40 dil, 9 akıl yürütme görevi, Google yeni bir NLP karşılaştırma testi XTREME yayınladı

Yazar | Jiang Baoshang
Editör | Jia Wei
Dünyada yaklaşık 6.900 dil vardır, ancak çoğu İngilizce veri ölçeğine sahip değildir, bu da çoğu NLP kriterinin İngilizce görevlerle sınırlı olmasına neden olur ve bu da doğal dil işlemenin çok dilli gelişimini büyük ölçüde kısıtlar.
Dilbilimsel bir bakış açısından, farklı dillerin aynı kökene sahip olabileceğine dikkat çekmek önemlidir, örneğin, İngilizce "masa" ve Almanca "Tisch" Latince "discus" dan gelir.
Yetersiz veri sorununun üstesinden gelmek için diller arasındaki bu "paylaşım yapısının" nasıl kullanılacağı, akademik çevrelerde çok dilli araştırmanın mevcut yönlerinden biridir.
Kısa süre önce Google, büyük bir teşvik olan "XTREME: Çapraz Dilli Genelleştirmeyi Değerlendirmek için Çok Dilli Çok Görevli Bir Karşılaştırma" (XTREME: Çok Dilli Çok Dilli Bir Çok Görevli Karşılaştırma) büyük bir teşvik olarak ortaklaşa lanse edildi. Çok dilli araştırma.

(Lei Feng.com) Bu araştırma, 40 tür dili (12 dil ailesini kapsayan) ve ayrıca farklı sözdizimi veya anlambilim düzeylerinde ortak akıl yürütme gerektiren 9 görevi kapsamaktadır.
XTREME tasarım ilkeleri
Google makalesinin başlığı olarak, XTREME, diller arası aktarım öğreniminin kalitesini değerlendirmek için kullanılan bir karşılaştırma ölçütüdür. Çeşitlendirilmiş ve temsili görevler ve diller açısından, karşılaştırmayı oluşturan görevlerin ve dillerin seçilmesiyle ilgili temel hususlar şunları içerir: Görevler Görevin zorluğu, görev çeşitliliği ve eğitimin verimliliği, çok dillilik, yeterli tek dilli veri vb.
1. Görevin zorluğu, çapraz dil performansını insan performansından daha düşük hale getirecek kadar zordur;
2. Görev, farklı düzeylerde farklı anlamları iletmek için dil modellerini gerektirmelidir.Örneğin, sınıflandırma görevleri cümle düzeyinde anlam aktarımı gerektirirken, konuşma bölümü (POS) etiketleme veya adlandırılmış varlık tanıma (NER) gibi sıralı etiketleme görevlerinin test edilmesi gerekir. Modelin kelime düzeyinde anlamı aktarma yeteneği;
3. Sınırlı kaynaklar göz önüne alındığında, görev bir GPU üzerinde eğitim gerektirir ve eğitim süresi bir günü geçemez;
4. Önce birden çok dili ve dil ailesini kapsayan görevleri düşünün;
5. Görevlerin kullanımına izin verilir, araştırma için kullanılabilir ve bu amaçla verilerin yeniden dağıtımı yapılabilir.
XTREME görev listesi

(Lei Feng Ağı)
XTREME, 9 görev içerir, toplam 4 kategori, farklı anlam seviyelerinde akıl yürütebilirsiniz. Göreve genel bakış yukarıdaki tabloda gösterilmektedir.
XNLI: FAIR ve New York Üniversitesi, MultiNLI'nin test setini ve geliştirme setini Swahili ve Urduca gibi düşük kaynak dilleri de dahil olmak üzere 15 dile genişleten yeni bir doğal dil çıkarım külliyatı olarak ortaklaşa geliştirildi.
PAWS-X: PAWS veri kümesine dayalı olarak, 6 farklı dil türü içeren ifade tanıma çatışmalı veri kümesini genişletmiştir. Desteklenen diller şunlardır: Fransızca, İspanyolca, Almanca, Çince, Japonca ve Korece. PAWS-X veri seti, insan yargısıyla elde edilen 23659 PAWS genişletilmiş cümle çifti seti ve makine çevirisi ile elde edilen 296406 eğitim çifti seti içerir.
POS: Yazar, veritabanındaki POS etiket verilerini genel bağımlılık ilişkisinde kullandı ve eğitim için İngilizce eğitim verilerini kullandı ve hedef dilin test setinde değerlendirildi.
NER: Yazar, NER için Wikiann veri setini kullanır ve Wikipedia'daki adlandırılmış varlıklar için IOB2 formatında LOC, PER ve ORG gerçekleştirmek için bilgi tabanı nitelikleri, çapraz dil, bağlantı bağlantıları, kendi kendine eğitim ve veri seçiminin bir kombinasyonunu kullanır. Etiketlerin otomatik ek açıklaması.
XQuAD: Profesyonel çevirmenler tarafından on dile çevrilmiş 240 paragraf ve 1190 soru yanıtını içeren daha kapsamlı bir diller arası karşılaştırma testi.
MLQA: Bu, XQuAD'e benzer çok dilli bir soru cevaplama veri setidir ve diller arası soru cevaplama performansını değerlendirmek için kullanılabilir. SQuAD formatında (İngilizce'de 12K) 5K'dan fazla çıkarılmış QA örneğinden oluşur ve İngilizce, Arapça, Almanca, İspanyolca, Hintçe, Vietnamca ve Basitleştirilmiş Çince olmak üzere 7 dil kullanır.

