Özel Bayes sınıflandırma algoritmasını anlamak için bir makale (öğrenme kaynakları ile)

Bayes sınıflandırması, Bayes teoremine dayanan bir sınıflandırma algoritmaları sınıfı için genel bir terimdir, bu nedenle topluca Bayes sınıflandırması olarak adlandırılırlar. Bu makale öncelikle sınıflandırma problemini tanıtır ve sınıflandırma probleminin tanımını verir. Sonra Bayes sınıflandırma algoritması-Bayes teoreminin temelini tanıtın. Son olarak, en basit Bayes sınıflandırması olan Naif Bayes sınıflandırmasını tanıtıyoruz ve bunu uygulama durumlarıyla daha da açıklıyoruz.
Bayes sınıflandırması
1. Sınıflandırma sorunlarının özeti
Her birimiz sınıflandırma sorununa yabancı değiliz, çünkü onu günlük hayatımızda az ya da çok kullanıyoruz. Örneğin, bir yabancı gördüğünüzde, beyniniz bilinçaltında TA'nın bir erkek ya da kadın olduğunu yargılar; sık sık yolda yürüyebilir ve yanınızdaki bir arkadaşınıza şöyle diyebilirsiniz: "Bu kişi ilk bakışta çok zengin ve orada ana akım olmayan bir kişi var. "Aslında bu bir sıralama işlemidir.
Matematiksel açıdan, sınıflandırma problemi şu şekilde tanımlanabilir:
Bilinen küme:
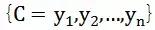
ile
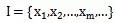
Eşleme kurallarını belirlemek için
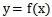
, 0 herhangi yapmak
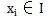
Tek ve tek
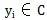
Yapmak
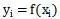
Kuruldu. Bunlar arasında, C'ye kategori kümesi adı verilir; burada her öğe bir kategori ve I, her öğenin sınıflandırılacak bir öğe olduğu ve f'ye sınıflandırıcı olarak adlandırılan bir öğe kümesi denir. Sınıflandırma algoritmasının görevi, sınıflandırıcı f'yi oluşturmaktır.
Burada, sınıflandırma problemlerinin eşleme kurallarını oluşturmak için sıklıkla deneysel yöntemler kullandığı, yani normal koşullar altında sınıflandırma problemlerinin% 100 doğru haritalama kurallarını oluşturmak için yeterli bilgiden yoksun olduğu, ancak belirli bir olasılık anlamını elde etmek için deneysel verilerin öğrenilmesi yoluyla vurgulanması gerekir. Bu nedenle, eğitimli sınıflandırıcı, sınıflandırılacak her bir öğeyi doğru bir şekilde sınıflandıramayabilir.Sınıflandırıcının kalitesi ve sınıflandırıcının yapım yöntemi, sınıflandırılacak verilerin özellikleri, eğitim numunelerinin sayısı ve diğer birçok faktör ilişkili.
Örneğin, bir doktorun bir hastayı teşhis etmesi tipik bir sınıflandırma sürecidir. Hiçbir doktor hastanın durumunu doğrudan göremez, ancak durumu anlamak için yalnızca hastanın semptomlarını ve çeşitli laboratuar test verilerini gözlemleyebilir. Şu anda doktor bir doktor gibidir. Sınıflandırıcı ve doktorun teşhisinin doğruluğu, eğitim alma şekli (yapım yöntemi), hastanın semptomlarının belirgin olup olmadığı (sınıflandırılacak verilerin özellikleri) ve doktorun deneyimi (eğitim numunelerinin sayısı) ile yakından ilgilidir.
