Jeff Dean, Google Brain'in geleneksel veritabanı tasarım konseptini değiştirecek olan veri indeksleme yöntemini yıkmak için makine öğrenimini kullanmasına öncülük ediyor

Leifeng.com Yapay Zeka Teknolojisi Yorumu: Makine öğrenimi teorisi ve teknolojisinin ve bir disiplin olarak makine öğreniminin gelişmesiyle birlikte, gittikçe daha fazla insan buna dikkat ediyor ve katılıyor ve makine öğreniminin uygulama senaryoları da artıyor. çeşitlendirme. Geçtiğimiz iki yılın popüler uygulamaları herkese çok tanıdık geliyor.Go oynamak için derin sinir ağı + pekiştirmeli öğrenme kullanan AlphaGo ve konuşma üretimi için derin sinir ağını kullanan WaveNet, uzun süredir geleneksel yöntemlerle çalışılıyor, ancak bir ilerleme yok. Tanrıların şaşırtıcı etkisini elde etmek için yeni fikirler ve yeni araçlar kullanarak sahada derin öğrenmeye giriş ve küçük bir yinelemeli güncellemeden sonra daha mükemmel olacak.
Son zamanlarda, Google Brain ayrıca makine öğrenimini belirli kurallara ve algoritmalara dayalı olarak geleneksel veritabanı sistemlerine uygulamaya çalışan yeni bir devrim niteliğinde makale yayınladı ve aynı zamanda iyi ön sonuçlar elde etti: gerçek verileri indeksleme görevi. , Sinir ağı tarafından oluşturulan dizin, geleneksel önbellek için optimize edilmiş B-ağaç dizini yönteminden% 70 daha hızlı olabilir ve depolama alanı, büyüklük sırasına göre kaydedilebilir. Jeff Dean dahil yazarlar da veri tabanı sisteminde daha farklı görevler üstlenmek için sinir ağlarının nasıl kullanılacağını tartıştılar ve denediler.Bunun, geleceği etkileyebilecek yeni ve çok potansiyel bir araştırma ve uygulama yönü olduğunu düşünüyorlar. Veritabanı sisteminin tasarım konsepti. Leifeng.com AI Technology Review, "Öğrenilmiş Dizin Yapıları Örneği" makalesinin bir bölümünü aşağıdaki gibi tanıtmaktadır.

Verilere erişerek başlayın
Bilgisayar sistemleri için, verilere verimli erişim ihtiyacı olduğu sürece, bir indeks yapısı oluşturulabilir. İndeksleme fikri şimdiye kadar gelişti ve çeşitli farklı erişim modlarını ele almak için çeşitli yöntemler var. Örneğin, menzil erişimi için (belirli bir süre içinde tüm kayıtları okumak gibi), B-ağacı en iyi seçimdir; anahtar tabanlı sorgu görevleri için, karma tablo yönteminin performansı çok iyidir; ve kayıtları sorgulamak istiyorsanız Var olsun, Bloom Filtresi çoğu zaman seçimdir. Dizinler veritabanı sistemlerinde ve diğer uygulamalarda çok önemli bir rol oynadığından, son on yılda çeşitli indeksleme yöntemleri sürekli olarak güncellenip geliştirildi ve çeşitli yeni yöntemler giderek daha fazla bellek, önbellek ve CPU kaynağı kullandı. Verimli.
Bununla birlikte, tüm mevcut indeksleme yöntemleri hala genel amaçlı veri yapılarıdır.Tüm bunlar, genellikle gerçek verilere yansıyan dağıtım özelliklerinden yararlanmak yerine, verilerin en kötü şekilde dağıtıldığını varsayar. Örneğin, hedef sabit uzunlukta, sürekli tam sayıların (1 ila 100 milyon gibi) anahtar değerlerinin depolanması ve sorgulanması için son derece özelleştirilmiş bir sistem oluşturmaksa, anahtar değerler için geleneksel B ağaçlarını kullanın. Dizin oluşturma iyi bir yöntem değildir, çünkü anahtar değerinin kendisi bir ofset olarak kabul edilebilir. Herhangi bir anahtar değeri bulma veya bir anahtar değer aralığının başlangıç konumunu bulma görevi için zaman karmaşıklığı bunun yerine O (log n) O (1) 'e geliştirildi; Benzer şekilde, anahtar değerinin kendisi bir ofset olarak kabul edilirse, indeks tarafından kullanılan bellek boyutu da O (n)' den O (1) 'e düşürülebilir. Diğer veri dağıtım modlarının da kendi uygun optimizasyon yöntemlerini bulabilmesi biraz şaşırtıcı olabilir. Başka bir deyişle, verilerin tam dağılımını biliyorsanız, veritabanı şu anda ne tür bir indeksleme yöntemi kullanıyor olursa olsun, neredeyse daha fazla optimize edilebilir.
