Adlandırılmış varlık tanıma yeni SOTA: geliştirilmiş Transformer modeli

Yazar | Wangwang Liu
Editör | Tang Li
TENER: Ad Varlık Tanıma için Trafo Kodlayıcıyı Uyarlama
Bağlantı: https: // ar xi v.org/pdf/1911.04474.pdf
Kod: Hayır
Bir. motivasyon
Transformer modeli, iyi paralellik yetenekleri ve mükemmel efektleri ile nlp alanındaki makine çevirisi, eğitim öncesi dil modelleri vb. Gibi büyük görevlerde yaygın olarak kullanılmaktadır. Blog (https: //zhuanlan.zhihu .com / p / 54743941) Ayrıca birçok açıdan deneyler, Transformer modelinin CNN ve RNN modellerinden daha iyi olduğunu göstermektedir. Bununla birlikte, NER görevinde, Transformer BiLSTM'den çok daha az etkilidir.
iki. Önkoşul bilgisi
NER
NER olarak kısaltılan adlandırılmış varlık tanıma, metindeki belirli anlamlara sahip varlıkların tanımlanmasını ifade eder, temel olarak kişilerin, yerlerin, kuruluşların, özel isimler vb. Adlarının yanı sıra zaman, miktar, para birimi ve orantılı değerler gibi sözcükler de genellikle sıralar olarak kabul edilir. Görevleri etiketlemek için mevcut ana yöntem, üç parça içeren sinir ağlarını kullanmaktır: kelime vektör katmanı, bağlam kodlama katmanı ve kod çözme katmanı.
Transformatör
Transformatör katmanı iki bölümden oluşur: Multi-Head Attention (MHA) ve Position-wise Feed-Forward Network (FFN).
MHA:
Tek dikkat başlığı hesaplama yöntemi:

Çoklu dikkat başı hesaplama yöntemleri:
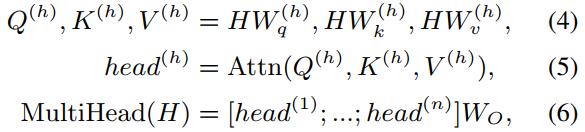
FFN:

MHA katmanı ile FFN katmanı arasında ve FFN katmanından sonra ayrıca bir artık bağlantı ve norm katmanı vardır. Ayrıntılar için https: // ar yazısına bakın xi v.org/pdf/ 1706 .03762.pdf
üç. Çözüm
Makale, Transformer'in neden NER görevlerinde iyi performans göstermediğinin nedenlerini analiz etmekte ve geliştirilmiş bir TENER (NER için Transformer Encoder) yöntemi önermektedir.
Transformer'in NER görevlerinde iyi performans göstermemesinin nedenleri

