Derin öğrenme GPU operasyonunu optimize etmek için TVM nasıl kullanılır? Düzinelerce Python kodu satırı ile 2-3 kat iyileştirme elde etmeyi öğretin
Birkaç gün önce Chen Tianqinin ekibi TVMnin lansmanını duyurdu ve Weiboda şöyle dedi: "Bugün TVM'yi yayınladık ve NNVM birlikte çeşitli donanımlarda derin öğrenme için eksiksiz bir optimizasyon araç zinciri oluşturuyor, cep telefonlarını, cuda, opencl, metal, javascript ve Diğer çeşitli arka uçlar. Derin öğrenme, derleme ilkeleri, yüksek performanslı bilgi işlem ve donanım hızlandırma ile ilgilenen öğrencilere açık kaynak proje topluluğunu tanıtmak ve yönetmek için dmlc'ye katılmaya hoş geldiniz. "
Leifeng.com AI Technology Review'a göre, mevcut sistemlerin çoğu, dar bir sunucu seviyesi GPU yelpazesi için optimize edilmiştir ve cep telefonlarına, IOT cihazlarına ve özel hızlandırıcılara dağıtılması için çok fazla çalışma gerektirir. TVM, derin öğrenme iş yüklerini donanıma dağıtan uçtan uca bir IR (orta düzey temsil) yığınıdır. Başka bir deyişle, bu tür bir çözüm, derin öğrenme modelini çeşitli donanım cihazlarına dağıtabilir ve uçtan uca ayarlamayı başarabilir.
Üç özelliği vardır:
-
Düzenli derin öğrenme görevlerinde CPU, GPU ve diğer özel donanımların hesaplama miktarını optimize edebilir;
-
Hesaplama grafiklerini otomatik olarak dönüştürebilir, bellek kullanımını en aza indirebilir, veri düzenini optimize edebilir ve hesaplama modlarını entegre edebilir.
-
Tarayıcıda mevcut ön uçtan çıplak donanım donanımına ve yürütülebilir Javascripts'e kadar uçtan uca derleme sağlayın.
Leifeng.com AI Technology Review, TVMnin ilk blogunun bunu tanıttığını öğrendi:
"TVM'nin yardımıyla, geliştiricilerin cep telefonlarında, gömülü cihazlarda ve hatta tarayıcılarda derin öğrenme görevlerini kolayca yürütmek için yalnızca küçük bir miktar ekstra çalışmaya ihtiyaçları var. TVM ayrıca birden fazla donanım platformunda birleşik derin öğrenme iş yükleri sağlıyor. Yeni bilgi işlem ilkelerine dayanan özel hızlandırıcılar dahil optimize edilmiş çerçeve. "
Bugün Chen Tianqi, Tucson'un gelecekteki öğreticisi Hu Yuwei ile TVM'nin derin öğrenme op optimizasyonunun tanıtımına odaklanan Weibo'da yeni bir güncelleme yayınladı.
"Derin öğrenme operasyonu optimizasyonu çok önemli ama zor bir problem. Gelecekte Tucson'dan Hu Yuwei, derin öğrenme gpu operasyonunu optimize etmek için TVM'nin nasıl kullanılacağına dair bir eğitim yazdı ve mevcut tf'den iki veya üç daha fazlasını elde etmek için düzinelerce python kodu satırı aracılığıyla İyileştirme zamanları. "
Bu makale şu anda TVM blogunda da güncellenmektedir.Leifeng.com AI Technology Review ilk kez kapsam ve raporlar sağladı.
Pekin Havacılık ve Uzay Üniversitesi'nden Elektronik Mühendisliği Yüksek Lisansı olan Hu Yuwei, şu anda bir yıldır Gap ve şimdi Tucson'daki gelecekteki HPC grubunda stajyer. Bu makale, "Derin Öğrenme GPU Operatörlerini TVM ile Optimize Edin: Derinlemesine Evrişim Örneği" başlığını taşımaktadır (Derinlemesine Evrişimi örnek alarak, derin öğrenme GPU operatörlerini optimize etmek için TVM kullanarak)
Etkili derin öğrenme operatörleri, derin öğrenme sistemlerinin çekirdeğidir. Genellikle bu operatörlerin optimize edilmesi zordur ve HPC uzmanlarından çok çaba gerektirir. Uçtan uca bir tensör IR / DSL yığını olan TVM, tüm süreci kolaylaştırabilir.
Bu makale, geliştiricilere TVM'nin yardımıyla yüksek performanslı GPU operatör çekirdeklerinin nasıl yazılacağını öğretmek için iyi bir referans sağlar. Ekip örnek olarak Depthwise Convolution'u (yani topi.nn.depthwise_conv2d_nchw) kullandı ve manuel olarak optimize edilmiş TensorFlow'da CUDA çekirdeğinin nasıl geliştirileceğini gösterdi.
Makalenin açıklamasına göre, TVM kullanan son sürüm, farklı iş yükleri altında tf-1.2'de optimize edilmiş çekirdekten 2-4 kat daha hızlıdır ve operatör füzyon hızı 3 ila 7 kat artar. Aşağıdakiler GTX1080, filtre boyutu =, adım =, dolgu = 'AYNI' altındaki test sonucudur:

Depthwise Convolution, Google Xception ve Depthwise Convolution'a ait MobileNet dahil olmak üzere derin sinir ağlarının hesaplama karmaşıklığını etkili bir şekilde azaltabilen bir model oluşturmak için temel bir fikirdir.

