ICLR 2020 V4D: Video seviyesi, öğrenen dört boyutlu evrişim sinir ağını temsil eder

Bu makalede ICLR 2020 "V4D: Video Düzeyi Temsil Öğrenimi için 4D Konvolüsyonel Sinir Ağları" makalesi açıklanmaktadır.
Yazar | Kod Uzun Teknoloji Düzenle |

Tez Adresi: https: //arxiv.org/abs/2002.0744
Video öğrenimi için kullanılan 3D evrişimsel sinir ağlarının çoğu klip tabanlı yöntemlerdir ve video seviyesinin uzay-zaman özelliklerindeki değişiklikleri dikkate almazlar. Değişiklikleri temsil etmek için uzun bir mesafe alanı oluşturmak için dört boyutlu bir konvolüsyon kullanarak V4D olarak adlandırılan video seviyesinin dört boyutlu konvolüsyonel sinir ağını önerdik ve aynı zamanda özellikleri kurtarmak için artık yapıyı kullandık. Üç boyutlu uzay -zaman. Ayrıca V4D'nin eğitim ve akıl yürütme yöntemlerini tanıttık. Üç video anlayışının veri setleri üzerinde çok sayıda deney yaptık ve V4D iyi sonuçlar elde etti ve 3D evrişim ağını aştı.
1. Giriş
3D sinir ağları ve varyantları, tüm videodan antrenman yapmak yerine esas olarak franchise -düzey özellikleri için kullanılır. Eğitim süresi boyunca, öğrenimi temsil etmek için videodaki kısa fragmanları (örn. 32 kare) rastgele örnekleme için parçaya dayalı bir yöntem kullanılır. Test sırasında, pencereyi kaydırırken tüm videodan birden fazla fragmanı eşit olarak örnekler ve her bir parçanın tahmin skorlarını bağımsız olarak hesaplarlar. Son olarak, tüm video parçalarının tahmin puanı ortalamadır ve video seviyesi tahmin sonuçları elde edilir. Eğitim süreci sırasında, bu klip tabanlı modeller video seviyesi yapısını ve uzun menzilli uzay-zaman bağımlılığını yok sayar, çünkü tüm videonun sadece küçük bir bölümünü örnekler. Aynı zamanda, test sırasında, tüm ortalama fragmanların tahmin puanları da üstün olabilir. Bu sorunun üstesinden gelmek için, Time Fragment Network (TSN) tüm videodan çoklu parçaları eşit olarak örnekler ve eğitim süreci sırasında ters yayılmayı yönlendirmek için ortalama puanlarını kullanır. Bu nedenle TSN, öğrenme çerçevesini gösteren bir video seviyesidir. Bununla birlikte, TSN'deki frame etkileşimi ve video seviyesi füzyon sadece geç bir aşamada gerçekleştirilir ve daha iyi bir zaman yapısı yakalanamaz.
Bu makale, Şekil 1'de gösterildiği gibi, V4D öğrenme çerçevesinin genel, esnek bir video seviyesi gösterimi önermektedir. V4D iki temel tasarımdan oluşur: (1) genel örnekleme stratejisi; (2) 4D evrişim bağlantısı. İlk olarak video seviyesi örnekleme stratejileri sunarak tüm videoyu kapsayan bir dizi kısa vadeli birim sunuyoruz. Daha sonra, 4D artık bloklar tasarlayarak, model için uzun mesafeli zaman ve boşluk bağımlılığı kullanılır. 4D artık bloklar, daha önce uzun aralıklı modelleme olan ve TSN'den daha erken yapılandırılmış olan mevcut 3D CNN'ye kolayca entegre edilebilir. Ayrıca V4D için belirli bir video seviyesi akıl yürütme algoritması tasarladık. Özellikle, V4D'nin üç video aksiyon tanıma kriterleri üzerindeki etkinliğini doğruluyoruz: mini-kinetik-200, kinetics-400 ve bir şey-bir şey-v1. V4D yapısı bu kriterlerde çok rekabetçi bir performans elde etti ve 3D CNN'ye kıyasla geliştirildi.


