Özel Entegre öğrenmeyi anlamak için bir makale (öğrenme kaynakları ile)

Bu makale, Datapie Araştırma Departmanı "Bütünleşik Öğrenim Ayı" nın ilk makalesi. Bu ay yoğun öğrenmenin konu içeriğini arka arkaya yayınlayacağız. Ay sonunda ödül kazanmak için interaktif aktiviteler yapılacaktır. İlgili konuları tartışmak için lütfen mesaj bırakın.

Entegre algoritma (Topluluk Al gorithms) Özet
Açıkçası, bu bir makine öğrenme algoritması değil, daha çok bir optimizasyon yöntemi veya stratejisi gibidir. Daha güvenilir kararlar almak için genellikle birden çok basit zayıf makine öğrenimi algoritmasını birleştirir. Bazı insanlar buna makine öğreniminde diyor "Ejderha Kılıcı" , Çok yönlü ve etkilidir. Entegre model, çeşitli makine öğrenimi görevlerinin doğruluğunu artırabilen güçlü bir teknolojidir. Entegre algoritma, çoğu veri yarışmasında genellikle önemli bir adımdır ve algoritmanın performansını iyi bir şekilde artırabilir. Felsefe "Üç kafa Zhuge Liang'ı dövdü" . Örnek olarak sınıflandırma problemini ele alalım: Sezgisel anlayış, tek bir sınıflandırıcının sınıflandırmasının yanlış ve güvenilmez olabileceğidir, ancak birden fazla sınıflandırıcı oy verirse, güvenilirlik çok daha yüksek olacaktır.
Gerçek hayatta, genellikle oylama ve toplantılarla daha güvenilir kararlar alırız. Entegre öğrenme benzerdir. Entegre öğrenme, stratejik olarak bazı temel modeller oluşturmak ve daha sonra nihai kararı vermek için bunları stratejik olarak birleştirmektir. Entegre öğrenme, çoklu sınıflandırıcı sistem olarak da adlandırılır.
Topluluk yöntemi, çoklu zayıf model topluluk model gruplarından oluşur.Genel zayıf sınıflandırıcı, DT, SVM, NN, KNN vb. Modeller ayrı ayrı eğitilebilir ve tahminleri bir şekilde genel bir tahminde bulunmak için birleştirilebilir. Bu algoritmanın temel sorunu, hangi zayıf modellerin birleştirilebileceğini ve bunların nasıl birleştirileceğini bulmaktır. Bu çok güçlü bir teknoloji seti, bu yüzden çok popüler.
Topluluk algoritma ailesi güçlüdür ve fikirler çeşitlidir, ancak görünüşe göre aynı terminoloji yoktur ve birçok kitap farklı şekilde yazılmıştır.Farklı bilim adamlarının farklı açıklamaları vardır. En yaygın olanı, entegre düşünme mimarisine dayalı olarak üç türe ayrılmasıdır: Torbalama, Artırma ve İstifleme. Çin'de Nanjing Üniversitesi'nden Profesör Zhou Zhihua, entegre öğrenme üzerine derinlemesine bir araştırma yapıyor. 2009'da "Ensemple Learning" adlı bir genel bakış makalesi yayınladı (https://cs.nju.edu.cn/zhouzh/zhouzh.files/publication /springerEBR09.pdf) bu üç mimariyi açıkça tanımlamıştır.
Algoritma kuş bakışı
Torbalama: Verilerin rastgele yeniden örneklenmesine dayalı bir sınıflandırıcı oluşturma yöntemi. Eğitim setinden, her temel modelin gerektirdiği alt eğitim setini oluşturmak için alt örnekleme yapılır ve nihai tahmin sonucunu üretmek için tüm temel modellerin tahmin sonuçları sentezlenir.
Artırma: Eğitim süreci merdiven şeklindedir, temel model sırayla tek tek eğitilir (paralel uygulanabilir), temel modelin eğitim seti her seferinde belirli bir stratejiye göre dönüştürülür ve bir önceki model her seferinde iyileştirilir. Veri kümesinin ağırlığı ve son olarak, nihai tahmin sonuçlarını üretmek için tüm temel model tahminlerinin sonuçlarının doğrusal kombinasyonu.