Elbette çoğu gerçek uygulama senaryosundaki veriler, bilinen bir veri dağıtımıyla tam olarak eşleşmeyebilir ve her kullanım durumu için özel bir çözüm oluşturulursa, yatırım için gereken maliyet çok yüksektir. Ancak, bu makalenin yazarları (o sırada Google'ı ziyaret eden Jeff Dean ve bir MIT akademisyeni dahil dört Google araştırmacısı) makine öğreniminin artık yepyeni bir fırsat getirdiğini ve öğrendiği modelin verileri yansıtabileceğine inanıyor. İç bağlantılar ve dağıtım modelleri. Bu temelde, yazarların dediği özel bir dizin yapısını otomatik olarak oluşturabilir. "Öğrenilmiş dizinler" Ve mühendislik maliyeti de daha düşük.
"Öğrenilmiş dizin" mümkündür ve mevcuttur
Bu makalede yazarlar, makine öğrenimi ile öğrenilen modellerin (sinir ağları dahil) B-ağaçları ve Bloom Filtreleri gibi geleneksel indeks yapılarının yerini almak için kullanılıp kullanılamayacağını araştırdılar. Bu biraz sezgisel olabilir, çünkü geleneksel indeksleme yöntemleri genellikle kesin anlamsal garantiler gerektirir ve makine öğrenimi bunu genellikle sağlayamaz; Buna ek olarak, sinir ağları en güçlü makine öğrenimi modeli türü olmasına rağmen, insanlar da geleneksel olarak Etkilerini değerlendirmek için gereken maliyetin çok yüksek olduğunu düşünün. Ancak yazarlar, bu bariz zorlukların pratikte göründükleri kadar ciddi olmadığına ve tam tersine, yazarlar tarafından önerilen öğrenme modellerinin yönteminin, özellikle büyük ölçekli matris işlemlerinin tasarımında bariz faydalar sağlama potansiyeline sahip olduğuna dikkat çekti. Yeni nesil donanımda.
Spesifik olarak, anlamsal koruma açısından, modern indeksleme yöntemleri zaten büyük ölçüde öğrenilmiş modellerdir.Bu durumda, mevcut modelleri yenileriyle değiştirmek aslında çok basit ve doğrudan bir şeydir. Aynı şey, onu bir sinir ağıyla değiştirmek de dahil. Örneğin, bir B-ağaç indeksi bir model olarak kabul edilebilir: girdi olarak bir anahtar değeri alır ve ardından karşılık gelen veri kaydının konumunu tahmin eder; Bloom Filtresi, bir anahtar değer verildiğinde ikili bir sınıflandırıcı olarak kabul edilebilir, Bu anahtar değerinin var olup olmadığını tahmin edin. Tabii ki, bazı ince ama çok önemli farklılıklar var.Örneğin, mevcut Bloom Filtresi yanlış pozitiflere sahip olabilir, ancak yanlış pozitifler olmayacak. Bununla birlikte, bu makale daha sonra yeni öğrenme teknikleri ve / veya basit yardımcı veri yapıları ile bu farklılıkların muhtemelen çözüleceğini gösterecektir.
