Kazanmak ya da kaybetmek için değil! Ke Jie VS AlphaGo dövüşmeden önce, birkaç şeyi bilmeniz gerekir

Lei Feng.com: AlphaGo nihayet tekrar burada. Geçtiğimiz yıl "yapay zeka" dalgasını yeni bir seviyeye taşıyan Go yapay zekası AlphaGo yarın 23 Mayıs'ta bir kez daha ortaya çıkacak. Bu beş günlük etkinlikte AlphaGo, dünyanın en iyi Go oyuncusu Ke Jie ile resmi bir düello yapmanın yanı sıra canlandırıcı bir "eşleştirme maçı" ve "takım maçı" yapacak.

Leifeng.com tarafından öğrenilen özel program aşağıdaki gibidir:
23 Mayıs'ta açılış seremonisi, üçlünün ilk maçı olan Ke Jie - AlphaGo;
24 Mayıs, Yapay Zeka Forumu;
25 Mayıs'ta Ke Jie'ye karşı AlphaGo'nun üçlü oyun;
26 Mayıs'ta çöpçatanlık, takım yarışması (karşılıklı satranç);
27 Mayıs'ta Ke Jie, AlphaGo'nun üçüncü üçlü oyununa karşı.
Bu yarışmanın temel amacı, AlphaGo'nun Go'daki tüm insanları geride bırakan bir "AI" yaratıp yaratmadığını görmek için halka açık olarak gücünü doğrulamaktır.
Çin'deki en önemli teknoloji medyası olan Leifeng.com da etkinliği boyunca takip edecek. Ancak oyun resmi olarak başlamadan önce bilmeniz gereken birkaç soru var:
1. Bu sefer "Yeni AlphaGo" ile "Eski AlphaGo" arasındaki fark nedir?
2. Ke Jie "Yeni AlphaGo" yu yenebilir mi?
3. Maçla ilgili canlı yayın nasıl izlenir?
Yeni AlphaGo: "İnsan esaretini" ortadan kaldırın

AlphaGo, 2014'ten günümüze geliştirilen bir Go yapay zeka projesi olarak aslında geliştirilmesinde en eski Yicheng Go'da "DeepMind" veya daha önce Yehu platformunda "Master" gibi birçok isim kullandı. Yani bu "yeni AlphaGo" sadece yeni bir isim mi?
Cevap hayır olmalı Yeni isim muhtemelen gizlilik ve kişisel tercih gibi nedenlerden kaynaklanıyordu, ancak bu sefer yeni eklenen "yeni" kelime sadece bir noktayı vurgulamak içindir - bu AlphaGo'nun "makinenin kendi kendine öğrenmesine" odaklanan bir sürümüdür.

Bu yargıya dair ipucu, Usta'nın bu yılın başında İnternet üzerinden 60 insan satranç oyuncusunu taramasından geliyor. Usta, Ke Jie'yi ikinci kez yendikten sonra, Nie Weiping bir keresinde şöyle dedi:
Usta, geleneksel kalınlık kavramımızı değiştirdi ve yıllarca kalıpları altüst etti. Git düşündüğümüz kadar basit olmaktan çok uzak. Biz insanların kazmasını bekleyen devasa bir alan var. İster Alphago ister Usta olsun, bunların hepsi insanlara yol göstermesi için 'Go God' tarafından gönderildi.
Ünlü satranç oyuncusu Coulee, mağlup olan 60. Usta oyuncuydu ve bundan sonra Weibo ile ilgili duygularını da dile getirdi:
60. savaşçı olarak feda edildi. . . Birkaç gün oyun oynadıktan sonra Go'nun gizemini derinden hissediyorum, Usta bize gizemli bir kapı açmış gibi görünüyor.Zafer ya da yenilgi ne olursa olsun, Go dünyasını keşfeden insanların ve yapay zekanın perdesi açılmak üzere. Bir Go devrimi sürüyor. . .
Bu performans, yaklaşık bir yıl önceki "eski AlphaGo" dan oldukça farklı. Böyle bir sonuca ulaşmanın tek bir yolu var - DeepMind Go'daki "insan esaretinden" kurtulmak için bir mekanizma buldu.
Gizemli gelişme: AlphaGo bir hamlede insan öğretmeni olur