İstifleme: Eğitim bazında tüm eğitilmiş temel modelleri tahmin edin. İ-inci eğitim örneği için j-inci temel modelin tahmini değeri, yeni eğitim setindeki i-inci örneklemin j-inci özellik değeri olarak kullanılacaktır ve son olarak yeni eğitim setine dayalı olacaktır Eğitim düzenleyin. Aynı şekilde, tahmin süreci önce tüm temel modellerin tahminleri üzerinden yeni bir test seti oluşturmalı ve son olarak test setinde tahminler yapmalıdır:

Yığınlama algoritması iki katmana bölünmüştür.İlk katman, T zayıf sınıflandırıcıları oluşturmak için farklı algoritmalar kullanır ve aynı zamanda orijinal veri kümesiyle aynı boyutta yeni bir veri kümesi oluşturur ve bu yeni veri kümesini ve ikinci katmanı oluşturmak için yeni bir algoritmayı kullanır Sınıflandırıcı.
Yukarıdaki resim, entegre öğrenme teorisi için sklearn kullanmaktan geliyor @jasonfreak
(Http://www.cnblogs.com/jasonfreak/p/5657196.html)
Yaygın olarak kullanılan model füzyon geliştirme yöntemleri
-
Torbalama (Bootstrapped Aggregation)
-
Rastgele Orman
-
Artırma
-
AdaBoost (Uyarlamalı Güçlendirme)
-
Gradyan Artırma Makineleri (GBM)
-
Gradyan Artırılmış Regresyon Ağaçları (GBRT)
-
Yığın Genelleme (harmanlama)
Temel sınıflandırıcının sonuçlarını entegre etmenin ana yolu hakkında
1. Regresyon tahmini için (sayısal tahmin)
-
Basit ortalama (Basit Ortalama), her bir sınıflandırıcının sonuçlarının ortalamasını almaktır. $$ G (x) = \ frac {1} {T} \ sum \ limits {t = 1} ^ {T} {{{g} {t}}} (x) $$
-
Ağırlıklı ortalama. $$ G (x) = \ frac {1} {T} \ sum \ limits {t = 1} ^ {T} {{{\ alpha} {t}}} \ cdot {{g} {t}} ( x), {{\ alpha} {t}} \ ge 0 $$
2. Sınıflandırma için (sınıf tahmini)
-
Çoğunluk Oylama: Her sınıflandırıcının ağırlığı aynıdır, azınlık çoğunluğa uyar ve oyların yarısından fazlasını alan kategori sınıflandırma sonucudur.
$$ G (x) = işaret \ sol (\ sum \ limits {t = 1} ^ {T} {1} \ cdot {{g} {t}} (x) \ right) $$
-
Ağırlıklı Çoğunluk Oylama: Her sınıflandırıcının farklı bir ağırlığı vardır. $$ G (x) = işaret \ sol (\ sum \ limits {t = 1} ^ {T} {{{\ alpha} {t}}} \ cdot {{g} {t}} (x) \ right ), {{\ alpha} {t}} \ ge 0 $$
-
Olasılıklı oylama (Yumuşak oylama): Bazı sınıflandırıcıların çıktıları olasılık bilgisine sahiptir, bu nedenle olasılık oylaması kullanılabilir.
Entegre öğrenmenin iki temel noktası vardır:
-
Farklılıkları olan bir sınıflandırıcı nasıl oluşturulur;
-
Bu sınıflandırıcıların sonuçları nasıl entegre edilir.
Temel öğrenciler arasında performansta büyük bir fark olmalıdır, aksi takdirde entegrasyon etkisi çok kötü olacaktır, yani Çeşitlilik Temel öğrenci DT, SVM, NN, KNN vb. Veya farklı parametreler, farklı eğitim setleri veya farklı özellik seçimleri gibi farklı eğitim süreçlerine sahip aynı model olabilir.
Bootstrap yöntemine giriş
Bootstrap yöntemi çok kullanışlı bir istatistiksel tahmin yöntemidir. Bootstrap, parametrik olmayan bir Monte Carlo yöntemidir, özü, gözlem bilgilerini yeniden örneklemek ve ardından popülasyonun dağılım özellikleri hakkında istatistiksel çıkarımlar yapmaktır. İlk olarak, Bootstrap yeniden örnekleme yoluyla Çapraz Doğrulamanın neden olduğu örnek azaltma sorununu ortadan kaldırır.İkincisi, Bootstrap ayrıca verilerde rastgelelik yaratabilir. Bootstrap, yerine geçen tekrarlı bir örnekleme yöntemidir. Örnekleme stratejisi basit rastgele örneklemedir.
Bootstrap'e dayalı torbalama algoritması
Torbalama (Bootstrapped Aggregation) Belirli bir veri işleme görevi için, farklı modellere, parametrelere ve özelliklere sahip birden çok modeli eğitin ve son olarak nihai sonucu oylama veya ağırlıklı ortalama ile çıkarın. Temel öğrenci aynı model veya farklı olabilir. Genel olarak, aynı temel öğrenci kullanılır ve en yaygın kullanılan, CE karar ağacıdır.
Torbalama, orijinal veri kümesini değiştirme ile örnekleyerek orijinal veri kümesi D ile aynı boyutta yeni veri kümeleri D1, D2, D3 vb. Oluşturur ve daha sonra bu yeni veri kümelerini birden çok sınıflandırıcı g1'i eğitmek için kullanır, g2, g3 ..... Değiştirilen numuneler olduğu için, bazı numuneler birden çok kez görünebilir ve bazı numuneler göz ardı edilecektir.Teorik olarak, yeni numuneler orijinal eğitim verilerinin% 67'sini içerecektir.
Torbalama, temel sınıflandırıcının varyansını azaltarak genelleme yeteneğini geliştirir.Bu nedenle, Torbalama performansı, temel sınıflandırıcının kararlılığına bağlıdır.Temel sınıflandırıcı kararsızsa, Torbalama, eğitim verilerinin rastgele bozulmasından kaynaklanan hatayı azaltmaya yardımcı olur. Ancak temel sınıflandırıcı kararlı ise, yani veri değişikliklerine duyarlı değilse, torbalama yöntemi performans artışı sağlamayacaktır.
Algoritma akışı aşağıdaki gibidir:

Torbalamaya Dayalı Rastgele Orman
Rastgele Orman, birçok karar ağacının ortalamasıdır, Her karar ağacı, Bootstrap aracılığıyla elde edilen rastgele örneklerle eğitilir. Ormandaki her bir ağaç, tam bir karar ağacından daha zayıftır, ancak bunları birleştirerek, çeşitlilik sayesinde daha yüksek bir genel performans elde edilebilir.
Rastgele orman ilk olarak birçok farklı karar ağacı oluşturur.Her bir ağaçtaki değişken sayısı $ \ sqrt {K} $ ($ K $ mevcut değişkenlerin sayısıdır) olabilir ve bu da modelin eğitim hızını önemli ölçüde hızlandırabilir. Genel temel sınıflandırıcı sayısı 500 veya daha fazladır.
Rastgele orman, kendi kendini sınama özelliklerine sahiptir, çünkü rastgele orman Bootstrap tarafından örneklenir. Teorik olarak, orijinal verinin yaklaşık 1 / 3'ü seçilmez. Biz buna OOB (paket dışı) diyoruz ve verilerin bu kısmı tamam. Çapraz Doğrulama rolüne benzer şekilde test için kullanılır.
Rastgele Orman, bugün makine öğreniminde çok popüler bir algoritmadır. Bu, eğitilmesi (veya inşa edilmesi) çok kolay olan bir tür "küme zekasıdır" ve iyi performans gösterme eğilimindedir.
Rastgele ormanın birçok avantajı vardır:
-
Tüm veriler etkili bir şekilde kullanılabilir ve çapraz doğrulama için verilerin bir kısmını manuel olarak ayırmaya gerek yoktur;
-
Rastgele orman yüksek doğruluk sağlayabilir, ancak yalnızca birkaç parametreye sahiptir ve sınıflandırma ve regresyon için uygundur;
-
Aşırı uyum konusunda endişelenmeyin;
-
Önceden özellik seçimi yapmaya gerek yoktur ve her seferinde ağacı eğitmek için yalnızca rastgele birkaç özellik seçin.
Dezavantajları:
-
Diğer algoritmalarla karşılaştırıldığında çıktı tahmini daha yavaş olabilir.
Artırma
Boosting (Adaptive Boosting kısaltması), hatalara dayalı sınıflandırıcıların performansını artırır Mevcut sınıflandırıcılar tarafından yanlış sınıflandırılan örneklere odaklanılarak, yeni sınıflandırıcılar oluşturulur ve entegre edilir. Buradaki fikir, modelin her yinelemeden geçmesidir. Veri örneklerinin genel işleme doğruluğunu iyileştirmek için hata örneklerinin kayıp ağırlığını ayarlayın.
Güçlendirme ve Torbalama arasındaki en büyük fark Yani, Boosting seridir ve Torbalama'daki tüm sınıflandırıcılar aynı anda üretilebilir.Bunlar arasında ilişki yoktur.Araştırmada, önce ilk sınıflandırıcı üretilmeli, ardından ilk sınıflandırıcının sonucuna göre ilk sınıflandırıcı üretilmelidir. İki sınıflandırıcı sırayla gerçekleştirilir.

