Özel Sinir ağını oyun oynamak için eğitmek için Q öğrenme algoritmasını kullanmayı öğretin (kaynak kodu ile)

Orijinal başlık: NeuralNetwork'e Q-öğrenme kullanarak oyun oynamayı öğretmek
Yazar: Soren D
Çeviri: Yang Jinhong
Bu makalenin uzunluğu 6000 kelime , Okumanız tavsiye edilir 12 dakika
Bu makale, bilgisayar oyunlarını oynamak için sinir ağına ve Q öğrenme algoritmasına dayalı bir yapay zekanın nasıl oluşturulacağını açıklar.
Daha önce, yapay zekaya basit oyunları oynamayı öğretmek için Q öğrenme algoritmasını kullanmayı tanıtmıştık, ancak bu blog ek boyutların getirilmesi nedeniyle daha karmaşık olacak. Bu blog gönderisinden en iyi şekilde yararlanmak için, önce bir önceki yazıyı (https://www.practicalai.io/teaching-ai-play-simple-game-using-q-learning/) okumanızı tavsiye ederim.
Bu örneğin tam kaynak kodu Github'da mevcuttur (https://github.com/daugaard/q-learning-simple-game/tree/neuralnetwork). Takviye öğrenme algoritmasının sinir ağı versiyonunun sinir ağı dalında olduğuna dikkat edin.
oyun
Oyunumuz basit bir "peynir yakalama" oyunudur. Oyuncu P, peynir C'yi yakalamak ve O çukuruna düşmekten kaçınmak için hareket etmelidir.
Oyuncu P bir puan almak için bir peynir bulur ve oyuncu P çukura düştüğünde bir puan düşülür. Kullanıcı 5 puan veya -5 puan alırsa oyun sona erer.
Yukarıda belirtildiği gibi, orijinal oyunu oyuncuların yukarı, aşağı, sola ve sağa hareket edebileceği yeni bir boyutla genişletiyoruz. Bu gif, oyuncunun bu yeni oyunu oynadığını gösterir.

Sinir ağına dayalı pekiştirmeli öğrenme
Önceki makalede, AI oluşturmak için bir Q tablosu elde etmek için q öğrenme algoritmasını kullandık. Algoritma, mevcut durumda en iyi sonraki eylemi bulmak için Q tablosunu kullanır (Q öğrenme algoritmasının nasıl çalıştığını anlamak istiyorsanız, bu makaleyi kontrol edebilirsiniz (https://www.practicalai.io/teaching-ai-play-simple- oyun kullanarak q öğrenme # q-öğrenme-algoritması)). Basit oyunlar için iyidir, çünkü oyunun karmaşıklığı arttıkça, Q tablosunun karmaşıklığı da artar. Bunun nedeni, olası her oyun durumunda S, Q tablosunun her olası A eyleminin q değerini içermesi gerektiğidir.
Alternatif bir yöntem, Q tablosu sorgusu yerine bir sinir ağı kullanmaktır. Sinir ağı, S durumunu ve A eylemini girdi olarak alır ve aynı zamanda q değerini verir. Q değeri, S durumunda A eylemini gerçekleştirmenin olası ödülünü ifade eder.
Sinir ağının gerçekleştirilmesiyle, S durumunda hangi A eyleminin gerçekleştirileceğini belirleyebiliriz. AI'mız, ağı her eylem için bir kez çalıştıracak ve sinir ağı çıktısını en yüksek yapan eylemi seçecektir.Bu yaklaşım, AI'nın ödülünü maksimize edecektir.
Sinir ağımızı eğitmek için, orijinal Q öğrenme algoritmasına benzer bir yöntem kullanacağız, ancak bu sinir ağında bazı özel ayarlamalar yaptık:
-
ADIM 1: Sinir ağını herhangi bir değerle başlatın.
-
ADIM 2: Oyunu oynarken aşağıdaki döngüyü gerçekleştirin.
-
ADIM 2.a: 0 ile 1 arasında herhangi bir sayı oluşturun.
Üretilen sayı belirli bir e eşiğinden büyükse, o zaman rastgele bir eylem seçilir, aksi takdirde sinir ağı mevcut durum ve her olası eylem kombinasyonu altında çalıştırılır ve en yüksek ödülü alabilecek eylem seçilir.
