ACL 2018 Bilgi Teknolojileri Enstitüsü, Çin Bilimler Akademisi: Bilgi grafiğinin temsili öğrenimini iyileştirmek için basit kısıtlamaları kullanma
Ekstra! En iyi toplantı kağıt kuru ürünlerinden başka bir grup geliyor!
9-10 Haziran 2018, Çin Bilgi Toplumu Gençlik Çalışma Komitesi ve Baidu Company tarafından ortaklaşa düzenlenen "AIS2018 (ACL, IJCAI, SIGIR) Thesis Preliminary Lecture", akademiyi ve sektörü temsil eden en iyi değişim etkinliği ] Pekin'de görkemli bir şekilde düzenlendi. İki gün içinde, "duyarlılık analizi", "öneri sistemi", "makine sorusu yanıtlama" ve "diyalog sistemi" gibi farklı konulardaki en önemli konferans kağıdı raporları bir araya geldi.
Xinjun'un anlayışına göre, bu ön dersin akademik çevrede popülaritesi, organizatörün hayal gücünü tamamen aştı.Açık kayıt sadece birkaç gün içinde tamamlandı, böylece organizatörün katılımcıları taramak için koşullar belirlemesi gerekiyordu.
Bu ders öncesi toplantının etkinlik ortamı olarak Duxinjun, tüm süreç boyunca konferansı takip edecek ve etkinlikte en son bakış açılarını ve en değerli sonuçları kaydedecek.Özel olarak davet edilen ders öncesi bildiri konuşmacıları, okuyucular ve arkadaşlar için ortaklaşa başlayacak. Ön ders dizisi size zirvenin en son kağıt sonuçlarını gösterecek
Çekirdek okuyucuların kağıt değişim grubu için lütfen WeChat hesabımızı ekleyin: Zhizhizhuji . Senin için bekleniyor.

ACL 2018
Bilgi grafiğinin temsili öğrenimini iyileştirmek için basit kısıtlamalar kullanın
Basit Kısıtlamalar Kullanarak Bilgi Grafiği Gömmeyi İyileştirme
Bilgi Mühendisliği Enstitüsü, Çin Bilimler Akademisi
Bilgi Mühendisliği Enstitüsü, Çin Bilimler Akademisi
[Özet] Bilgi grafiğindeki varlıkların ve ilişkilerin vektörleştirilmiş temsillerinin elde edilmesi, yani temsil öğrenme, son yıllarda bir araştırma noktası olmuştur ve ilgili teknolojiler büyük ölçekli bilgi muhakemesi için kullanılabilir. İlk modeller, demetler üzerinde basit modeller tanımlayarak bu görevi başardı. Son zamanlarda yapılan bazı girişimler, temel model üzerinde harici bilgilerin kullanılmasını ve daha karmaşık demet modelleri tasarlamayı içerir. Bu çalışmada, temel modele bazı basit kısıtlamalar getirerek temsil öğrenmenin etkisini iyileştirmek için başka bir fikir deniyoruz. Varlıklara negatif olmayan sınırlamalar eklemeyi ve ilişkilere dolaylı kısıtlamalar eklemeyi düşündük. İlki, daha kompakt ve yorumlanabilir varlık vektörlerini öğrenmemize yardımcı olabilir; ikincisi, mantıksal çıkarım yapısını ilişkinin dağıtılmış temsiline kodlar. . Bu basit kısıtlamalar, temel modelin karmaşıklığını artırmadan performansı artırabilir. FB15K, WN18 ve DB100K genel veri setleri üzerinde testler yaptık ve bu basit kısıtlamanın temel modelin performansını önemli ölçüde artırabileceğini ve performansın bazı daha karmaşık modellerden bile daha iyi olduğunu kanıtladık.Ayrıca varlık ve ilişki vektörlerinin performansını da test ettik. Yorum görsel bir analiz yaptı, kodumuz ve verilerimiz https://github.com/iieir-km/ComplEx-NNE_AER üzerinden elde edilebilir.

