Toplu standardizasyonun üç alanını anlama (kod makalesi) Makine öğreniminde karşılaşacağınız "çukurlar"


Birçok çerçevede, toplu standardizasyonun çalışması (bundan sonra BN olarak anılacaktır) spesifik uygulamada çok basittir ve keras'ta istisna değildir. Modele sadece BN katmanını eklememiz gerekir, bu da standardizasyonun bir katmana karşı yapıldığı anlamına gelir. :
keras.layers'dan BatchNormalization'ı BN olarak içe aktarın
BN (epsilon = 0.001, center = True, scale = True, beta_initializer = 'sıfırlar', gamma_initializer = 'ones')
Eğitim süreciyle ilgili parametreler esas olarak burada açıklanmaktadır. Epsilon'un olduğu resmi varsayılan parametre ayarlarını kullanıyoruz (

) Standart sapma tahmin edildiğinde, tanımlanmamış gradyanlardan kaçınmak için varyansa çok küçük bir sayının eklenmesi gerektiği anlamına gelir:
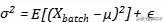
merkez (
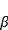
) Ve ölçeklendir (

Yeniden ölçeklendirme için öğrenilebilir iki parametredir. Bunu True olarak ayarladık, bu da bu iki öğrenilebilir parametreyi kullanacağımız anlamına gelir.

Özel kullanımımızda, birini seçerek tutabilir veya hariç tutabiliriz. Sonuncusu, öğrenilebilir parametrelerin ilklendirme yöntemidir, tamamlamak için başlatıcıyı keras'ta kullanabiliriz.
Önceki bölümde yer alan teorik makalede belirtilen birkaç konuyu esas olarak tartışıyoruz:
- Genel olarak, BN eğitimi gerçekten hızlandırabilir mi?
- Yalnızca özellik ölçeklendirmesi dikkate alınır ve dahili ortak değişken kayması dikkate alınmaz BN katmanı arttıkça, eğitim daha iyi ve daha iyi olacak mı?
- Yeniden parametreleme, katmandan katmana koordinasyon güncellemesi sorununu değiştirirse, uyarlanabilir öğrenme hızı algoritması ve BN daha iyi sonuçlar elde edecek mi?
- Eğitimde farklı gruplar kullandığımızda, BN üzerinde nasıl bir etkisi olacak?
Eğitim için hala MNIST veri setini kullanıyoruz, önceki yapıyı kullanmaya devam ediyoruz (veya etkisini daha iyi görebilmek için ağı daha derinleştirebiliriz), eğitim sonuçlarını kaydediyoruz ve optimizasyon etkisini gözlemliyoruz. Bazı durumlarda, test aşamasında her katmanın çıktısını alın ve sonuçları gözlemleyin.
Önce verileri içe aktarıyoruz, onu tek sıcak kodlama için kullanıyoruz ve normalleştiriyoruz:
numpy'yi np olarak içe aktar
keras.datasets'den ithalat mnist
keras.utils'den içe_categorical'a aktar
# Verileri İçe Aktar
(X_train, y_train), (X_test, y_test) = mnist.load_data ()
train_labels = to_categorical (y_train)
test_labels = to_categorical (y_test)
X_train_normal = X_train.reshape (60000,28 * 28)
X_train_normal = X_train_normal.astype ('float32') / 255
X_test_normal = X_test.reshape (10000, 28 * 28)
X_test_normal = X_test_normal.astype ('float32') / 255
Ve normal bir ileri beslemeli sinir ağı oluşturmak için sigmoid işlevini gizli birim olarak kullanın:
numpy'yi np olarak içe aktar
keras.datasets'den ithalat mnist
keras.models'den Sıralı içe aktarma
keras.layers'dan Yoğun ithal
keras içe aktarma optimize edicilerden
keras.layers'dan BatchNormalization'ı BN olarak içe aktarın
def normal_model (a):
model = Sıralı ()
model.add (Yoğun (512, aktivasyon = a, input_shape = (28 * 28,)))
model.add (Yoğun (256, etkinleştirme = a))
model.add (Yoğun (128, etkinleştirme = a))
model.add (Yoğun (64, aktivasyon = a))
model.add (Yoğun (10, aktivasyon = 'softmax'))
model.compile (optimizer = optimizers.SGD (momentum = 0.9, nesterov = True), \
kayıp = 'categorical_crossentropy', \
metrics =)
dönüş (model)
Yukarıdaki modele yeni bir model olarak bir BN katmanı ekleyin:
def BN_model (a):
model = Sıralı ()
model.add (Yoğun (512, aktivasyon = a, input_shape = (28 * 28,)))
model.add (BN ())
model.add (Yoğun (256, etkinleştirme = a))
model.add (Yoğun (128, etkinleştirme = a))
model.add (Yoğun (64, aktivasyon = a))
model.add (Yoğun (10, aktivasyon = 'softmax'))
model.compile (optimizer = optimizers.SGD (momentum = 0.9, nesterov = True), \
kayıp = 'categorical_crossentropy', \
metrics =)
dönüş (model)
İki modeli 10 döneme kadar eğitin ve performanslarını gözlemleyin:
model_1 = normal_model ('sigmoid')
his_1 = model_1.fit (X_train_normal, train_labels, batch_size = 128, validation_data = (X_test_normal, test_labels), ayrıntılı = 1, epochs = 10)
w1 = his_1.history
model_2 = BN_model ('sigmoid')
his_2 = model_2.fit (X_train_normal, train_labels, batch_size = 128, validation_data = (X_test_normal, test_labels), ayrıntılı = 1, epochs = 10)
w2 = his_2.tarihi
matplotlib.pyplot dosyasını plt olarak içe aktar
seaborn'u sns olarak ithal etmek
sns.set (style = 'whitegrid')
plt.plot (aralık (10), w1, '-.', etiket = 'BN'siz')
plt.plot (aralık (10), w2, '-.', etiket = 'BN_1 ile')
plt.title ('Sigmoid')
plt.xlabel ('epochs')
plt.ylabel ('Kayıp')
plt.legend ()

