Algoritmik önyargı dedektifi

AI Technology Review Press: Tıp kurumları ve devlet daireleri gibi toplumun her düzeyine gittikçe daha fazla algoritma girmeye devam ettikçe, algoritma yanlılığı üzerine giderek daha fazla tartışma yapılmaktadır. Nature dergisi, bu ay 2018'in en popüler ilk on bilimsel öyküsünü seçti. Bunlar arasında Rachel Courtland'ın algoritma yanlılığını tartışan makalesi başarıyla seçildi. AI Technology Review orijinal metni aşağıdaki gibi derledi.
2015 yılında endişeli bir baba, sağlık ekonomisti Rhema Vaithianathan'a aklından hâlâ geçen bir soru sordu.
O gün, Pennsylvania, Pittsburgh'da bir bodrum katında toplanan küçük bir grup insan Rhema Vaithianathan'ın yazılımın çocuk istismarı sorununu nasıl çözebileceğini anlattığını dinledi. Her gün bölgedeki yardım hattı, yakınlarda tehlikede olan çocuklar olduğundan şüphelenilen düzinelerce arama alıyor; bu aramaların bazıları, soruşturma için çağrı merkezi personeli tarafından işaretleniyor. Ancak bu sistem tüm çocuk istismarı vakalarını kontrol edemez. Vaithianathan ve meslektaşları, sorunu çözmeye yardımcı olabilecek algoritmalar geliştirmelerini gerektiren 500.000 dolarlık bir sözleşme imzaladılar.
Sağlık ekonomisti Vaithianathan, Yeni Zelanda'daki Auckland Teknoloji Üniversitesi Sosyal Veri Analiz Merkezi'nin eş direktörüdür.İnsanlara bu algoritmanın nasıl çalıştığını göstermek için aşağıdaki örneği kullanır: Örneğin, büyük miktarda veriyle eğitilmiş bir araç (aile geçmişi ve sabıka kayıtları dahil) , Bir çağrı aldığınızda bir risk puanı oluşturabilirsiniz. Bu, denetçinin araştırılması gereken haneleri işaretlemesine yardımcı olabilir.
Vaithianathan seyirciyi soru sormaya davet ettiğinde, endişeli baba (daha önce bahsedilen) ayağa kalktı ve konuştu. Uyuşturucu bağımlılığı yaşadığını ve uyuşturucu bağımlılığı ile mücadele ettiğini söyledi. Sosyal hizmet uzmanı bir keresinde çocuğunu evden uzaklaştırdı. Ancak şu anda bir süredir detoksifikasyonda başarılı. Bilgisayar kayıtlarını değerlendirdiğinde hayatını değiştirmeye yönelik bu çabalar anlamsız mı? Başka bir deyişle: Algoritmanın onun hakkındaki değerlendirmesi adil değil mi?
Yapay zekanın kara kutusunu açabilir miyiz?
Vaithianathan, babaya, insanların her zaman reform yapacağına ve çabalarının göz ardı edilmeyeceğine dair güvence verdi. Ancak bu güne kadar, bu otomatik değerlendirme aracı devreye alınmış olsa da, Vaithianathan hala bu babanın sorunu hakkında düşünüyor. Bilgisayar hesaplamaları, bir kişinin hayatını değiştirebilecek kararları kontrol etmek için giderek daha fazla kullanılmaktadır, bunlara suç işlemekle suçlanan sanıkların tutuklanması, hangi ailelerin çocuk istismarına maruz kalabileceğini araştırmak ve son "öngörücü polislik" "Trend (toplum polisinin dikkat etmesi gereken konular). Bu araçların daha tutarlı, doğru ve titiz kararlar vermesi beklenir. Ancak bu sistemin denetimi sınırlıdır: bu tür sistemlerin kaçının kullanıldığını kimse bilmiyor. Bu algoritmaların adaletsizliği uyanıklığa neden oluyor. Örneğin, 2016'da Amerikalı gazeteciler, gelecekteki suç faaliyetlerinin riskini değerlendirmek için kullanılan sistemin siyah sanıklara karşı ayrımcılık yapacağını savundu. New York Üniversitesi'nde yapay zekanın sosyal etkisini inceleyen bir araştırma merkezi olan "AI Now" Enstitüsü'nün kurucu ortağı Kate Crawford, "Benim en büyük endişem, önerdiğimiz sistemin sorunu iyileştirmesi, ancak sonunda sorunu daha da kötüleştirebileceği" dedi. Crawford ve diğerleri uyardığında, hükümet yazılımı daha güvenilir hale getirmeye çalışıyordu. Geçen yılın Aralık ayında, New York Şehir Meclisi, algoritmik bilgilerin kamuya açık paylaşımı için önerilerde bulunmak ve önyargılı olup olmadıklarını araştırmak için bir görev gücü oluşturdukları bir tasarıyı kabul etti. Bu yıl Fransa Cumhurbaşkanı Emmanuel Macron, Fransa'nın hükümetin kullandığı tüm algoritmaları ifşa edeceğini açıkladı. Bu ay yayınlanan kılavuzda İngiliz hükümeti, kamu sektöründe verilerle çalışanların şeffaf ve hesap verebilir olmaları çağrısında bulundu. Mayıs ayı sonunda yürürlüğe giren Avrupa Genel Veri Koruma Yönetmeliği (GDPR) de algoritma hesap verebilirliğini artıracak.