1. Giriş
Geçtiğimiz birkaç on yılda, büyük ölçekli bilgi grafikleri muazzam bir gelişme kaydetti ve WordNet, Freebase ve GoogleKnowledge Valut gibi projeler doğdu. Bilgi grafiği resmi olarak üçlü bir set olarak temsil edilebilir
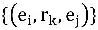
,onların arasında
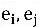
Bir varlıktır,

Bu bir ilişki. Bu yapılandırılmış bilgi temsili, soru yanıtlama, akademik erişim, makine okuma vb. Gibi doğal dil işleme ve bilgi erişiminin birçok aşağı akış uygulaması için zengin bir arka plan bilgisi sağlar ve çok geniş bir uygulama alanına sahiptir.
Son yıllarda, bilgi grafiklerinin temsili öğrenimi yaygın bir ilgi gördü.Anahtar fikir, varlıkların ve ilişkilerin vektörleştirilmiş bir temsilini elde etmektir.Bu vektörleştirilmiş gösterim, grafiğin iç yapısını korurken işlemleri basitleştirir. Bu yöndeki erken keşifler çoğunlukla demet verilerini kullandı ve bunun üzerine basit puanlama modelleri tasarladı. Bu tür bir temel model verimli olsa da muhakeme doğruluğu sınırlıdır. Son zamanlarda yapılan bazı çalışmalarda, muhakemenin doğruluğunu daha da iyileştirmek için başlıca iki yol vardır: İlk yol, metin, mantıksal kurallar vb. Gibi harici verileri kullanmaktır, ancak bu yol belirli verilere bağlı olacaktır ve genellikten yoksundur; ikinci yol Daha karmaşık bir model tasarlamaktır, ancak bu yöntem aynı zamanda hesaplama maliyetini de artıracaktır.
Bu çalışmada, temel modele bazı basit kısıtlamalar eklemeye çalışıyoruz.Özellikle, varlıklara negatif olmayan kısıtlamalar ve ilişkilere yaklaşık ima kısıtlamaları ekliyoruz. İlki, varlık vektörlerinin negatif olmayan bir vektör uzayında olmasını gerektirir. Negatif olmama, kelime vektörleriyle sınırlıdır. Matris çarpanlarına ayırma alanı kapsamlı bir şekilde incelenmiştir. Olumsuzluk, daha kompakt ve seyrek vektör gösterimleri elde etmemizi sağlayabilir. Ortaya çıkan vektör daha yorumlanabilir. İkincisi, mantıksal çıkarım yapısını vektörün temsiline kodlayabilir. Temel model üzerinde mantıksal kuralları kullanmadan önce birçok çalışma yapılmıştır. Bizimkine çok benzeyen bir çalışma, aynı zamanda sıralı gömme yöntemini de kullanan bu çalışmadır. Mantıksal çıkarım, vektörün temsiline kodlanmıştır, ancak bu çalışma esas olarak varlık çiftlerini modellemek içindir ve eğitim setinde görünmeyen varlık çiftlerini tahmin edemez.Aynı zamanda, bu yöntem, modelleme yaklaşımı olmaksızın yalnızca katı uygulama kurallarını dikkate alır. Seks.
Sonunda, yöntemin performansını halka açık veri setinde test ettik ve üç veri setindeki karşılaştırma yöntemini önemli ölçüde aştı ve hatta bazı karmaşık derin ağ tabanlı modellerden daha iyi. Aynı zamanda, öğrenilen varlıkların ve ilişki vektörlerinin yorumlanabilirliğinin görsel bir analizini de yaptık ve basit kısıtlamalar ekledikten sonra modelin daha iyi yorumlanabilirliğe sahip olduğunu kanıtladık.
2. İlgili çalışma
Üç ana ilgili çalışma türü vardır:
İlk kategori, yer değiştirme tabanlı model TransE ve varyantları ve anlamsal eşleştirme tabanlı model RESCAL ve varyantları dahil olmak üzere temel temsil öğrenme modellerini içerir. Bu modeller yalnızca demet bilgisini kullanır. Bu temel modellere dayalı olarak, bazı modeller, ilişkisel yolları ve metin bilgisini kullanmak gibi, temsil öğreniminin performansını iyileştirmek için dış bilgileri kullanır. Ek olarak, bazı modeller performansı artırmak için daha karmaşık puanlama işlevleri tasarlar.Örneğin, bu çalışmada, evrişimli sinir ağları puanlama işlevlerini tasarlamak için kullanılır.