Performans açısından yazarlar, günümüz CPU'larının hepsinin güçlü SIMD (tek talimat çoklu veri) hesaplama yeteneklerine sahip olduğunu gözlemlediler ve ayrıca birçok dizüstü bilgisayar ve cep telefonunun yakında GPU'lara veya TPU'lara sahip olacağını tahmin ediyorlar. Ayrıca CPU-SIMD / GPU / TPU'nun gittikçe daha güçlü hale geleceğini tahmin ettiler, çünkü genel komut setleriyle karşılaştırıldığında bu işlemciler, sinir ağlarının gerektirdiği matematiksel işlemlerin çok sınırlı bir kısmının işlem ölçeğini daha kolay genişletebilirler. . O zaman, bir sinir ağını çalıştırmak için gereken yüksek hesaplama gücü gelecekte nihayet değersiz hale gelebilir. Örneğin, hem NVIDIA GPU hem de Google TPU, tek bir saat döngüsünde binlerce, hatta on binlerce sinir ağı hesaplama işlemini tamamlayabilir. Dahası, 2025'e kadar GPU'ların hızının bin kat artırılabileceği, o zamana kadar Moore Yasası'nın CPU'lar için temelde başarısız olduğu belirtildi. Önemli sayıda şubeye sahip dizin yapısı bir sinir ağı ile değiştirildiği sürece, veritabanı sistemleri bu tür donanım geliştirme trendlerinden yararlanabilir.
B ağacının yerini alan makine öğrenimi modeli teoride tamamen var
Burada, sinir ağı tarafından öğrenilen indeks ile kağıttaki B-ağaç indeksi arasındaki karşılaştırmaya odaklanıyoruz.
Veritabanının indeks yapısı aslında bir modeldir, çünkü indeksin rolü, belirli bir anahtar değerinden sonra bu kaydın konumunu "tahmin etmektir". Böyle bir durum varsayıldığında, B-ağacı, aşağıdaki Şekil 1 (a) 'da gösterildiği gibi, bellek içi analitik veritabanının (yani, salt okunur bir veritabanı) sıralı birincil anahtarlarını indekslemek için kullanılır. Bu durumda, B-ağaç dizini, sorgulanacak anahtar değerden sıralı kayıt dizisindeki bir konuma bir eşleme sağlarken, kayıt dizisindeki bu konumun anahtar değerinin sorgunun anahtar değerine eşit olmasını sağlar. Veya sorgunun anahtar değerinden büyük. Menzil erişim talepleri yapmak için verilerin olması gerektiğinden bahsetmeye değer ve bu genel kavram, en düşük seviyenin çiftlerin bir listesi olduğu ve anahtar değerin indekslenmiş özellik olduğu ikincil indeksler için de geçerlidir. İşaretçi, veri kaydını gösterir.
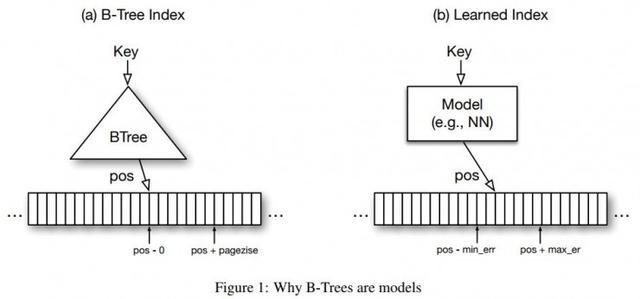
Dizini daha verimli hale getirmek için, sıralı kayıt dizisindeki her anahtar değeri dizine değil, her sayfada ilk olan her n kaydı dizine eklemek yaygın bir uygulamadır. Anahtar değer. Bu, dizinde depolanması gereken veri miktarını önemli ölçüde azaltabilirken, performans düşüşü çok azdır. Bu nedenle, B-ağacı bir modeldir.Makine öğrenimi terimlerinde, bir regresyon ağacı olarak adlandırılabilir: bir anahtar değeri bir konuma eşler ve maksimum ve minimum hataya sahiptir (buradaki minimum hata). 0, maksimum hata sayfa boyutudur) ve bu değer var olduğu sürece, bu aralıkta bulacağınızdan emin olabilirsiniz.
Bundan sonra, verilerin en küçük hatada ve mevcut olduğu sürece en büyük hatada olmasını sağlamak için benzer garantiler sağlayabildikleri sürece, bu indeksleme mekanizmasını derin öğrenme modelleri de dahil olmak üzere diğer makine öğrenimi modelleriyle değiştirebiliriz. Hata aralığı arasında bulun.