-
ADIM 2.b: 2.a adımından elde edilen eylemi gerçekleştirin.
-
ADIM 2.c: Ödülü gözlemleyin r.
-
ADIM 2.d: Sinir ağını eğitmek için r ödülünü ve aşağıdaki formülü kullanın.
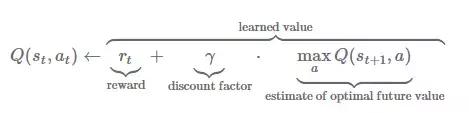
Bu süreç boyunca, bir AI elde edeceğiz.Bu AI'nın sinir ağı, çevrimiçi eğitim yöntemine göre elde edilir, yani sinir ağı, veri mevcut olduğunda hemen eğitilir.
Yıkıcı müdahale ve deneyimin tekrarı
Yukarıda açıklandığı gibi, çevrimiçi eğitim algoritmaları yıkıcı müdahalelere karşı hassastır. Bir sinir ağı, yeni bilgiler öğrenirken öğrendiklerini aniden unutursa, felaketle sonuçlanan bir müdahaleye neden olabilir.
Örneğin oyunda bazen sola doğru yürüdüğünüzde peynir yaşayacaksınız, diğer zamanlarda sola doğru yürürseniz çukura düşeceksiniz. Yıkıcı müdahale, sinir ağının önceden öğrenilenleri unutmasına neden olacak "sola gidip çukura düşecektir". Bu, sinir ağlarının iyi bir oyun çözümü bulmasını zorlaştırır.
Yıkıcı müdahaleyi çözmek için deneyim tekrarı adı verilen bir yöntem kullanıyoruz. Yapay zekaya R boyutunda bir tekrarlama belleği ekliyoruz Her yinelemede, sinir ağını eğitmek için tekrar hafızasından B boyutundaki durum bilgilerini ve eylem bilgilerini rastgele olarak çıkarıyoruz. Bu yöntemi kullanarak, yalnızca belirli bir örnek segmenti kullanmak yerine, sinir ağını eğitmek için sürekli olarak yeni örnek grupları kullanıyoruz. Yıkıcı müdahaleyi çözmek için.
Şimdi Q öğrenme algoritmamız aşağıdaki gibidir:
-
ADIM 1: Sinir ağını herhangi bir değerle başlatın.
-
ADIM 2: Oyunu oynarken aşağıdaki döngüyü gerçekleştirin.
-
ADIM 2.a: 0 ile 1 arasında herhangi bir sayı oluşturun.
Üretilen sayı belirli bir e eşiğinden büyükse, rastgele bir eylem seçin, aksi takdirde sinir ağını mevcut durum ve olası her eylemin kombinasyonu altında çalıştırın ve en yüksek ödülü alabilecek eylemi seçin.
-
ADIM 2.b: 2.a adımından elde edilen eylemi gerçekleştirin.
-
ADIM 2.c: Ödülü gözlemleyin r.
-
ADIM 2.d: Mevcut durumu, eylemi, ödülü ve yeni durumu tekrar oynatma hafızasına ekleyin (hafıza doluysa, en eski bilgilerin üzerine yazın).
-
ADIM 2.e: Tekrarlama belleği tam örnek B boyutunda bir grup ise.
Parti numunesinin her bir örneğinde, hedef q değerini hesaplamak için aşağıdaki formülü kullanın:
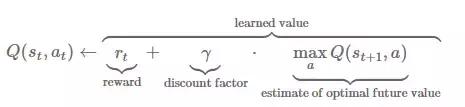
Sinir ağını eğitmek için toplu hedef q değerlerini ve giriş durumunu kullanın.
Sinir ağlarını uygulayan AI
Algoritmayı tanımladıktan sonra, AI oyuncularımızı uygulamaya başlayabiliriz. Oyun, oyuncu nesnesi olarak oyuncu sınıfının örneklerini kullanır. Player sınıfı get_input işlevini uygulamalıdır. Get_input işlevi, oyun döngüsünün her yinelemesinde bir kez çağrılır ve oyuncunun hareket yönünü döndürür.