ana fikir Hedeflenen öğrenme için eğitim setini değiştirmektir. Her yineleme ile yanlış numunenin ağırlığı artırılır ve doğru numunenin ağırlığı azaltılır. Hatalarınızı düzeltin ve daha iyi hale gelin.

Yukarıdaki resim (prml p660'dan resim) bir Güçlendirme sürecidir, yeşil çizgi mevcut modeli (model önceki m modellerinden elde edilmiştir) ve noktalı çizgi mevcut modeli temsil etmektedir. Her sınıflandırdığınızda, yanlış verilere daha fazla dikkat edeceksiniz.Yukarıdaki şekilde, kırmızı ve mavi noktalar veridir. Nokta ne kadar büyükse, ağırlık o kadar yüksek olur. Sağ alt köşedeki resme bakın. M = 150 olduğunda, Model neredeyse kırmızı ve mavi noktaları ayırt edebildi.
Algoritma akışı aşağıdaki gibidir:

Daha önce yanlış öğrenilen örneklerin ağırlığını artırmak ve doğru olduğuna karar verilen örneklerin ağırlığını azaltmak bir parça düzeltmedir ve yanlış olduğunu bildiğiniz zaman düzeltmenin anlamı ve hedefe yönelik öğrenme.
Teoride, Boosting rastgele doğru sınıflandırıcılar oluşturabilirken, temel öğrenci keyfi olarak zayıf olabilir ve yalnızca tahmin etmekten daha iyi olması gerekir.
Torbalama, sapmayı (sapmayı) azaltırken, Artırma önyargıyı (sapmayı) azaltır. Belirli ayrıntılar için, Zhihu netizenlerinin yanıtına bakabilirsiniz. Torbalama neden varyansı azaltırken, artırma önyargıyı azaltır? (Https: //www.zhihu .com / soru / 26760839)
Artırmaya dayalı AdaBoost
AdaBoost, Boosting'deki en temsili algoritmadır. AdaBoost, Torbalama'dan farklı bir Boosting yöntemidir. Adaboost'ta farklı alt modellerin seri eğitimlerle elde edilmesi, Her yeni alt model, eğitilen modelin performansına göre eğitilir ve Boosting algoritmasındaki temel öğrenci, zayıf öğrenmedir ve bu da şu şekilde anlaşılabilir: Sadece rastgele tahmin etmekten biraz daha iyi, İki sınıflandırma durumunda, doğru oran 0,5'ten biraz daha yüksektir.
AdaBoost'taki her eğitim örneğinin bir ağırlığı vardır ve başlangıç değeri Wi = 1 / N'dir. Adaboost'ta, her yineleme aynı eğitim verilerini kullanarak yeni bir alt model oluşturur, ancak örneğin ağırlığı farklı olacaktır. AdaBoost, yanlış numunenin ağırlığını artırma ve doğru numunenin ağırlığını azaltma prensibine göre her numunenin ağırlığını mevcut hata oranına göre güncelleyecektir. Eğitimi tekrarlayın ve eğitim hata oranı veya temel öğrenci sayısı kullanıcı tarafından belirtilen sayıya ulaşıncaya kadar ağırlıkları ayarlayın. Adaboost'un nihai sonucu, her zayıf öğrencinin ağırlıklı sonucudur.
Algoritma akışı aşağıdaki gibidir:

AdaBoost avantajları:
-
Uygulaması kolay
-
Ayarlanacak neredeyse hiç parametre yok
-
Aşırı uyum konusunda endişelenme
Dezavantajları:
-
Formüldeki yerel optimal çözümdür ve optimal çözüm olacağı garanti edilemez.
-
Gürültüye çok duyarlı
AdaBoost'un öğretmen Lin Xuantian'ın kursundaki algoritma akışını anlamak daha kolay olabilir ...


