sonunda! Supervise.ly, portre segmentasyon veri kümesini yayınlar (ücretsiz ve açık kaynak)
Lei Feng Net Not: Bu makale, Lei Feng'in altyazı grubu tarafından derlenen teknik bir blogdur. Orijinal başlık, makinelerin insanları segmentlere ayırmasını öğretmek için "Denetimli Kişi" veri setini Yayınlıyor ve yazar da Supervise.ly.
Tercüme | Guo Naiqiao Wang Ning Zhang Hu Bitirme | Fan Jiang Wu Xuan
Supervisely portre veri setinin resmi olarak yayınlandığını burada duyurmaktan gurur duyuyoruz. Yalnızca akademik amaçlar için halka açık ve ücretsizdir.

Yapay zekanın herkes tarafından paylaşılması için sadece açık kaynağa değil, aynı zamanda güçlü bir "açık veri" hareketine de ihtiyacımız var. Wu Enda
Onunla kesinlikle hemfikiriz ve bu fikri genişletmemize izin verin. Anlamsal bölümlere sahip insanlar için çok sayıda derin sinir ağı araştırması var. Bununla birlikte, çoğu durumda, veri toplamak, verileri çalıştırmak için algoritmalar geliştirmek ve uygulamaktan daha zor ve pahalıdır.
Bu nedenle, eğitim veri setleri geliştirmekten sinir ağlarını eğitmeye ve dağıtmaya kadar tüm makine öğrenimi iş akışını kapsayabilecek özel olarak tasarlanmış bir platforma ihtiyacımız var.

"Gözetimli Portre Veri Kümesi" nden birkaç örnek gelir
Çalışmamızın geliştiricilere, araştırmacılara ve iş adamlarına yardımcı olacağına inanıyoruz. Daha büyük bir eğitim veri setini daha hızlı oluşturmak için, çalışmamız yalnızca halka açık bir veri seti olarak değil, aynı zamanda bir dizi yenilikçi yöntem ve araç olarak da görülebilir.
Daha sonra, bu veri setini sıfırdan nasıl oluşturacağımızı tanıtacağız, bazı ilginç gerçekleri göstermeme izin verin:
-
Veri seti, 6884 yüksek kaliteli açıklamalı insan örnekleriyle 5711 görüntüden oluşur.
-
Aşağıdaki tüm adımlar herhangi bir kodlama olmadan Denetimli olarak dahili olarak yapılır.
-
Daha da önemlisi, bu adımlar herhangi bir makine öğrenimi uzmanlığı olmadan dahili açıklayıcım tarafından gerçekleştirilir. Veri bilimciler sadece bu süreci kontrol eder ve yönetir.
-
Ek açıklama grubu iki üyeden oluşuyordu ve tüm süreç sadece 4 gün sürdü.
Supervisely, veri bilimini içeren akıllı bir makine öğrenimi platformudur. Veri bilimcilerinin gerçek yeniliğe odaklanmalarına ve günlük işleri başkalarına bırakmalarına olanak tanır (evet, iyi bilinen sinir ağı mimarisini eğitmek de rutin bir iştir).
Çözülecek problem
Pek çok gerçek dünya uygulamasında portre algılama, insan görüntülerini analiz etmede kilit bir görevdir ve hareket tanıma, otonom araçlar, video gözetimi ve mobil uygulamalarda kullanılır.
DeepSystems'te, insan algılama görevleri için veri eksikliğini fark etmemizi sağlayan dahili araştırmalar yaptık. Bize soracaksınız: COCO, Pascal, Mapillary, vb. Gibi halka açık veri kümeleri ne olacak? Bu soruyu cevaplamak için size birkaç örnek göstereceğim:

COCO veri kümesinden çeşitli insan ek açıklama örnekleri
Çoğu halka açık veri kümesindeki insan algılama verilerinin kalitesi gereksinimlerimizi karşılamıyor. Kendi veri kümelerimizi oluşturmalı ve yüksek kaliteli açıklamalar sağlamalıyız. Bunu nasıl yaptığımızı size anlatacağım.
Adım 0: İlk sinir ağını eğitmek için genel veri setini bir başlangıç noktası olarak yükleyin ve hazırlayın
Herkese açık veri setlerini sisteme yükleyin: PascalVoc, Mapillary. "İçe aktarma" modülümüz çoğu genel veri setini destekler ve bunları Supervisely formatı adı verilen birleşik bir json tabanlı formata dönüştürür :)
Bazı işlemleri gerçekleştirmek için DTL ("Data Transformation Language") sorguları gerçekleştiriyoruz: veri setlerini birleştirme- > İnsan olmadan görüntüleri atla > Görüntüdeki herkesi kırpın > Bunları genişlik ve yüksekliğe göre filtreleyin - > Eğitim / test setlerine bölün.
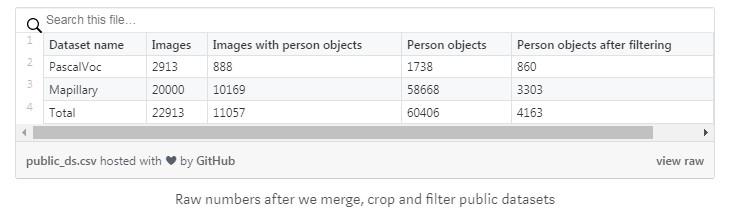
Herkese açık veri kümelerini birleştirdikten, kırptıktan ve filtreledikten sonra orijinal veriler
Halka açık pek çok veri var gibi görünüyor, ancak daha önce de bahsettiğimiz gibi, bazı gizli sorunlar var: düşük açıklama kalitesi, düşük çözünürlük, vb.
Bu nedenle ilk eğitim veri setini oluşturduk.
1. Adım: Sinir ağını eğitin
UNet benzeri mimariyi biraz özelleştireceğiz

Unet_v2 mimarisi
Kayıp = ikili kayıp entropisi + (1-rastgele sayı).
Ağın eğitilmesi hızlıdır, çok doğru, uygulaması ve özelleştirmesi kolaydır. Bir çok deney yapmamızı sağlar. Denetimli olarak, kümedeki birden çok düğüme dağıtılabilir.
Böylece aynı anda birkaç sinir ağını eğitebiliriz. Benzer şekilde, tüm sinir ağları platformumuzda çoklu GPU eğitimini destekler. Her eğitim testinin giriş çözünürlüğü 256 * 256'dır ve 15 dakikayı geçmez.

2. Adım: Verileri açıklama için hazırlayın
Etiketsiz görselleri toplamadığımız için internetten indirmeye karar verdik. Bu projeyi github üzerinde uyguladık, böylece Pexels tarafından yapılan mükemmel bir fotoğraf kütüphanesinden veri indirebiliriz (onun sayesinde, bu gerçekten harika bir iş).
Bu nedenle görevimizle ilgili etiketleri içeren yaklaşık 15 bin resim indirip Supervisely'ye yükledik ve süper yüksek çözünürlüğe sahip oldukları için DTL sorguları ile yeniden boyutlandırma işlemleri gerçekleştirdik.
3. Adım: Sinir ağını etiketlenmemiş görüntüye uygulayın
Geçmiş mimari, örnek segmentasyonu desteklemiyordu. Bu nedenle, nesnenin kenarına yakın segmentasyon kalitesi çok düşük olduğu için Mask-RCNN kullanmadık.
Bu nedenle iki aşamalı bir plan yapmaya karar verdik: görüntüdeki tüm insanları tespit etmek için Daha Hızlı RCNN (NasNet'e dayalı) uygulayın ve ardından baskın nesneyi bölümlere ayırmak için her kişinin sınırlayıcı kutusu için bir bölümleme ağı uygulayın. Bu yöntem, hem örnek segmentasyonu simüle etmemizi hem de nesne kenarlarını doğru şekilde segmentlere ayırmamızı sağlar.
3 dakikalık uygulama modeli videosu ve manuel düzeltme algılama
Farklı çözünürlükler denedik: NN'ye ne kadar yüksek çözünürlük aktarırsak, o kadar iyi sonuçlar ürettik. Toplam çıkarım süresi umurumuzda değil, çünkü Supervisely birden fazla makineye dağıtılan çıkarımı destekler. Bu, otomatik ön etiketleme görevleri için yeterlidir.
4. Adım: Manuel doğrulama ve düzeltme
Tüm çıkarım sonuçları kontrol panelinde gerçek zamanlı olarak görüntülenecektir. Operatörlerimiz tüm sonuçları önizler ve görüntüleri birkaç etiketle etiketler: kötü tahmin, tahmin düzeltme, iyi tahmin. Bu işlem hızlıdır çünkü "Sonraki Resim" ve "Etiket Resmi Ata" çok az klavye kısayolu gerektirir.