Şekil 1: Video tanıma için video seviyesi 4D evrişimsel sinir ağları.
2. İlgili çalışma
Video tanıma mimarisi kabaca üç gruba ayrılabilir: çift akım CNN, 3D CNN'ler ve uzun vadeli modelleme çerçevesi.
2.1 Çift Akış CNN
Çift akarsu mimarisi ilk olarak Simonyan ve Ziserman tarafından önerildi. Bunlardan biri RGB görüntülerinden öğrenmek için kullanıldı ve diğeri ışık akışını modellemek için kullanıldı. Son tahmin sonuçlarını elde etmek için iki akışın sonuçları sonraki aşamada kaynaşmıştır. Bununla birlikte, ana dezavantajı, ışık akışının hesaplanmasının genellikle daha uzun zaman almasıdır. Son zamanlarda, bazı çalışmalar simüle edilmiş ışık akışının hesaplama maliyetini azaltmaya kararlıdır. Video anlayışı alanında, çift akış girişi ve füzyon, çeşitli yapısal doğruluğu artıran yaygın bir yöntemdir. Önerdiğimiz V4D ile diktir.
2.2 3D CNNS
3D CNN genellikle daha fazla parametreye sahiptir ve yüksek performans elde etmek için daha fazla eğitim verisi gereklidir. Son zamanlarda, kinetics-400 gibi büyük ölçekli veri setleri üzerindeki deneyler, 3D CNN'lerin çoğu durumda 2D CNN'yi veya hatta çift akış yöntemine eşdeğer olabileceğini göstermektedir. Bununla birlikte, 3D CNN'nin çoğu parçalara dayanmaktadır, bu da eğitim aşamasında sadece bazı videoları keşfettikleri anlamına gelir.
2.3 uzun vadeli modelleme çerçevesi
Şu anda, daha karmaşık zaman yapıları yakalamak için uzun vadeli modelleme çerçeveleri geliştirmek için bazı yöntemler olmuştur. Bir yöntem, çerçeve seviyesi özellik çıkarımı için 2D CNN kullanır ve sürekli video çerçeve dizilerini hesaplamak için özyinelemeli sinir ağlarını kullanır. TSN, video -seviye portresini öğrenmek için tüm videodan seyrek örnekleme çerçeveleri çıkarmak için seyrek örnekleme ve toplama kullanır ve son olarak video seviyeleri oluşturmak için bu puanların ortalama yargısı. Başlangıçta 2D CNN için tasarlanmış olmasına rağmen, TSN, bu makalenin temel çizgilerinden biri olarak ayarlanan 3D CNN'ye de uygulanabilir. TSN'nin bariz bir kusuru, basit ortalama toplama nedeniyle daha iyi bir zaman yapısını modelleyememesidir.
3 V 4 D
Bu bölümde, video eylem tanıma için yeni bir video 4D konvolüsyonu sinir ağı, yani V4D tanıttık. RGB tabanlı video tanıma için ilk kez 4D evrişim tasarlamaya çalıştım. Mevcut 3D CNN, giriş olarak kısa vadeli bir parça kullanır ve video katmanları yapmak için üç boyutlu boşluk zaman özelliklerinin evrimini dikkate almaz. Yerel olmayan ağ ve kompakt genellik yerel olmayan ağ, yerel olmayan uzay-zaman karakteristiklerinin modellenmesi için kendi kendine para mekanizması önermiş olsa da, bu yöntemler başlangıçta fragmanlara dayalı 3D CNN için tasarlanmıştır. Bu işlemin genel video temsiline nasıl dahil edileceği ve bu işlemin video seviyesi öğrenimi için yararlı olup olmadığı belirsizdir. Ek olarak, tüm videoya yerel olmayan hesaplanması nispeten yüksektir. Amacımız düşük hesaplama ve optimizasyon ile uzun süreli bir uzamsal model tasarlamaktır. Bu çalışmada, "zaman" video seviyesini elde etmek için 3D özelliklerin uzun aralıklı etkileşimini öğrenmek için artık 4D blok ve 3D CNN projesini 4D CNN'ye tanıttık.
3.1 Video -düzey örnekleme stratejisi
Anlamlı video eylem notunu tanımak için, ağın girişi belirli bir videonun genel süresini kapsamalı ve aynı zamanda kısa vadeli eylem ayrıntılarını korumalıdır. Bu çalışmada, tüm videoyu eşit olarak bölüyoruz ve "Eylem Birimi" adı verilen kısa vadeli bir eylem modunu temsil etmek için her bölümden bir parça seçiyoruz. Ardından, videodaki genel eylemi temsil etmek için bir dizi aksiyon birimi kullanıyoruz.
3.2 4d zaman ve mekan etkileşimini öğrenmek için kullanılan evrişim
Üç boyutlu evrişim nükleer, uzun yıllar boyunca önerilmektedir, bu da kısa vadeli boşluk özellikleri için modellemede güçlü bir role sahiptir. Bununla birlikte, üç boyutlu çekirdeğin daha küçük boyutu nedeniyle, üç boyutlu nükleer alıcı alanı genellikle sınırlıdır. Genel olarak, alıcı alanı genişletmek için maksimum havuz kullanılır ve bilgi kaybına neden olur. Bu, kısa vadeli ve uzun vadeli boşluk zaman gösterimlerini aynı anda modelleyebilen yeni operasyonlar geliştirmemize ilham veriyor ve optimize etmek ve hızlı bir şekilde eğitmek kolaydır. Bu perspektiften, uzun aralıklı boşluk etkileşimini daha iyi modellemek için 4D evrimi önerdik.
Girişin boyutunu tanımlarız (C, U, T, H, W), burada C kanal sayısıdır ve U, eylem birimlerinin sayısıdır. T, H ve W uzunluğu, yüksekliği ve her bir eylem ünitesinin genişliği. JJ kanalına ait çıkış piksellerinden biri (u, t, h, w)
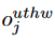
4D evrişimin temsil edilebileceğini ifade etmek için gel