Gradyan Artırma Makineleri (GBM)
Gradyan artırma, zayıf karar ağaçlarından oluşması açısından rastgele ormana benzer. En büyük fark, gradyan artırmada ağaçların birbiri ardına eğitilmesidir. Sonraki her ağaç, esas olarak önceki ağaç tarafından hatalı şekilde tanınan verilerle eğitilir. Hangi yapar Gradyan artırma, kolayca öngörülebilir durumlara daha az ve zor durumlara daha çok odaklanır.
Gradient Boost (https://en.wikipedia.org/wiki/Gradient_boosting) ile geleneksel Boost arasındaki fark, her yeni modelin gradyan yönünde önceki modelin kalıntısını azaltmak için tasarlanmış olmasıdır. Gradient Boost ile geleneksel Boost arasındaki fark, her hesaplamanın son artığı (artık) azaltmasıdır ve artığı ortadan kaldırmak için artık azalmanın (Gradyan) gradiyenti yönünde yeni bir model oluşturabiliriz. . Bu nedenle, Gradient Boost'ta her yeni model, doğru ve yanlış örneklerin ağırlıklandırılması için geleneksel Boost'tan çok farklı olan gradyan yönünde önceki modelin kalıntısını azaltmak için oluşturulur.
Gradyan artırıcı eğitim hızı da çok hızlı ve performans çok iyi. Bununla birlikte, eğitim verilerindeki küçük değişiklikler modelde köklü değişiklikler üretebilir, bu nedenle en yorumlanabilir sonuçları vermeyebilir.
Gradyan Artırılmış Regresyon Ağaçları (GBRT)
Açıklanması gereken ilk şey, bu algoritmanın birçok isme sahip olduğudur, ama aslında aynıdır ~
-
Gradyan Ağacı Güçlendirme
-
GBRT (Gradyan Arttırma Regresyon Ağacı) Gradyan Arttırma Regresyon Ağacı
-
GBDT (Gradient BoostDecision Tree) gradyan artırma karar ağacı
-
MART (MultipleAdditive Regression Tree) çoklu karar regresyon ağacı
-
Tree Net Karar Ağacı Ağı
GBRT ayrıca bir Boosting yöntemidir. Her alt model, eğitilen öğrencinin performansına (kalan hata) göre eğitilir. Alt model, Seri eğitimle elde edildi, paralelleştirilmesi kolay değil. GBRT, artık öğrenmenin hesaplanmasına dayanır ve AdaBoost'ta numune ağırlığı kavramına sahip değildir. GBRT, gradyan yineleme ve regresyon ağacını birleştirir ve doğruluk çok yüksektir, ancak aynı zamanda aşırı uyum riski de vardır. GBRT'de yinelemeli, artığın gradyanıdır ve artık, tahmin edilen sonuç ile elde edilen tüm eğitmenlerin mevcut kombinasyonunun gerçek değeri arasındaki farktır.
GBRT çok yaygın olarak kullanılmaktadır, Sınıflandırabilir, regresyon tahmini yapabilir. GBRT, bir sınıflandırma ağacı değil, bir regresyon ağacıdır. İşin özü, her ağacın önceki tüm ağaçların kalıntılarından öğrenmesidir. GBRT bir sınıflandırma ağacı değil, bir regresyon ağacıdır.
Karar ağaçları, regresyon ağaçlarına ve sınıflandırma ağaçlarına bölünmüştür: Regresyon ağaçları, sıcaklık, kullanıcı yaşı vb. Gibi gerçek değerleri tahmin etmek için kullanılır. Sınıflandırma ağaçları, hava koşulları, kullanıcı cinsiyeti vb. Gibi etiket değerlerini sınıflandırmak için kullanılır.
Model kombinasyonunun iki temel biçimi vardır + karar ağacı ile ilgili algoritmalar - rastgele orman ve GBDT ((Gradient Boost Decision Tree) ve diğer nispeten yeni model kombinasyonu + karar ağacı algoritmaları bu iki algoritmanın uzantılarıdır.
Algoritma akışı aşağıdaki gibidir:
Algoritma uygulaması dahil Torbalama ve Yükseltme mimarisi altındaki entegrasyon algoritması hakkında daha fazla ayrıntı için lütfen Python resmi web sitesi makine öğrenimi paketi entegrasyon modülüne bakın: sk-learn (
İstifleme
Wolpert, 1992 tarihli bir makalede yığılmış genellemeyi tanıttı (https://www.researchgate.net/publication/222467943_Stacked_Generalization), Temel fikir Çok sayıda temel sınıflandırıcı kullanır ve ardından genelleme hatalarını azaltmak için tahminlerini birleştirmek için başka bir sınıflandırıcı kullanır.
İstifleme esas olarak iki bölüme ayrılmıştır. İlk katman, birçok küçük sınıflandırıcıyı eğiten geleneksel eğitimdir; ikinci katman, bu küçük sınıflandırıcıların çıktılarını yeni bir eğitim setinde yeniden birleştirmek ve daha yüksek düzeyde bir sınıflandırıcı eğitmektir; amaç, karşılık gelen öğeyi bulmaktır. Bunların ağırlığı veya aralarındaki kombinasyon.
İkinci düzey sınıflandırıcıyı eğitirken, her temel sınıflandırıcının çıktısı girdi olarak kullanılır, ikinci düzey sınıflandırıcının işlevi, temel sınıflandırıcının çıktısını entegre etmektir.