Şekilde görüldüğü gibi, sadece bir BN katmanının eklendiği ve modelin yakınsama hızının eklenmeden çok daha hızlı hale geldiği görülebilir.
"Ortak Gizli Birimler" de sigmoid yerine ReLU kullandık ve yakınsama hızı arttı BN katmanımız da ReLU gibi iyi performans gösteren gizli birimleri hızlandıracak mı? ReLU'yu etkisini gözlemlemek için kullanacağız:

Şekilde gösterildiği gibi, ReLU sigmoid gradyan kaybolması problemini yaklaşık doğrusallaştırma ile hafiflettiğinden ve BN, katmanlar arasındaki bağımlılığı zayıflatarak çalıştığı için, BN yakınsamayı ReLU temelinde daha da hızlandırabilir.
BN anlayışımıza dayanarak, 4 katmanlı modelimiz için katmanlar arasındaki bağımlılığı zayıflatarak (veya temsil sürecindeki iç değişken kaymanın etkisini zayıflatarak) yakınsamayı gerçekten hızlandırıyorsa, o zaman yalnızca ekleyin İlk BN katmanı, alt katmanı diğer üç katmandan ayırır, bu üç katmanın optimizasyonu hala birbirini etkiler. Bu nedenle, bir BN katmanı eklersek, yakınsama hızının da daha hızlı olması beklenebilir.
Uygulamada, her biri farklı BN katmanlarına sahip sırayla dört model oluşturuyor ve onları dönemlerle Loss değişim grafiğini elde etmek için eğitiyoruz:


