aslında işe yaramaz olduğunu düşünmem uzun sürmedi]
Bir araya koymak
Şimdi bu 3 fikri, tam bir evrişimli sinir ağı oluşturmak için bir araya getirebiliriz. Daha önce gördüğümüz yapıya benzer, ancak 10 nöronlu bir çıktı katmanı ekler. Bu katmandaki her nöron 0-9 arasında doğrudan bir sayıya karşılık gelir:

Bu ağın giriş boyutu 28 × 28'dir ve her giriş MNIST görüntüsünün bir pikselidir. Daha sonra üç özellik haritası kullanılır ve yerel algısal alanın boyutu 5 × 5'tir. Bu, 3 × 24 × 24 çıktıyla sonuçlanır. Ardından, 3 × 12 × 12'lik bir çıktı elde etmek için her özellik haritasının çıktısına 2 × 2 maksimum havuzlama uygulayın.
Son katman, tamamen bağlı bir ağdır, 3 × 12 × 12 nöron, çıkış 10 nöronun her birine bağlanacaktır. Bu, daha önce tanıtılan tamamen bağlı sinir ağıyla aynıdır.
Evrişim yapısı, önceki tam bağlantılı yapıdan çok farklıdır. Ancak genel resim benzerdir: Bir sinir ağında birçok nöron vardır ve davranışları ağırlıklar ve önyargılarla belirlenir. Ve genel amaç benzerdir: Ağın resimleri olabildiğince iyi tanıyabilmesi için ağın ağırlıklarını ve önyargılarını eğitmek için eğitim verilerini kullanın.
Daha önce de belirtildiği gibi, burada eğitim için hala stokastik gradyan inişi kullanıyoruz. Ancak geri yayılım algoritması farklıdır. Bunun nedeni, bp algoritmasının önceki türetiminin tamamen bağlı bir sinir ağına dayanmasıdır. Neyse ki, evrişim ve maks-havuzlamanın türevini bulmak çok basit. Ayrıntıları bilmek istiyorsanız, lütfen kendiniz belirleyin. [Bu makale CNN'nin gradyan çözümünü tanıtmayacaktır. Aşağıdaki uygulama theano kullanmaktadır. CS231N'nin CNN'si, otomatik türetmeye dayalı olarak bu gradyanın nasıl bulunacağını tanıtacak ve aynı zamanda verimli algoritmalar sunacaktır. Okuyucular, lütfen dikkat etmeye devam edin]
CNN iş başında
Daha önce CNN'nin temel teorisini tanıttık, ancak gradyanı nasıl bulacağımız hakkında konuşmadık. Buradaki kod, gradyanı otomatik olarak bulmak için theano'yu kullanır. Geçici olarak cnn'yi kara kutu olarak görebilir ve MNIST numaralarını tanımlamak için kullanmaya çalışabiliriz. Sonraki makaleler theano'yu ve theano'nun CNN'i uygulamak için nasıl kullanılacağını tanıtacak.
Kod
İlk önce kodu alın: git clone
Kurulum Theano
Buraya bakın; eğer bir ubuntu sistemiyse, buna başvurabilirsiniz; makinenizde gpu varsa, lütfen cuda'yı kurun ve theano'nun gpu'yu desteklemesine izin verin.
Varsayılan network3.py'nin 52. satırı GPU = True şeklindedir. Makinenizde GPU yoksa lütfen bu satırı GPU = False olarak değiştirin
temel
İlk olarak bir temel sistem uyguluyoruz.Sadece bir gizli katman ve gizli katmanda 100 nöron ile 3 katmanlı tam bağlantılı bir ağ oluşturuyoruz. $ \ Eta = 0.1 $ öğrenme oranını kullanarak 60 dönem eğitim veriyoruz, toplu iş boyutu 10 ve herhangi bir düzenleme yok:
$ cd src
$ ipython
> > > ağ3 içe aktar
> > > ağ3 içe aktarma Ağından
> > > network3'ten ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer içe aktarın
> > > training_data, validation_data, test_data = network3.load_data_shared
> > > mini_batch_size = 10
> > > net = Ağ (, mini_batch_size)
> > > net.SGD (eğitim_verisi, 60, mini_batch_size, 0.1,
validation_data, test_data)
Elde edilen sınıflandırma doğruluğu% 97,8'dir. Bu, test_data'daki doğruluk oranıdır. Bu model eğitim verileri kullanılarak eğitilmiştir ve validation_data'ya göre şu anda en iyi modeli seçer. Aşırı uyumu önlemek için doğrulama verilerini kullanın. Modelin parametreleri rastgele başlatıldığı için okuyucu çalıştığında sonuçlarda bazı farklılıklar olabilir.
