MySQL bilgi noktalarının özeti
Depolama motoru
Yaygın olarak kullanılan bazı komutlar
MySQL tarafından sağlanan tüm depolama motorlarını görüntüleyin
mysql > gösteri motorları;
MySQL tarafından sağlanan tüm depolama motorlarını görüntüleyin
Yukarıdaki şekilden, MySQL'in mevcut varsayılan depolama motorunun InnoDB olduğunu ve 5.7 sürümündeki tüm depolama motorları arasında yalnızca InnoDB'nin işlemsel bir depolama motorunu olduğunu görebiliriz, bu da yalnızca InnoDB'nin işlemleri desteklediği anlamına gelir.
MySQL'in mevcut varsayılan depolama motorunu görüntüleyin
Varsayılan depolama motorunu aşağıdaki komutla da görüntüleyebiliriz.
mysql > '% storage_engine%' gibi değişkenleri gösterin;Tablonun depolama motorunu görüntüleyin
"tablo_adı" gibi tablo durumunu gösterir;
Tablonun depolama motorunu görüntüleyin
MyISAM ve InnoDB arasındaki fark
MyISAM, MySQL'in varsayılan veritabanı motorudur (sürüm 5.5'ten önce). Performans mükemmel olmasına ve tam metin indeksleme, sıkıştırma, uzamsal işlevler vb. Dahil olmak üzere çok sayıda özellik sunmasına rağmen, MyISAM işlemleri ve satır düzeyinde kilitleri desteklemez ve en büyük kusur, bir çökme sonrasında güvenli bir şekilde kurtarılamamasıdır. Ancak, sürüm 5.5'ten sonra, MySQL InnoDB'yi (işlemsel veritabanı motoru) tanıttı.MySQL sürüm 5.5'ten sonra, varsayılan depolama motoru InnoDB'dir.
Çoğu zaman InnoDB depolama motorunu kullanıyoruz, ancak bazı durumlarda yoğun okuma gerektiren durumlarda MyISAM kullanmak da uygun oluyor. (MyISAM çökme yanıt sorununa aldırış etmezseniz).
İkisinin karşılaştırılması:
"MySQL High Performance" da şunu söyleyen bir cümle vardır:
"MyISAM InnoDB'den daha hızlıdır" gibi deneysel konuşmalara kolayca inanmayın. Bu sonuç genellikle mutlak değildir. Bilinen birçok senaryoda, InnoDB'nin hızı, özellikle kümelenmiş dizinlerin kullanıldığı veya erişilmesi gereken verilerin belleğe konulabildiği uygulamalar için MyISAM ile eşsiz olabilir.Normal şartlar altında, InnoDB'yi seçiyoruz sorun değil, ancak belirli durumlarda ölçeklenebilirlik ve eşzamanlılık umurunuzda değil, işlem desteğine ihtiyacınız yok ve bir çökme sonrasında güvenlik kurtarmayı umursamıyorsunuz, MyISAM'ı seçmek de iyi bir seçimdir . Ancak normal şartlar altında, hepimizin bu konuları dikkate alması gerekir.
Karakter kümesi ve harmanlama kuralları
Karakter kümesi, ikili kodlamadan belirli bir karakter sembolü türüne eşlemeyi ifade eder. Harmanlama kuralları, belirli bir karakter seti altındaki sıralama kurallarına atıfta bulunur. MySQL'deki her karakter seti bir dizi harmanlama kuralına karşılık gelir.
MySQL, karakter kümesinin varsayılan değerini belirtmek için benzer bir miras yöntemi kullanır.Her veritabanı ve her veri tablosunun, katman katman miras alınan kendi varsayılan değeri vardır. Örneğin: bir kitaplıktaki tüm tabloların varsayılan karakter kümesi, veritabanı tarafından belirtilen karakter kümesi olacaktır (bu tablolar, karakter kümesi belirtilmediği takdirde yalnızca varsayılan karakter kümesini kullanacaktır) Not: "The Way of Practice of Java Engineers
indeks
MySQL indeksi tarafından kullanılan veri yapısı esas olarak şunları içerir: BTree endeksi ile Hash indeksi . Bir karma dizini için temel veri yapısı bir karma tablodur, bu nedenle gereksinimlerin çoğu tek kayıt sorgusu için olduğunda, en hızlı sorgu performansına sahip bir karma dizini seçebilirsiniz; diğer senaryoların çoğu için bir BTree dizini seçmeniz önerilir.
