Çin ekibinin en son araştırması, bilgisayar "kelime düzeyinde dudak okuma" nın doğruluğunu% 84.41'e çıkardı.
Son yıllarda, derin öğrenmenin hızla gelişmesi ve geniş bir potansiyel uygulama yelpazesi ile bilgisayar görmesine dayalı dudak okuma teknolojisi giderek daha fazla ilgi görmüştür.Aynı zamanda yardımlı konuşma tanıma, biyometrik kimlik doğrulama ve yardım gibi birçok önemli uygulamaya sahiptir. İşitme engelliler vb.
Ancak dudak okuma görevinin zorluğu çok fazladır.Duyuş ve ışık değişikliklerinin neden olduğu tanıma zorluklarına, konuşmacının görünüşüne, konuşma hızının değişmesine ve diğer parazit faktörlerine karşı direnirken, dudakların hareket bilgisinin etkin bir şekilde nasıl elde edileceği kilit noktadır. Dudak görüntüsü özelliklerini kelime metinleriyle doğru bir şekilde ilişkilendirmek veya sesteş sözcükleri ayırt etmek de zordur.
Zhejiang Teknoloji Üniversitesi, Çin Bilimler Akademisi Akıllı Bilgi İşlem Temel Laboratuvarı ve Çin Bilimler Akademisi Hesaplama Teknolojisi Enstitüsü'nden araştırmacılar, dudakların görsel özelliklerini ve ses içeriğini geliştirmek için yerel özellik katmanında ve küresel sıra katmanında karşılıklı bilgi kısıtlamaları getirmeyi önerdiler. İlişki.
Bazı temel veri kümeleri üzerinde testler yaparak, ekip tarafından önerilen yöntemin etkili dudak okumayı sağlamak için aynı zamanda iyi bir ayrımcılık ve sağlamlığa sahip olması beklenmektedir.

Şekil | Kelime düzeyinde dudak okuma zor bir iştir. (A) "HAKKINDA" gerçek ek açıklama kelimesinin çerçevesi o sırada yalnızca T = 1219 çerçeve adımlarını içeriyordu. (B) Aynı kelime etiketi her zaman sürekli değişen görünüm değişikliklerine sahiptir. (Kaynak: arxiv)
Dudak okuma alanında, yani kelime düzeyinde dudak okuma alanında önemli bir teknik dal vardır.Bu görev için, yukarıdaki şekilde gösterildiği gibi aynı videoda başka kelimeler olmasına rağmen, her giriş videosuna tek bir kelime etiketi ile açıklama yapılması gerekir: (a) "Video örneği" HAKKINDA "olarak ek açıklama eklenen toplam 29 kare içerir, ancak" HAKKINDA "kelimesinin gerçek çerçevesi yalnızca T = 1219 zaman adımının karelerini içerir. Bu aralıktan önceki ve sonraki kareler" JUST "ve" "HAKKINDA" yerine TEN ". Dudak dili vizyonuna dayalı araştırmada, bir kelimenin tam sınırını bölmek bizim için her zaman zordur.
Bu özellik, aynı kelime etiketi altında farklı videolarda yansıtılan potansiyel ancak tutarlı özellikleri öğrenebilmek için iyi bir dudak okuma modeli gerektirir, böylece etkili ana çerçevelere daha çok odaklanabilir ve diğer alakasız çerçevelere daha az odaklanabilir.
Kesin olmayan kelime dağarcığı sınır zorluğuna ek olarak, aynı kelime etiketine karşılık gelen video örneklerinde her zaman büyük çeşitlilik ve görünüm değişiklikleri vardır. (B) 'de gösterildiği gibi, tüm bu özellikler, diziye direnebilmek için dudak okuma modelini gerektirir. Farklı konuşma koşullarında tutarlı potansiyel kalıpları yakalamak için gürültü.
Aynı zamanda dudak hareketlerinin sınırlı etki alanı nedeniyle konuşma sürecinde farklı kelimeler benzer fenomenler gösterebilir. Özellikle sesteş sözcüklerin varlığı, farklı sözcükler aynı ya da çok benzer görünebilir, bu da pek çok ek zorluk çıkarır, bu nitelikler modelin her bir sözcüğü ayırt edebilmesi için çerçeve düzeyinde farklı sözcüklerle ilgili ince taneli farklılıkları bulabilmesini gerektirir.
Yukarıdaki problemleri çözmek için, araştırmacılar, etkili dudak okuması elde etmek için modelin sağlam ve ayırt edici sunumları öğrenmesine yardımcı olmak için farklı seviyelerde karşılıklı bilgi maksimizasyonu (MIM) getirdiler.
Bir yandan, her bir zaman adımında üretilen özellikleri sınırlandırmak için yerel karşılıklı bilgi maksimizasyonu kısıtlamaları (LMIM) empoze ederek, ses içeriği ile güçlü bir korelasyona sahiptir ve böylece modelin ince dudak hareketlerini algılama yeteneğini geliştirir. Benzer şekilde telaffuz edilen kelimeler arasındaki "harcama" ve "harcama" gibi ince farkların yanı sıra; diğer yandan, modelin konuşma içeriğiyle ilgili ayırt etmeye daha fazla dikkat etmesini sağlayan küresel sıra düzeyi maksimum karşılıklı bilgi kısıtlaması (GMIM) tanıtıldı. Anahtar çerçeveler daha azdır ve konuşma sürecinde daha az gürültü vardır.
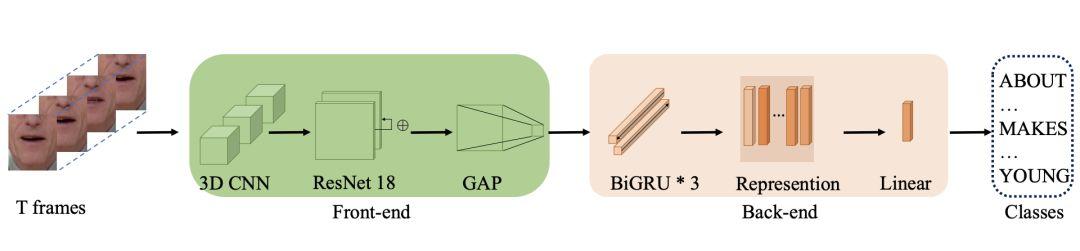
Şekil Temel mimari (Kaynak: arxiv)
Buna ek olarak GMIM, modeli farklı örneklerde aynı kelime etiketinin potansiyel olarak tutarlı genel modelini öğrenmeye zorlarken, duruş, ışık ve diğer ilgisiz koşullardaki değişikliklere karşı dayanıklıdır; LMIM, her bir adımda kelimeyle ilgili ince taneli hareketi geliştirebilir. , Farklı kelimeler arasındaki farkı daha da geliştirmek için. Model, bu iki tür kısıtlamayı birleştirerek, hedef kelimenin etkili ve önemli çerçevelerini otomatik olarak keşfedebilir ve ayırt edebilirken, diğer ilgisiz çerçeveleri göz ardı edebilir, bu da tanımanın doğruluğunu daha da geliştirir.