Ve evrişimsel taşıma doğrusal bir işlem olduğundan, formülü (2) almak için diziyi değiştirebilirsiniz.

Braketlerdeki operasyonun aslında 3D evrişimsel operasyonlar olduğunu unutmayın, bu nedenle 4D evrişim 3D konvolüsyon ile elde edilebilir. Çoğu derin öğrenme çerçevesinde 4D bilgi işlem sağlamadan 4D evrişimsel konvolüsyonun bu şekilde farkındayız.
Ek olarak, Şekil 2'de, birkaç 4D evrişim çekirdeğinin davranışını görsel olarak görsel olarak görsel olarak görsel olarak görsel olarak görsel olarak görsel olarak görsel olarak görsel olarak görsel olarak görsel olarak. Şekildeki mavi, konvolüsyon çekirdeğini gösterir ve yeşil, evrişim çekirdeğinin merkezini temsil eder.

Şekil 2: 4D çekirdeklerin uygulanması, 3D çekirdek s. her çekirdek yeşil renkte.
Üç boyutlu evrişim ile karşılaştırıldığında, önerdiğimiz 4D evrişim, videoları daha karmaşık uzak üç boyutlu alan -zaman etkileşimi öğrenmesini sağlamak için daha anlamlı bir 4D özellik alanında modelleyebilir. Bununla birlikte, 4D evrişim kaçınılmaz olarak daha fazla parametre ve hesaplama maliyeti getirecektir. Pratik uygulamalarda, örnek olarak 4D evrişim çekirdeğini örnek olarak alın. K × K × K'nın 3D evrişim çekirdeğinin parametreleri daha fazla K katıdır, bu yüzden K × K × 1'e haklıyız × 1 × 1 Parametreleri azaltmak ve aşırı risklerden kaçınmak için K × 1 × 1 × 1 4D çekirdekleri ile keşfedin.
3.3 Video Seviye 4D CNN Mimarisi
Mevcut CNN yapısına 4D evrimi ekliyoruz. Mevcut 3D CNN'yi tam olarak kullanmak için, aynı anda kısa aralıklı ve uzun aralıklı alan değişikliklerini öğrenmeyi mümkün kılan artık 4D modülünü önerdik. Özellikle, bir değişim işlevi tanımlıyoruz,
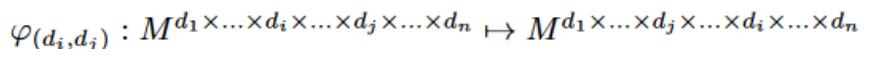