Rhema Vaithianathan, potansiyel çocuk istismarı vakalarını işaretlemeye yardımcı olmak için algoritmalar geliştirir.Bu tür faaliyetlerde, bilim adamları karmaşık bir soruyla karşı karşıya kalırlar: Bir algoritmayı adil hale getirmek ne anlama gelir? Kamu kurumlarında çalışan Vaithianathan gibi araştırmacılar sorumlu ve etkili yazılımlar geliştirmeye çalışıyorlar. Otomatikleştirilmiş araçların önyargılara neden olabileceği veya mevcut eşitsizlikleri derinleştirebileceği sorununu çözmek için çalışmaları gerekir, özellikle de bu araçlar zaten ayrımcı bir sosyal sisteme yerleştiriliyorsa. "Oldukça aktif bir araştırma grubu var ve bu tür sistemleri dışarıdan gözden geçirmek ve değerlendirmek için yöntemler geliştirmeye çalışıyorlar." Salt Lake City'deki Utah Üniversitesi'nde teorik bir bilgisayar bilimcisi olan Suresh Venkatasubramanian, otomatik karar verme araçlarının yol açtığı adalet sorununun yeni bir sorun olmadığına işaret etti.İnsanlar, onlarca yıldır suç veya kredi riskini değerlendirmek için aktüeryal araçlar kullandı. Büyük veri kümelerinin ve daha karmaşık modellerin popülaritesiyle, bunların etik etkilerini görmezden gelmek giderek daha zor hale geliyor. "Bilgisayar bilimcilerin başka seçeneği yok. Bu alanda araştırmaya başlamalıyız. Artık algoritmanın adilliğini görmezden gelemeyiz ve bu şekilde ne olacağını göremeyiz."
Adalet uzlaşması
2014 yılında, Pittsburgh'daki Allegheny İlçe İnsan Hizmetleri Departmanından yetkililer otomatik bir araç için tavsiye istediğinde, henüz onu nasıl kullanacaklarına karar vermemişlerdi. Ancak yeni sisteme açık olmaları gerektiğini biliyorlar. Bölümün veri analizi, araştırma ve değerlendirme ofisi müdür yardımcısı Erin Dalton, "Yaptığımız şeyi topluma açıklayamayan kara kutu çözümleri için devlet fonlarını kullanmaya son derece karşıyım" dedi. Departman, 1999 yılında inşa edilmiş ve barınma, ruh sağlığı durumu ve sabıka kayıtları gibi birçok kişisel bilgi içeren merkezi bir veri ambarına sahiptir. Dalton, Vaithianathan'ın ekibinin çocuk refahına odaklanmak için büyük çaba sarf ettiğini söyledi.