Algoritma akışı aşağıdaki gibidir:

İstifleme, Torbalamanın yükseltilmiş bir versiyonu gibidir. Torbalamadaki temel sınıflandırıcılar aynı ağırlıklara sahiptir, ancak İstiflemede farklıdır. İstiflemede öğrenmenin ikinci katmanı, uygun ağırlıkları veya uygun kombinasyonları bulmaktır.
Bunu belirtmeye değer Yığınlama mimarisi altında, Yığınlama, Karıştırma, Yığın Genelleme gibi sık görülen bazı ifadeler vardır.Birçok makale aralarındaki ilişkiyi açıkça belirtmemektedir.
durumunda Kesinlikle ayırt etmemek Öyleyse, Yığınlama, Karıştırma ve Yığınlı Genellemenin aslında aynı algoritma için farklı isimler olduğu düşünülebilir. Geleneksel toplu öğrenmede, hedef işlevine yaklaşmak için eğitim setine uymaya çalışan birden fazla sınıflandırıcımız var. Her sınıflandırıcının kendi çıktısı olduğundan, sonuçları birleştiren bir kombinasyon mekanizması bulmamız gerekir; bu, oylama (çoğunluk kazanır), ağırlıklı oylama (bazı sınıflandırıcıların diğerlerinden daha fazla yetkiye sahiptir), ortalama sonuçlar vb.
Yığınlamada, kombinasyon mekanizması, sınıflandırıcının (seviye 0 sınıflandırıcı) çıktısının aynı amaç fonksiyonuna yaklaşmak için başka bir sınıflandırıcının (seviye 1 sınıflandırıcı) eğitim verisi olarak kullanılmasıdır. Temel olarak, seviye 1 sınıflandırıcının birleştirme mekanizmasını bulmasına izin verin.
Yığınlama, Harmanlama ve Yığın Genelleme, farklı isimlerle aynı şeydir. Bu bir tür toplu öğrenmedir. Geleneksel topluluk öğrenmede, hedef işleve yaklaşmak için bir eğitim setine uymaya çalışan birden fazla sınıflandırıcımız var. Her sınıflandırıcı kendi çıktıları varsa, sonuçları birleştirmek için bir birleştirme mekanizması bulmamız gerekecek.Bu, oylama (çoğunluk kazanır), ağırlıklı oylama (bazı sınıflandırıcıların diğerlerinden daha fazla yetkiye sahiptir), sonuçların ortalamasını alma vb. yoluyla olabilir.
Yığınlama ve Harmanlama hakkında daha fazla ayrıntı için lütfen KAGGLE ENSEMBLING GUIDE (https://mlwave.com/kaggle-ensembling-guide/), Çin kaggle rekabet entegrasyon kılavuzu @qjgods ( makale / ayrıntılar / 53054686)
Dünyaya başka bir bakış
Son olarak, öğretmen Lin Xuantian'ın kursunun açıklamasına göre makine öğrenimi entegrasyon algoritmasının bir özetini de yapabiliriz. Entegre model esas olarak iki ana hatta bölünmüştür, bir Harmanlama hattı ve bir Öğrenme hattı. Harmanlama, çeşitli temel sınıflandırıcılar elde ettiğimizi varsayar.Öğrenme, temelde bir sürü veriyle karşı karşıya olduğumuz anlamına gelir.Bunları birleştirme yöntemini öğrenirken temel sınıflandırıcıları da elde etmemiz gerekir.