içinde

4D evrişim operasyonu,

Giriş ve çıkış, giriş çıkış boyutunun tutarlılığı PHI anahtarlama fonksiyonu tarafından sağlanır.
Teorik olarak, 4D konvolüsyon bloğumuzu entegre ederek üç boyutlu CNN yapısı 4D CNN'ye yansıtılabilir. Daha önce işte gösterildiği gibi, daha düşük seviyelerde iki boyutlu evrişim uygulayarak ve daha yüksek seviyelerde üç boyutlu evrişim uygulayarak daha iyi performans elde edebilir. Çerçevemizde, Feichtenhofer ve ark. İlk SlowPath ResNet50 için tasarlanmış olsa da, daha fazla deney için i3d-S ResNet18'e genişletebiliriz. 3D gövdemizin ayrıntılı yapısı Tablo 1'de gösterilmiştir.

3.4 Eğitim ve Akıl yürütme eğitimi
Eğitim yöntemi: Şekil 1'de gösterildiği gibi, ağın evrişim kısmı bir 3D evrişim tabakasından ve önerilen artık 4D bloktan oluşur. Her eylem birimi, aynı parametrenin üç boyutlu evrişim tabakasında paralel olarak eğitilir. Her bir eylem ünitesinden hesaplanan bu ayrı 3D özellikler daha sonra sürekli eylem ünitesinin uzun vadeli evrimini simüle etmek için artık 4D bloğa girilir. Son olarak, tüm aksiyon birimlerinin dizi uygulaması, video düzeyinde temsiller oluşturmak için küresel bir ortalama havuza sahiptir.
Akıl yürütme yöntemi:

3.5 Daha fazla tartışma
Bu bölümde, ekran tarafından önerilen V4D, son yıllarda yaygın olarak kullanılan yöntemlerin genişlemesi olarak kabul edilebilir.
(1) Zaman ağı
V4D'miz Time Network (TSN) ile yakından ilişkilidir. Başlangıçta 2D CNN için tasarlanmış olmasına rağmen, TSN video notunu modellemek için doğrudan 3D CNN'ye uygulanabilir. Eğitim süreci sırasında, her bir parça ayrı olarak hesaplanır ve ardından tam bağlantı katmanından sonra tahmin puanı ortalama. Tam bağlantı katmanı doğrusal bir işlem olduğundan, tam bağlantı katmanından önce (Global Avgpool'a benzer) veya tam bağlantı katmanından sonra (TSN'ye benzer) hesaplama ortalaması matematiksel olarak eşdeğerdir. Bu nedenle, 4D bloklardaki tüm parametreler sıfıra tahsis edilirse, V4D'miz 3D CNN+TSN olarak kabul edilebilir.
(2) Boş Sekans Evrişim
Özel bir 4D evrişim çekirdeği olan KX1x1x1, zamanında boş konvolüsyon ile yakından ilişkilidir. Tüm eylem birimleri zaman boyutuna bağlandığında, giriş video seviyesi (C, UXT, H, W) bir tensör olarak görülebileceğini gösterir. Bu durumda, Kx1x1x1'in 4D evrimi, boş mağara ile Kx1x1'in 3D konvolüsyonu olarak kabul edilebilir. Tabii ki, Kx1x1x1'in 4D evrimi en basit 4D evrişim nükleer formudur. Diğer daha karmaşık 4D evrişim çekirdekleri bu şekilde açıklanamaz. Buna ek olarak, önerdiğimiz 4D artık blok artık yapıyı içerir, böylece uzun vadeli video yapıları ve kısa süreli boş zaman yapıları aynı anda öğrenilebilir. Bu, zamanın boş olduğu işlevidir.
4 deney
4.1 Veri Seti
Üç standart ölçüt üzerinde denedik: mini-kinetik-200, kinetik-400, bir şey-bir şey-v1. Mini-kinetikler, kinetik-400'ün bir alt kümesi olan 200 aksiyon sınıfı içerir. Kinetik veri kümesinin verilerinin eksikliği nedeniyle, Kinetics-400 sürümümüz sırasıyla eğitim ve doğrulama alt konsantrasyonlarında 240436 ve 19796 videolarını içerir. Mini-kinetik versiyonu 78.422 eğitim videosu ve 4994 doğrulama videosu içerir. Video başına yaklaşık 300 kare var. Bir şey-bir şey-V1, 86017 eğitim için kullanılan toplam 108.499 video, doğrulama için 11522 ve test için 10960 video içerir. Her videonun 36 ila 72 karesi vardır.
4.2 Mini Kinetik Deneyleri
ImageNet'ten modelleri başlatmak için öncesi ağırlıklar kullanıyoruz. Eğitim için Bölüm 3.1'de belirtilen genel örnekleme stratejisini kullanıyoruz. Tüm videoyu bir U bölümüne eşit olarak bölüyoruz ve her bölümden rastgele 32 -frame parçası seçiyoruz. Her bir parça için, 4 çerçeveyi eşit olarak örnekliyoruz ve sabit adımlar bir eylem ünitesi oluşturmak için 8'dir. Aşağıdaki deneydeki etkisini inceleyeceğiz. Önce her çerçevenin boyutunu 320 × 256 olarak ayarlarız, sonra rastgele kesilir ve daha sonra kesme alanını 224 × 224 olarak ayarlarız. SGD optimizer kullanıyoruz, başlangıç öğrenme oranı 0.01, ağırlık zayıflaması olarak ayarlandı
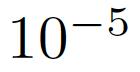
Momentum miktarı 0.9'dur. 35, 60 ve 80 öğrenme oranı 10 kat azaldı ve model 100 döngü için eğitildi.