Bizimle ilgili ikinci çalışma türü, mantıksal kurallar modelini kullanmaktır, ancak yukarıdaki çalışmaların çoğu, uzay ve zamanda nispeten verimsiz olan mantıksal kuralların somutlaştırılmasını gerektirir; somutlaştırmayı önlemek için, sıralı gömme yöntemi benimsenmiştir, ancak bu Bu makaledeki çalışma esas olarak varlık çiftlerini modellemeyi amaçlamaktadır ve eğitim setinde yer almayan varlık çiftlerini tahmin edemez.Aynı zamanda, bu yöntem modelleme yaklaşımı olmadan yalnızca katı uygulama kurallarını dikkate alır; bu çalışmada, yüzleşme ağı aracılığıyla yapılır. Somutlaştırmayı önlemek için. Bize en yakın çalışma, ancak bu çalışma yalnızca denklik ve ters çıkarımları ele alıyor ve genel çıkarımlara genellemiyor ve güveni modelleyemez.
Bizimle ilgili üçüncü çalışma türü negatif olmayan temsil öğrenmesidir.Olumsuzluk birçok alanda çalışılmıştır. Önceki çalışmalar negatif olmamanın öğrenilen vektörün seyrekliğine yol açabileceğini ve daha fazlasını öğrenebileceğini göstermiştir. Yorumlanabilir vektör gösterimi. Kelime vektörleri üzerine yapılan bazı araştırmalarda, negatif olmayan kısıtların uygulanmasının daha fazla temsil edilebilir vektörleri öğrenebileceği de belirtilmiştir.
3 yöntem
İlk önce demetleri modellemek için kullanılan temel modeli tanıtıyoruz, ardından negatif olmayan kısıtlamaları ve yaklaşık çıkarım kısıtlamalarını tanıtıyoruz ve son olarak son modeli veriyoruz.
3.1 Temel model
ComplEx'i şu anda en iyi performans gösteren temel temsil öğrenme modellerinden biri olan temel gömme modeli olarak kullanıyoruz. ComplEx, varlıkları ve ilişkileri karmaşık vektörler olarak temsil eder
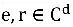
, Her karmaşık vektör
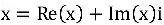
Ve ardından bir puanlama işlevi tanımlayın
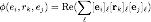
Her bir demet için, puanlama fonksiyonu, demetin kurulma olasılığını ölçmek için bir puan hesaplar.Skor ne kadar yüksekse, kurulma olasılığı o kadar yüksek olur.
3.2 Negatif olmayan varlık kısıtlamaları
Varlığın negatif olmayan kısıtlaması, varlık vektörünün negatif olmayan bir alanda olmasını gerektirir. Özellikle,
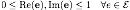
Negatif olmayan varlık vektörleri yalnızca bilgiyi daha verimli bir şekilde kodlayabilen pozitif anlamlar içerir. Örneğin, "Paris" varlığı için, pozitif anlambilimin yalnızca "Paris, Fransa'nın başkentidir" kodlaması gerekirken, negatif anlambilimin "Paris, Çin değildir" ifadesini kodlaması gerekir. Paris, Amerika Birleşik Devletleri'nin başkenti değil ve Paris, Rusya'nın başkenti değil ... Aslında bilgi fazlalığına neden olacak. Ek olarak, negatif olmayan vektörler seyrekliğe de yol açabilir, bu da daha seyrek gösterimleri öğrenmemize ve böylece daha yorumlanabilir varlık vektörleri elde etmemize olanak tanır.
3.3 İlişkisel yaklaşık uygulama kısıtlamaları
Negatif olmayan kısıtlamaya ek olarak, aşağıdaki gibi yazılabilecek, ilişkinin yaklaşık uygulama kısıtlamasını da dikkate alıyoruz.