TVM ortamında, Depthwise Convolution çalıştırma kodu aşağıdaki gibidir:
# padding stagePaddedInput = tvm.compute (
(batch, in_channel, height_after_pad, width_after_pad),
lambda b, c, i, j: tvm.select (
tvm.all (i > = pad_top, i-pad_top = pad_left, j-pad_left Girişi, tvm.const (0.0)),
name = "PaddedInput") # deepconv stagedi = tvm.reduce_axis ((0, filter_height), name = 'di') dj = tvm.reduce_axis ((0, filter_width), name = 'dj') Çıktı = tvm.compute (
(toplu, kanal dışı, dış_yükseklik, dış_genişlik),
lambda b, c, i, j: tvm.sum (
PaddedInput * Filtresi,
eksen =),
name = 'DepthwiseConv2d')
Genel GPU optimizasyon kılavuzu
Hu Yuwei, makalede CUDA kodunu optimize ederken genellikle dikkat edilmesi gereken üç ana konudan bahsetti. Verilerin yeniden kullanımı (verilerin yeniden kullanımı), paylaşılan hafıza (paylaşılan hafıza) ve erişim çakışmaları (banka çakışmaları).
Modern bilgi işlem mimarilerinde, bellekten veri yükleme maliyeti, tek bir kayan nokta hesaplamasından çok daha yüksektir. Bu nedenle, giriş verilerinin kayıt veya önbelleğe yüklendikten sonra tekrar kullanılabileceğini umuyoruz.
Derinlemesine evrişimde iki veri yeniden kullanım biçimi vardır: filtrenin yeniden kullanımı ve girişin yeniden kullanımı. İlki, giriş kanalının üzerinden kaydırıldığında ve birden çok kez hesaplandığında meydana gelir ve ikincisi, döşeme sırasında ortaya çıkar. 3x3 derinlemesine evrişimi örnek olarak alın:

Döşeme olmadan, her iş parçacığı 1 çıkış öğesini hesaplar ve 3x3 giriş verilerini yükler. 16 diş için 9x16 yük vardır.

Bölünmüş durumda, her iş parçacığı 2x2 çıkış elemanlarını hesaplar ve 4x4 giriş verilerini yükler. 4 iş parçacığı için toplam 16x4 yük.
Paylaşılan hafıza ve erişim çakışması
Paylaşılan bellek, GPU'da bir önbellek olarak görülebilir ve daha hızlı olan yonga üzerindedir. Genel uygulama, verileri genel bellekten paylaşılan belleğe yüklemek ve ardından bloktaki tüm iş parçacıkları paylaşılan bellekten verileri okumaktır.

Erişim çakışmalarını önlemek için, aşağıda gösterildiği gibi ardışık iş parçacıkları ardışık bellek adreslerine erişmek için en iyisidir (her renk paylaşılan bir bellek bankasını temsil eder):
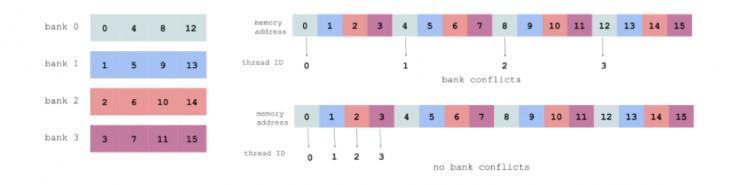
Ayrıntılar için lütfen https://devblogs.nvidia.com/parallelforall/using-shared-memory-cuda-cc/ adresine bakın.
Spesifik optimizasyon süreci
Bellek ayırmayı kaydetmek için girişi satır içi olarak hesaplayın ve doldurun
Dolgu, ayrı bir aşama olarak açıkça belirtilmiştir. Satır içi işlemleri hesaplayarak fazladan bellek tahsisinden kaçının:
s = tvm.create_schedule (Output.op) s.compute_inline
Büyük bir kanalı daha küçük parçalara ayırın
Basit bir yaklaşım, bir CUDA bloğunda bir giriş kanalını ve ilgili filtreyi işlemek, bunu paylaşılan belleğe yüklemek ve hesaplamaktır:
IS = s.cache_read (PaddedInput, "paylaşılan",)
FS = s.cache_read (Filtre, "paylaşılan",)
block_y = tvm.thread_axis ("blockIdx.y")
block_x = tvm.thread_axis ("blockIdx.x")
# toplu iş boyutunu (NCHW'de N) block_y ile bağlayın
s.bind (Output.op.axis, block_y)
# kanalın boyutunu (NCHW'de C) block_x ile bağlayın
s.bind (Output.op.axis, block_x)
Aşağıdaki şekil test sonucudur, GTX 1080'de ortalama 1000 çalıştırma maliyetidir ve tensorflow'daki deepwise_conv2d ile karşılaştırılır.
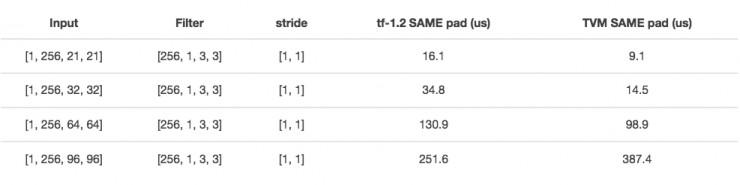
Kanal boyutu 21 x 21 veya 32 x 32 ise performans iyidir ancak 64 x 64 ise performans büyük ölçüde azalacaktır. Bazı değişiklikler yaparsanız, etki çok gelişir:


İplik numarası ayarı
Aşağıdaki gibi bir cuda bloğunda 32 x 32 iş parçacığı uygulayın:

En uygun çözümü elde etmek için num_thread_y ve num_thread_x parametrelerini nasıl ayarlayabilirim? Filter = ve stride = altında:

Test sayesinde ekip şu sonuçları aldı:
-
Büyük ölçekli döşeme, verilerin yeniden kullanımı için iyidir, ancak yerel bellekten okumak için iyi değildir.
-
num_thread_y ve num_thread_x erişim çakışmaları üzerinde farklı etkilere sahiptir.
-
En iyi num_thread_y ve num_thread_x kombinasyonunun verimli paylaşımlı bellek erişimi (depolama alanı çakışmalarını önleme), verilerin yeniden kullanımı ve yerel bellek okuma dengesi sağlaması gerekir.
Kaba kuvvet araması yoluyla, TVM'de num_thread_y ve num_thread_x parametrelerini program işlevine geçirebilir ve en iyi kombinasyonu bulmak için tüm olası kombinasyonları deneyebiliriz.

Vthread (sanal iş parçacığı) ve Strided Patterns
TVM'de Vthread, Strided Pattern'leri etkin bir şekilde destekleyebilir.

Filter =, stride =, blocking_h = 32, blocking_w = 32 durumunda sonuçlar aşağıdaki gibidir:

Durum 2, durum 1'den daha hızlıdır, çünkü 2 num_thread_x = 8 ve num_vthread_x = 4 durumunda, ardışık iş parçacıklarının ardışık bellek adreslerine erişmesi sağlanır ve böylece aşağıda gösterildiği gibi erişim çakışmaları önlenir (her renk bir iş parçacığını temsil eder) İş yoğunluğu):

Tensorflow ile karşılaştırmayı gözden geçirelim:

Operatör füzyonu
Operatör füzyonu, derin öğrenme ağlarını optimize etmek için tipik bir yöntemdir. TVM'de, deepwise_conv2d + scale_shift + relu orijinal modu dikkate alındığında, aşağıdaki gibi biraz değiştirilebilir:

IR'yi aşağıdaki gibi oluşturun:
/ * Girdi =, Filtre =, adım =, padding = 'AYNI' * / Relu üret {
// attr thread_extent = 1 // attr storage_scope = "local" DepthwiseConv2d'yi ayır
// attr thread_extent = 1 // attr thread_extent = 8 // attr thread_extent = 8 DepthwiseConv2d'yi üretin {
(i, 0, 4) {için
(j, 0, 4) {için
DepthwiseConv2d = 0.000000f
for (di, 0, 3) {
for (dj, 0, 3) {
DepthwiseConv2d = (DepthwiseConv2d + (tvm_if_then_else ((((((1-di) -i)}
}
}
}
}
for (i2.inner.inner.inner, 0, 4) {
for (i3.inner.inner.inner, 0, 4) {
Relu = max (((DepthwiseConv2d * Scale) + Shift), 0.000000f)
}
}}
Gördüğünüz gibi, her evre, deepwise_conv2d'nin sonucunu global belleğe yazmadan önce scale_shift ve relu'yu hesaplar. Füzyon operatörü, tek bir deepwise_conv2d kadar hızlıdır. Aşağıdakiler, Input =, Filter =, stride =, padding = "SAME" sonucudur:
-
tf-1.2 deepwise_conv2d: 251.6 us
-
tf-1.2 deepwise_conv2d + scale_shift + relu (ayrı): 419.9 us
-
TVM deepwise_conv2d: 90.9 us
-
TVM deepwise_conv2d + scale_shift + relu (füzyon): 91.5 us
Daha optimize edilmiş kod aşağıdaki bağlantıya başvurabilir:
Bildirin: https://github.com/dmlc/tvm/blob/master/topi/python/topi/nn/convolution.py
Zamanlama: https://github.com/dmlc/tvm/blob/master/topi/python/topi/cuda/depthwise_conv2d.py
Test: https://github.com/dmlc/tvm/blob/master/topi/recipe/conv/depthwise_conv2d_test.py