MySQL'in BTree indeksi B numarasında B + Ağacı kullanır, ancak iki ana depolama motorunun uygulanması farklıdır.
- MyISAM: B + Ağaç yaprak düğümünün veri alanı, veri kaydının adresini depolar. İndeks alımı sırasında indeks ilk olarak B + Ağaç arama algoritmasına göre aranır Belirtilen Anahtar varsa, veri alanının değeri çıkarılır ve ardından adres olarak veri alanının değeri ile ilgili veri kaydı okunur. Buna "kümelenmemiş dizin" denir.
- InnoDB: Veri dosyasının kendisi dizin dosyasıdır. MyISAM ile karşılaştırıldığında, indeks dosyası ve veri dosyası ayrılmıştır Tablo veri dosyasının kendisi, B + Ağacı ile organize edilmiş bir indeks yapısıdır ve ağacın yaprak düğüm veri alanı tam veri kayıtlarını kaydeder. Bu dizinin anahtarı veri tablosunun birincil anahtarıdır, bu nedenle InnoDB tablo veri dosyasının kendisi birincil dizindir. Buna "kümelenmiş dizin (veya kümelenmiş dizin)" denir. Dizinlerin geri kalanı yardımcı dizinler olarak kullanılır Yardımcı dizinin veri alanı, yine MyISAM'dan farklı olan adres yerine karşılık gelen kaydın birincil anahtarının değerini depolar. Birincil dizine göre arama yaparken, verileri almak için anahtarın bulunduğu düğümü doğrudan bulabilirsiniz; ikincil dizine göre arama yaparken, önce birincil anahtarın değerini almanız ve ardından birincil dizine geçmeniz gerekir. Bu nedenle, bir tablo tasarlarken, birincil anahtar olarak çok uzun alanların kullanılması ve birincil dizinin sık bölünmesine neden olacak şekilde monoton olmayan alanların birincil anahtar olarak kullanılması önerilmez. Not: "The Way of Java Engineer Practice" den düzenlenmiştir
Dizinler hakkında daha fazla bilgi için lütfen belgenin ana sayfasındaki MySQL dizinindeki dizinlerin ayrıntılı özetini kontrol edin.
Sorgu önbelleğinin kullanımı
Bir sorgu ifadesi çalıştırılırken önce önbellek sorgulanır. Ancak, MySQL 8.0'dan sonra kaldırılacaktır çünkü bu işlev çok pratik değildir.my.cnf'ye aşağıdaki yapılandırmayı ekleyin, sorgu önbelleğini etkinleştirmek için MySQL'i yeniden başlatın
query_cache_type = 1 query_cache_size = 600000MySQL, aşağıdaki komutu çalıştırarak da sorgu önbelleğini açabilir
global query_cache_type = 1 olarak ayarlayın; global query_cache_size = 600000;Yukarıdaki gibi, Sorgu önbelleği açıldıktan sonra, aynı sorgu koşulları ve veriler altında sonuçlar doğrudan önbellekte döndürülür. . Buradaki sorgu koşulları, sorgunun kendisini, sorgulanacak mevcut veri tabanını, istemci protokolü sürüm numarasını ve sonuçları etkileyebilecek diğer bilgileri içerir. Bu nedenle, herhangi iki sorgu arasındaki herhangi bir karakterdeki herhangi bir fark, önbelleğin kaybolmasına neden olacaktır. Ek olarak, sorgu herhangi bir kullanıcı tanımlı işlev, saklanan işlev, kullanıcı değişkenleri, geçici tablolar ve MySQL kitaplığında sistem tabloları içeriyorsa, sorgu sonuçları önbelleğe alınmayacaktır.
Önbellek oluşturulduktan sonra, MySQL'in sorgu önbellek sistemi sorguya dahil olan her tabloyu izleyecektir.Bu tablolar (veri veya yapı) değişirse, bu tabloyla ilgili önbelleğe alınmış tüm veriler geçersiz olacaktır.