Şekil 1'de gösterildiği gibi, yön bilgisi ve göreceli konum NER görevleri için önemlidir. Örneğin, "Inc" kelimesinden önceki kelime muhtemelen bir organizasyon (ORG) ve "in" kelimesinden sonraki kelime muhtemelen bir zaman ve yer (TIME) olacaktır ve bir varlık kırmızı ile işaretlenmiş ardışık kelimelerden oluşmalıdır "Louis Vuitton", mavi "Inc" ile bir varlık oluşturmayacaktır. Ancak orijinal Transformer bu bilgiyi yakalayamaz.
Yukarıdaki sorunlara yanıt olarak, makale iki iyileştirme önermektedir:
(1) Yön ve göreceli konum bilgileri içeren bir onay mekanizması önerin;
(2) Orijinal Transformatör öz-dikkat ölçek faktörü atılır. Ölçek faktörü, nispeten eşit dağıtılmış bir dikkat ağırlığı elde etmek için eklenir, ancak NER'de gerekli değildir Dikkat Tüm kelimeler.
Ayrıca, kelime düzeyinde bağlam bilgisini modellemek için Transformer'ı kullanmanın yanı sıra, Transformer ayrıca karakter düzeyinde bilgileri modellemek için de kullanılır.
Kağıt geliştirilmiş TENER modeli
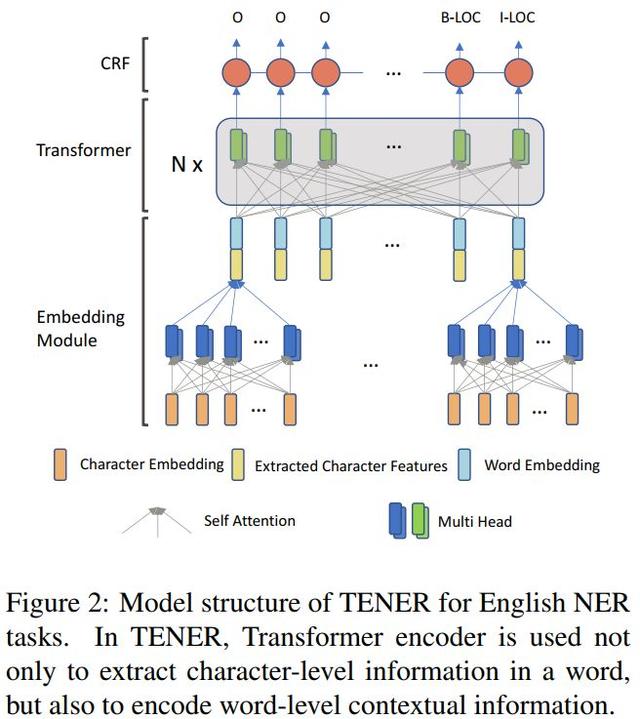
1. Kelime vektör katmanı
Verilerin seyrekliğini ve oov problemini iyileştirmek için, NER görevleri genellikle kelimeleri temsil edecek karakter dizilerini kodlamak için CNN kullanır. Bilstm ile karşılaştırıldığında, CNN karakter dizilerini kodlamada daha etkilidir Makale ayrıca, kelime temsillerini elde etmek için karakter dizilerini kodlamak için Transformer kullanımını araştırdı. Son kelime vektörü temsili, karakter dizisi ve harici eğitim öncesi kelime vektörü tarafından temsil edilen kelimenin birleştirilmesidir.
2. İle Yön ve göreceli konum bilgilerine sahip atak mekanizması
Orijinal transformatör kodlayıcı, konum vektörünü elde etmek için aşağıdaki formülü kullanır:

t, metindeki sözcüğün konumu, d, konum vektörünün boyutu ve ayrıca sözcük vektörünün boyutudur,

. Formüle göre, konum vektöründeki tek ve çift boyutların değerleri sırasıyla hesaplanır. Makale, formül (8) (9) 'a göre elde edilen konum vektörünün yalnızca göreceli konum bilgisine sahip olduğunu, ancak yön bilgilerini içermediğini belirtti. , Kanıt şu şekildedir:

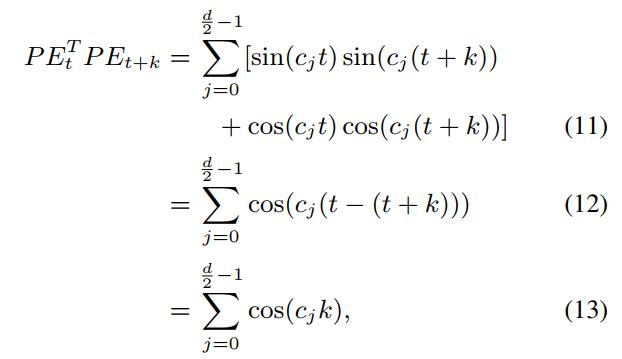
onların arasında,

Sabit mi

Formül (11) ila Formül (12), aşağıdaki formülle belirlenir

almak. Formül (13) 'e göre, t'inci konumun konumu

Ve t + k. Konumun konum vektörü
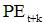
Çarpın, elde edilen sonuç sadece göreli konum k ile ilgilidir. Ve izin ver

,Mevcut:

Formül (14) (15) ayrıca formül (8) (9) 'a göre elde edilen konum vektörünün sadece göreli konum bilgisini içerdiğini ancak yön bilgisini içermediğini gösterir Parmak izi3 de bu sonucu kanıtlar.