2. Bayes sınıflandırmasının temeli-Bayes teoremi
Bu teorem, gerçek hayatta sıklıkla karşılaşılan bir sorunu çözer: belirli bir koşullu olasılığı bilmek, değişimden sonra iki olayın olasılığını nasıl elde edeceğimizi, yani P (B | P (A | B) bilindiğinde nasıl bulunur? A). İlk önce koşullu olasılığın ne olduğunu açıklayın:
P (A | B), B olayının meydana geldiği öncülü altında A olayının meydana gelme olasılığını temsil eder ve B olayı meydana geldiğinde A olayının koşullu olasılığı olarak adlandırılır. Temel çözüm formülü:
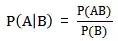
Bayes teoremi kullanışlıdır çünkü hayatımızda bu durumla sık sık karşılaşıyoruz: P (A | B) 'yi doğrudan kolayca alabiliriz ve P (B | A)' yı doğrudan elde etmek zordur, ancak biz P (B | A) 'yı daha çok önemsersek, Bayes teoremi P (A | B)' den P (B | A) elde etmemizin yolunu açacaktır.
Aşağıdakiler, Bayes teoremini doğrudan kanıt olmadan verir:
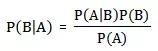
3. Naive Bayes Sınıflandırması
Naif Bayes Sınıflandırmasının ilkesi ve süreci:
Naive Bayes (sınıflandırıcı), eğitim örneklerine dayalı olarak olası her kategoriyi modelleyen üretken bir modeldir. Her bir özniteliğin sınıflandırma sonuçlarını bağımsız olarak etkilediğini varsayan özniteliklerin koşullu bağımsızlığı varsayımı nedeniyle Naive Bayes olarak adlandırılır. Yani aşağıdaki formül:
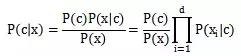
Sonraki çarpımda not edilmelidir ki 0 olasılık değeri varsa, sonraki tahmini etkileyecektir, bu nedenle özellik olasılığı için 0 değil, görünmeyen küçük bir değer belirledik, bu Laplace düzeltmesidir ( Laplacian düzeltmesi).
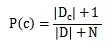
Laplace düzeltmesi aslında öznitelik değerlerinin ve kategorilerinin tekdüze bir dağılımını varsayar ve ek olarak öğrenme sürecine ön bilgileri getirir.
Tüm saf Bayes sınıflandırması üç aşamaya ayrılmıştır:
Aşama1: Hazırlık aşaması, Bu aşamadaki görev, saf Bayes sınıflandırması için gerekli hazırlıkları yapmaktır. Asıl çalışma, özellik özniteliklerini belirli duruma göre belirlemek ve her bir özellik özniteliğini uygun şekilde bölmek ve ardından bir eğitim örneği oluşturmak için sınıflandırılacak öğelerin bazılarını manuel olarak sınıflandırmaktır. Ayarlamak. Bu aşamanın girdisi, sınıflandırılacak tüm verilerdir ve çıktı, özellik öznitelikleri ve eğitim örnekleridir. Bu aşama, tüm saf Bayes sınıflandırmasında manuel olarak tamamlanması gereken tek aşamadır.Kalitesinin tüm süreç üzerinde önemli bir etkisi olacaktır.Sınıflandırıcının kalitesi büyük ölçüde özellik özellikleri, özellik özelliklerinin bölünmesi ve eğitim örneklerinin kalitesi ile belirlenir.
Aşama2: Sınıflandırıcı eğitim aşaması, Bu aşamanın görevi, bir sınıflandırıcı oluşturmaktır. Asıl çalışma, eğitim örneğindeki her kategorinin ortaya çıkma sıklığını ve her kategori için her özellik öznitelik bölümünün koşullu olasılık tahminini hesaplamak ve sonuçları kaydetmektir. Girdi, özellik öznitelikleri ve eğitim örnekleridir ve çıktı, sınıflandırıcıdır. Bu aşama, yukarıda tartışılan formüle göre program tarafından otomatik olarak hesaplanabilen mekanik bir aşamadır.