Şekil Benzer seslerin daha iyi tanınması (kaynak: arxiv)
Son olarak, ekip, iki büyük ölçekli kelime düzeyinde dudak okuma veri seti LRW ve LRW-1000 üzerinde, akranlar tarafından önerilen ana akım dudak dili tanıma modeli yöntemleriyle karşılaştırmalı bir değerlendirme gerçekleştirdi.Bu iki veri setinin örnekleri, hepsi farklı TV programlarında toplanan ve konuşma koşulları da ışık koşulları, çözünürlük, duruş, cinsiyet, makyaj vb. Dahil olmak üzere çeşitli konuşma koşullarını kapsayacak şekilde çok değişti.
LRW, 500 kelimelik dudak örnekleri, 1.000'den fazla konuşmacı dahil olmak üzere 2016 yılında piyasaya sürüldü, eğitim setindeki örnek sayısı 488766'ya ulaştı ve doğrulama ve test setlerindeki örnek sayısı 25.000 idi; LRW-1000 veri seti Toplam 1.000 Çince kelime, toplamda yaklaşık 718.018 örnek örneği ve yaklaşık 57 saatlik bir süreye sahip geniş ölçekli doğal olarak dağıtılmış kelime düzeyinde bir karşılaştırma veri kümesi, ancak veri kümesi, farklı konuşma kalıplarındaki ve görüntüleme koşullarındaki doğal değişiklikleri kapsayacak şekilde tasarlanmıştır. , Pratik uygulamalarda karşılaşılan zorlukları dahil etmek.

Şekil Önceki alandaki en gelişmiş yöntem modeliyle karşılaştırılan test sonuçları (Kaynak: arxiv)
LRW veri setinde, LMIM'in tanıtımı, taban çizgisinin doğruluğunu yaklaşık% 1,19 artırır. LMIM'in, ana görev için daha ayırt edici ve ince taneli özellikleri yakalaması beklenir.Aynı zamanda, GMIM'in tanıtılması, doğruluğu% 84,41'e çıkarır. Farklı çerçevelere verdiği farklı ilgi sayesinde.
Bununla birlikte, LRW-1000 veri setinde, aydınlatma koşulları, çözünürlük, konuşmacının yaşı, duruş, cinsiyet, makyaj vb. Dahil olmak üzere ses koşullarındaki büyük değişiklikler nedeniyle, endüstrinin en iyi test sonucu yalnızca% 38.19'du. Bu veri seti üzerinde iyi bir tanıma etkisi elde etmek hala bir zorluktur Yeni model yöntemi, mevcut en son sonuçlardan biraz daha iyi olan% 38.79'luk bir tanıma doğruluğuna ulaşmaktadır.
Sonuçlar, ekip tarafından önerilen yöntemin, ek veri veya ek ön eğitim modelleri kullanmadan iki zorlu veri setinde diğer dudak tanıma modellerine kıyasla yeni bir gerçek zamanlı performans durumu sunduğunu göstermektedir. . Ekip ayrıca, yöntemin diğer görevler için bir model olarak kolayca değiştirilebileceğini, böylece diğer görevler için bazı anlamlı içgörüler sağlayabileceğini belirtti.