Daha da önemlisi, öz-dikkati hesaplarken, sadece yakalanabilen göreceli konum bilgisi kaybolacaktır. Formül (1) 'den, öz dikkat gerçekleştirirken önce matristen geçilmesi gerektiği görülebilir.
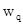
, H'yi (konum vektörü ve kelime vektörü kombinasyonu) karşılık gelen boşluğa dönüştürün. Aslında, iki konum vektörü şu şekilde hesaplanır:

(
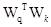
Bir matris olarak görüldüğünde,

). İki W'yi rastgele örnekleyin ve sonuç grafiğini çizin. Finger4'te gösterildiği gibi, matris dönüşümü yapılmadığında, konum vektörü göreceli konum bilgisini yakalayabilir.Matris dönüşümünden sonra, yani öz-dikkat gerçekleştirirken, göreceli konum bilgisi yok edilir.

Makale, göreli konum bilgilerini ve yön bilgilerini yakalarken öz dikkatini hesaplamak için formül (1) - (3) ve formül (8) (9) yerine aşağıdaki formülleri kullanır: formül (16), formül (1), K ile karşılaştırılır Artık eşlenmez; t hedef simgenin dizinidir, j bağlam simgesinin dizinidir, formül (17) konumu kodlarken göreceli konum ve yön bilgilerini sunar, mesafe t (j = 0) ve mesafe - Formül (20) 'de gösterildiği gibi t'nin (j = 2t) iki konumunun konum vektörleri tek sayılı boyutlarda farklıdır ve çift sayılı boyutlarda aynıdır. Formül (18) 'de dikkat ağırlığı hesaplanırken kelime vektörü konum vektöründen ayrı olarak hesaplanır (NER görevi için konum çok önemlidir) ve bir önyargı terimi eklenir. Formül (3) ile karşılaştırıldığında formül (19) kaldırılır
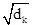
.

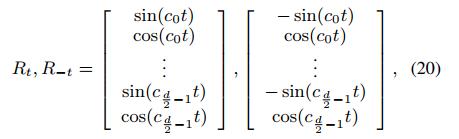
Sorun, K'nin artık eşlenmemiş olmasıdır, bu nedenle K'nin boyutu, kelime vektörünün boyutuyla aynıdır, bu da karşılaştırılamaz.

(Boyutlar
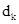
) Matris çarpım işlemlerini gerçekleştirin. Makalenin yazarı ayrıca burada bazı yazım hataları olduğunu söyledi. İfade etmek istediğim, her bir dikkat başlığını K'den (yani, H) hesaplamak ve 0'dan

Boyut

Boyutlar vb.
3. CRF katman kod çözme
Önceki Bilstm ile aynı, esas olarak farklı etiketler arasında bağımlılık bilgilerini tanıtmak için. Giriş sırası verildiğinde:
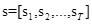
Ve etiket

.

Olası tüm etiketleme dizilerini temsil eder. Y etiketleme olasılığı şu şekilde hesaplanır:
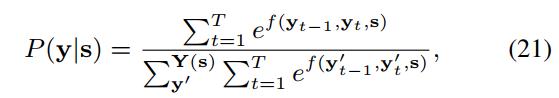
onların arasında,
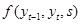
Ek açıklamadan hesapla