Geliştirilmiş sürüm 1
İlk olarak girdiden sonra evrişimli bir katman ekliyoruz. 5 ila 5 yerel algısal etki alanı kullanıyoruz, adım 1'e eşittir ve 20 özellik haritası. Ardından 22 maksimum havuz katmanını bağlayın. Ardından tamamen bağlantılı bir katman ve son olarak softmax (afin dönüşüm artı softmax):

Bu ağ yapısında, evrişim ve havuzlama katmanının giriş görüntüsünün yerel uzamsal özelliklerini öğrenebileceğini, tam bağlantılı katmanın ise global bilgileri entegre edip daha soyut özellikleri öğrenebileceğini düşünebiliriz. Bu, evrişimli sinir ağlarının ortak bir yapısıdır.
İşte kod:
> > > net = Ağ (, mini_batch_size)
> > > net.SGD (eğitim_verisi, 60, mini_batch_size, 0.1,
validation_data, test_data)
[Resmin boyutuna dikkat edin, başlangıç (mini_batch_size, 1, 28, 28), 205 5 evrişimli havuz katmanından sonra (mini_batch_size, 20, 24, 24) olur ve sonra 22 max -Havuzlandırma (mini_batch_size, 20, 12, 12) olur ve sonra tam olarak bağlı katman bağlandığında, tüm özellik haritalarının genişletildiği anlaşılabilir, yani 201212, yani FullyConnectedLayer'ın n_in'i 201212'dir]
Bu modelin doğruluğu% 98,78'dir ve bu önceki% 97,8'e göre büyük bir gelişmedir. Aslında hata oranımız 1/3 oranında düşürüldü ki bu büyük bir gelişme. [Doğruluk oranı yüksek olduğunda, daha tatmin edici olan hata oranındaki azalmaya bakın, haha]
Gpu kullanmak istiyorsanız, yukarıdaki komutu bir test.py dosyasına kaydedebilir ve ardından:
$ THEANO_FLAGS = mod = FAST_RUN, aygıt = gpu, floatX = float32 python test.py
Bu ağ yapısında, evrişime ve havuzlama katmanlarına bir bütün olarak bakıyoruz. Bu sadece bir alışkanlık. network3.py bunları bir bütün olarak ele alacak ve her evrişimli katmanın ardından bir havuz katmanı gelecektir. Ancak bazı gerçek evrişimli sinir ağlarının havuz katmanına bağlanması gerekmez.
Geliştirilmiş sürüm 2
Ardından ikinci bir evrişim havuzlama katmanı ekliyoruz. Bu evrişimli katman, birinci evrişimli katman ile tamamen bağlantılı katman arasına yerleştirilir. Aynı 5 × 5 yerel algısal alanı ve 2 × 2 maks. Havuzlamayı kullanıyoruz. kod aşağıdaki gibi gösterilir:
> > > net = Ağ (, mini_batch_size)
> > > net.SGD (eğitim_verisi, 60, mini_batch_size, 0.1,
validation_data, test_data)
[Resmin boyutuna dikkat edin, başlangıç (mini_batch_size, 1, 28, 28), 205 5 evrişimli havuz katmanından sonra (mini_batch_size, 20, 24, 24) olur ve sonra 22 max Sonraki-paylaşım, (mini_batch_size, 20, 12, 12) olur. Sonra, (mini_batch_size, 40, 8, 8) haline gelen ve ardından max-pooling (mini_batch_size, 40, 4, 4) haline gelen 40 adet 5 * 5 evrişimli katman vardır. Sonra tamamen bağlantılı katman]
Bu model% 99,6 doğruluk elde ediyor!