İlk bakışta, böyle bir hata garanti mekanizması sağlayabilecek herhangi bir tür makine öğrenimi modeli bulmak zor görünebilir, ancak aslında şaşırtıcı derecede kolaydır. Aslında, B-ağaçları yalnızca depolanan veriler için bu tür bir garanti sağlayabilir, ancak tüm olası veriler için değil. Yeni eklenen veriler için, B ağacının aynı hata garantisini sağlayabilmesi için önce makine öğrenimi terimleriyle "yeniden eğitim" olarak yeniden dengelenmesi gerekir. Bu, sorunu büyük ölçüde basitleştirebilir: garanti edilecek minimum ve maksimum hata, eğitim verileri (depolanan veriler) için modelin maksimum hatasıdır. Yani, sadece bir şey yapmanız, her anahtar değer için bir makine öğrenimi modeli yürütmeniz ve ardından konum tahmininde en kötü yukarı ve aşağı sapma değerlerini hatırlamanız gerekir. Bir anahtar değer verildiğinde, model verilerin nerede bulunacağına dair bir tahmin yapacaktır; bu anahtar değeri varsa, minimum ve maksimum tahmin hataları ile tanımlanan aralık içinde olmalıdır. Daha sonra, yukarıdaki Şekil 1 (b) 'de gösterildiği gibi, B-ağacını doğrusal regresyon veya sinir ağı dahil olmak üzere herhangi bir spesifik regresyon modeli ile değiştirebilirsiniz.
B-ağacını öğrenilmiş bir indeks ile resmen değiştirmeden önce, çözülmesi gereken bazı teknik zorluklar vardır. Örneğin, ekleme ve sorgulama işlemleri için B-ağacının hesaplama maliyeti sınırlı bir aralıktadır ve önbellek çok iyi kullanılabilir; aynı zamanda, B-ağacı, bellek veya diskte sürekli olarak eşlenmeyen sayfalara anahtar değerleri eşleyebilir. Ayrıca, sorgulanacak anahtar değeri veri tabanında yoksa, böyle bir model tarafından döndürülen pozisyon, model boyutunu monoton olarak arttırmıyorsa, minimum / maksimum hata aralığının dışında olabilir. Tüm bu özellikler ilginç zorluklar ve araştırma konularıdır. Makine öğrenimi, özellikle sinir ağları, birçok farklı veri dağılımını, veri karışımlarını ve diğer veri modellerini ve garip özellikleri öğrenebilecek kadar büyülü bir yapıya sahiptir. Dolayısıyla, burada kalan bariz zorluk, modelin karmaşıklığı ve doğruluğu arasında bir denge bulmaktır ve yazarlar ayrıca bazı olası çözümler önerdiler.
Bir "öğrenilmiş dizin" uygulayın
Tamamen bağlı basit bir ağ iyi performans göstermiyor
Yazarlar ilk önce TensorFlow + Python kullanarak her katmanda iki tam bağlantılı katman ve 32 nöron içeren bir sinir ağı oluşturmak için basit bir yöntem denedi. Bunu, 200MB web sunucusu günlük kayıtları için ikincil bir dizin olarak kullanın ve zamanı bir giriş özelliği olarak ve eğitim ve test için ağ tarafından tahmin edilen bir etiket olarak konum olarak kullanın. Bu şekilde elde edilen modelin bir kez çalıştırılması 80.000 nanosaniye sürüyor; aksine, B-ağacının sadece 300 nanosaniye ihtiyacı var ve anahtar-değer alanındaki arama hızı da daha hızlı.
Yazarlar bunun aşağıdaki nedenlerden kaynaklandığına inanıyor:
TensorFlow platformunun tasarım amacı, büyük modelleri verimli bir şekilde çalıştırmaktır, bu nedenle çalışma ek yükü, özellikle Python ile kullanıldığında yüksektir;
B-ağacı veya karar ağacı modeli, veri alanını art arda böldüğünde genellikle çok etkilidir; diğer modeller, verilerin toplam kümülatif olasılık yoğunluğunu tahmin etme konusunda daha yeteneklidir, ancak sonuçta veri alanı büyük değildir (istatistiksel yasa tutarsızlaşmaya başlar. Açıkçası), hız yavaşlayacak;
Tipik makine öğrenimi optimizasyon hedefi, ortalama hatayı optimize etmektir. Ancak, indeksleme görevleri için gerçek maksimum ve minimum hata değerleri daha önemlidir;
B-ağacının önbellek verimliliği çok yüksektir, her zaman en üst düğümü önbelleğe alır ve ardından gerekli diğer bazı sayfaları önbelleğe alır. Aksine, sinir ağının bir işlemi tamamlamak için hafızadaki tüm ağırlıkları okuması gerekir.