Etiketlemek için
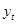
Transfer puanı ve skor, optimizasyonun amacı maksimize etmektir
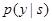
. Kod çözme sırasında, Viterbi algoritması, en yüksek olasılıkla y'yi seçmek için kullanılır.
dört. Deneysel sonuçlar
veri seti
Çince veri kümesindeki (tablo1) sonuçlar, Çince NER doğrudan şu kelimelere dayanmaktadır:
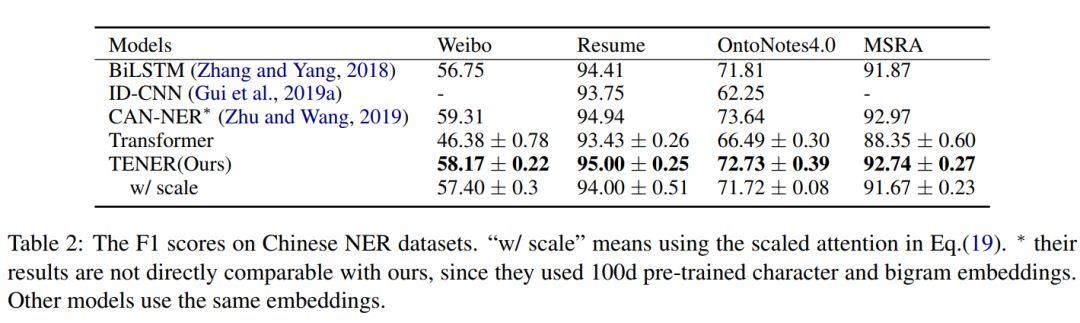
1. TENER'in etkisi sadece orijinal Transformer modelinden daha iyi değil, aynı zamanda CNN tabanlı modelden ve Bilstm tabanlı modelden daha iyidir.Bunların arasında CAN_NER, 100 boyutlu önceden eğitilmiş kelime vektörleri ve bigram vektörleri kullandığından, etki daha iyidir.
2. Weibo veri seti nispeten küçüktür, bu nedenle farklı modeller bu veri setinde kötü performans gösterir. TENER modeli ayrıca diğer modellere kıyasla etkiyi geliştirir, bu da bu makalede önerilen geliştirilmiş yöntemin veri setinin boyutuna belirli bir sağlamlığa sahip olduğunu gösterir.
3. Ölçek faktörü ile kişisel dikkat, sonucu daha da kötüleştirecektir.
İngilizce veri seti üzerindeki etki (tablo2):
1. TENER'in İngilizce veri seti üzerindeki etkisi yalnızca orijinal Transformer modelinden daha iyi değil, aynı zamanda Bilstm tabanlı modelden de daha iyidir ve şu anda en iyi sonuçları elde etmiştir.
2. Aynı ölçek faktörüyle kişisel dikkat, sonucu daha da kötüleştirecektir.

Farklı karakter kodlayıcıların ve kelime bağlam kodlayıcılarının kombinasyon sonuçları (tablo4):

İki İngilizce veri setinde, farklı karakter kodlayıcıların ve kelime bağlam kodlayıcılarının birleşik sonuçları karşılaştırılır.Tablo4, 2013 veri setinde CNN tabanlı karakter kodlayıcı + TENER tabanlı kelime bağlam kodlayıcı En iyi sonuçlar elde edilmiştir; ancak, OntoNote5.0'da en iyi sonuçları elde etmek için tüm TENER modelleri kullanılmıştır. Ancak ne tür bir karakter kodlayıcı kullanılırsa kullanılsın veya hatta karakter kodlaması kullanılmasa da, kelime bağlamını modellemek için TENER modelini kullanmak etkiyi artırabilir.
Yakınsama hızının karşılaştırılması (şekil 5):

TENER modelinin yakınsama hızı Bilstm'inkine eşittir ve trafo ve ID-CNN'den daha hızlıdır.
Beşler. sonuç olarak
1. Transformer'in NER görevlerinde iyi performans göstermemesinin nedenlerini analiz edin
2. NER için kullanılan Transformer'in (TENER modeli) konum kodlaması ve öz-dikkat kısmı geliştirildi ve iyi sonuçlar elde edildi.İki İngiliz veri setinde, mevcut en iyi sonuçlar elde edildi.
3. Makalenin en göze çarpan kısmı, Transformer'in NER görevinde neden iyi performans göstermediğinin nedenlerinin analizinde yatmaktadır. Öz dikkatin iyileştirilmesi, biraz Transformer XL'e benzer.