Adil bir karşılaştırma yapmak için, yerel olmayan ve yavaş bir FCN testini takip ettik. Tüm videodan 10 eylem birimini eşit olarak çıkarıyoruz, her bir eylem ünitesini kapsamak için 3 256 × 256 alan kullanıyoruz ve ardından V4D akıl yürütmeyi gerçekleştiriyoruz. Orijinal TSN için, çıkarma döneminde 25 parça ve 10 kırpma akıl yürütmesi kullandığını unutmayın. I3D ve V4D'yi adil bir şekilde karşılaştırmak için TSN için TSN 10 fragmanları ve 3 kırpma muhakeme stratejileri de uyguladık.
sonuç. V4D'nin etkinliğini doğrulamak için, klip tabanlı bir yöntem i3D-S ve video tabanlı bir yöntem TSN+i3d-S ile karşılaştırdık. 4D bloklar tarafından sunulan ek parametreleri telafi etmek için, I3D-S ResNet18 ++ olarak ifade edilen adil karşılaştırma için i3d-S'nin res4'üne 3 × 3 × 3 artık bloklar ekliyoruz. Tablo 2A'da gösterildiği gibi, V4D akıl yürütmede i3D-S'de kullanılan çerçevelerin sayısından 4 kat daha az ve i3d-S ResNet18 ++ 'dan daha az parametre olsa bile, V4D hala i3d-S'nin doğruluğundan%2 daha yüksektir. . Video seviyesi TSN+I3D-S yöntemi ile karşılaştırıldığında, V4D%2.6 doğruluğunu arttırır.
4D evrişim çekirdeklerinin farklı formları. Daha önce de belirtildiği gibi, 4D evrişim çekirdeğimiz üç tipik form kullanır: K × 1 × 1 × 1, K × K × 1 × 1 ve K × K × K. Bu deneyde, K = 3 kullanacağız ve i3d-S Resnet18'in Res4'ünün sonunda 1 4D blok uygulayacağız. Tablo 2c'de gösterildiği gibi, 3 × 3 × 3 × 3 çekirdeğinin V4D'si en yüksek performansa ulaşabilir. Bununla birlikte, model parametreleri ve performans arasındaki dengeyi göz önünde bulundurarak, aşağıdaki deneylerde 3 × 3 × 1 × 1 çekirdeğini kullandık.
4D blokların yeri ve miktarı. V4D'nin performansını incelemek için Res3, Res4 veya Res5 üzerindeki 3 × 3 × 1 × 1 × 1 × 1 4D bloklar kullanarak 4D blok sayısının V4D üzerindeki etkilerini değerlendirdik. Tablo 2D'de gösterildiği gibi, Res3 veya Res4'e 4D bloklar uygulayarak daha yüksek doğruluk elde edebilir.
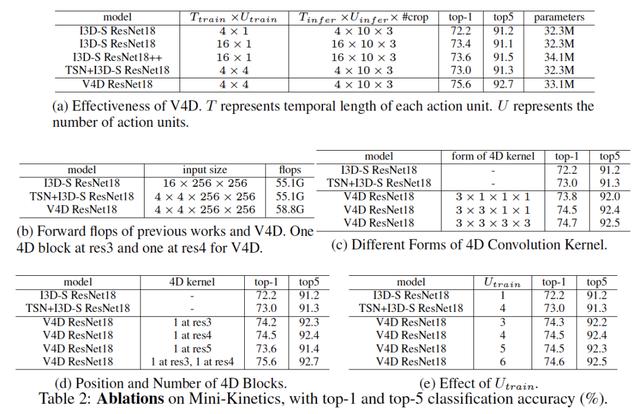
Farklı sayıda aksiyon birimi. V4D'yi farklı U_Train parametre değerlerini kullanmak için farklı sayıda eylem birimi kullanarak eğitiyoruz. Bu deney, ResNet18'in Res4 ucuna 1 3 × 3 × 1 × 1 4D blok ekler. Tablo 2E'de gösterildiği gibi, U_Train performans üzerinde önemli bir etkiye sahip değildir, bu da aşağıdakileri gösterir: (1) V4D, sağlam sayıda kısa vadeli birim olan bir video seviyesi karakteristik öğrenme modelidir; (2) Genel olarak bir eylemdir. Birden fazla aşama içermez, bu nedenle artan yardım yoktur. Buna ek olarak, eylem birimi sayısındaki artış, dördüncü boyutta bir artış anlamına gelir, bu da zaman ve mekan temsilinin kapsam evrimini kapsamak için daha büyük bir 4D çekirdeği gerektirir.
En son teknoloji ile karşılaştırıldığında. V4D'mizi geçmişte en son yöntemlerle karşılaştırıyoruz. Res3 ve Res4'te, her 3D modülünde her 3D modül kullanılır. Eğitim ve çıkarım sırasında kullanılan daha az çerçeve olmasına rağmen, V4D ResNet50'miz, 5 kompakt genelleştirilmiş yerel olmayan bloklara sahip 3D ResNet101'in 3D ResNet101'in 3D ResNet101'den bile daha yüksek olan tüm raporların sonuçlarından daha yüksek doğruluğa sahiptir. Ek olarak, V4D resNet18'imiz 3D ResNet50'den daha yüksek bir doğruluk elde ederken, V4D yapımızın etkinliğinin daha fazla doğrulanması.