Bir insan oyuncu sınıfı örneği aşağıda verilmiştir:
need'io / console '
classPlayer
attr_accessor: y,: x
def başlat
@x = 0
@y = 0
son
def get_input
input = STDIN.getch
girdi == 'a' ise
dönüş: sol
elsif girişi == 'd'
dönüş: sağ
elsif girişi == 'w'
dönüş: yukarı
elsif girişi == 's'
dönüş: aşağı
elsif girişi == 'q'
çıkış
son
dönüş: hiçbir şey
son
son
Sinir ağı AI oyuncularıyla ilgili olarak, get_input işlevindeki eylemleri belirlemek için yukarıdaki algoritma taslağını kullanan yeni bir oyuncu sınıfı uygulamalıyız.
İhtiyacımız olan ilk şey, FANN (Hızlı Yapay Sinir Ağı, C dilinde bir sinir ağı uygulaması) için Ruby bağlamalarını içeren Ruby-FANN araç setidir.
Ardından, algoritmanın gerektirdiği oynatıcının niteliklerini ve parametrelerini ayarlayan bir kurucu tanımlarız. Örneğimizde 500'lük bir tekrar belleği ve 400'lük bir grup eğitim örneği kullanılmıştır.
'ruby-fann' gerektirir
classQLearningPlayer
attr_accessor: y,: x,: oyun
def başlat
@x = 0
@y = 0
@actions =
@first_run = doğru
@iscount = 0.9
@epsilon = 0.1
@max_epsilon = 0.9
@epsilon_increase_factor = 800.0
@replay_memory_size = 500
@replay_memory_pointer = 0
@replay_memory =
@replay_batch_size = 400
@runs = 0
@r = Random.new
son
Dinamik e değerini desteklemek için kullanılan parametre ayarlarına dikkat edin. e, algoritmanın 2.a adımının bir eylemi seçmek için kullanılması olasılığıdır. E'nin değeri çok düşükse, o zaman en yüksek ödüllü eylemi seçmek yerine rastgele yüksek olasılığa sahip bir eylem seçeceğiz. E değerinin gerçekleştirilmesi, çok düşük bir değerden başlayarak ve her yinelemede maksimum değere ulaşana kadar artarak dinamik olacaktır.
Ardından, sinir ağını başlatmak için bir işlev ayarlayın. Ağın girdi boyutunu, xy eksenindeki eşleme sayısı artı çalıştırılabilir eylem sayısının toplamı olarak ayarladık. Giriş katmanı ve çıkış düğümü (q değeri) ile aynı sayıda nörona sahip gizli bir katmanımız var. Ek olarak, öğrenme oranını 0.2'ye ayarlayın ve negatif değerleri desteklemek için aktivasyon işlevini sigmoid simetriye değiştirin.
def initialize_q_neural_network
# Kurulum modeli
# Giriş, haritanın boyutu + eylem sayısıdır
# Çıktı boyutu bir
@q_nn_model = RubyFann :: Standard.new (
num_inputs: @ game.map_size_x * @ game.map_size_y + @ actions.length,
hidden_neurons :,
num_outputs: 1)
@ q_nn_model.set_learning_rate (0.2)
@ q_nn_model.set_activation_function_hidden (: sigmoid_symmetric)
@ q_nn_model.set_activation_function_output (: sigmoid_symmetric)
son
Şimdi get_input işlevini uygulama zamanı. AI oyuncusunu takip etmemize ve çalıştırma sayısını izleme özelliğini artırmamıza yardımcı olmak için birkaç milisaniye duraklayın. Ardından, ilk çalıştırma olup olmadığını ve sinir ağının başlatılıp başlatılmadığını kontrol edin (adım 1).
def get_input
# İnsanların takip edebildiğinden emin olmak için durun
# Çalıştırma sayısı ile duraklamayı artırın
uyku0.05 + 0.01 * (@ koşu / 400.0)
@runs + = 1
if @ first_run
# Eğer bu ilk çalıştırılırsa Q-sinir ağını başlatın
initialize_q_neural_network
@first_run = yanlış
Başka
Bu ilk çalıştırma değilse, en son ne olduğunu değerlendirin ve ilgili ödülü hesaplayın (adım 2.c). Oyun puanı artarsa ödül 1'e ayarlanır; oyun puanı düşerse ödül -1'e; hiçbir şey olmazsa ödül -0,1'e ayarlanır. Hiçbir şey olmaması durumunda, algoritmayı doğrudan peyniri yakalamaya teşvik eden olumsuz bir ödül verilir.