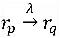
, Yaklaşık uygulama kısıtlaması, iki ilişki için
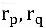
Birincisi, ikincisine yaklaşabilir. Örneğin, birinin doğduğu yeri (doğduğu yeri) bildiğimiz anlamına gelir ve yüksek bir olasılıkla, kişinin milliyetini (milliyeti) çıkarabiliriz. Her yaklaşık çıkarımın bir ağırlığı vardır
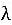
, Çıkarımın oluşturulduğuna dair güveni temsil eder, ağırlık arttıkça güven artar. Bu tür örtük kısıtlamalar, kural madenciliği sistemi tarafından otomatik olarak tuplelardan çıkarılabilir.
Yaklaşık çıkarım kısıtlamalarını modellemek için, ilk olarak uygulama kısıtlamalarını modelliyoruz Bilgi grafiğinde, uygulama kısıtlamalarını aşağıdaki şekilde modelleyebiliriz
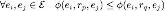
Bu formülün anlamı, herhangi bir varlık çifti için şunu söylemektir.
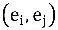
,bu durumda
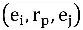
Doğrudur ve daha yüksek puan alırsa
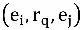
Her zaman doğru ve daha yüksek puanlar alacak. Ancak bu tür bir kısıtlama çözümümüz için elverişli değildir, çünkü tüm varlık çiftlerini geçmemiz gerekir, bu nedenle yeniden yazmak için sıralı gömme yöntemini kullanırız, bu durumda yukarıdaki formülün yeterli bir koşulu:
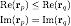
Bu şekilde, her örtük kısıtlama için yalnızca iki ilişkisel vektörün hesaplanması dahil edilir ve hesaplama miktarı büyük ölçüde azaltılır.
Son olarak, modellemenin yaklaşık çıkarımını ele alıyoruz Burada, gevşek değişken modellemenin yaklaşık çıkarımını sunuyoruz ve son yaklaşık çıkarım kısıtlamaları aşağıdaki gibi elde edilebilir.Yukarıdaki spesifik türetme ayrıntıları için lütfen orijinal makalenin ekine bakın.
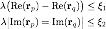
3.4 Son model
Temel modelle birleştirildiğinde, amaç fonksiyonumuz şu şekilde tanımlanabilir:
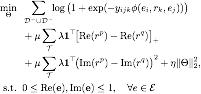
Bunlar arasında, amaç fonksiyonundaki ilk terim, lojistik kaybın kullanıldığı demetleri modellemektir ve ikinci terim, bir menteşe kaybı olan yaklaşık çıkarım kısıtlamasının gerçek kısmının kısıtlamasıdır.

, Kısıtlamanın ihlali olarak kabul edilir, ne kadar büyük olursa ihlal derecesi o kadar büyükse, eğer

, Kısıtlamaların ihlali söz konusu değildir ve herhangi bir ceza verilmez. Üçüncü terim, iki sanal parçayı eşit olmaya zorlayarak yaklaşık çıkarım kısıtlamasının sanal parça kısıtlamasını modellemek için kullanılan kare bir terimdir ve ilgili türetme ayrıntıları orijinal makaleye atıfta bulunabilir. Son öğe
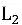
Normal, fazla takmayı önlemek için kullanılır.
3.5 Karmaşıklık analizi
Modelin olumsuzluk ve çıkarımla karmaşıklığı
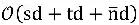
, D boyut olduğunda, sd demetleri modellemek için kullanılan orijinal ComplEx modelinin karmaşıklığıdır; td, yaklaşık örtük kısıtlamaların karmaşıklığıdır ve t, bilgi grafiğindeki tuplelardan çok daha küçük olan yaklaşık örtük kısıtlamaların sayısıdır. Sayı bir sabit olarak tahmin edilebilir,

Negatif olmayan kısıtlamaların neden olduğu karmaşıklık,
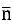
Bir mini partideki ortalama varlık sayısıdır Basit kısıtlı modelin, çok verimli bir algoritma olan temel model ile aynı karmaşıklık seviyesine sahip olduğu görülebilir.