Bu sorunların üstesinden gelmek ve teorik olarak uygulanabilir fikirlerin pratik uygulanabilirliğini göstermek için, yazarlar, öğrenilen dizini gerçekleştirmeye yardımcı olmak için özel olarak birkaç yöntem geliştirdiler.
Öğrenme Dizini Çerçevesi
Yazarlar, bir dizin oluşturma sistemi olarak kabul edilebilecek Öğrenme Dizini Çerçevesi, LIF'i yazdılar: Bir dizin özelliği verildiğinde, LIF farklı dizin yapılandırmaları oluşturacak, bunları optimize edecek ve otomatik olarak test edecektir. LIF, çalışırken basit modelleri öğrenmek için TensorFlow'da uygulanan daha karmaşık modelleri kullanabilir; aynı zamanda, çıkarım süreci TensorFlow'a dayanmaz.Öğrenilen modelden verimli bir C ++ derlenmiş sürümü oluşturacaktır, böylece çıkarım büyük ölçüde olabilir. Gereksiz hesaplama yükünü azaltın ve çalışma süresi 30 nanosaniyeye düşürülür.
Yinelemeli Model Dizini
Özyinelemeli model indeksi, özyinelemeli model indeksi RMI, veri alanı küçüldükten sonra modelin öngörü yeteneğinin kötüleştiği yukarıda belirtilen problemi çözmektir. Örneğin, 100M kayıttan veri ararken, maksimum ve minimum hataları birkaç yüz büyüklüğe düşürmek istiyorsanız, tek bir modele güvenmek çok zordur; ancak aynı zamanda hatayı 10k mertebesine düşürmek için bu modeli kullanın B-ağacının en üstteki iki katmanını değiştirmek çok daha basittir ve basit bir modelle yapılabilir. Benzer şekilde, bir sonraki katman modelinin hatayı yalnızca 10k'dan birkaç yüze düşürmesi gerekir.Yalnızca verilerin bir alt kümesine odaklanması gerektiğinden, bu aynı zamanda nispeten basit bir sorundur.

Bu şekilde, yazarlar yinelemeli model indeksi RMI'yi önerdiler. Şekilde gösterildiği gibi, yazarlar birçok modeli içeren hiyerarşik bir ağ yapısı tasarlamışlardır.Her katmandaki modeller giriş olarak anahtar değerleri alır ve ardından son katmanın model çifti konumuna kadar bir sonraki katmanın modelini buna göre seçer. Tahminler yapın. Burada, her model, anahtar-değer alanının belirli bir kısmından sorumlu olarak kabul edilebilir ve katman katman seçim sürecinde tahmin hatasını kademeli olarak azaltır. Yazarlar ayrıca böyle bir modelin katman katman eğitilebileceğini ve sonunda eksiksiz bir ağın elde edilebileceğini kanıtladılar.
Ancak şunu da belirtmekte fayda var RMI bir ağaç modeli değildir . Yukarıdaki şekilde gösterildiği gibi, farklı üst düzey modeller aynı alt düzey modeli seçebilir; ve her modelin kapsadığı veri aralığı bir B-ağacı gibi sabit değildir; son olarak, tahmin farklı modeller arasındaki seçimle yapılır. Bu nedenle, bu sürecin anlaşılması "konumun kademeli olarak doğru tahmini" olarak görülmemelidir, ancak "bu anahtar değer hakkında daha iyi bilgi sahibi olan model art arda seçilir".