Ağustos 2016'da Allegheny Aile Tarama Aracı (AFST) piyasaya sürüldü. Çağrı merkezi çalışanı, yardım hattına yapılan her çağrı için, otomatik risk değerlendirme sistemi tarafından oluşturulan bir puan (1 ila 20 puan) görecek ve bu puanın 20 puanı en yüksek risk olarak tanımlanan vakaya karşılık geliyor. AFST, bu yüksek puanlı ailelerin çocuklarının büyük olasılıkla iki yıl içinde evden çıkarılacağını veya arayan kişinin bu çocukların istismara uğradığından şüphelenmesi nedeniyle tekrar ilçeye gönderileceğini tahmin ediyor (ilçe ikinci değerlendirme göstergesini terk ediyor. Göstergeler, daha fazla araştırma gerektiren vakaları doğru bir şekilde yansıtmıyor gibi görünüyor).
California'daki Stanford Üniversitesi'nde bağımsız bir araştırmacı olan Jeremy Goldhaber-Fiebert, hala bu aracı değerlendiriyor. Ancak Dalton, ön sonuçların aracın faydalı olduğunu gösterdiğini söyledi. Aracı benimsedikten sonra, çağrı merkezi personeli tarafından araştırmacılara sunulan davaların daha fazla meşru kaygı örneği içerdiğini söyledi. Görünüşe göre telefon denetçileri de benzer vakalarda daha tutarlı kararlar alacaklar. Yine de, kararlarının algoritmanın risk puanıyla uyuşması gerekmez; ilçe hükümeti iki sonucu birbirine yaklaştırmayı umuyor.
Reform öngörücü polislik
AFST konuşlandırıldıkça Dalton, sistemin taraflı olup olmayacağını belirlemek için daha fazla yardım istiyor. 2016'da Pittsburgh'daki Carnegie Mellon Üniversitesi'nde istatistikçi olan Alexandra Chouldchova'dan, yazılımın belirli gruplara karşı ayrımcılık yapıp yapmadığını analiz etmesine yardımcı olmasını istedi. Chouldchova daha önce algoritmadaki önyargı sorununu düşünmüştü ve bu konuda geniş kapsamlı bir tartışmaya yol açan bir vakaya katılacak. Aynı yılın Mayıs ayında, ProPublica haber sitesinden bir muhabir, Broward County yargıçları tarafından kullanılan ve bir suçla suçlanan bir sanığın duruşmadan önce hapishaneden serbest bırakılıp bırakılmayacağının belirlenmesine yardımcı olan ticari yazılımı bildirdi. Muhabirler, yazılımın siyahi sanıklara karşı önyargılı olduğunu söyledi. COMPAS adı verilen bu araç, bir kişinin iki yıl içinde tekrar suç işleme olasılığını ölçmek için kullanılan bir puan oluşturabilir. Propublica ekibi, ekibin kamu kayıtlarının talepleri yoluyla elde ettiği, binlerce sanığın COMPAS puanlarını araştırdı. Siyah ve beyaz sanıkları karşılaştırarak, muhabirler, siyah sanıkların "yanlış pozitiflerinin" (suçlu olarak kabul edilen ancak aslında suçlu olmayan) beyaz sanıklara oranının ciddi şekilde işlevsiz olduğunu keşfetti: siyahlar COMPAS tarafından yüksek riskli gruplar olarak listeleniyor, ancak gerçekte Daha sonra suçlanmadılar. Algoritmanın geliştiricisi, aracın tarafsız olduğuna inanan Northpointe (şimdi Canton, Ohio'da Equivant) adlı Michigan merkezli bir şirkettir. PUSULA'nın aynı zamanda yüksek riskli grup olarak sınıflandırılan beyaz veya siyah bir sanığın tekrar suç işleyip işlemeyeceğinin iyi bir öngörücüsü olduğunu söylüyorlar (bu bir "öngörücü denklik" örneğidir). Chouldechova kısa sürede Northpointe ve ProPublica'nın adalet önlemlerinin ters olduğunu keşfetti. Tahmine dayalı eşitlik, eşit yanlış pozitif hata oranları ve eşit yanlış negatif hata oranlarının tümü, "adaleti" yansıtmanın yolları olarak kullanılabilir, ancak iki grup arasında farklılıklar varsa - örneğin, beyazların ve siyahların tekrar tutuklanma olasılığı ( Aşağıdaki "Adalet" Nasıl Tanımlanır? Bölümüne bakın), o zaman istatistiklerde tam adalet elde etmek imkansızdır. University College London'da güvenilir makine öğrenimi araştırmacısı Michael Veale şunları söyledi: "Hem balık hem de ayı pençelerine sahip olamazsınız! Bir açıdan adil olmak istiyorsanız, o zaman mantıklı gelen başka bir durumda, bunu yapmanız gerekebilir Adil olamaz. ""Adalet" nasıl tanımlanır?