# Bu ilk değilse
# Son eylemde ne olduğunu değerlendirin ve ödülü hesaplayın
r = 0 # varsayılan 0'dır
@ game.new_game ve @ old_score eğer! < @oyun skoru
Puanımız yükselirse r = 1 # ödül 1 olur
elsif! @ game.new_gameand @ old_score > @oyun skoru
r = -1 # puanımız düşerse ödül -1 olur
elsif !@game.new_game
r = -0.1
son
Bir sonraki adım, oyunun mevcut durumunu yakalamak ve ödül ve önceki durumla birlikte tekrar oynatma hafızasına koymaktır. Yakalanan durumu sinir ağının giriş vektörü olarak kullanın. Oyuncu konumunda bir vektör 1 ayarlayarak giriş vektörünün mevcut konumunu kodlayın (adım 2.d).
# Mevcut durumu yakala
# Girişi, oyuncu konumunda 1 ile ağ map_size_x * map_size_y + eylem uzunluk vektörüne ayarlayın
input_state = Array.new (@ game.map_size_x * @ game.map_size_y + @ actions.length, 0)
input_state = 1
# Ödül, old_state ve giriş durumunu belleğe ekleyin
@replay_memory = {ödül: r, old_input_state: @old_input_state, input_state: input_state}
# Bellek işaretçisini artırın
@replay_memory_pointer = (@replay_memory_pointer < @replay_memory_size)? @ replay_memory_pointer + 1: 0
Ardından hafızanın dolu olup olmadığını kontrol edin. Doluysa, rastgele bir numune grubunu çıkarın, q değerini hesaplayın ve güncelleyin ve ağı eğitin (adım 2.e).
# Yeniden oynatma hafızası, hafızadaki bir grup durum üzerinde tam tren ağı ise
if@replay_memory.length > @replaymemory_size
# Bellekteki bir eylem grubunu rastgele örnekleyin ve bu eylemlerle ağı eğitin
@batch = @ replay_memory.sample (@replay_batch_size)
training_x_data =
training_y_data =
# Her parti için mevcut ağa ve ödüle bağlı olarak yeni q_value hesaplayın
@ batch.eachdo | m |
# Mevcut durumun tüm q tablo satırını almak için ağı her olası eylem için bir kez çalıştırın
q_table_row =
@ actions.length.timesdo | a |
# Bu eylem için sinir ağı giriş vektörü oluşturun
input_state_action = m.clone
# Giriş vektörünün eylem konumunda 1 ayarlayın
input_state_action = 1
# Bu eylem için ağı çalıştırın ve q tablo satırı girişi alın
q_table_row = @ q_nn_model.run (input_state_action) .ilk
son
# Q değerini güncelleyin
updated_q_value = m + @discount * q_table_row.max
# Eğitim setine ekle
training_x_data.push (m)
training_y_data.push ()
son
# Toplu olarak tren ağı
train = RubyFann :: TrainData.new (: inputs = > training_x_data,: required_outputs = > training_y_data);
@ q_nn_model.train_on_data (tren, 1, 1, 0.01)
son
son
Ağın güncellenmesiyle daha sonra ne yapacağımızı düşünmeye başladık. İlk olarak, ağ giriş vektöründe oyunun mevcut durumunu yakalayın ve ardından algoritmanın mevcut çalışmasına göre e değerini hesaplayın. Daha yüksek bir e değeri, en yüksek ödüle sahip eylemlerin rastgele eylemler yerine daha yüksek olasılıkla seçildiği anlamına gelir.
Ardından, rastgele bir eylem seçin veya mevcut S durumunda bir sinir ağı çalıştırın, her eylem A'yı yürütün ve ağ çıktısına göre hangi eylemin gerçekleştirileceğine karar verin.