4.3 Kinetikte deney
Ayrıca, V4D'nin yeteneğini değerlendirmek için büyük ölçekli video tanıma ölçütü kinetics-400 denemeyi denedik. Adil bir şekilde karşılaştırmak için ResNet50'yi V4D'nin ana gövdesi olarak kullanıyoruz. Eğitim ve akıl yürütme örnekleme stratejileri önceki bölümle aynıdır. Her eylem birimi hariç, 4 kare yerine 8 kare dahil edilmiştir. Sınırlı eğitim kaynakları nedeniyle, çok aşamalı bir eğitim modeli seçiyoruz. İlk olarak 8 kare ile eğitim 3D ResNet50 ana ağına giriyoruz. Daha sonra 3D ResNet50 parametrelerini V4D ResNet50'ye yükledik ve aynı zamanda tüm 4D parametrelerini 0'a dondurduk. Ardından, v4d resNet50'yi incelemek için çerçeveye girmek için 8 × 4 kullanın. Son olarak, tüm 4D blokları optimize ettik ve V4D'yi eğitmek için 8 × 4 kare kullandık. Tablo 4'te gösterildiği gibi, V4D'miz Kinetics-400 ölçütünde rekabetçi sonuçlar elde etmiştir.

4.4 Bir Şey-Bir Şey Deneyimi-V1
Mini kinetik ve kinetiklerle karşılaştırıldığında, bir şey esas olarak zaman bilgisi ve hareket için modellenir. Arka plan kinetikten daha temiz, ancak hareket kategorisi çok daha karmaşık. Her videodaki bir şey, zaman boyutunda net bir başlangıç ve bitiş olan tek bir sürekli eylem içerir.
sonuç. Önceki çalışmalarla karşılaştırıldığında, Tablo 4.4'te gösterildiği gibi, V4D'miz bir şey-v1'de rekabetçi sonuçlar elde etmiştir. Deneyler için kinetikler tarafından önceden eğitilmiş V4D ResNet50 kullanıyoruz.

Kronolojik olarak. Ters zaman boyunca, 3D modellerin doğruluğu önemli ölçüde azalır, bu da 3D CNN'nin çok güçlü bir dizi öğrenebileceğini gösterir. V4D'miz için iki zaman sırası, kısa aralıklı sipariş ve uzun aralıklı bir sipariş vardır. Tablo 6'da gösterildiği gibi, Top-1'in doğruluğu, her bir eylem ünitesindeki kare veya ters eylem birimleri dizisini tersine çevirerek önemli ölçüde azalmıştır, bu da V4D'mizin uzun vadeli ve kısa vadeli dizileri yakalayabileceğini gösterir.

5. Sonuç
Güçlü boşluk evriminin uzun mesafeli süresini ve boşluğunu öğrenmek ve kalıntı bağlantılarla 3D özellikleri korumak için yeni bir video -seviye 4D evrişimsel sinir ağı, yani V4D tanıttık. Buna ek olarak, V4D'nin iyi bir sonuç elde ettiği üç video tanıma ölçütü üzerinde deneyler yapan V4D'nin eğitim ve çıkarım yöntemlerini de tanıttık.

Görselleştirmenin sonucu, ilk satır RGB Video, İkinci Davranış TSN+I3D-S, Üçüncü Davranış V4D
AI Teknoloji İnceleme Serisi Canlı
1, ACL 2020 -Fudan Üniversitesi Serisi Yorum
Canlı Tema: Farklı Granüler Çizim Metin Özeti Sistemi
Lektör: Wang Danqing, Zhong Ming
Oynama Bağlantı: (Dönüş Süresi: 26 Nisan'da 22:00)
Canlı Tema: Sözlük ile birlikte Çince adlandırma varlığı kimliği [ACL 2020 -Fudan Üniversitesi Serisinin (2) yorumlanması]
Yerelci: Ma Ruotian, Li Xiaonan
Canlı Süre: 26 Nisan (Pazar akşamı) 20:00.
Canlı Tema: ACL 2020 | Karşı örneğin bağımlı sözdizimi modeline dayanarak
[ACL 2020 -Fudan Üniversitesi Serisinin Yayınlanması (3)]
Lektör: Zeng Jiehang
Canlı Süre: 27 Nisan, (Pazartesi gecesi) 20:00.
2. ICLR 2020 Serisi Canlı Yayın
Canlı Tema: ICLR 2020 Eylem Anlambilim Ağı: Çok yönlü sistemlerde eylemlerin etkileri göz önüne alındığında
Konuşmacı: Wang Weizheng
Oynama Bağlantı: Tema: ICLR 2020 Olumsuz örnekleme yoluyla kendini düzeltme stratejilerini ve değer işlevlerini öğrenin
Yerelci: Luo Yuping
Oynama Bağlantı: Tema: ICLR 2020 Segmental Aktivasyon Fonksiyonu Nöral Ağ Kaybı Yüzeyini şekillendirdi
Konuşmacı: O Fengxiang
Oynama Bağlantı: katılınır?