Bu model yapısının birkaç avantajı vardır:
Veri dağıtımının genel şeklini öğrenmek daha kolaydır ve bu model yapısı bu yasadan yararlanır;
Böyle bir model, veri alanını verimli bir şekilde çok sayıda küçük alana bölebilir, böylece veri alanı çok küçük olduğunda nihai veri alanının tahmin doğruluğunu geliştirmek için daha az işlem kullanabilir;
Ağdaki farklı katmanlar arasında arama işlemine gerek yoktur. Örneğin, model 1.1'in çıktısı doğrudan model 1.2'nin sonraki katmanını seçer. Bu yalnızca tüm yapıyı yönetmek için gereken talimat sayısını azaltmakla kalmaz, aynı zamanda tüm dizini TPU / GPU'da tamamlanabilen bir matris çarpma işlemi olarak ifade eder;
Böyle bir yapı, farklı modellerin karıştırılmasına izin verir. Örneğin, üst model ReLU aktivasyon işlevini kullanan bir sinir ağı olabilir, çünkü genellikle birçok farklı karmaşık veri dağılımını öğrenebilirler; alt model binlerce basit doğrusal regresyon modeli olabilir, çünkü alan gerektirir ve Uygulama süresi çok kısa.
Karma model ağı ve eğitimi
Bu yazıda, yazarlar farklı modellerden oluşan bir RMI ağını eğitmek için bir algoritma yazdılar. Spesifik olarak, tek model, her biri maksimum 32 nöron genişliğine sahip 0 ila 2 tamamen bağlı katman ve ReLU aktivasyon işlevlerine sahip basit bir sinir ağı olabilir; ayrıca bir karar ağacı olan bir B-ağacı da olabilir. Diğer model türlerini istiyorsanız, önce bu iki türü kullanabilirsiniz.
Yazarın tasarımına göre her modelin standart minimum / maksimum hatası alt modelde saklanacaktır.Bu yaklaşımın avantajı, kullanılan modele göre her bir anahtar değeri için arama alanının ayrı ayrı ayarlanabilmesidir. boyut. Yazarlar ayrıca karma model ağ için bir değiştirme işlevi tasarladılar.Başlangıçta, ağdaki tüm modeller sinir ağlarıdır ve sinir ağı modelinin mutlak minimum / maksimum hatası belirli bir eşikten yüksekse, eğitim algoritması Bu sinir ağı modeli, bir B-ağacı ile değiştirildi. Bu aslında karma model ağ performansının alt sınırını belirler: en kötü, öğrenilemeyen veri dağıtımı için karma model ağ temelde bir B-ağaç modelidir; ve diğer durumlarda, Tüm modeller daha iyi performansı hak ediyor.
Test sonuçları
Yazarlar, öğrenilen indeks modelini çeşitli veri setlerinde B-ağaç modeli ile karşılaştırdı. B-ağaç modeli farklı sayfa boyutları kullanır ve öğrenilen indeks modeli 2 katmanlı bir RMI modeli kullanır Test ayrıca farklı ikinci aşama model arama numaralarının performansını gösterir. Model yapısı ile ilgili olarak, ikinci aşama modeli, yapı en basit olduğunda (0 tamamen bağlı katman) aslında en iyi performansa sahiptir, bu temelde doğrusal bir modeldir; bu şaşırtıcı değildir, çünkü arama alanı azaltıldıktan sonra çalıştırın Daha karmaşık modeller uygun maliyetli değildir. Öğrenilen indeks modelinin tamamı LIF ile derlendikten sonra, GPU / TPU olmadan Intel E5 CPU üzerinde çalışır.
Weblogları veri seti, bir üniversite web sitesinin son yıllarda 200 milyon erişim kaydını içerir ve her kaydın farklı bir zaman damgası vardır. Bu veri seti neredeyse en kötü durum olarak kabul edilebilir çünkü veri modeli, öğrenmesi çok zor olan kurs planlama, hafta sonları, tatiller, öğle yemeği, üniversite etkinlikleri, tatil zamanı vb. Faktörlerden etkilenecektir.
