Dekoder performans darboğazını nasıl aşabilirim? FasterTransformer ilkesinin ve uygulamasının aydınlatılması
İçbükey tapınaktan biraz Qubit Raporu | Genel Hesap QbitAI
9 Nisan'da Nvidia x Qubit bir nlp çevrimiçi kursunu paylaştı.NVIDIA'dan bir GPU bilgi işlem uzmanı ve FasterTransformer 2.0'ın geliştiricilerinden biri olan Xue Boyang, yüzlerce geliştiriciyle görüştü:
- FasterTransformer 2.0 yeni özellik tanıtımı
- Kod Çözücü ve Kod Çözme için optimize etme
- Kod Çözücü ve Kod Çözme Nasıl Kullanılır
- Kod Çözücü ve Kod Çözme nasıl bir hızlandırma etkisi sağlayabilir?
Okuyucuların isteği üzerine, paylaşılan içeriği düzenleyip herkesle birlikte öğreneceğiz. Makalenin sonunda, bu canlı yayına ve doğrudan izleyebileceğiniz PPT'ye bağlantılar var.
Bu paylaşımın içeriği aşağıdadır:
Herkese merhaba, bugün sizlerle tanıştıracağım FasterTransformer 2.0 ilkesi ve uygulaması .
FasterTransformer nedir?
Öncelikle bu canlı yayına katılan arkadaşların belirli bir Transformer mimarisi anlayışına sahip olması gerekir. Bu mimari, "Tek İhtiyacınız Olan Dikkat" başlıklı makalede önerilmiştir. BERT Encoder'da çok sayıda Transformatör kullanılır ve etkisi çok iyidir. Bu nedenle Transformer, NLP alanında çok popüler bir derin öğrenme ağ mimarisi haline geldi.
Ancak, Transformatör hesaplamaları genellikle çok büyüktür. Bu nedenle, Transformatörün gecikmesi, pratik uygulamaların ihtiyaçlarını karşılamak için genellikle zordur.

Tek İhtiyacınız Olan Dikkat, ekran görüntüsü
Transformatör mimarisi, Kodlayıcıya veya Kod Çözücüye uygulanabilir. Kodlayıcıda, Transformatör 1 çok başlı dikkat ve 1 ileri beslemeli ağ içerir, Dekoderde 2 çok başlı dikkat ve 1 ileri beslemeli ağ içerir.
Bunların arasında, saf Encoder mimarisi, QA sistemleri, reklam öneri sistemleri vb. Gibi birçok mevcut uygulamada iyi bir performansa sahiptir. Bu nedenle, Encoder için optimizasyon çok gereklidir.
Çeviri senaryoları gibi bazı senaryolarda Encoder ve Decoder mimarilerine ihtiyacımız var. Bu mimari altında, kod çözücü tarafından tüketilen zaman oranı çok yüksektir ve bu, akıl yürütmenin ana darboğazı olan% 90'dan fazlasına ulaşabilir. Bu nedenle, kod çözücünün optimizasyonu da önemli bir çalışmadır ve bariz hızlanma etkileri sağlayabilir.
Pratik uygulamalarda, FasterTransformer 1.0 sürümü, BERT'deki Kodlayıcı için birçok optimizasyon ve hızlandırma yapmıştır. Sürüm 2.0'da, Dekoder için optimizasyonlar esas olarak eklenmiştir ve üstün performansı, çeviri, diyalog robotları, metin tamamlama ve düzeltme gibi çeşitli üretken senaryolara yardımcı olacaktır.

Yukarıdaki tablo Kodlayıcı ve Kod Çözücünün hesaplama miktarını karşılaştırmaktadır. Bir cümleyi kodlamamız ve kodunu çözmemiz gerektiğinde, Kodlayıcı aynı anda birçok kelimeyi kodlayabilir, hatta bir cümleyi doğrudan kodlayabilir.
Ancak Kod Çözücü bir kod çözme işlemidir ve bir seferde yalnızca bir sözcük çözülebilir.Bu nedenle, bir cümleyi çözerken GPU için daha da dostça olmayan çoklu Kod Çözücüye ihtiyacımız var.

Daha hızlı Transformer çerçevesi
Yukarıdaki şekil FasterTransformer'da BERT için optimize edilmiş modülleri listelemektedir. Kodlama açısından, BERT bazlı, kullanıcıların arayabilmesi için BERT Transformer'a eşdeğer tek katmanlı bir modül sağlanmıştır. Çok katmanlı bir Transformer'a ihtiyacımız olduğunda, Encoder'ı yalnızca birkaç kez çağırmamız gerekir.
Kod çözme daha karmaşıktır. Esneklik ve verimliliği dengelemek için farklı boyutlarda ve efektlerde iki modül sunuyoruz:
Kod çözücü (sarı blok), iki dikkat ve bir ileri besleme ağı içeren tek katmanlı bir Transformer katmanından oluşur; ve Kod Çözme (mavi blok), Transformer katmanının birden çok katmanını içermenin yanı sıra, diğer işlevleri de içerir. embedding_lookup, ışın araması, pozisyon Kodlama vb.