Önbellek veritabanının sorgu performansını iyileştirebilmesine rağmen, önbellek ayrıca ek yük getirir.Her sorgudan sonra bir önbellek işlemi gerekir ve geçersiz kıldıktan sonra yok edilmesi gerekir. Bu nedenle, özellikle yazma yoğunluklu uygulamalar için önbelleğe alınmış sorguları etkinleştirirken dikkatli olmanız gerekir. Etkinleştirilmişse, önbellek alanının boyutunu makul şekilde kontrol etmeye dikkat edin.Genel olarak, boyutu onlarca MB olarak ayarlamak uygundur. Ek olarak, Ayrıca, bir sorgu ifadesinin önbelleğe alınması gerekip gerekmediğini kontrol etmek için sql_cache ve sql_no_cache'yi de kullanabilirsiniz:
usr'den sql_no_cache count (*) seçin;İşlem nedir?
İşlem, hepsi yürütülür veya hiçbiri yürütülmez, mantıksal bir işlem kümesidir.
En klasik işlem genellikle bir transfer örneği olarak gösterilmektedir. Xiao Ming, Xiaohong'a 1000 yuan transfer etmek isterse, bu transfer iki temel işlemi içerecektir: Xiao Ming'in bakiyesini 1000 yuan düşürmek ve Xiaohong'un bakiyesini 1000 yuan artırmak. Bu iki işlem arasında, Xiaoming'in dengesinin düşmesine neden olan bir bankacılık sisteminin çökmesi gibi ani bir hata varsa, ancak Xiaohong'un bakiyesi artmıyorsa, bu yanlıştır. İşlem, bu iki anahtar işlemin başarılı olmasını veya her ikisinin de başarısız olmasını sağlamaktır.
Şeylerin dört özelliği (ASİT)
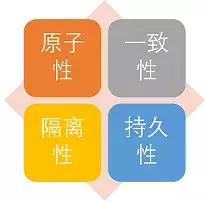
Şeylerin özellikleri
Eşzamanlı işlemlerin neden olduğu sorunlar nelerdir?
Tipik bir uygulamada, birden çok işlem aynı anda çalışır ve genellikle görevlerini tamamlamak için aynı verileri kullanır (birden çok kullanıcı birleştirilmiş veriler üzerinde çalışır). Eşzamanlılık gerekli olsa da aşağıdaki sorunlara neden olabilir.
- Kirli okuma: Bir işlem veriye erişip verileri değiştirdiğinde ve bu değişiklik henüz veri tabanına kaydedilmediğinde, başka bir işlem de verilere erişir ve ardından verileri kullanır. Bu veriler henüz kaydedilmemiş veriler olduğundan, başka bir işlem tarafından okunan veriler "kirli veriler" dir ve "kirli verilere" dayalı işlem yanlış olabilir.
- Değiştirmek için kayıp: Bir işlem bir veri parçasını okuduğunda, başka bir işlem de verilere eriştiğinde, daha sonra birinci işlemde veri değiştirildikten sonra, ikinci işlem de verileri değiştirir. Bu şekilde, ilk işlemdeki değişikliğin sonucu kaybolur, dolayısıyla kayıp değişiklik denir. Örneğin: İşlem 1 bir tablodaki A = 20 verisini okur, işlem 2 ayrıca A = 20 okur, işlem 1 A = A-1'i değiştirir, işlem 2 ayrıca A = A-1'i değiştirir, nihai sonuç A = 19, işlem 1'in değiştirilmesi kayboldu.
- Unrepeatableread: Bir işlemde aynı verileri birden çok kez okumayı ifade eder. Bu işlem bitmeden başka bir işlem de verilere erişir. Daha sonra, birinci işlemdeki iki veri okuması arasında, birinci işlemde iki kez okunan veriler, ikinci işlemin modifikasyonu nedeniyle farklı olabilir. Bu, bir işlemde iki kez okunan veriler farklı olduğunda meydana gelir, bu nedenle buna tekrarlanamayan okuma denir.