Son derece özel bir satranç oyunu ve görevi olarak Go'nun çok sayıda olasılığı vardır.Toplam konum sayısı 10 ^ 172'ye ulaşırken, gözlemlenebilir evrendeki atom sayısı yalnızca 10 ^ 80'dir. Bu aynı zamanda tükenmenin kesinlikle akıllıca bir yol olmadığı anlamına gelir.
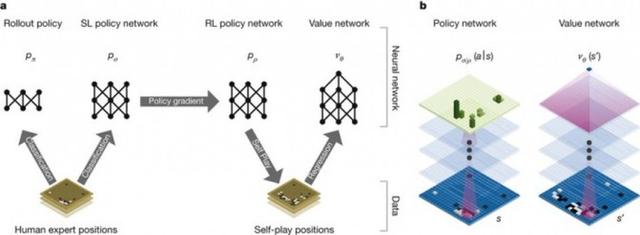
Sonunda, DeepMind en iyi insan ustalarını "simüle edebilecek" bir dizi çözüm sundu: derin öğrenme + Monte Carlo arama ağacı + kendi kendine evrim.
Bu mimari seti, DeepMind tarafından Nature dergisinde yayınlanan bir makalede ayrıntılı olarak açıklanmıştır.
(Https://www.nature.com/nature/journal/v529/n7587/full/nature16961.html)
Ayrıntılarla ilgileniyorsanız, yerli bir yapay zeka girişim şirketi olan Caiyun AI'nın kurucusu ve CEO'su Zhihu'daki ilgili cevabı okumanız tavsiye edilir.
(Https://www.zhihu.com/question/41176911/answer/90118097)
İnsan satranç tahtasını analiz etmek için derin öğrenme, iş yükünü azaltmak için Monte Carlo arama ağacı ve yeteneği geliştirmek için kendi kendine evrim kullanılır. Ancak sınırlı hesaplama gücü DeepMind için hala büyük bir sorun teşkil ediyor. Sonunda, sonunda bir yol buldu: Monte Carlo arama ağacı işlemlerini öğrenilmiş insan satrancı hareketlerinde gerçekleştirmek, tıpkı sabit formüllere güvenen bir insan satranç oyuncusu gibi.
Jingshi olarak da bilinen Jingshi, Go oynarken insanlar tarafından biriktirilen uzun vadeli bir deneyimi ifade eder. Oyundaki her iki oyuncu da belirli koşullar altında sabit bir oyunu takip edecektir. Ünlü satranç oyuncusu Wu Qingyuan bunu basitçe "taşlar köşede birbirine değdiğinde en makul hareket" olarak tanımladı.
Bu stiller, çeşitli satranç kayıtlarında kaydedilir ve yeni başlayanlar için mutlaka okunması gereken bir kitap haline gelir.
Duruş bir anlamda en makul yol olsa da idealize edilmiş koşulların bir ürünüdür Duruşu tam anlamıyla yeniden üretmek için her iki tarafın da aynı idealleştirilmiş düşünceye sahip olması gerekir. Tarihte, itaatsizlik veya rakipleri yenileriyle yenme örnekleri konusunda hiçbir eksiklik yoktur.
Soru şu ki, sürekli değişen Go oyununun sabit formülleri neden var? Jose'ye sadık kalırsan kaybedeceksin, jose'yi öğrenmezsen kaybedeceksin. Tek bir cevap var - insanların Go'daki değişiklikleri azaltması gerekiyor, böylece orta oyuna girdikten sonra insanlar oyunun yönünü kavramak için kendi yeteneklerini kullanabilirler.
Tesadüfen, bu sefer karşılaştığımız şey, insanoğlunun çok ötesinde bir hesaplama gücüne sahip bir bilgisayardı ve bu da Go'nun tüm gizemlerine daha fazla ve hatta hükmetmeyi mümkün kıldı.
Ama yeni AlphaGo "insan esaretinden" nasıl kurtulacak? Önceki "eski AlphaGo" çalışma yöntemine atıfta bulunarak, hesaplama sürecindeki tüm insan unsurlarını hariç tutmak en kapsamlı yöntem olabilir. Ancak bu şekilde, hesaplama baskısını azaltmak için başka bir strateji bulmalıyız. Şu anda, bu sır yalnızca daha sonra DeepMind tarafından açıklanabilir.
İnsanlığın yenilgisi belirlendi mi?

İnsan temsilcisi geçen yıl Güney Koreli oyuncular olsa da, seçici bir göze sahip olan herkes şu anki ve geçen yıl Go insan-makine oyunlarının popülaritesindeki farkı görebilir. Bu aynı zamanda çoğu izleyicinin görüşlerini başka bir açıdan yansıtıyor: bu sefer insanlar kaybedecek. Geçen yıl Mart ayında Li Shijia 1: 3 oranında geri çekildiğinde, Ke Jie canlı yayında şunları söyledi:
AlphaGo'nun gerçekten mükemmel olduğunu kabul etmeliyiz, ancak yenilmez değildir.

Geçen ay yapılan basın toplantısında Ke Jie özellikle alçakgönüllüydü:
Biraz gerginim, ama kolayca kaybetmeyeceğim.Alpha Go ortaya çıkmadan önce, bilgi işlem gücünün AI'nın avantajı olduğunu düşünmüştüm. Daha sonra beni şok eden şey genel görüşüydü. AI'nın makro düşüncesi beni hayran bıraktı. AlphaGo bunun yanlış olup olmadığını yeniden düşünmemizi sağlıyor. Bize çok ilham verecek. Kaybetmenin acısı dış dünyanın hayal gücünün ötesinde. Ne pahasına olursa olsun zafer peşinde koşacağım.
"Başarısızlık kolay" ifadesi, CCTV konusundaki tutkusuyla tam bir tezat oluşturuyor. Objektif ve adil olmak gerekirse, Ke Jie'nin kazanma şansı çok düşük ve satrancın kazanabileceği üç turdan biri bile başarılı.
Diğer iki oyun (eşleştirme oyunu, takım oyunu) da ciddi dikkat çekicidir.Bu iki oyunda insan oyuncular önce AlphaGo ve ardından "grup dövüşü" AlphaGo ile eşleşecekler. Bu yalnızca DeepMind'in güvenini yansıtmakla kalmaz, aynı zamanda bu Go zirvesinin temasını da vurgular:
En iyi satranç oyuncuları, insan bilgeliğinin sınırlarına meydan okumak için öncü bir şekilde dünyaya harika satranç becerileri getiriyor. Aynı zamanda, AlphaGo ve dünyanın en iyi satranç oyuncuları birbirlerine ilham veriyor ve Go'nun ardındaki derin gizemleri birlikte keşfediyor.
Başka bir deyişle, insanlar ve makineler arasında kimin kazandığı ve kimin kazandığı konusunda endişelenmeyi bırakın, acele edin ve teknolojinin getirdiği muazzam değişiklikleri hissedin ve geleceği önceden görün!