Aşama3: uygulama aşaması, Bu aşamanın görevi sınıflandırıcıyı sınıflandırılacak maddeleri sınıflandırmak için kullanmaktır Girdi sınıflandırıcı ve sınıflandırılacak maddelerdir ve çıktı, sınıflandırılacak maddeler ile kategori arasındaki eşleştirme ilişkisidir. Bu aşama da mekanik bir aşamadır ve programla tamamlanır.
4. Yarı naif Bayes Sınıflandırması
Naif sınıflandırmada, her bir öznitelik arasındaki bağımsızlığı varsayarız, bu hesaplama kolaylığı içindir ve öznitelikler arasındaki çok fazla bağımlılığın neden olduğu çok sayıda hesaplamayı önler. Bu tam anlamıyla naifin anlamıdır. Naif Bayes'in sınıflandırma etkisi iyi olmasına rağmen, her şeyden önce nitelikler arasında bir korelasyon vardır.Bir nitelik başka bir niteliğe bağlıdır, bu yüzden yarı naif bir Bayes sınıflandırıcısı vardır.
Çok fazla hesap yapmamak için, her bir niteliğin yalnızca diğerine bağlı olduğu varsayılır. Bu şekilde gerçek durum daha doğru tanımlanabilir.
Formül şöyle olur:
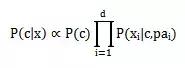
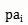
Öznitelik
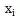
Bağlı olduğu nitelik olur
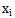
Üst nitelik.
Üst niteliği belirlemek için aşağıdaki yöntemler vardır:
-
SOPDE yöntemi. Bu yöntem, tüm özniteliklerin ortak bir ana özniteliğe bağlı olduğunu varsayar.
-
TAN yöntemi. Her bir özniteliğin bağlı olduğu diğer öznitelikler, maksimum ağırlıklı kapsayan ağaç tarafından belirlenir.
-
Öncelikle aralarındaki ağırlık olarak her özellik arasındaki karşılıklı bilgiyi arayın.
-
Bileşenin tam çizimi. Ağırlık, yeni elde edilen karşılıklı bilgidir. Ardından, bu grafiğin maksimum ağırlıklı yayılma ağacını elde etmek için maksimum ağırlıklı yayılma ağacı algoritmasını kullanın.
-
Bir kök değişkeni bulun ve ardından grafiği sırayla yönlendirilmiş bir grafiğe dönüştürün.
-
Her özelliğin yönlendirilmiş kenarına y kategorisini ekleyin.
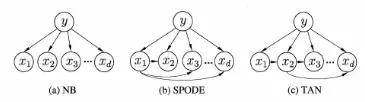
Üç yöntemin öznitelik bağımlılığı
Bayes algoritması uygulamalarına örnekler
Aşağıda, esas olarak makine öğreniminde kullanılan Bayes yönteminin evrenselliğini göstermek için bazı pratik örneklerden alıntı yapıyoruz.
2.1 Çince kelime segmentasyonu
Google araştırmacısı Wu Jun'un "Matematiğin Güzelliği" serisinde Çince kelime segmentasyonunu tanıtan bir makalesi var, işte sadece ana fikir.
Kelime segmentasyon problemi şu şekilde tanımlanır: Nanjing Yangtze Nehri Köprüsü gibi bir cümle (dizge) verildiğinde. Bu cümlenin nasıl bölümlere ayrılacağı (kelime dizgisi) en güvenilir olanıdır. Örneğin:
-
Nanjing Şehri / Yangtze Nehri Köprüsü
-
Nanjing / Belediye Başkanı / Jiang Köprüsü
Bu iki katılımcıdan hangisi daha güvenilirdir?