Algoritmalarda önyargı üzerine çalışan araştırmacılar, adaleti tanımlamanın birçok yolu olduğunu söylüyor, ancak bu yöntemler bazen çelişkili.
Tekrar tutuklanma risklerini ölçmek için iki grup şüpheliyi (mavi ve mor ile gösterilen) puanlamak için ceza adalet sisteminde bir algoritma kullandığınızı hayal edelim. Geçmiş veriler, mor grubun tutuklanma olasılığının daha yüksek olduğunu göstermektedir, bu nedenle model mor gruptaki daha fazla kişiyi yüksek riskli gruplar olarak sınıflandıracaktır (aşağıdaki şeklin üst kısmına bakın). Bu, model geliştiricisi, önyargıyı önlemek için bir kişinin mavi veya mor olarak sınıflandırılması gerekip gerekmediğini modele doğrudan söylememeye çalışsa bile gerçekleşir. Bunun nedeni, eğitim girdisi olarak kullanılan diğer verilerin mavi veya mor ile ilgili olabilmesidir.

Yüksek riskli durum, şüphelinin tekrar tutuklanıp tutuklanmayacağını mükemmel bir şekilde tahmin edemese de, algoritmanın geliştiricileri tahmini adil hale getirmeye çalıştı: bu iki grup insan için "yüksek risk" 2/3 şans anlamına gelir İki yıl içinde tekrar tutuklandı. (Bu adalet, öngörücü parite olarak adlandırılır.) Gelecekteki tutuklama oranları geçmişteki kalıpları takip etmeyebilir, ancak bu basit örnekte, gerçekten beklendiği gibi olduklarını varsayın: mavi grupta 3/10 ve mor grupta 3/106/10 (ve her gruptaki kişilerin 2 / 3'ü) gerçekten yeniden tutuklandı (aşağıdaki resmin altındaki gri çubuğa bakın).
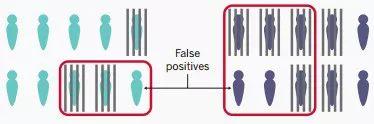
Algoritma, öngörücü pariteyi karşılar (siyah ve beyaz davalıların risk puanları açısından aynı genel doğruluğa sahip olup olmadığına bakılmaksızın), ancak yine de bir sorun vardır. Mavi grupta 7 kişiden 1'i (% 14) yüksek riskli grup olarak, mor grupta ise 4 kişiden 2'si (% 50) yüksek riskli grup olarak yanıldı. Bu nedenle, mor bireylerin yüksek riskle karıştırılan "yanlış pozitif" olma olasılığı daha yüksektir.
Mavi grup ve mor grubun üyeleri farklı bir tutuklanma olasılığına sahip olduğu sürece, öngörücü parite ve eşit bir yanlış pozitif oranı elde etmek zordur. Matematiksel olarak, üçüncü adalet kriterini karşılarken bunu başarmak imkansızdır (öngörücü parite ve eşit yanlış pozitif oran hariç): eşit bir yanlış negatif oran (düşük risk olarak tanımlanır, ancak daha sonra Tekrar tutuklananlar; yukarıdaki örnekte mor ve mavi grupların yanlış negatif oranları tamamen aynı, yani% 33).
Bazı insanlar, mor gruptaki yüksek yanlış pozitif oranlarının algoritmanın ayrımcı doğasını yansıttığına inanıyor. Ancak diğer araştırmacılar, bunun mutlaka algoritma yanlılığının kesin kanıtı olmadığına inanıyor. Bu dengesizliğin daha derin bir nedeni olabilir: Mor grup başlangıçta haksız bir şekilde hedef alınmış olabilir. Geçmiş verilere dayanarak, algoritma mor grubun daha fazla üyesinin tekrar tutuklanacağını doğru bir şekilde tahmin edebilir. Bu nedenle, algoritmanın (hatta kesinliğin) önceden var olan sosyal önyargılara sahip olduğunu düşünebiliriz.