Şekilde gösterildiği gibi, sigmoid aktivasyon fonksiyonunu kullanan modelin yakınsama hızı ve etkisi katman sayısı arttıkça artar ReLU kullanan model BN katmanlarının sayısına duyarlı görünmemektedir.Bir katman kullanmak ile birden fazla katman kullanmak arasında önemli bir fark yoktur. Bunun nedeni muhtemelen ağın yeterince derin olmamasıdır, ReLU artı bir BN katmanı bu model optimizasyonunun sınırına ulaşmış gibi görünüyor.
Bir sonraki kodumuz ReLU'yu tartışmayacak çünkü sigmoid aktivasyon fonksiyonu modelinin ayarlama için daha fazla yeri var gibi görünüyor ve etkisini kolayca görebiliriz. Bunu başarmak için nispeten basit, SGD algoritmasını Adam algoritmasına değiştiriyoruz.Bir yandan BN katmanını kullanmayan modele uyarlanabilir bir öğrenme hızı optimizasyon algoritması ekleyebiliriz, diğer yandan BN katmanını kullanan modele kendi kendine uyarlanabilir öğrenme hızı optimizasyon algoritmaları ekleyebiliriz. Yakınsamayı hızlandırıp hızlandırmadığını görmek için öğrenme hızı optimizasyon algoritmasını uyarlayın.
Önceki bölümdeki bilgilere göre, BN ve uyarlanabilir öğrenme oranı, parametre güncelleme aralığını değiştirmek için iki yöntemdir, her ikisi de parametre güncelleme aralığını olabildiğince büyük bir sıra içinde tutar ve üst ve alt arasında fark yoktur.
Uygulamada yukarıdaki modellerden yola çıkarak iki yeni model tanımlıyoruz: Biri BN kullanmıyor ama Adam kullanıyor, diğeri BN kullanıyor ve ayrıca Adam algoritmasını kullanıyor ve ilk iki modelle karşılaştırıyor. , Adam ve SGD'nin öğrenme oranını aynı tutuyoruz, her ikisi de 0.01, keras'taki ikisinin varsayılan parametreleri aynı değil, lütfen manuel olarak ayarlayın:

Şekilde gösterildiği gibi, BN kullanarak modele Adam algoritmasının eklenmesinin modelin yakınsamasını daha da hızlandırdığını, BN'siz modele Adam algoritmasının eklenmesinin de BN ile benzer etkiler sağladığını görüyoruz.
Teorik olarak standardizasyonun partiye dayandığını bulabiliriz. Parti, eğitim setinin bir alt kümesidir. Boyutu, BN'deki varyans ve ortalamanın hesaplanmasını doğrudan etkileyecektir. Muhtemelen her partinin farklı bir ortalama ve varyansı vardır.
Standartlaştırılmış parametrelerin belirli bir parti için sabitlendiği varsayılmaktadır. Toplu iş boyutunun azaltılması, gruplar arasındaki farklılığı artıracak (BN'nin varyansını değil), ağı daha değişken hale getirecektir. Bununla birlikte, BN kullanılmasa bile, parti boyutunun gradyan tahminini yine de etkileyeceğine dikkat edilmelidir. Büyük partilerin yinelenmesi daha hızlıdır, ancak yerel minimumlara düşme eğilimindedir. Küçük partiler daha yüksek rasgeleliğe sahiptir, ancak bir dönemi geçmek daha fazla zaman alır. Bu nedenle, parti boyutunu değiştirdikten sonra, yakınsama etkisinin BN katmanından mı yoksa gradyan tahmininden mi kaynaklandığını etkili bir şekilde belirleyemiyoruz.
Ama bu problemi başka bir probleme dönüştürebiliriz, yani BN eklenen model ile farklı partilerde BN eklenmemiş modelin performansını karşılaştırabiliriz.Küçük bir toplu iş üzerindeyse BN eklenen model BN'siz modelle karşılaştırılır. BN modelinin eklenmesi iyi sonuçlar vermedi, bu da BN katmanının küçük partide bir rol oynamadığı anlamına geliyor.
Bu fikre göre, BN modelini ve BN'siz modeli eğitmek için 4, 64, 256, 1024 dört parti boyutu kullanıyoruz, şunları elde edebiliriz:

Şekilde gösterildiği gibi, birçok bilgi bulabiliriz.BN katmanı eklenmiş model için (kesikli çizgi), parti boyutu 64 ve 4 olduğunda, yakınsama etkisi ve hız en iyisidir.BN eklenmemiş model için (düz çizgi), toplu olarak Etkisi 4 olduğunda en iyisidir. Bununla birlikte, küçük partilerde, BN kullanılıp kullanılmayacağı, performansı neredeyse hiç etkilemeyecektir.Küçük partilerde, BN katmanı performansı düşürür.