Burada iki doğal sorun var. İlki: İkinci bir evrişim havuzlama katmanı eklemenin amacı nedir? Aslında, ikinci evrişimli katmanın girişinin 12 * 12 "resim" olduğunu ve "piksellerinin" belirli bir yerel özelliği temsil ettiğini düşünebilirsiniz. [Örneğin, birinci evrişimli katmanın gözleri ve burunları tanıdığını ve ikinci evrişimli katmanın yüzleri tanıdığını düşünebilirsiniz. Burunların ve gözlerin farklı yaratıkların yüzlerindeki göreli konumları anlamlıdır]
Bu oldukça iyi bir açıklama, işte ikinci soru geliyor: ilk evrişimli katmanın çıktısı farklı 20 farklı yerel özelliktir, bu nedenle ikinci evrişimli katmanın girdisi 201212'dir. Sanki bir "resim" yerine 20 farklı "resim" girdik. Peki ikinci evrişimli katmandaki nöronlar ne öğrendi? [Evrişimli ağın ilk katmanı "gözleri", "burnu" ve "kulakları" tanıyabiliyorsa. Sonra ikinci katmandaki "yüz" 2 göz, 2 kulak ve 1 burundur ve belirli uzamsal kısıtlamaları karşılarlar. Yani ikinci katmandaki her nöronun birinci katmanın her çıkışına bağlanması gerekir, eğer ikinci katman sadece "gözlerin" özellik haritasını birleştirirse, o zaman sadece 2 göz ve 3 göz öğrenilebilir. Artık kullanmıyorum]
Geliştirilmiş sürüm 3
ReLU aktivasyon işlevini kullanın. ReLU'nun tanımı:
> > > network3'ten ReLU içe aktar
> > > net = Ağ (, mini_batch_size)
> > > net.SGD (eğitim_verisi, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda = 0.1)
ReLU kullanıldıktan sonra, doğruluk oranı% 99.06'dan% 99.23'e yükseldi. Yazarın deneyimine göre, ReLU her zaman sigmoid aktivasyon işlevinden daha iyidir.
Fakat ReLU neden sigmoid veya tanh'den daha iyidir? İyi bir teorik giriş yok. ReLU, ancak son yıllarda popüler hale geldi. Popüler olmasının nedeni deneyim: Bazı insanlar ReLU'yu denedi ve görevlerinde sigmoidden daha iyi sonuçlar aldı ve sonra diğerleri de aynı şeyi yaptı. Teoride, hiç kimse ReLU'nun daha iyi bir aktivasyon işlevi olduğunu kanıtlamadı. [Bu nedenle, derin öğrenmede birkaç yıl içinde popüler hale gelebilecek pek çok numara vardır, ancak bazı insanlar bu numaraların birkaç yıl sonra anlamsız olduğunu düşünüyor. Örneğin, en eski ön eğitim artık neredeyse hiç kullanılmıyor.
Geliştirilmiş sürüm 4
Genişletilmiş veriler.
Derin öğrenme, verilere çok bağlıdır. Görevin özelliklerine göre yeni verileri "oluşturabiliriz". Basit bir yöntem, eğitim verilerindeki sayıları çevirmek ve döndürmektir. Teorik olarak evrişimli sinir ağları, konumla ilgili olmayan özellikleri öğrenebilse de, eğitim verilerindeki sayılar her zaman sabit bir konumda görünüyorsa, gerçek model bunu öğrenemeyebilir. Bu nedenle, bu tür veriler oluşturmamız daha iyi olacaktır.
$ python expand_mnist.py
Expand_mnist.py komut dosyası verileri genişletir. Resmi bir piksel yukarı, aşağı, sola ve sağa hareket ettirir. Genişletmeden sonra eğitim verileri 50.000'den 250.000'e değişti.
Daha sonra modeli eğitmek için genişletilmiş verileri kullanıyoruz:
> > > expanded_training_data, _, _ = network3.load_data_shared (
"../data/mnist_expanded.pkl.gz")
> > > net = Ağ (, mini_batch_size)
> > > net.SGD (expanded_training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda = 0.1)
Bu modelin doğruluğu% 99.37'dir. Genişletilmiş veriler çok önemsiz görünüyor, ancak tanıma doğruluğunu büyük ölçüde geliştiriyor.
Geliştirilmiş sürüm 5
Bundan sonra iyileştirmenin bir yolu var mı? Tamamen bağlı katmanımızda yalnızca 100 nöron var. Nöron eklemek yardımcı olur mu? Yazar, 300 ve 1000 nörondan oluşan tamamen bağlı bir katmanı denedi ve% 99.46 ve% 99.43 doğruluk elde etti. % 99.37 ile karşılaştırıldığında önemli bir gelişme yok.
Tamamen bağlantılı bir katman eklemek yardımcı olur mu? Biz denedik:
> > > net = Ağ (, mini_batch_size)
> > > net.SGD (expanded_training_data, 60, mini_batch_size, 0.03,
validation_data, test_data, lmbda = 0.1)
Tamamen bağlanmış ilk katmandan sonra, 100 nöronun eklendiği tamamen bağlı bir katman vardır. Elde edilen doğruluk oranı% 99,43 olup, bu katmandaki nöron sayısının 100'den 300 ve 1000'e çıkarılmasıyla elde edilen doğruluk oranları% 99,48 ve% 99,47'dir. Bazı iyileştirmeler var ama açık değil.