Bu sorunu resmi olarak tanımlamak için Bayes'in formülünü kullanıyoruz, X bir dizge (cümle) ve Y bir dizge (belirli bir kelime bölümleme hipotezi) olsun. Sadece P (Y | X) 'i en büyüğü yapan Y'yi bulmalıyız, Bayes'i bir kez kullanarak:
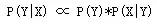
Doğal dilde, bu kelime bölütleme (kelime dizgisi) olasılığı, bu kelime dizgisinin cümlenizi oluşturma olasılığı ile çarpılır. P (X | Y) 'nin yaklaşık olarak 1'e eşit olarak kabul edilebileceğini kolayca görebiliriz, çünkü herhangi bir varsayımsal kelime bölütleme yöntemi altında üretilen cümlelerimiz her zaman doğru bir şekilde üretilir (sadece kelime bölütleme ) Arasındaki sınırlama sembolünü atın. Bu nedenle, bu kelime dizgisinin (cümlenin) olasılığını maksimuma çıkaran bir kelime bölütlemesini bulmak olan P (Y) 'yi maksimize etmeye başladık. Ve bir kelime dizgisinin olasılığı nasıl hesaplanır: W1, W2, W3, W4 ..?
Ortak olasılık formülüne göre: P (W1, W2, W3, W4 ..) = P (W1) * P (W2 | W1) * P (W3 | W2, W1) * P (W4 | W1, W2, W3) * .. Böylece, bir dizi koşullu olasılığın çarpımı (doğru formül) aracılığıyla tüm ortak olasılığı bulabiliriz. Ne yazık ki, koşulların sayısı arttıkça (P (Wn | Wn-1, Wn-2, .., W1) için n-1 koşulları vardır), veri seyrekliği sorunu, külliyat bile olsa daha ciddi hale gelecektir. Güvenilir bir P (Wn | Wn-1, Wn-2, ..., W1) saymak imkansızdır.
Bu sorunu hafifletmek için, bilgisayar bilimcileri "naif" hipotezi kullanmaya devam ediyorlar: Bir cümledeki bir kelimenin olasılığının yalnızca ondan önceki sınırlı k kelimeye bağlı olduğunu varsayıyoruz (k, yalnızca bir öncekine bağlıysa, genellikle 3'ü geçmez. Bir kelime 2 gramlık bir dil modelidir (2 gram), benzer şekilde 3 gram, 4 gram vb. Vardır), bu sözde "sınırlı ufuk" hipotezidir. Bu varsayım biraz idealist görünse de, sonuçlar sonuçlarının genellikle çok güçlü olduğunu göstermektedir. Daha sonra değinilen Naive Bayes yönteminin kullandığı varsayımlar, ruhen bununla tamamen tutarlıdır. Neden böyle bir varsayım açıklayacağız. İdeal hipotezler güçlü sonuçlar verebilir.
Şu anda, bu varsayımla ürünün hemen şu şekilde yeniden yazılabileceğini bildiğimiz sürece: P (W1) * P (W2 | W1) * P (W3 | W2) * P (W4 | W3) .. (her kelime varsayılarak Sadece ondan önceki kelimeye bağlıdır). P (W2 | W1) istatistikleri artık veri seyrekliği ile uğraşmamaktadır. Yukarıda bahsettiğimiz "Nanjing Yangtze Nehri Köprüsü" örneğinde, kelimeleri açgözlü yönteme göre soldan sağa ayırırsak, sonuç "Nanjing Belediye Başkanı / Jiang Köprüsü" olacaktır. Ancak Bayesci kelime segmentasyonuna göre (3 gram kullanıldığı varsayılırsa), "Nanjing Belediye Başkanı" ve "Jiang Köprüsü" kelimelerinin külliyatta bir arada görünme sıklığı 0 olduğu için, tüm bu cümlenin olasılığı 0 olarak değerlendirilecektir. Sonuç olarak, kelime segmentasyonu "Nanjing Şehri / Yangtze Nehri Köprüsü" kazanır.