AI Technology Review Not: İstatistiksel paradoks hakkında daha fazla bilgi için bkz. Bu meşhur istatistiksel paradoks, onu ilk duyan insanlar muhtemelen hayattan şüphe edecek Bir makale.
Aslında matematiksel açıdan adaleti tanımlamanın daha fazla yolu var: Bu yıl Şubat ayında bilgisayar bilimcisi Arvind Narayanan "21 Adillik Tanımları ve Stratejileri" başlıklı bir konuşma yaptı. Başka tanımların da olduğuna dikkat çekti. Chouldchova da dahil olmak üzere ProPublica vakasını araştıran bazı araştırmacılar, "eşit olmayan hata oranlarının, algoritmanın önyargılı olduğunu gösterip göstermediğinin" belirsiz olduğuna dikkat çekti. Stanford Üniversitesi'nde bir bilgisayar bilimcisi olan Sharad Goel, bunun yerine algoritmaların bir grup için tahmin edilmesinin diğerinden daha zor olduğu gerçeğini yansıttığını söyledi. "Bunun aşağı yukarı istatistiksel bir yanılsama olduğu ortaya çıktı."
Bazı insanlar için ProPublica vakası, birçok kuruluşun algoritma araçlarını bulmak ve doğru şekilde değerlendirmek için kaynaklara sahip olmadığı gerçeğini vurguluyor. Chicago Üniversitesi Veri Bilimi ve Kamu Politikası Merkezi direktörü Rayid Ghani şunları söyledi: "Bu durumun bize söylediği şey, Northpointe'yi istihdam eden devlet kurumunun algoritmanın ne kadar adil olduğuna dair net bir tanım vermediğidir. Devletin bu sistemleri nasıl bulacağını, algoritmaların ölçülmesi gereken göstergelerin nasıl tanımlanacağını ve satıcılar, danışmanlar ve araştırmacılar tarafından sağlanan sistemlerin gerçekten adil olmasını nasıl sağlayacağını öğrenmek için eğitim alması ve öğrenmesi gerekiyor. "
Allegheny County'nin deneyimi, bu sorunları çözmenin ne kadar zor olduğunu gösteriyor. Chouldchova, 2017'nin başlarında Allegheny'nin verilerini araştırmaya davet edildi ve bu aracın da benzer istatistiksel dengesizliklere sahip olduğunu buldu. Modelin bazı "çok istenmeyen özelliklere" sahip olduğunu söyledi. Farklı ırklar arasındaki hata oranlarındaki fark beklenenden çok daha yüksektir. Dahası, henüz net olmayan nedenlerle, en yüksek istismar riski altında olduğu düşünülen beyaz çocukların evden uzaklaştırılma olasılığı, en yüksek istismar riski altında kabul edilen siyah çocuklara göre daha azdır. Allegheny ve Vaithianathan'ın ekibi şu anda başka bir modele geçmeyi düşünüyor. Chouldchova, "Bu adaletsizliği azaltmaya yardımcı olabilir." Dedi.
İstatistiksel dengesizlik çözülmesi gereken bir sorun olsa da, algoritmada gizlenmiş daha derin adaletsizlik seviyeleri vardır (sosyal adaletsizliği şiddetlendirebilirler). Örneğin, COMPAS gibi bir algoritma başlangıçta gelecekteki suç faaliyetlerinin olasılığını tahmin etmek için tasarlanabilir, ancak yalnızca ölçülebilir modellere dayanabilir: tutuklanma gibi. Polislik uygulamalarındaki farklılıklar, bazı sosyal grupların tutuklanma olasılığının daha yüksek olduğu ve diğer sosyal gruplarda göz ardı edilebilecek suçlar nedeniyle tutuklanabilecekleri anlamına gelebilir. David Robinson, Upturn'un icra direktörüdür (Upturn, Washington, D.C.'de bulunan kar amacı gütmeyen bir sosyal adalet kuruluşudur). "Bazı vakaları doğru bir şekilde tahmin etsek bile, biz de olabiliriz Haksız bir şekilde muamele gördü. " Bu, büyük ölçüde yargıçların karar vermek için bu tür algoritmalara ne ölçüde güvendiğine bağlı olacaktır ve biz bu konuda çok az şey biliyoruz.