(Leifeng.com) XTREME kıyaslamasında desteklenen görevler
TyDiQA-GoldP: TyDiQA, 11 farklı dil türünü kapsayan bir soru-cevap derlemidir.TyDiQA-GoldP basitleştirilmiş sürümüdür ve bazı cevaplanamayan soruları hariç tutar. XQuAD ve MLQA'ya benzer, ancak sırasıyla bu ikisinden üç kat ve iki kat daha az sözcüksel çakışmaya sahiptir. Ek olarak, yazar, hedef dilin test setini eğitmek ve değerlendirmek için İngilizce eğitim verilerini kullanır.
BUCC: Bu veri seti, her dil için eğitim ve test segmentasyonu sağlar. Basit olması için yazar, ince ayar yapmadan test setindeki gösterimi doğrudan değerlendirir, ancak benzerliği hesaplamak için kosinüs benzerlik formülünü kullanır.
Tatoeba: Bu veri seti 122 dili kapsayan 1000 adede kadar İngilizce cümle çifti içerir.Bu veri setinde yazar, en yakın komşuyu bulmak için kosinüs benzerliğini kullanır ve hata oranını hesaplar.
Özetle, XTREME'de yer alan görevler, cümle sınıflandırması, yapılandırılmış tahmin, cümle alma ve soru yanıtlama gibi bir dizi paradigmayı kapsar.
Değerlendirme
İngilizce, çok dilli sunumda en yaygın kullanılan değerlendirme ayarı olduğundan ve çoğu görevde yalnızca İngilizce eğitim verileri bulunduğundan, Google, değerlendirme ortamında diller arası sıfır vuruş aktarımı için kaynak dil olarak İngilizceyi kullanır. İngilizce, tüm hedef dillerin diller arası geçişi için en iyi kaynak dil olmasa da, pratikte en uygun ayardır.
Model performansını değerlendirmek için XTREME'yi kullanmak için, önce modeli çok dilli metin üzerinde, diller arası öğrenmeye neden olan hedef dili kullanarak önceden eğitmek ve ardından modelde belirtilen görevin İngilizce verileri üzerinde ince ayar yapmak gerekir. Ardından XTREME, hedef dilde modelin sıfır vuruşlu diller arası geçiş performansını değerlendirir.
Aşağıdaki şekil, ön eğitimden ince ayara ve sıfır atış geçişine kadar üç ana süreci göstermektedir:
Modelin çapraz dil aktarımı öğrenme süreci: 1. Çok dilli metin için ön eğitim; 2. Aşağı akış görevlerinde ince ayar yapmak için İngilizce kullanın; 3. Sıfır vuruş değerlendirmesi için XTREME'yi kullanın.
Uygulamada, bu sıfır atış ayarının faydalarından biri, hesaplama verimliliğini artırabilmesidir, yani ön eğitim modelinin her görev için yalnızca İngilizce verileri üzerinde ince ayarlanması gerekir ve doğrudan diğer dillerde değerlendirilebilir.
Diğer dillerdeki verileri de etiketleyen görevler için yazar, bu dillerde ince ayar yaptıktan sonra modelin performansını da karşılaştırdı ve sonunda 9 XTREME görevinin sıfır atış puanını ve kapsamlı puanı aldı.
Karşılaştırma testi açısından Google araştırmacıları, test için çok dilli BERT modeli (mBERT), çok dilli BERT modeli XLM ve XLM-R'nin büyük sürümleri ve büyük çok dilli makine çevirisi modeli M4 dahil olmak üzere son teknoloji ürünü birkaç çok dilli model seçti. . Bu modellerin ortak özelliği, farklı dillerden büyük miktarda veri üzerinde önceden eğitilmiş olmalarıdır.
Yöntemler açısından ana kullanım, çok dilli temsili öz denetim yoluyla veya çeviri yardımı ile öğrenmektir.