4 deney
Deneyimiz iki bölüme ayrılmıştır: İlk bölüm, daha önce birçok ilgili çalışmada temsil öğrenmenin performansını test etmek için yapılmış bir bağlantı tahmin deneyidir, ikinci bölüm ise varlık ilişki vektörlerinin yorumlanabilirliğinin görsel bir analizidir.
4.1 Veri seti
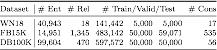
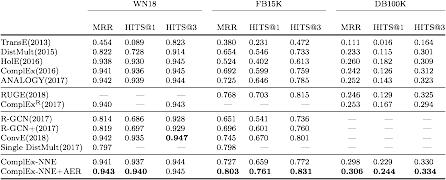
WN18, FB15K ve DB100k olmak üzere üç veri seti üzerinde deneyler yaptık. WN18 ve FB15K, ilk olarak bu çalışmada yayınlanan Freebase'in bir alt kümesi olan WordNet'tir, DB100K, DBPedia'da çıkardığımız şeyin bir alt kümesidir. Her veri setinin istatistiksel verileri aşağıdaki gibidir; burada #Ent, #Rel, # Train / Valid / Test, #Cons, varlıkların sayısını, ilişki sayısını, eğitim / doğrulama / test setindeki tuple sayısını ve yaklaşık uygulama kısıtlamalarını temsil eder.
Uygulama kısıtlamaları, otomatik kural çıkarma yazılımı AMIE + ile elde edilir. Her veri kümesindeki kurallar (yukarıdan aşağıya, WN18, FB15K, DB100k) aşağıdaki gibidir:

4.2 Bağlantı tahmini
Bağlantı tahmin görevi, eksik baş veya kuyruk varlıklarının bir demeti verilen karşılık gelen baş ve kuyruk varlıklarını tahmin etmektir. Değerlendirmede, her bir demetin baş (kuyruk) varlıkları için bir dizi test demeti verildiğinde, bunları test grupları dışında bilgi grafiğinde görünmeyen varlıklarla rastgele değiştirin ve ardından bu öğeleri hesaplayın Grubun puanı elde edilir ve ilgili test demetinin r sıralaması elde edilir. Bu sıralamaya göre iki gösterge hesaplanır,
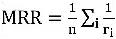
Ortalama ters değer mi,
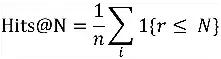
,onların arasında
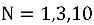
, Bu, en üst N'deki doğru dizilerin oranını temsil eder.
Seçtiğimiz üç tür karşılaştırma yöntemi vardır: İlk tür temel modeldir. Bu tür model yalnızca demet bilgilerini kullanır ve puanlama işlevi basittir.
İkinci model türü, mantıksal kuralları birleştiren bir modeldir,
Üçüncü tip modeller, derin sinir ağlarına dayalı modeller de dahil olmak üzere son zamanlarda en iyi sonuçları elde eden ve performansı artırmak için çok sayıda olumsuz örnek kullanan daha karmaşık modellerden bazılarıdır.
Tablodan, ComplEx-NNE'nin (negatif olmayan varlık kısıtlamaları eklenmiş ComplEx modeli) ve ComplEx-NNE + AER'nin (negatif olmayan varlık ve ilişki uygulama kısıtlamaları eklenmiş model) ComplEx'i önemli ölçüde iyileştirebileceğini görebiliriz. ComplEx-NNE-AER'nin performansı, temel modelleri, mantıksal kuralları kullanan modelleri ve derin sinir ağlarına dayalı modeller dahil bazı karmaşık modelleri içeren karşılaştırma yönteminden önemli ölçüde daha iyidir. Bu basit kısıtlamanın, hesaplama verimliliğini sağlarken performansı önemli ölçüde artırabileceği görülebilir.
4.3 Görsel analiz
Daha sonra, varlıkların ve ilişkilerin yorumlanabilirliğinin görsel bir analizini yapıyoruz.