-
Karıştırma çerçevesi

-
Öğrenme çerçevesi

Elbette daha karmaşık bir şey var, yani Entegre entegrasyon .
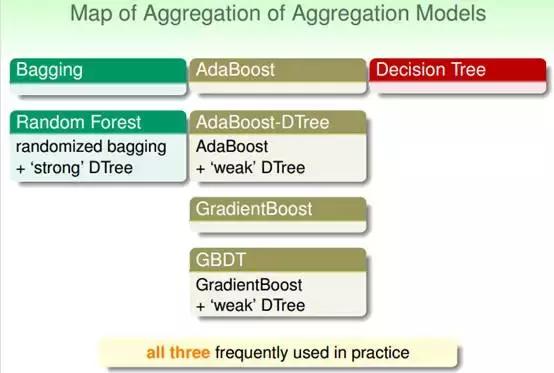
Model değerlendirmesi
Bir modelin artılarını ve eksilerini değerlendirmek için birçok kriter vardır.
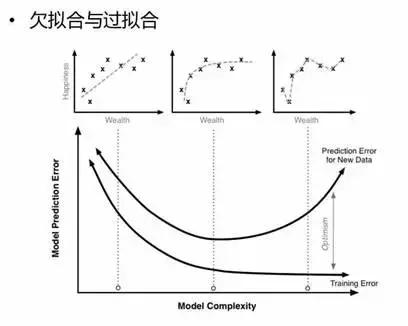
Yetersiz ve fazla uydurma Bunlar sıklıkla ortaya çıkan iki durumdur. Basit değerlendirme yöntemi, eğitim hatası ile test hatası arasındaki ilişkiyi karşılaştırmaktır. Uygun olmayan bir şekilde yerleştirildiğinde, model eğitim doğruluğunu iyileştirmek için daha fazla özellik tasarlanabilir. Aşırı uydurma olduğunda, özellik miktarı azaltmak için optimize edilebilir Model test doğruluğunu iyileştirmek için model karmaşıklığı.
-
Aşırı uyum ve yetersiz uyum

-
Varyans ve önyargı
Makine öğrenimi modelinin Önyargı ve Varyans analizi, Önyargılı Varyans Ödünleşimini Anlama'daki bir resim ( bize sapmayı ve varyansı canlı bir şekilde gösterir. ilişki:

Basit bir ifadeyle, bir model ne kadar karmaşıksa, eğitim örnekleminin uyumu o kadar yüksek olacak ve Sapması o kadar küçük olacaktır (eğitim hatası daha küçük). Bununla birlikte, verilere çok duyarlı olduğundan, oluşturulan modelin varyasyon aralığı nispeten büyük olabilir (daha büyük varyans) ve bu da test verilerinin performansında yüksek belirsizliğe yol açabilir.
Kaynaklar
-
Makine Öğreniminin Temel Taşı Teknikleri Tayvan Üniversitesi Öğretmeni Lin Xuantian
Bu iki kurs, Ulusal Tayvan Üniversitesi'nden Öğretmen Lin Xuantian tarafından sunulan başlangıç seviyesinde makine öğrenimi kurslarıdır. Köşe taşı sınıfı teoriye odaklanır ve VC Boyut, Aşırı Uyum, Düzenlilik ve Doğrulama gibi çok temel konuları kapsar.Teknik sınıfı, SVM, AdaBoost, Karar Ağacı, Rastgele Orman, Derin Öğrenme ve RBF Ağı gibi çok sayıda pratik algoritmayı giriş için üç kategoriye ayırır. Her algoritma derinlemesine konuşur, çok sayıda matematiksel türetme içerir ve modeller ile algoritmalar arasındaki ilişkiye büyük önem verir. Kurs slaytları güzelce hazırlanmış ve dersler basit bir şekilde açıklanmıştır. Ödevi çok zordur ve çok zaman alır.
Entegrasyon öğrenimi (toplama) ile ilgili olarak, Bay Lin Xuantian, 7. dersi teknik sınıfındaki 11. derse, yaklaşık beş saat, entegrasyon algoritmasının ilgili ayrıntılarını ve arkasındaki matematiksel ilkeleri tam olarak anlayabilir ve daha iyi uygulayabilir. Entegre algoritmaları kullanın
Kurs videoları ve ders notları (
Tartışma alanı (https://www.csie.ntu.edu.tw/~htlin/course/ml15fall/)
Referans kitabı (
İş referansı (
-
Veri Madenciliği: Teori ve Algoritma (Yuan Bo) School Online Edition
Veri Madenciliği Kursu (
Samanyolu'nun soyundan gelen Öğretmen Yuan Bo, açıkça güçlü bir hiziptir, ancak o idol yoluna gitmek istiyor. Öğretmen Yuan Bo, veri madenciliğiyle ilgili diğer ders ve ders kitaplarında nadiren yer alan temel fikirleri, temel teknolojileri ve bazı önemli bilgi noktalarını canlı ve mizahi bir şekilde tanımladı. Bütünleşik öğrenme modülü kursun sekizinci haftasında.