Kod Çözücü ve Kod Çözme arasındaki farkı göstermek için basit bir sahte kod kullanıyoruz.
Kod çözmede, genellikle iki sonlandırma koşulu vardır; bunlardan biri, maksimum dizi uzunluğuna önceden ulaşılıp ulaşılmadığı ve ikinci koşul, tüm cümlelerin çevrilip çevrilmediğidir ve döngü sonlandırılmadığında devam edecektir.
Örnek olarak cümle uzunluğu 128 olan bir cümle çeviri senaryosunu ele alalım.Kod Çözücü 6 Katman Transformatör katmanından oluşuyorsa, toplam 128x6 = 768 Kod Çözücünün çağrılması gerekir; Kod Çözme kullanılıyorsa, Kod Çözme yalnızca bir kez çağrılmalıdır, bu nedenle Muhakeme verimliliği daha yüksektir.
özet

Her şeyden önce, FasterTransformer son derece optimize edilmiş bir Transformer katmanı sağlar: Encoder için BERT'ye dayanır; Kod Çözücü için standart olarak OpenNMT-TensorFlow açık kaynak kitaplığına dayanır; Kod çözme, tüm çeviri sürecini içerir ve ayrıca OpenNMT-TensorFlow'a dayanır.
İkinci olarak, FasterTransformer 2.0'ın alt katmanı CUDA ve cuBLAS tarafından uygulanır, FP16 ve FP32 iki hesaplama modunu destekler ve şu anda C ++ API ve TF OP sağlar.
Şimdi, FasterTransformer 2.0 açık kaynak kodludur. Tüm kaynak kodunu ana sayfadaki DeepLearningExamples / FasterTransformer / v2'den alabilirsiniz · NVIDIA / DeepLearningExamples · GitHub.
Nasıl optimize edilir?
Encoder'ı örnek olarak alalım.

TF Encoder Transformer katmanı
Parametreler: XLA yok, parti boyutu 1, 12 kafa, kafa başına boyut 64, FP 32
Şekildeki mavi kare, GPU'nun gerçekten çalıştığını gösterir ve boşluk, GPU'nun boşta olduğunu, dolayısıyla GPU'nun birçok kez boşta olduğunu gösterir. GPU'nun boşta olmasının nedeni, çekirdeklerin çok küçük olması ve CPU'nun çekirdeği başlatması için GPU'nun sürekli olarak boşta kalması gerektiğidir.Bu aynı zamanda çekirdek başlatmaya bağlı sorun olarak da adlandırılır.
bu problem nasıl çözülür?

TF'nin XLA'sını açmaya çalışıyoruz, diğer parametreler değişmeden kalıyor. Şekilde, bir Transformer katman katmanının orijinal hesaplamasından 50 çekirdeğin yaklaşık 24'e indirilmesi gerektiğini görebiliriz. Çekirdeğin çoğu, hızlanma olmasına rağmen genişler, ancak boşta kalma süresi daha da fazladır.

Bu nedenle, Encoder için optimize etmek üzere FasterTransformer'ı öneriyoruz.
Öncelikle matris hesaplama bölümünü seçiyoruz ve hesaplamak için NVIDIA'nın son derece optimize edilmiş kütüphane cuBLAS'ını kullanıyoruz, diğer kısım için ise mümkün olduğunca entegre edilebilen çekirdekleri entegre ediyoruz.
Nihai sonuç, yukarıdaki şeklin sağ tarafında gösterildiği gibidir Genel optimizasyondan sonra, tek katmanlı Transformer katmanı hesaplamasını tamamlamak için yalnızca 8 matris hesaplamasına ve 6 çekirdeğe ihtiyacımız var, bu da gerekli çekirdeklerin 24'ten 14'e düşürülmesi anlamına geliyor.

Optimizasyondan sonra her çekirdeğin nispeten büyük olduğunu ve küçük bir zaman oranına sahip çekirdeğin de küçüldüğünü görebiliriz. Ancak hala çok sayıda boş parça var.

Doğrudan C ++ API diyoruz, şekilde gösterildiği gibi, GPU boşta kalma süresi neredeyse bitti. Bu nedenle, küçük bir parti boyutu olması durumunda, daha hızlı hız için C ++ API'yi kullanmanızı öneririz. Parti boyutu nispeten büyük olduğunda, GPU boşta kalma süresi daha az olacaktır.
Sonra Dekodere bakıyoruz.