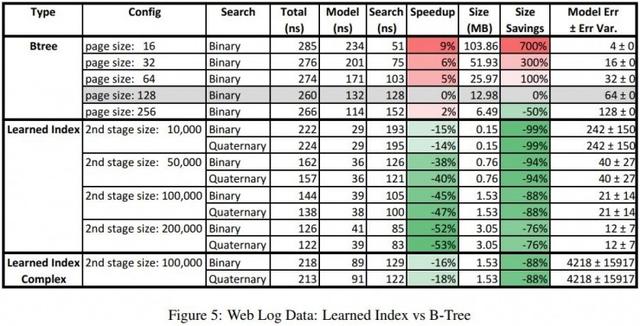
Gerçek test sonuçları, B-ağacı ile karşılaştırıldığında, öğrenilen indeks modelinin sadece her zaman daha hızlı olmadığını, aynı zamanda% 99'a kadar tasarruf sağladığını, bu da iki büyüklük sırası olduğunu göstermektedir.
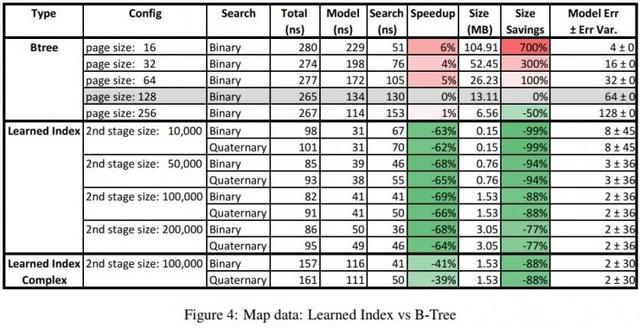
Harita veri seti, dünyanın her yerinden kullanıcılar tarafından eklenen yaklaşık 200 milyon dönüm noktası bilgisi içerir. Bu veri setinin verileri daha doğrusal ve daha az düzensizdir. Bu nedenle, öğrenilen indeks Weblogları veri setinden daha iyi performansa sahiptir.Hız sadece% 60'tan fazla hızlandırmakla kalmaz, boyut% 99'a kadar azaltılabilir ve maksimum tahmin hatası da çok azaltılır.
Bu sonuç, yazarlar tarafından makalenin başında önerilen "veriler düzenli olduğunda, makine öğrenimi yönteminin indeksleme verimliliğini optimize edebilir" varsayımını güçlü bir şekilde doğrulamakla kalmadı, aynı zamanda ön denemenin etkisi şaşırtıcı derecede iyi.
Yeni dizin modelini öğrendikten sonra
Yazarların, geleneksel indeks yapısını öğrenilen indeks ile tamamen değiştirme niyetinde olmadıklarını belirtmek gerekir. Aslında, mevcut araştırmaya ek olması gereken yeni bir indeksleme yöntemine işaret etmek ve onlarca yıllık olan veritabanı indeksleme alanı için yeni bir araştırma yönü açmak istiyorlar (tabii ki, bu hala Daha fazla takip araştırması ve tartışma).
Yazarın bu makaledeki araştırması, salt okuma yüküne (anahtar-değer araması, veri konumu, mevcudiyet arama) odaklanır ve ayrıca bu fikrin, ağır yazma yükü olan bir sistemin hızlanmasına nasıl genişletileceğini kabaca tartışır. Yazarlar ayrıca, sıralama ve birleştirme dahil olmak üzere veritabanı sisteminin diğer bileşenlerini ve işlemlerini değiştirmek için aynı fikrin nasıl kullanılacağını kısaca açıkladılar. Bu çalışmalar sorunsuz bir şekilde ilerlerse, bu mevcut veritabanı sistemi modelinden sapan yeni bir yaklaşıma dönüşebilir.Yüksek boyutlu indeksleme, veritabanı işlem algoritmalarını öğrenme, GPU / TPU hızlandırılmış veritabanı operasyonlarının tümü ilginç ve geniş kapsamlı pratik araştırma hedefleri olacaktır.
Genel olarak yazarlar, makine öğrenimi ile öğrenilen modellerin, mevcut en iyi veritabanı indeksleme yöntemlerine dayalı olarak önemli iyileştirmeler getirmeye devam etme potansiyeline sahip olduğunu göstermektedir.Bu sadece veritabanıyla ilgili teknoloji araştırmaları için yeni bir yön değil, aynı zamanda makine öğrenimi Bir başka yeni alan, yeni sınırlar açar.
Kağıt adresi: https://arxiv.org/abs/1712.01208
Lei Feng Network AI Teknolojisi İnceleme Derlemesi