Açıklamalar: Çeviri temelli kıyaslamaların cümle alımı için hiçbir anlamı yoktur. Hedef dil eğitimi verisi durumunda, yazar bir dil içi kıyaslama sağlar.
Deneysel sonuçlar yukarıdaki şekilde gösterilmektedir. XLMR, genel olarak mBERT'ye göre önemli bir gelişme gösteren en iyi performans gösteren modeldir, ancak yapılandırılmış tahmin görevlerindeki gelişme küçüktür. MMTE'nin çoğu görevdeki performansı, mBERTinkiyle karşılaştırılabilir ve XNLI, POS ve BUCC'deki performans daha güçlüdür.
Dilde eğitim verisi olan görevler için, dil içi verilerle eğitilmiş çok dilli bir model, sıfır atışlı bir geçiş modelinden daha iyidir. Bununla birlikte, daha fazla İngilizce örnek olduğu sürece, sıfır vuruşlu geçiş modeli, dilde yalnızca 1000 karmaşık QA görevi örneğini eğiten çok dilli bir modelden daha iyi olacaktır.
Yapılandırılmış tahmin görevleri için, 1.000 dilsel örnek, modelin eksiksiz bir etiketli veri seti üzerinde eğitim performansına ulaşmasını sağlayabilir.
Son olarak, Translate-train ve In-language ayarlarında çoklu görev öğrenimi genellikle tek dil eğitiminden daha iyidir.
Bazı temsili modeller için yazar, diller arası transfer boşluğunu, yani İngilizce test setindeki performans ile diğer tüm diller arasındaki boşluğu inceledi.

Yukarıdaki şekilde gösterildiği gibi, XLM-R gibi güçlü modeller, XQuAD ve MLQA gibi zorlu görevler üzerindeki mBERT ile karşılaştırıldığında boşluğu önemli ölçüde daraltabilmesine rağmen, sözdizimsel yapılı tahmin görevleri üzerindeki etkileri aynı değildir.
Sınıflandırma görevlerinde, transfer öğrenmedeki boşluk en küçüktür ve bu görevlerde iyileştirme için daha az yer olabileceğini gösterir.
Makine çevirisinin kullanımı tüm görevler arasındaki boşluğu daralttı. Genel olarak, tüm yöntemlerde büyük bir boşluk vardır, bu da diller arası göç çalışması için büyük bir potansiyel olduğunu göstermektedir.
analiz
Yazar, SOTA'ya ulaşabilen mevcut çapraz dil modelinin sınırlamalarını incelemek için bir dizi analiz yaptı. Spesifik analiz beş bölümden oluşur:

Açıklama: Her görev özetinde tüm dillerin XTREME görevindeki XLM-R
En iyi sıfır atış modunun analizi: Yukarıdaki şekilde gösterildiği gibi, bu bölüm temel olarak farklı görevler ve dillerdeki evrensel çok dilli temsilleri değerlendirmenin neden önemli olduğunu açıklamaktadır.

Eğitim öncesi veri boyutu ile korelasyon: Yukarıdaki şekilde gösterildiği gibi, model performansı ile her dildeki Wikipedia makalelerinin sayısı arasındaki Pearson korelasyon katsayısı , çoğu görevin korelasyon katsayılarının yapılandırılmış tahmin görevleri dışında çok yüksek olduğunu gösterir. Bu, mevcut modellerin sözdizimsel görevlere aktarmak için eğitim öncesi verilerden çıkarılan bilgileri tam olarak kullanamayacağı anlamına gelir.
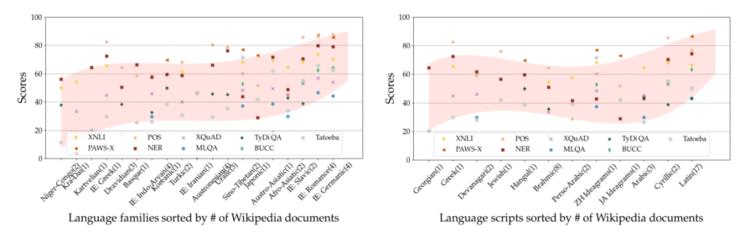
Dil özelliklerinin analizi: Yukarıdaki şekilde gösterildiği gibi, sonuçlar farklı dillere ve yazılara göre analiz edilir. MBERT için, Hint-Avrupa dil ailesinin dalları (Germen, Romantik ve Slav dili gibi) en iyi göç performansına sahiptir. Buna karşılık, Nijer-Kongo ve Kara-Dai gibi düşük kaynak dil aileleri, düşük diller arası aktarım performansına sahiptir. Ek olarak, Latince ve ideogramlar gibi farklı popüler komut dosyaları sözdizimsel görevlerde farklı şekilde çalışır.
Çapraz dil hataları: Diğer test setleri İngilizce'den çevrilmiş XNLI ve XQuAD olduğundan, bu bölümün yazarları bu yöntemlerin kaynak ve hedef dillerde aynı tür hataları yapıp yapmadığını analiz eder. Daha spesifik olarak, İngilizce'deki doğru ve yanlış tahmin örneklerinin diğer dillerde doğru tahmin edilip edilmediğini araştırır. Sonuç, XNLI ve XQuAD veri kümelerinde farklı yanıtların olmasıdır.
Görünmez etiket kombinasyonlarına ve varlıklarına genelleyin: Bu bölüm temel olarak yapılandırılmış tahmin görevlerinin başarısız geçişinin nedenlerini analiz eder. Sonuç, modelin daha fazla hedef dil özelliklerine sahip varlıklara genelleştirilmesinin zor olabileceğidir.