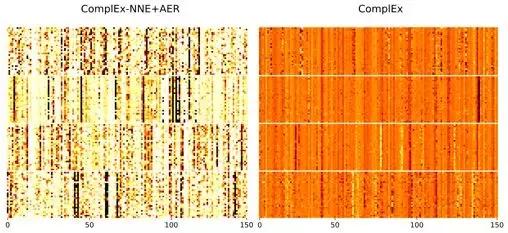
4.3.1 Varlık anlamsal dağılımının ısı haritası
Dört kategoriden (sürüngen, şarap_ bölgesi, türler, programlama_dil yukarıdan aşağıya) rastgele 30 varlık seçtik, bu varlık vektörlerini istifledik (yatay eksen boyutu temsil eder) ve ardından ısı haritasını çizdik. Renk ne kadar koyu olursa, değeri o kadar büyük gösterir.Şekilden, kısıtlı model tarafından öğrenilen vektörün (solda), kısıtlanmamış model tarafından öğrenilen vektöre (sağda) göre daha seyrek olduğunu görebiliriz; aynı zamanda, Soldaki şekilde, aynı türden varlıklar aynı boyutları tutarlı bir şekilde etkinleştirebilir, bu da bu türlerin anlamlarının da bu boyutlarda yoğunlaştığını gösterir:
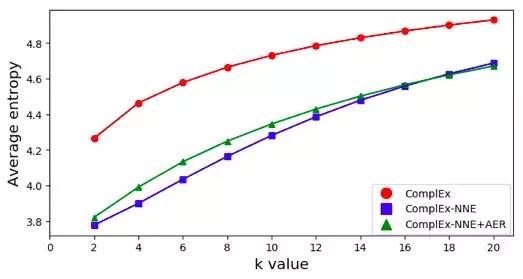
4.3.2 Varlık semantik saflık eğrisi
Anlamsal saflık, bir boyut için, boyutun daha büyük değerlerine sahip varlıkların mümkün olduğunca aynı kategoriye ait olması gerektiği anlamına gelir. Anlamsal saflığı ölçmek için entropi kullanırız. Entropi ne kadar düşükse, anlamsal saflık o kadar yüksek olur. Şekil, ComplEx, ComplEx-NNE ve ComplEx-NNE-AER'nin her boyutta ortalama anlamsal saflığını göstermektedir .. ComplEx-NNE ve ComplEx-NNE-AER'in daha yüksek anlamsal saflığa sahip olduğu görülebilir.
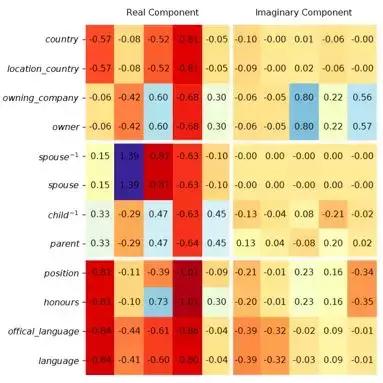
4.3.3 İlişkilerin görsel analizi
Üç grup çıkarım ilişkisi seçtik (her grupta iki, üstteki ilişki çıkarımın sol kısmı ve aşağıdaki, çıkarımın sağ kısmıdır) eşdeğer, ters ve genel çıkarımdır; eşdeğerlik ve tersi Genel zımni özel durum, eşdeğerlik şartı herhangi iki varlık çifti içindir
,var olmak
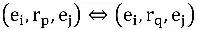
Ve ters gereklilik
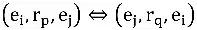
. Yeterli koşulları için, eşdeğer iki ilişki gerektirir
tatmin etmek
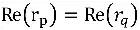
,
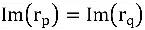
, Ters gereksinimleri karşılar

, Genel çıkarımın yalnızca tatmin etmesi gerekir
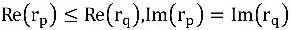
Ayrıntılı kanıt, makalenin ekinde bulunabilir. Şekildeki tüm ilişki çiftlerinin yukarıdaki kısıtlamaları karşılayabildiğini görebiliriz.