Parametreler: XLA yok, parti boyutu 1, 8 kafa, kafa başına boyut 64, FP32
İstatistiklere göre, TF'nin bir Transformer katmanını hesaplamak için yaklaşık 70 çekirdek kullanması gerekiyor. Sezgisel olarak, çok küçük ve çok kısa zaman oranına sahip daha fazla çekirdek vardır. Bu nedenle, parti boyutu nispeten küçük olduğunda, optimizasyon etkisi daha belirgin olacaktır.
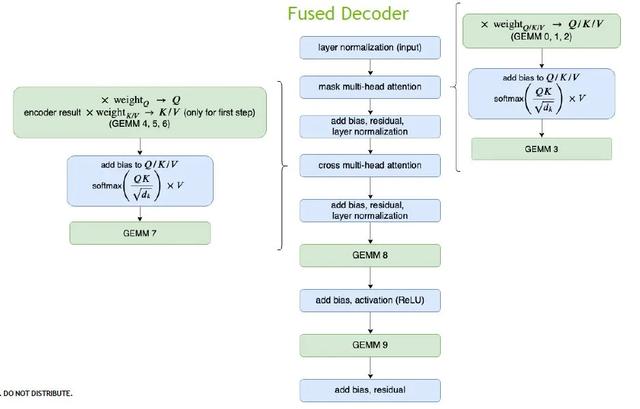
Dekoderin optimizasyonu, yukarıdaki Kodlayıcı ile aynıdır Özel özellik, Dekoderdeki matris hesaplama miktarının çok küçük olmasıdır, bu nedenle tüm çok kafalı dikkati tamamlamak için bir çekirdek kullanırız. Optimizasyondan sonra, başlangıçta tamamlanması için 70 çekirdek gerektiren hesaplama yalnızca 16 çekirdek ile tamamlanabilir.

Daha büyük Kod Çözme modülünde, daha fazla zamana neden olan diğer çekirdek ışın aramasıdır Burada en iyi k için optimize ediyoruz. GPU'da, birden fazla blok ve birden fazla çözgü aynı anda yürütülebilir, paralel işlemler büyük ölçüde zamandan tasarruf sağlar.

Daha optimize edilmiş ayrıntılar
FasterTransformer nasıl kullanılır?
İlgili bilgileri ana sayfadaki DeepLearningExamples / FasterTransformer / v2'de bulabilirsiniz · NVIDIA / DeepLearningExamples · GitHub kök dizini:



Kod Çözücü ve Kod Çözme için FasterTransformer, sırasıyla C ++ ve TensorFlow OP sağlar.
C ++ arayüzü
Önce bir Eecoder oluşturun, hiperparametreler şekilde gösterilir:

İkinci olarak, eğitilen modelin ağırlığını ayarlayın;
Ayarladıktan sonra, doğrudan yönlendirmeyi aramanız yeterlidir.
TF OP arayüzü
İlk önce OP'yi yüklememiz gerekiyor. Örnek olarak Kod Çözücüyü ele alırsak, TF'nin ihtiyaç duyduğu kitaplık otomatik olarak oluşturulur ve .so dosyası (şekilde kırmızıyla işaretlenmiş) arabirim çağrılırken ilk önce içe aktarılır:

Ardından Dekoderi çağırın, girdi, ağırlık ve hiperparametreleri girin ve ardından Oturumu dışarı atmak için çalıştırın.
Burada, parametrede sözde bir girdi olduğuna dikkat edilmelidir. Bu giriş, TensorFlow kod çözücünün ve Daha Hızlı Dönüştürücü Kod Çözücünün paralelleştirilmesini önlemek içindir, çünkü kod çözücüdeki belleğin paralel olarak çalıştırıldığında bozulabileceğini bulduk. Bu girdi, gerçek uygulamada kaldırılabilir.
Optimizasyon etkisi
Son olarak, optimizasyonun etkisine bir göz atalım. İlk önce ortam ayarlarını test edin:

Kullanılan GPU, NVIDIA'nın Tesla T4 ve V100'idir.
Tesla V100'deki Kodlayıcı modülünün sonuçları
Hiper parametre ayarı: FP 16 altında 12 katman, 32 sıra uzunluğu, 12 kafa, kafa başına 64 boyut (BERT tabanı)

Sonuç, yukarıdaki şekilde gösterildiği gibidir .. Parti boyutunu kademeli olarak 100'den 500'e çıkarma sürecinde, FasterTransformer TF'ye kıyasla ve XLA'yı açarak yaklaşık 1,4 kat hızlanma sağlayabilir.
Tesla T4'te Kod Çözücü ve Kod Çözme modüllerinin sonuçları
Hiper parametre ayarları: Parti boyutu 1, ışın genişliği 4, 8 kafa, kafa başına 64 boyut, 6 katman, kelime boyutu 30000, FP 32

Sonuç, yukarıdaki şekilde gösterildiği gibidir.TF ile karşılaştırıldığında, FasterTransformer Decoder, farklı dizi uzunlukları altında yaklaşık 3.4 kat hızlanma etkisi sağlayabilir ve Kod Çözme, daha verimli olan 7-8 kat ivme sağlayabilir.
Hiper parametre ayarları: Parti boyutu 256, sıra uzunluğu 32, ışın genişliği 4, 8 kafa, kafa başına 64 boyut, 6 katman, kelime boyutu 30000

Sonuç, yukarıdaki şekilde gösterildiği gibidir. Parti boyutu daha yüksek bir değere sabitlendiğinde, Daha Hızlı Dönüştürücü Kod Çözücü ve Kod Çözme, farklı FP'ler altında belirli hızlandırma etkileri de getirir.
Son olarak, bu canlı yayının PPT'si şu bağlantıyı alır: "Bağlantı"
Bu canlı yayının kayıttan yürütülmesi: NVIDIA Webinar