Camden, New Jersey'deki polis, hangi alanlarda devriye gezilmesi gerektiğini belirlemeye yardımcı olmak için otomatik araçlar kullanıyor.
Allegheny'nin araçları da benzer eleştiriler aldı. Yazar ve siyaset bilimci Virginia Eubanks, algoritmanın doğru olup olmadığına bakılmaksızın, önyargılı girdi çalışmasına dayandığına inanıyor, çünkü yardım hattında siyah ve karışık ırk ailelerinden bahsedilme olasılığı daha yüksek. Ek olarak, model Allegheny sistemindeki kamu hizmeti bilgilerine dayandığından ve bu tür hizmetleri kullanan haneler genel olarak zayıf olduğundan, algoritma daha yoksul haneleri daha sıkı bir şekilde inceleyerek bu haneleri daha adaletsiz hale getirecektir. Dalton, mevcut verilerin yüzleşmemiz gereken bir sınırlama olduğunu kabul etti, ancak insanların hala bu araca ihtiyaç duyduğuna inanıyor. Allegheny County, bu yılın başlarında AFST web sitesinde Eubanks'e yanıt verdi: "Talihsiz sosyal yoksulluk sorunu," bakımımıza ihtiyacı olan çocuklar için karar verme yeteneklerimizi geliştirme sorumluluğumuz olduğunu inkar etmiyor! "
Şeffaflık ve sınırlamaları
Bazı kurumlar kendi araçlarını veya ticari yazılımlarını oluşturmuş olsalar da, bilim adamları kamu sektörü algoritmalarındaki çalışmalarının büyük talep gördüğünü gördüler. Chicago Üniversitesi'nde Ghani, Chicago Halk Sağlığı Departmanı dahil olmak üzere bir dizi ajansla birlikte çalışarak hangi hanelerin sağlığa zararlı bir yol tutabileceğini tahmin etmek için bir araç üzerinde çalışıyor. Birleşik Krallık'ta Cambridge Üniversitesi'ndeki araştırmacılar, kovuşturmaya alternatif olarak kime müdahale edilebileceğini belirlemelerine yardımcı olacak bir model oluşturmak için Durhan County'de polisle birlikte çalıştı. Goel ve meslektaşları, bu yıl San Francisco Bölge Savcılığı Ofisi de dahil olmak üzere devlet kurumlarıyla çalışan Stanford Hesaplama Politikası Laboratuvarı'nı kurdu. Bölge Savcılığı Bürosunda analist olan Maria McKee, dışarıdan araştırmacılarla ortaklığın çok önemli olduğuna inanıyor. "Hepimiz neyin doğru neyin adil olduğunu biliyoruz, ancak bu hedefe nasıl ulaşacağımızı bize doğru ve net bir şekilde anlatacak araçlara veya araştırmaya çoğu zaman sahip değiliz." Dedi. Allegheny'nin benimsediği yaklaşımla tutarlı olan davanın şeffaflığını artırmak çok istiyor insanlar. Allegheny County paydaşlara ulaştı ve muhabirlere kapıyı açtı. AI Now Enstitüsü'nden Crawford, algoritma "algoritma incelemesini, incelemesini veya kamuya açık tartışmayı kabul edemeyen kapalı bir döngü" olduğunda, bunun genellikle sorunu yoğunlaştırdığını söyledi. Ancak algoritmanın nasıl daha açık hale getirileceği henüz belli değil. Ghani, bir modelin tüm parametrelerini basitçe yayınlamanın çalışma mekanizmasının açıklamasını sağlamadığına inanıyor. Şeffaflık, gizlilik korumasıyla da çelişebilir. Bazı durumlarda algoritmanın çalışma prensibi hakkında çok fazla bilgi ortaya çıkarmak, kötü niyetli kişilerin sisteme saldırmasına izin verebilir. Goel, hesap verebilirliğin önündeki en büyük engelin, bu ajansların genellikle bu araçları nasıl kullandıkları veya nasıl performans gösterdiklerine dair veri toplamaması olduğunu söyledi. "Çoğu durumda sözde şeffaflık yoktur, çünkü paylaşılabilecek hiçbir bilgi yoktur." Örneğin, Kaliforniya