- Hayalet okuma: Hayali okuma, tekrarlanamayan okumaya benzer. Bir işlem (T1) birkaç satır veri okuduğunda ve daha sonra başka bir eşzamanlı işlem (T2) bazı verileri eklediğinde gerçekleşir. Sonraki sorguda, ilk işlem (T1), sanki bir yanılsama meydana gelmiş gibi, orijinal olarak var olmayan daha fazla kayıt olduğunu bulacaktır, bu nedenle buna hayali okuma denir.
Tekrarlanamazlık ve hayali okuma arasındaki fark:
Tekrarlanamayan okumanın odak noktası değişikliktir.Örneğin, bir kaydı birden çok kez okumak, bazı sütunların değerinin değiştirildiğini bulur. Hayali okumanın odağı ekleme veya silme. Örneğin, bir kaydı birden çok kez okumak, kayıt sayısının arttığını veya azaldığını bulur.
İşlem izolasyon seviyeleri nelerdir? MySQL'in varsayılan izolasyon seviyesi nedir?
SQL standardı dört izolasyon seviyesini tanımlar:
- READ-UNCOMMITTED (onaylanmadan oku): Henüz gönderilmemiş veri değişikliklerinin okunmasına izin veren en düşük izolasyon seviyesi, Kirli okumalara, hayali okumalara veya tekrarlanamayan okumalara neden olabilir .
- OKUMA BAŞLADI (okuma gönderildi): Eşzamanlı işlemlerle işlenen verilerin okunmasına izin verir, Kirli okumalar engellenebilir, ancak hayali okumalar veya tekrarlanamayan okumalar yine de meydana gelebilir .
- TEKRARLANABİLİR-OKUNUR (tekrarlanabilir okuma): Veriler işlemin kendisi tarafından değiştirilmedikçe, aynı alandaki birden fazla okumanın sonuçları tutarlıdır, Kirli okumalar ve tekrarlanamayan okumalar engellenebilir, ancak hayali okumalar yine de meydana gelebilir .
- SERİLEŞTİRİLEBİLİR (serileştirilebilir): En yüksek izolasyon seviyesi, ACID izolasyon seviyesine tam olarak uyar. Tüm işlemler tek tek gerçekleştirilir, böylece işlemler arasında herhangi bir çakışma ihtimali kalmaz, Bu seviye, kirli okumaları, tekrarlanamayan okumaları ve hayali okumaları önleyebilir .
İzolasyon seviyesi kirli okuma tekrarlanamaz okuma fantom okuma OKUMA-HABERLEŞTİRİLMEDİ OKUMA-DEVAM EDİLDİ × TEKRARLANABİLİR-OKUMA ×
MySQL InnoDB depolama motoru tarafından desteklenen varsayılan izolasyon seviyesi TEKRARLANABİLİR-OKUMA (yeniden okunabilir) . Görüntülemek için SELECT @@ tx_isolation; komutunu kullanabiliriz
mysql > SEÇ @@ tx_isolation; + ----------------- + | @@ tx_isolation | + ----------------- + | TEKRARLANABİLİR-OKUNABİLİR | + ----------------- +Burada not edilmelidir: SQL standardından farkı, InnoDB depolama motorunun TEKRARLANABİLİR-OKUMA (yeniden okunabilir) Next-Key Lock kilit algoritması, işlem izolasyon seviyesinde kullanılır, böylece diğer veritabanı sistemlerinden (SQL Server gibi) farklı olan hayali okuma oluşumunu önleyebilir. Dolayısıyla, InnoDB depolama motoru tarafından desteklenen varsayılan yalıtım düzeyi TEKRARLANABİLİR-OKUMA (yeniden okunabilir) İşlemin izolasyon gereksinimlerini tam olarak garanti edebilir, yani SQL standardını karşılayabilir SERİLEŞTİRİLEBİLİR (serileştirilebilir) İzolasyon seviyesi.
İzolasyon seviyesi ne kadar düşükse, işlem isteklerini o kadar az kilitler, bu nedenle çoğu veritabanı sisteminin izolasyon seviyesi TAMAMLANDI (gönderilen içeriği oku): , Ancak bilmeniz gereken, InnoDB depolama motorunun TEKRARLANABİLİR-OKUMA (yeniden okunabilir) Performans kaybı olmayacak.
InnoDB depolama motoru Dağıtılmış işlem Bu durumuda SERİLEŞTİRİLEBİLİR (serileştirilebilir) İzolasyon seviyesi.