2.2 Bayesian spam filtresi
Bir e-posta verildiğinde, spam olup olmadığını belirleyin. Emsale göre, bu e-postayı temsil etmek için hala D kullanıyoruz. D'nin N kelimeden oluştuğunu unutmayın. İstenmeyen e-postayı belirtmek için h + ve normal e-postayı belirtmek için h- kullanıyoruz. Sorun resmi olarak şu soruyla tanımlanabilir:
P (h + | D) = P (h +) * P (D | h +) / P (D)
P (h- | D) = P (h-) * P (D | h-) / P (D)
Bunlar arasında, P (h +) ve P (h-) bu iki önceki olasılığı bulmak çok kolaydır.Sadece bir posta kitaplığındaki istenmeyen postanın normal postaya oranını hesaplamanız gerekir. Bununla birlikte, P (D | h +) 'nın bulunması kolay değildir, çünkü D, N kelime d1, d2, d3, .. içerir, bu nedenle P (D | h +) = P (d1, d2, .., dn | h +). Veri seyrekliği ile tekrar karşılaştık, bunu neden söylüyoruz? P (d1, d2, .., dn | h +), mevcut e-postamızla tam olarak aynı olan bir e-postanın istenmeyen e-postalarda görünme olasılığının çok düşük olduğu, çünkü her bir e-posta farklı olduğu ve Sonsuz mesajlar. Bu veri seyrekliğidir, çünkü eğitim veritabanında ne kadar e-posta toplarsanız toplayın, şu anki ile tamamen aynı olanı bulmanın imkansız olduğunu söylemek güvenlidir. Bunun sonuçları? P (d1, d2, .., dn | h +) 'yı nasıl hesaplamalıyız?
P (d1, d2, .., dn | h +) 'ı şu şekilde genişletiriz: P (d1 | h +) * P (d2 | d1, h +) * P (d3 | d2, d1, h +) * ... Bu formül herkese aşina olmalı.Burada daha radikal bir varsayım kullanacağız.Di ve di-1'in tamamen koşullu bağımsız olduğunu varsayıyoruz, bu nedenle formül P (d1 | h +) * P (d2 | h + ) * P (d3 | h +) * ... Bu sözde koşullu bağımsızlık hipotezi ve aynı zamanda Naive Bayes Metodu'nun basitliğidir. Ve hesaplamak için P (d1 | h +) * P (d2 | h +) * P (d3 | h +) * .. Bu noktada problem basitleşir, sadece spam'deki di kelimesinin sıklığını sayın.
Yukarıdaki çalışma sayesinde, Bayesci çıkarımın temelde belirli bir sonuç veremeyeceğini, çünkü tüm olasılıkları tüketemeyeceğini gördük. Bununla birlikte, çok sayıda testten sonra, elde edilen test sonuçları doğruysa, algoritmamıza çok güveneceğiz (algoritmanın doğruluğu doğrulanmamış olsa bile). Aslında, yeni test sonuçları ortaya çıktıkça, algoritmanın güvenilirliği giderek değişiyor.
Hayatta, Bayes Teoremini kasıtlı veya kasıtsız olarak sıklıkla kullanırız.Algoritma perspektifinden, ilkeleri gerçekten anlamak istiyorsak, matematiksel istatistiklere ilişkin daha derinlemesine bilgi edinmemiz ve uygulamaya devam etmemiz gerekir.Sonunda, herkesin Bir şey kazanabilir.
Önerilen kitaplar:
-
"Bayes Yöntemi: Olasılıksal Programlama ve Bayesci Çıkarım"
-
"Bayes Analizi"
-
"Bayesçi Düşünce: İstatistiksel Modelleme için Python Öğrenme Yöntemi"
Literatür referansı:
1.
2. https://wenku.baidu.com/view/8ae844c843323968001c921d.html
3.
4. Bayes Yöntemi: Olasılıksal Programlama ve Bayesci Çıkarım (Artı) Cameron Davidson-PiIon; Xin Yuan, Zhong Li, Ouyang Ting tarafından çevrildi

Feng Ye, Peking Üniversitesi yazılım mühendisliği bölümünün ikinci yılında okuyorum, veri madenciliğine büyük ilgi duyuyorum, henüz emekleme aşamasındayım ve herkesle birlikte ilerlemeyi umuyorum.