yasama organı, insanların sanıkların kefalet ödemesi ihtimalini azaltmalarına yardımcı olabilecek risk değerlendirme araçları arayan bir yasa tasarısı hazırladı, ancak bu yaklaşım, düşük gelirli sanıkları cezalandırdığı için eleştirildi. Goel, tasarının, yargıçların aracı kullanmayı kabul etmedikleri destekleyici davalara ilişkin verilerin yanı sıra kararın sonucu da dahil olmak üzere her davanın belirli ayrıntılarının toplanmasını zorunlu hale getireceğini umuyor. "Amacımız, kamu güvenliğini korurken hapis cezasını radikal bir şekilde azaltmak, bu yüzden bunun etkili olup olmadığını bilmeliyiz." Dedi. Crawford, algoritmanın güvenilirliğini sağlamak için bir dizi "yasal süreç" altyapısına ihtiyacımız olacağını söyledi. Bu yılın Nisan ayında, AI Now Institute, algoritmik karar verme araçlarını güvenilir bir şekilde benimsemek isteyen kamu kurumları için bir çerçeve geliştirdi; ayrıca, enstitü topluluk girdisi çağrısında bulundu ve insanların kararlarına itiraz etmesine izin verdi.Yapay zeka araştırmalarında kör noktalar
Pek çok insan, yasanın bu hedefleri uygulayacağını umuyor. Yapay zekanın etik ve politika konuları üzerine çalışan Cornell Üniversitesi'nden araştırmacı Solon Barocas, aslında bu tür emsallerin olduğunu söyledi. Amerika Birleşik Devletleri'nde bazı tüketiciyi koruma yasaları, vatandaşların kredi değerlendirmesine elverişli olmayan kararlar alırken vatandaşlara yorum yapma hakkı verir. Veale, Fransa'nın 1970'lerin başlarında, vatandaşlara otomatik kararları yorumlama ve bunlara itiraz etme hakkı veren yasalar çıkardığını söyledi.
En büyük test 25 Mayıs'ta yürürlüğe girecek olan Avrupa GDPR olacak. Belirli hükümler (otomatik karar verme vakalarında yer alan mantık hakkında anlamlı bilgi edinme hakkı gibi) algoritmik hesap verebilirliği teşvik ediyor gibi görünmektedir. Ancak Birleşik Krallık'taki Oxford İnternet Araştırma Enstitüsü'nde bir veri etiği uzmanı olan Brent Mittelstadt, algoritmaların adilliğini değerlendirmek isteyenler için GDPR'nin aslında algoritma adaletini engelleyen bir "yasal mayın tarlası" yaratabileceğini söyledi. Bir algoritmanın belirli açılardan önyargılı olup olmadığını test etmenin (örneğin, bir ırkı destekleyip desteklemediğini ve başka bir ırkı ayırt edip etmediğini) test etmenin en iyi yolu, sisteme dahil olan kişilerin ilgili özelliklerini anlamaktır. Ancak Mittelstadt, GDPR'nin bu tür hassas verilerin kullanımına yönelik kısıtlamalarının o kadar katı olduğunu ve cezaların o kadar yüksek olduğunu, bu nedenle algoritmaların adilliğini değerlendirme yeteneğine sahip şirketlerin bu bilgileri işlemek için fazla teşvikleri olmayabileceğini söyledi. "Bu, algoritmaların adaletini değerlendirme yeteneğimizi sınırlıyor gibi görünüyor." Dedi.
Halkın belirli bir algoritma anlayışına sahip olmasına ve halkın dikkatini çekmesine izin veren GDPR yasalarının kapsamıyla ilgili bazı sorunlar da vardır. Daha önce belirtildiği gibi, bazı GDPR kuralları yalnızca tam otomatik sistemler için geçerlidir. Bu, "algoritmaların karar verme üzerinde belirli bir etkiye sahip olduğu, ancak nihai kararı insanların vermesi gerektiği" durumunu ortadan kaldırabilir. Mittelstadt, bu ayrıntıların eninde sonunda mahkemede açıklığa kavuşturulması gerektiğini söyledi.