# Mevcut durumu ve puanı yakalayın
# Girişi, oyuncu konumunda 1 ile ağ map_size_x * map_size_y vektörüne ayarlayın
input_state = Array.new (@ game.map_size_x * @ game.map_size_y + @ actions.length, 0)
input_state = 1
# Durum için Q değeri tahminlerine dayalı eylem seçin
# Rastgele bir sayı epsilon'dan yüksekse, rastgele
# Koşuya bağlı olarak @ epsilon'u yavaşça maksimum @ max_epsilon'a yükselteceğiz - bu, erken keşfi teşvik eder
epsilon_run_factor = (@ çalıştırmalar / @ epsilon_increase_factor) > (@ max_epsilon- @ epsilon)? (@ max_epsilon- @ epsilon): (@ çalışır / @ epsilon_increase_factor)
if@r.rand > (@epsilon + epsilon_run_factor)
# Rastgele eylem seçin
@action_taken_index = @ r.rand (@ actions.length)
Başka
# Mevcut durumun tüm q tablo satırını almak için ağı her olası eylem için bir kez çalıştırın
q_table_row =
@ actions.length.timesdo | a |
# Bu eylem için sinir ağı giriş vektörü oluşturun
input_state_action = input_state.clone
# Giriş vektörünün eylem konumunda 1 ayarlayın
input_state_action = 1
# Bu eylem için ağı çalıştırın ve q tablo satırı girişi alın
q_table_row = @ q_nn_model.run (input_state_action) .ilk
son
# Olası en yüksek ödüllü eylemi seçin
@action_taken_index = q_table_row.each_with_index.max
son
Son olarak, geçerli puanı eski puan değişkeninde saklayın, mevcut durumu eski durum değişkeninde saklayın ve oyunun gerçekleştirebileceği eylemleri geri getirin (adım 2.b).
# Mevcut durumu, puanı ve q tablo satırını kaydedin
@old_score = @ game.score
# Kaydetmeden önce giriş durumunda gerçekleştirilen eylemi ayarlayın
input_state = 1
@old_input_state = input_state
# Harekete geç
dönüş @ eylemler
son
Kombinasyon kodunun tamamı burada bulunabilir:
https://github.com/daugaard/q-learning-simple-game/blob/55748d5e821b34a531dba4d9c4b2683038db6b3d/q_learning_player.rb.
AI oynasın
Kodu eğitimli AI ile çalıştırın ve nasıl çalıştığını görün.
İlk başta yapay zekanın etrafta dolaştığını görebiliriz. Bunun nedeni dinamik e değeridir. Tekrar hafızası dolana kadar sinir ağını eğitmeye başlamayacağız. Bu, başlangıçta gerçekleştirilen tüm eylemlerin rastgele olduğu anlamına gelir. Ancak 1. turun ve 2. turun sonunda yapay zekanın düdene düşmekten kaçınmayı ve doğrudan peynire gitmeyi öğrendiğini göreceksiniz.
Daha genel bir yaklaşım
Bu makale, basit bir oyunu oynamak için simetrik bir s-şekilli aktivatör ile bir sinir ağının nasıl eğitileceğini göstermektedir. Yöntem, sinir ağının giriş vektörü olarak oyun durumunu ve eylemi kodlamak ve aynı zamanda ödülün belirli bir ölçümünü sinir ağı olarak kullanmaktır. Ağın çıktısı. Bu çözüm, bir ağ kurmak için oyun hakkında bilgi sahibi olmayı gerektirir ve tabii ki bu, daha genel bir yapay zeka oluşturmamız için bir sınırlamadır.
Daha genel bir yöntem, giriş olarak kodlanmış oyun durumunu, oyunu işlemek için kullanılan RBG değeriyle değiştirmektir. DeepMind'den araştırmacılar, bu yöntemi "Derin Pekiştirmeli Öğrenme ile Atari Oyunları Oynamak" başlıklı makalede ayrıntılı olarak tartıştılar. Onlar başarılı bir şekilde Q öğrenmeyi eğitti ve Space Invaders, Pong, Q Bert ve diğer Atari 2600 oyunlarını oynamak için bir sinir ağı Q masası kullandılar.
Orijinal bağlantı:
https://www.practicalai.io/teaching-a-neural-network-to-play-a-game-with-q-learning/
Editör: Huang Jiyan
Redaksiyon: Tan Jiayao

Yang Jinhong , Beijing Escort Technology Co., Ltd.'nin bir çalışanı, boş zamanlarında bazı teknik belgeleri tercüme etmeyi seviyor. Veri madenciliği ve veritabanları hakkında kitaplar okumayı, java programlamayı öğrenmeyi vb. Seviyorum. Veri pastası platformunda aynı hobilere sahip daha fazla ortakla tanışmayı umuyorum, böylece daha ileri gidebilir ve veri bilimi yolunda daha uzağa gidebilirim. .