OpenAI'nin en son keşfi: parametre alanına gürültü eklemek kolaydır ve öğrenmeyi kolayca hızlandırabilir
Lei Feng.com AI teknolojisi yorum notu: OpenAI'nin en son bulguları, ağın parametre alanına gürültü ekleyerek, performansın ağın davranış alanına gürültü eklemekten çok daha iyi olabileceğini gösteriyor. Ayrıca, birden çok ağı kapsayan bir dizi karşılaştırma kodu yayınladılar.
Lei Feng.com'un yapay zeka teknolojisi incelemesi aşağıdaki gibi derlenmiştir:
OpenAI Lab'in en son keşfi: Takviye öğrenme algoritmasındaki parametrelere sık sık uyarlanabilir gürültü ekledikten sonra, daha iyi sonuçlar elde edilebilir. Bu yöntemin uygulanması basittir ve temelde kötü sonuçlara yol açmaz ve herhangi bir problem üzerinde denemeye değer.

Şekil 1: Davranışsal uzaysal gürültüyle eğitilmiş bir model

Şekil 2: Parametre uzayında gürültü eğitimi olan model
Parametrik gürültü, algoritmanın uygun eylem aralığını verimli bir şekilde keşfetmesine ve ortamda mükemmel performans elde etmesine yardımcı olabilir. Şekil 1 ve Şekil 2'de gösterildiği gibi, 216 eğitim bölümünden sonra, parametre gürültüsü olmayan DDPG, sıklıkla verimsiz çalışma davranışı üretecek ve parametre gürültü eğitimi eklendikten sonra çalışma davranışı puanı daha yüksek olacaktır.
Parametre gürültüsü eklendikten sonra, aracının öğrenme görevi hızı daha hızlı hale gelir ve bu, diğer yöntemlerin getirdiği hız artışından çok daha iyidir. Yarı çita spor ortamında 20 bölüm eğitimden sonra (Şekil 1, Şekil 2), bu stratejinin puanı yaklaşık 3000 puan iken, geleneksel hareket gürültüsü eğitim stratejisi sadece 1500 puan alabilir.
Parametre gürültü yöntemi, davranış alanına eklemek yerine sinir ağı stratejisinin parametrelerine uyarlamalı gürültü eklemektir. Geleneksel pekiştirmeli öğrenme (RL), aracılar tarafından her an gerçekleştirilen eylemlerin olasılığını değiştirmek için davranışsal uzaysal gürültüyü kullanır. Parametre uzay gürültüsü, aracının parametrelerinin rasgeleliğini doğrudan artırır ve aracı tarafından alınan kararların türlerini değiştirir, böylece bunlar her zaman tamamen mevcut ortamın algısına bağlı olabilir. Bu teknoloji, evrimsel stratejiler (ajanın parametrelerini kontrol edebilen, ancak ortamı her adımda keşfettiğinde davranışını bir daha etkilemeyecektir) ve TRPO, DQN ve DDPG gibi derin pekiştirmeli öğrenme yöntemleri ( Parametreler kontrol edilemez, ancak stratejinin davranış alanına gürültü eklenebilir).
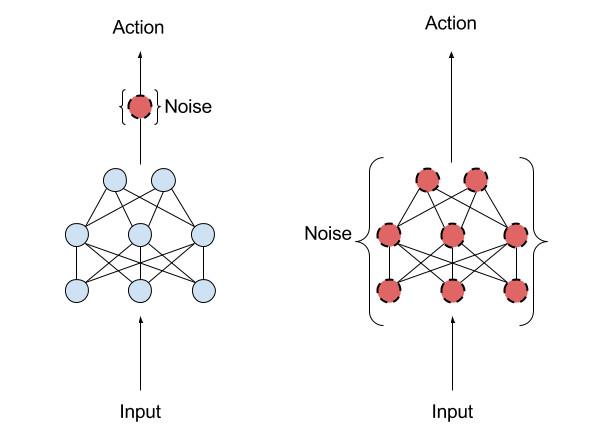
Şekil 3: Soldaki davranışsal alan gürültüsü ve sağdaki parametre alanı gürültüsü
Parametrik gürültü, algoritmanın ortamı daha verimli bir şekilde keşfetmesini, daha yüksek puanlar ve daha zarif eylemler elde etmesini sağlar. Strateji parametrelerine kasıtlı olarak gürültünün eklenmesi, aracının keşfini farklı zamanlarda tutarlı hale getirebileceğinden ve davranış alanına gürültünün eklenmesi, keşif sürecini tahmin etmeyi daha zor hale getirir.Bu keşif süreci, aracının parametrelerinden de farklıdır. Spesifik alaka düzeyi.
İnsanlar daha önce politika gradyanına parametrik gürültü uygulamayı denediler. OpenAI'nin keşfi altında, bu yöntem artık daha fazla yerde, örneğin derin sinir ağlarına dayalı stratejilerde veya stratejilere ve stratejiden bağımsız algoritmalara dayalı olarak kullanılabilir.