Resimleri nasıl etiketleriz: sol-kötü tahmin, orta-tahmin hafif manuel düzeltme, sağ-iyi tahmin gerektirir.
"Kötü tahmin" olarak işaretlenen resimler atlanır. Düzeltmemiz gereken görüntüleri işlemek için daha fazla çalışma devam ediyor.
Sinir ağı tahminleri nasıl düzeltilir?
Manuel düzeltme için gereken süre, baştan itibaren yapılan yorumlara göre çok daha azdır.
Adım 5: Sonuçları eğitim veri kümesine ekleyin ve 1. adıma gidin
gerçekleştirmek!
Bazı ipuçları:
Yalnızca herkese açık veriler üzerinde eğitilmiş bir NN uyguladığımızda, "uygun" görüntülerin yüzdesi ("iyi tahmin" ve "doğru tahmin" olarak etiketlenir) yaklaşık% 20'dir.
Ağacın hızlı bir şekilde tekrarlanmasından sonra bu sayı% 70'e çıktı. Toplam 6 yineleme tamamladık ve son NN oldukça doğru oldu :-)
Eğitimden önce, pürüzlü kenarları düzeltmek için nesnelerin kenarlarına küçük şeritler ekledik ve çeşitli geliştirmeler yaptık: çevirme, rastgele kırpma, rastgele açı döndürme ve renk dönüştürme. Gördüğünüz gibi, bu yöntem, bir görüntü üzerinde birden çok nesne sınıfına açıklama eklemeniz gerekse bile birçok bilgisayarla görme görevi için uygundur.
ödül
Bu veri seti, yapay zeka destekli açıklama araçlarını geliştirmemize ve insanları tespit etmek için özelleştirmemize yardımcı oluyor. En son sürümümüzde, sistem içinde NN'yi eğitme özelliğini ekledik. Aşağıda, kategori tabanlı araçların özelleştirilmiş sürümleri ile karşılaştırılması verilmiştir. Mevcut, verilerinizi deneyebilirsiniz.
Veri kümesine nasıl erişilir
Supervisely'e kaydolun ve "İçe Aktar" sekmesine gidin- > "Veri kümeleri kitaplığı". "Supervisely Person" veri setine tıklayın ve yeni proje için bir isim yazın. Ardından "üç nokta" düğmesini tıklayın. > "Json formatında indir" - > "Başlangıç düğmesi. Bu şekilde, toplam indirme süresi 15 dakika (~ 7 GB) alabilir.
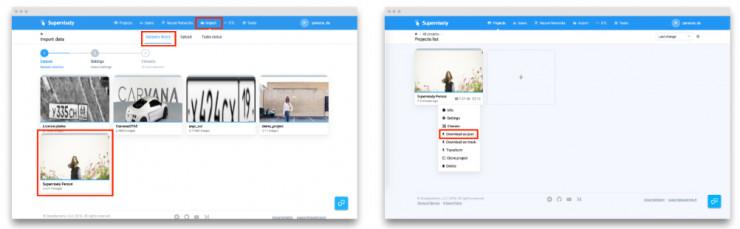
Sonuçlar nasıl indirilir
sonuç olarak
Makine öğrenimi geçmişi olmayan kişilerin tüm bu adımları nasıl tamamladığını görmek çok ilginç. Derin öğrenme uzmanları olarak çok zaman kazandık ve açıklama ekibimiz açıklama hızı ve kalitesi açısından daha verimli hale geldi.
Supervisely platformunun, her derin öğrenme ekibinin AI ürünlerini daha hızlı ve daha kolay hale getirmesine yardımcı olacağını umuyoruz.
Bu çalışmada kullandığımız en değerli Supervisely özelliklerini listeleyeyim:
1. "İçe Aktarma" modülü, tüm genel veri kümelerini yükleyebilir
2. Veri kümelerini işlemek, birleştirmek ve geliştirmek için "Veri Dönüştürme Dili"
3. "NN" modülü Daha Hızlı RCNN ve UnetV2 kullanır
3. "İstatistikler" modülü, sahip olduğumuz verilerden otomatik olarak faydalı içgörüler elde eder
4. "Ek açıklama", tıpkı Photoshop gibi verilerin "işbirliği" işlevini eğitmek için kullanılır, personelin açıklama ekibiyle birleştirilmesine, onlara görev atamasına ve tüm süreci kontrol etmesine olanak tanır.
Orijinal blog sitesi https://hackernoon.com/releasing-supervisely-person-dataset-for-teaching-machines-to-segment-humans-1f1fc1f28469
Leifeng.com ile ilgili tavsiyeler Leifeng.com
Makine öğrenimine nasıl başlayacağınızı bilmiyor musunuz? Bu bir başlangıç kılavuzu!
Lei Feng altyazı grubu işe alıyor
Aşağıdaki QR kodunu tarayın
"Lei Feng Altyazı Grubu + Adı" yorumları bize katılın