Kilitleme mekanizması ve InnoDB kilit algoritması
MyISAM ve InnoDB depolama motorları tarafından kullanılan kilitler:
- MyISAM, tablo düzeyinde kilitleme kullanır.
- InnoDB, satır düzeyinde kilitlemeyi ve masa düzeyinde kilitlemeyi destekler; varsayılan, satır düzeyinde kilitlemedir
Masa seviyesinde kilitler ile sıra seviyesinde kilitlerin karşılaştırması:
- Masa düzeyinde kilit: MySQL'de kilitleniyor Maksimum partikül boyutu Uygulanması kolay, daha az kaynak tüketen, hızlı kilitlenen ve kilitlenmeye neden olmayan mevcut operasyonun tüm tablosunu kilitleyen bir çeşit kilit. En büyük kilitleme granülerliğine, en yüksek kilit çakışmalarını tetikleme olasılığına ve en düşük eşzamanlılığa sahiptir.Hem MyISAM hem de InnoDB motorları masa düzeyinde kilitleri destekler.
- Satır düzeyinde kilit: MySQL'de kilitleniyor En küçük partikül boyutu Yalnızca geçerli işlem satırını kilitleyen bir kilit türü. Satır düzeyinde kilitler, veritabanı işlemlerindeki çakışmaları büyük ölçüde azaltabilir. Kilitleme ayrıntı düzeyi en küçüktür ve eşzamanlılık yüksektir, ancak kilitlemenin ek yükü de en büyüğüdür ve kilitleme yavaştır ve kilitlenmeler meydana gelir.
InnoDB depolama motoru için üç kilit algoritması vardır:
- Kayıt kilidi: tek satırlık bir kaydın kilidi
- Aralık kilidi: boşluk kilidi, kaydın kendisi hariç bir aralığı kilitle
- Sonraki tuş kilidi: kayıt + boşluk, kaydın kendisi de dahil olmak üzere bir aralığı kilitler
İlgili bilgi noktaları:
Büyük tablo optimizasyonu
Tek bir MySQL tablosundaki kayıt sayısı çok büyük olduğunda, veritabanının CRUD performansı önemli ölçüde azalacaktır. Bazı yaygın optimizasyon önlemleri aşağıdaki gibidir:
1. Verilerin kapsamını sınırlayın
Veri aralığını kısıtlayan herhangi bir koşul olmaksızın sorgu ifadelerini yasakladığınızdan emin olun. Örneğin: kullanıcıların sipariş geçmişini sorguladıklarını bir ay içinde kontrol edebiliriz;
2. Ayrımı oku / yaz
Klasik veri tabanı bölme şemasında, ana kütüphane yazmaktan, slave kütüphane ise okumaktan sorumludur;
3. Dikey bölüm
Veritabanındaki veri tablolarının korelasyonuna göre bölün. Örneğin, kullanıcı tablosu hem kullanıcının oturum açma bilgilerini hem de kullanıcının temel bilgilerini içeriyorsa, kullanıcı tablosu iki ayrı tabloya bölünebilir veya hatta alt veritabanı için ayrı bir veritabanına konulabilir.
Basitçe ifade etmek gerekirse, dikey bölme, veri tablosu sütunlarının bölünmesi, birçok sütun içeren bir tablonun birden çok tabloya bölünmesi anlamına gelir. Aşağıdaki şekilde gösterildiği gibi, herkesin anlaması daha kolay olmalıdır.
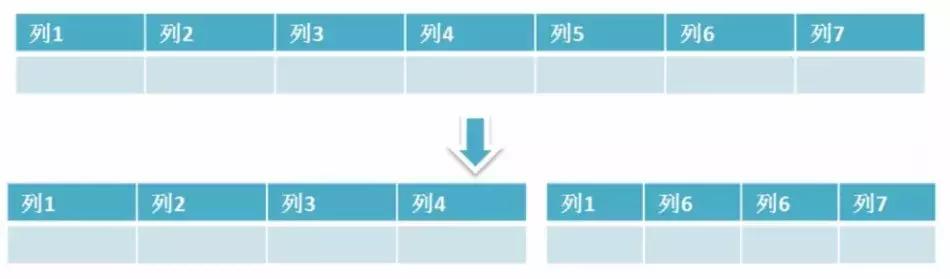
Veritabanı dikey bölümü
- Dikey bölünmenin avantajları: Sütun verilerini küçültebilir, sorgu sırasında okunan blok sayısını azaltabilir ve G / Ç sayısını azaltabilir. Ek olarak, dikey bölümleme tablonun yapısını basitleştirebilir ve bakımı kolaydır.