Şekil 4: Davranışsal alanda gürültü eğitimi ile model

Şekil 5: Parametre uzay gürültüsü ile eğitilmiş model
Şekil 4 ve Şekil 5'de görüldüğü gibi, parametre alanı gürültüsünü artırdıktan sonra yarış oyununda daha yüksek puan alabilirsiniz. İki eğitim bölümünden sonra, parametre alanına gürültü ekleyen DDQN ağı, eğitim sırasında hızlanmayı ve dönmeyi öğrenirken, eğitim sırasında davranış alanına gürültü ekleyen ağ çok daha zayıf eylem zenginliği gösterdi.
Bu araştırmayı gerçekleştirirken aşağıdaki üç problemle karşılaştılar:
-
Farklı ağ katmanları, bozulmalara karşı farklı hassasiyetlere sahiptir.
-
Eğitim süreci sırasında, strateji ağırlığının hassasiyeti zamanla değişebilir ve bu da stratejinin eylemini tahmin etmeyi zorlaştırır.
-
Uygun gürültüyü seçmek zordur çünkü eğitim sırasında parametre gürültüsünün stratejiyi nasıl etkilediğini sezgisel olarak anlamak zordur.
İlk problem, bozulan katmanın çıktısının (bu çıktı bir sonraki seviyenin girdisidir) rahatsız edilmediğinde dağılıma benzer kalmasını sağlayan seviye normalizasyonu ile çözülebilir.
İkinci ve üçüncü problemlerle başa çıkmak için parametre alanı bozukluğunun boyutunu ayarlamak için uyarlanabilir bir strateji getirilebilir. Bu ayarlama, bozukluğun davranış alanı üzerindeki etkisinin ve davranış alanı gürültüsü ile önceden belirlenmiş hedef (daha büyük veya daha küçük) arasındaki farkın ölçülmesiyle elde edilir. Bu teknik, parametre uzayından daha açıklayıcı olan gürültünün boyutunu davranış uzayına seçme problemini ortaya çıkarır.
Karşılaştırmayı seçin ve kıyaslama yapın
OpenAI, DQN, Double DQN (Double DQN), Dueling DQN, Double Duel DQN (Dueling Double DQN) ve DDPG için bu teknolojiyi entegre eden bir dizi kıyaslama kodu yayınladı.
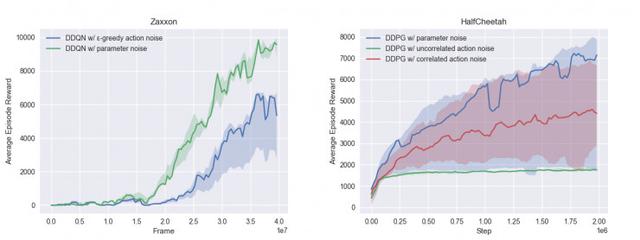
Ek olarak, DDQN'nin bazı Atari oyunlarını parametre gürültülü veya parazitsiz oynama performansının bir ölçütü de yayınlandı. Ek olarak, Mujoco simülatöründe bir dizi sürekli kontrol görevi altında üç DDQN varyantının performans kıyaslamaları vardır.
Araştırma süreci
Bu araştırmayı ilk kez yürütürken, OpenAI, DQN'nin Q işlevine uygulanan pertürbasyonun bazen çok aşırı olduğunu ve algoritmanın aynı eylemi tekrar tekrar gerçekleştirmesine neden olduğunu buldu. Bu sorunu çözmek için, stratejiyi DDPG'de olduğu gibi açık bir şekilde ifade edebilen bağımsız bir strateji ifade süreci eklediler (sıradan DQN ağında, Q işlevi stratejiyi yalnızca örtük olarak ifade edebilir), böylece ortam diğerleriyle karşılaştırılabilir. Deney daha benzer.
Bununla birlikte, bu sürüm için kodu hazırlarken bir deney yaptılar ve parametre alanı gürültüsünü kullanırken bağımsız bir strateji ifade süreci eklemediler.
Bağımsız bir strateji ifade süreci ekledikten sonra deneyin sonuçlarının sonuçlara çok benzediğini, ancak uygulamanın daha kolay olduğunu buldular. Daha ileri deneyler, bağımsız strateji başlığının gerçekten gereksiz olduğunu doğruladı, çünkü algoritmanın erken deneylerde iyileştirilmesi muhtemeldir (gürültüyü ayarlama yöntemini değiştirdiler). Bu yöntem daha basit ve daha uygulanabilirdir, eğitim algoritmalarının maliyetini düşürür ve benzer sonuçlar elde edebilir.
AI algoritmalarının (özellikle pekiştirmeli öğrenmede) bazı ince başarısızlıkları olabileceğini ve bu da insanların doğru ilaca çözüm bulmasını zorlaştırabileceğini unutmamak önemlidir.
Lei Feng.com AI Technology Review tarafından derlenmiştir.