-
Önerilen kitaplar
Topluluk Yöntemleri: Temeller ve Algoritmalar (Chapman ve Hall / CRC Veri Madenciliği ve Bilgi Keşfi Serisi) 1. Baskı, Zhi-Hua Zhou (Yazar)

-
Genişletilmiş okuma
XGBoost ve Yükseltilmiş Ağaç Chen Tianqi (
XGBoost: Ölçeklenebilir Ağaç Güçlendirme Sistemi (https://arxiv.org/abs/1603.02754)
Örnek öğrenme (
Örnek (
Artırma (
AdaBoost (
Makine öğrenimi algoritmalarında GBDT ve XGBOOST arasındaki farklar nelerdir? (Https://www.zhihu.com/question/41354392)
Profesör Zhou Zhihua tarafından önerilen Derin Orman modeli nasıl değerlendirilir? Mevcut sıcak derin öğrenme DNN'nin yerini alacak mı? (Https://www.zhihu.com/question/56474891)
SINIFLANDIRICILAR İÇİN TOPLANMA YÖNTEMLERİ (https://datajobs.com/data-science-repo/Ensemble-Methods-%5BLior-Rokach%5D.pdf)
Veri Bilimi Bilgi Repo (https://datajobs.com/data-science-repo/)
Regresyon için Model Toplama Yöntemlerinin Karşılaştırması (https://datajobs.com/data-science-repo/Boosting-and-Bagging-%5BBarutcuoglu-and-Alpaydin%5D.pdf)
Breimanın Rastgele Orman Makine Öğrenimi Algoritmasının Uygulanması (https://datajobs.com/data-science-repo/Random-Forest-%5BFrederick-Livingston%5D.pdf)
Rasgele Ormana göre Sınıflandırma ve Regresyon (https://datajobs.com/data-science-repo/Random-Forest-%5BLiaw-and-Weiner%5D.pdf)
Topluluk Modelleme Teknikleri (Skilltest Solution) hakkında bir Veri Bilimcisine sorulacak 40 Soru (https://www.analyticsvidhya.com/blog/2017/02/40-questions-to-ask-a-data-scientist-on-ensemble- modelleme-teknikleri-beceri testi-çözüm /)
KAGGLE TOPLAMA KILAVUZU (
Bu makale referansları
Toplu öğrenmeyi öğrenmeye nasıl başlanır? (Https://www.zhihu.com/question/29036379)
Makine Öğreniminde Algoritmalar (1) -Random Ormanı ve Karar Ağacı Modeli Kombinasyonunun GBDT'si @LeftNotEasy ( )
Makine Öğreniminde Matematik (3) -Model Boosting and Gradient Boosting @ LeftNotEasy ( -gradient-boosting.html)
Entegre öğrenme teorisi için sklearn kullanın @jasonfreak (
Entegre öğrenme yöntemi (
Topluluk öğrenme (Integrated Learning @ GJS Blog) (
Makine Öğrenimi Teknikleri - Fusion Modeli @ (
kaggle rekabet entegrasyon kılavuzu @ qjgods (
Yığınlama, Karıştırma ve Yığın Genelleme (