- Dikey bölünmenin dezavantajları: Birincil anahtar fazlalık olacak, yedek sütunların yönetilmesi gerekecek ve uygulama katmanında katılarak çözülebilecek bir Birleştirme işlemine neden olacaktır. Ek olarak, dikey bölümleme işlemleri daha karmaşık hale getirecektir;
4. Yatay Bölme
Veri tablosu yapısını değiştirmeden tutun ve veri parçalarını belirli bir strateji ile saklayın. Bu şekilde, her veri parçası farklı tablolara veya kitaplıklara dağıtılarak dağıtım amacına ulaşılır. Yatay bölme, çok büyük miktarda veriyi destekleyebilir.
Yatay bölme, veri tablosu satırlarının bölünmesini ifade eder. Tablodaki satır sayısı 2 milyon satırı aştığında yavaşlayacaktır. Şu anda, bir tablonun verileri depolama için birden çok tabloya bölünebilir. Örneğin, kullanıcı bilgileri tablosunu birden çok kullanıcı bilgisi tablosuna bölebiliriz, böylece çok büyük olan tek bir tablonun performans etkisini önleyebiliriz.
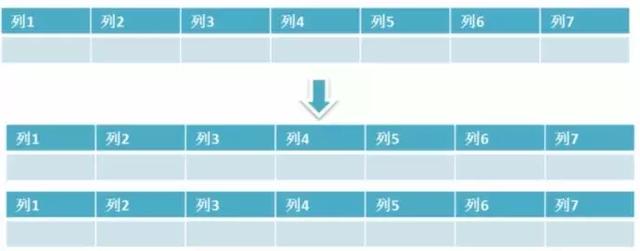
Veritabanı yatay bölme
Yatay bölme çok büyük miktarda veriyi destekleyebilir. Unutulmaması gereken bir nokta şudur: tablo bölme, yalnızca tek bir tablodaki çok büyük veri sorununu çözer, ancak tablodaki veriler hala aynı makinede olduğundan, aslında MySQL eşzamanlılığını iyileştirmek için hiçbir anlamı yoktur. Yatay bölme için en iyi alt kütüphane .
Yatay bölünmüş kutu Çok az uygulama tarafı dönüşümüyle çok büyük miktarda veri depolamayı destekler ,fakat Parçalanmış işlemlerin çözülmesi zordur , Cross-node Join zayıf performansa ve karmaşık mantığa sahiptir. "The Practice of Java Engineers" kitabının yazarı tarafından önerilmektedir Verileri parçalamamaya çalışın, çünkü bölünme çeşitli mantık, dağıtım, işletim ve bakım karmaşıklığı getirecektir. Doğru bir şekilde optimize edildiğinde, genel bir veri tablosunun on milyonlarca veri hacmini desteklemesinde büyük bir sorun yoktur. Gerçekten parçalamak istiyorsanız, istemci parçalama mimarisini seçmeye çalışın, bu da ağ G / Ç'sini ve ara yazılımları bir kez azaltabilir.
Veritabanı parçalanması için iki yaygın senaryo şunlardır:
- Müşteri temsilcisi: Parçalanma mantığı uygulama tarafındadır, bir jar paketinde kapsüllenir ve JDBC katmanını değiştirerek veya kapsülleyerek uygulanır. Dang dang Sharding-JDBC Ali'nin TDDL'si yaygın olarak kullanılan iki uygulamadır.
- Ara yazılım aracısı: Uygulama ile veriler arasına bir proxy katmanı eklenir. Parçalanma mantığı, ara yazılım hizmetinde tek tip olarak korunur. Hakkında konuşuyoruz Benim kedim , 360's Atlas, Netease's DDB, vb. Bu mimarinin uygulamalarıdır.