Neden daha fazla katman ekleyerek pek geliştirilmiyor? Görünüşe göre ifade yeteneği daha güçlü hale geldi. Olası neden aşırı uyuyor. Aşırı uyum nasıl çözülür? Bunun bir yolu okulu bırakmaktır. Düşüşün ayrıntılı açıklaması için lütfen buraya bakın. Basitçe söylemek gerekirse, eğitim sırasında bazı nöronların aktivasyonunu rastgele "kaybetmek" tir, böylece ağ daha sağlam özellikler öğrenebilir, çünkü ağın belirli nöronlar "başarısız" olduğunda "başarısız" olmaya devam etmesini gerektirir. Çalışın, bu yüzden belirli nöronlara çok bağlı değil, ama her nöron katkıda bulunuyor.
Aşağıdakiler, tamamen bağlı katmanların her ikisine de% 50 kayıp eklemektir:
> > > net = Ağ (,
mini_batch_size)
> > > net.SGD (expanded_training_data, 40, mini_batch_size, 0.03,
validation_data, test_data)
Bırakmayı kullandıktan sonra,% 99.60'lık bir modelimiz var.
Burada kayda değer iki nokta var:
-
Eğitim dönemi 40 olur. Okulu bırakma aşırı uyumu azalttığı için 60 döneme ihtiyacımız yok.
-
Tam bağlı katman 1000 nöron kullanır. Bırakma nöronların% 50'sini düşüreceğinden, sezgisel olarak 1000 nöron sadece 500'e eşdeğerdir. 100 nöron kullandıysanız, çok az hissedersiniz. Doğrulamanın ardından yazar, bırakma durumunda 1000'in 300'den daha iyi olduğunu buldu.
Geliştirilmiş sürüm 6
çoklu sinir ağlarını bir araya getirin. Yazar, her biri% 99,6 doğruluk elde eden ve daha sonra bunları oy kullanmak için kullanan 5 sinir ağını eğitti ve% 99,67 doğrulukla bir model aldı.
Bu çok iyi bir model. 10.000 test verisinin sadece 33'ü yanlış. Tüm yanlış resimleri listeledik:

Resmin sağ üst köşesi doğru sınıflandırmadır ve sağ alt köşesi modelin sınıflandırmasıdır. Bazı dijital kişilerin de net olarak ayırt edilmesi zor olduğu için bazı hataların insanlar tarafından yapılabileceği görülebilir.
[Bırakmayı neden yalnızca tam bağlantılı katmanlar için kullanmalı?
Okuyucular kodu dikkatlice okursa, yalnızca tam bağlantılı katmanı çıkardığımızı, ancak evrişimli katmanı çıkardığımızı göreceksiniz. Elbette, evrişimli katmanı da çıkarabiliriz. Ancak gerekli değildir. Çünkü evrişimli katmanın kendisi aşırı oturmayı önleme yeteneğine sahiptir. Bunun nedeni, ağırlık paylaşımının ağı herhangi bir konuma uygulanabilecek özellikleri öğrenmeye zorlamasıdır. Bu, özel yerel özellikleri öğrenmeyi kolaylaştırmaz. Bu nedenle, onu bırakmaya gerek yoktur.
Daha ileri git
İlgilenen okuyucular, MNIST veri setinin ve ilgili makalelerin en iyi sonuçlarını listeleyen buraya başvurabilir. Şimdiye kadarki en iyi sonuç% 99,79
Sıradaki ne?
Bir sonraki makale, çok popüler bir derin öğrenme çerçevesi olan theano'yu tanıtacak ve ardından CNN'yi uygulamak için theano'nun nasıl kullanılacağı olan network3.py'yi açıklayacak. bizi izlemeye devam edin.
Yazar: Li Li, şu anda çalışan Shun, anlık mesajlaşma platformları ve müşteri hizmetleri için bulut akıllı tüm medya platformu, halka mektubundaki akıllı ve akıllı robotla ilgili çalışmadaki müşteri hizmetleri, akıllı robotların performansını iyileştirmek için derinlik çalışmasını kullanmayı taahhüt ediyor.
İlgili Makaleler:
-
Li Li: Image Caption Generation'dan Derin Öğrenmeyi Anlamak (bölüm I)
-
Li Li: Image Caption Generation'dan Derin Öğrenmeyi Anlamak (bölüm II)
-
Li Li: Image Caption Generation'dan Derin Öğrenmeyi Anlamak (bölüm III)
-
Li Li: Otomatik gradyan çözümü, geri yayılım algoritmasının başka bir perspektifi
-
Li Li: Otomatik gradyan çözümü-cs231n'nin notları
-
Li Li: Otomatik Derivasyon Kullanarak Otomatik Gradyan Çözme-Gerçekleştirme Çok Katmanlı Sinir Ağı