"Hafta Sonu Yapay Zeka Sınıfı" Entegrasyonu Arttırma (Teori) Makine öğreniminde karşılaşacağınız "çukurlar"

Sonbahar yüksek ve hava güzel, öğrenmek için iyi bir zaman ~

Matematik hazırlığı
- Sapma-varyans ayrışımı: Gerçek dağılıma hiçbir zaman uyamayacağımızı varsayarsak, sapma, tahmin edilen değer ile gerçek değer arasındaki sapma derecesini ifade eder. Tahmin edilen değer, gerçek değere tamamen eşitse, sapma sıfırdır, ancak öğrenci muhtemelen gereğinden fazla uyuyor . Varyans, aynı öğrencinin tahmin edilen değerlerinin farklı veriler üzerindeki dağılım derecesini ifade eder Tahmin edilen değerler aynıysa, varyans sıfırdır, ancak öğrenci muhtemelen yetersiz uyum gösterir.
- Üstel kayıp: Örneklerin aynı önemde olması durumunda, üstel kayıp

- ,
- Gerçek kategori işaretini temsil eder,
Tahmin kategori işaretini gösterir Toplam kayıp, her örnek tahmin edildikten sonra üssel kaybın ortalaması olarak anlaşılabilir. (Kaybın karesine benzer şekilde, her bir örnek için kalan karelerin toplamının ortalamasıdır)
- Hata oranı: Numunelerin aynı önemde olması durumunda, hata oranı, yanlış sınıflandırmaya sahip numunelerin tüm numunelere oranıdır ve şu şekilde ifade edilir:
- Tutarsız örneklem önemi durumunda, hata oranı şu şekilde ifade edilen ağırlık katsayısı ile çarpılmalıdır.
. İlkinin yalnızca ikincisinin özel bir durumu olduğu görülebilir.
Skaler gradyan: Skaler bir fonksiyonun gradyanı, yönü skalerin en hızlı değiştiği yönü gösteren bir vektördür.
- Taylor serisi (Talor): sonsuz türevlenebilir fonksiyonlar için
- ,içinde
- Genişletilebilir
- , İlk terimin katsayısı, fonksiyonun gradyanıdır.Genel olarak, sadece düşük sıralı terimleri tutuyoruz, ancak daha yüksek dereceli terimler, yaklaşımı daha doğru hale getirecektir.
Güçlendirme Motivasyonu
Boosting'i derinlemesine anlamak için halihazırda bildiklerimizi özetlememiz gerekir:
- "Torbalama entegrasyonu ve istifleme entegrasyonu (kodu)" nda rastgele ormanın boyutundaki artışın aşırı uyuma yol açmayacağını, ancak entegratörün genelleme hatasını dengeleyeceğini gördük, bu da Torbalama entegrasyonundaki temel öğrencinin Sayının artması modelin karmaşıklığını artırmayacaktır.
- "Overfitting (Theory)" de sapmanın model doğruluğunun bir tezahürü olduğundan ve varyansın model kararlılığının bir tezahürü olduğundan bahsetmiştik. Spesifik olarak, sapma öğrencinin uydurma yeteneğini ölçer. Uydurma yeteneği ne kadar güçlüyse sapma o kadar küçük olur. Sapma çok küçük olduğunda, kayıp küçük olur ve bu da aşırı uyuma neden olur. Şu anda genelleme hatası büyük olacaktır, ancak sapma küçüktür ve genelleme hatasının asıl katkısı varyanstan gelir. Aynı zamanda, eğitim seti ve test seti aynı dağıtımdan örneklenir, ancak eğitim seti iyi performans gösterir, test seti kötü performans gösterir ve buna karşılık gelen varyans da büyüktür, bu da varyansın öğrencinin stabilitesini farklı verilere göre karakterize ettiğini gösterir.
Torbalama entegrasyonu örnek tedirginliği ekler, rastgele orman daha fazla özellik tedirginliği ekler ve son olarak bu farklılaştırılmış modellerin ortalamasının alınması, öğrencinin veri pertürbasyonuna karşı istikrarını mümkün olduğunca iyileştirmektir, yani öğrencinin varyansını azaltmaktır. Temel öğrenicinin artışı sadece modelin çeşitliliğini arttırır, ancak modelin karmaşıklığını arttırmaz.Model ne kadar karmaşıksa, uydurma yeteneği o kadar güçlüdür, ancak torbalama entegrasyonu sapmayı azaltmaya yardımcı olmaz ve hatta öğrencinin sapmasını artırır.
Modelin sapmasını azaltmak istiyorsak, torbalama iyi bir seçim değildir. Aynı zamanda, karmaşık ilişkilere sahip olabilecek veriler karşısında, tek bir basit model düşük önyargılı sonuçlar elde edemez. Bu tür öğrenenlere zayıf bir öğrenci diyoruz ve sözde güçlü öğrenci tasarımı kolay değildir. Gerçek uygulamalara göre Verimlilik ve geliştirme zorluğu açısından, zayıf öğreneni, Boosting entegrasyonumuz olan güçlü öğrenen algoritmasına yükseltmemiz gerekiyor. Boosting fikri hala modelin ağırlıklı ortalamasıdır:

onların arasında
Temel öğrenen,
Temel öğrencinin ağırlık katsayısıdır. Görünüşe göre artırma ve paketleme ifadeleri aynıdır, ancak her temel öğrenen, neredeyse bağımsız bir eğitilmiş modelken, artırmanın her temel öğrenicisi bir önceki adımın sonucunu optimize etmektedir. Örneğin, Adaboost'un yaklaşımı şudur: Önceki öğrenci tarafından yanlış sınıflandırılan örneklere daha fazla ağırlık verilir. Gradyan Artırmanın yöntemi, bir sonraki öğrencinin önceki sınıflandırıcının kalıntısına uymasıdır.
Örneğin, hedefleri vururken, görevimiz mümkün olan her seferinde hedefe vurmaktır. Torbalama entegrasyonu, on hedef atış yapmak gibidir, ancak her hedef kağıt kaldırılacaktır. Her ateş ettiğinizde, en son ne zaman olduğunu bilmiyorsunuz. Performans, o zaman izler çok yoğunlaşacak ve varyans küçük olacak; entegrasyonu artırmak hedef kağıdı değiştirmeden on atış gibidir.Sağa en son ateş ettiğimizde, mümkün olduğunca sola kaydırmaya çalışıyoruz, izler çok yoğun olmayacak, ancak sapma olacaktır. Küçültülecek.
Matematiksel bir bakış açısından, Boosting basit doğrusal regresyon ile tutarlıdır. Basit lineer model özdeğerlerin bir fonksiyonudur ve Boosting'imiz fonksiyonların bir fonksiyonudur. Yapmamız gereken, Kayıp fonksiyonunu en aza indirmektir:

Ancak bu tür bir optimizasyon zor olacaktır, çünkü aynı zamanda k fonksiyonlarını optimize etmemiz gerekir, Boosting açgözlü bir algoritma kullanır, yalnızca mevcut öğrenciyi dikkate alır, çünkü tıpkı bir hedefi vururken olduğu gibi, yavaş yavaş zayıf öğrenenler ekliyoruz Bullseye, dolayısıyla bir tekrarlama formülü var:

İstenilen etkiyi elde edene kadar bir seferde yalnızca bir öğrenciyi optimize etmemiz gerekiyor. Güçlendirme bir yöntem değil, bir yöntem türüdür.Aşağıda, esas olarak birçok insanın anladığı zorlukları açıklamak için bir sınıflandırma ve regresyon örneğinden bahsedeceğiz.
Adaboost
Adaboost muhtemelen en ünlü artırıcı topluluk algoritmasıdır.Orijinal algoritma, sıklıkla kullanılmayan bir üstel kayıp fonksiyonunu kullanır.Böyle bir kayıp çerçevesinde, ikili sınıflandırma örneklerini 0, 1 olarak işaretleyemeyiz. {0, 1} örnek etiketi, dizin terimi 0 göründüğü sürece kaybı 1 yapacağından, bunun yerine {-1, 1} örnek etiketini kullanırız.
Adaboost birçok malzemeyi ayrıntılı olarak açıklayacak, ancak alışılmadık üstel kayıp ve görünüşte karmaşık matematiksel dönüşümlerle birleştiğinde, buluttaki insanları bulutlamak kolaydır, ancak en kritik adımlar yalnızca iki adımdır:
- Öğrencinin ağırlık katsayısını alın
- Her numune turunun ağırlık katsayısını güncelleyin
Başlangıçta, her bir örneğin eşit derecede önemli olduğunu ve her örneğin ağırlığının eşit olduğunu varsaydık. Bu temelde, ilk öğrenciyi eğitiyoruz
Ve sınıflandırma hata oranını alın
Ve bu andaki hata oranını şu anda öğrencinin ağırlık katsayısına dönüştürün:
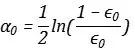
Böyle bir dönüşümü nasıl anlayabilirim? Lojistik regresyondan göreli olasılık olarak sezgisel olarak anlaşılabilir ve matematiksel olarak bu, şu anda öğrencinin üstel kaybını optimize etmenin kaçınılmaz sonucudur.
Üstel kayıp işlevi:

Koymak
Değişken olarak, yukarıda bahsedilen dönüşüm formunu türevini türeterek elde edebiliriz Başka bir deyişle, bu formu elde etmemizin temel nedeni, başkalarıyla hiçbir ilgisi olmayan bir üstel kayıp fonksiyonu kullanmamızdır. Ancak şu anda ağırlığı güncellemediğimize dikkat edin, çünkü öğrencinin ağırlık katsayısının güncellenmesi öğrencinin hata oranını kullanmalıdır.Hata oranı, önceki adımdaki örnek dağılımından elde edilir. Ağırlık katsayısını ancak öğrenmeyi aldıktan sonra güncelleyebiliriz. Bir sonraki adımda kullanılacak numune dağılımı.
İlk ağırlık dağılımının şöyle olduğunu varsayıyoruz:
, Üst simge örneği gösterir ve alt simge yineleme sayısını belirtir. İlk öğrenci eğitimi tamamlandıktan sonra ağırlıklarımız şu şekilde güncellenir:
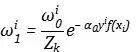
Bu ilişki, mevcut kayıp fonksiyonunun en aza indirilmesinden türetilebilir, ancak sezgisel olarak, her numunenin mevcut ağırlığı numunenin üssel kaybı ile çarpılır.Doğru kategorinin kaybı küçüktür ve yeni ağırlık da küçülecektir.
Bir normalleştirme faktörüne eşdeğer olan tüm ağırlıkların toplamıdır, çünkü toplam örnek olasılığının 1 olmasına ihtiyacımız var.
Bu tür adımları takip ederek, ihtiyacımız olan performansa ulaşana kadar sırayla bir dizi öğrenciyi eğitebiliriz. Örnek güncellemesinin ağırlığının, yeniden örneklemeden ziyade öğrencinin bir sonraki turunun kayıp fonksiyonuna doğrudan katılacağı unutulmamalıdır.
Gradyan Artırma
Gradyan artırma entegrasyonu, üstün performansa sahip başka bir Boosting türüdür. Yaygın biçim, GBDT olarak da bilinen gradyan artırma karar ağacıdır. Bu algoritmayı tam olarak anlamak için, "Gelişmiş Parametrik Olmayan Model" bölümünde regresyon ağaçlarını ayrıntılı olarak tanıttık. Orijinal gradyan entegrasyon yöntemi, regresyon ağaçlarının üst üste binmesidir.
Pek çok malzemenin yükseltilmiş ağaçlar ve eğimli yükseltilmiş ağaçlar olarak sınıflandırıldığını göreceğiz.Güçlendirilmiş ağaçlar, her adımda önceki adımın kalıntılarına uymak için kullanılır ve eğimli ağaçlar, kalıntıları yaklaştırmak için negatif gradyanlar kullanır. Ancak bu görüş, insanların yanlışlıkla kalıntıların negatif gradyanlardan daha temel olduğunu düşünmelerine neden olabilir, ancak gerçekte artıklar ve negatif gradyanlar aynı şeydir ve negatif gradyanların daha genel bir anlamı vardır. Ve en önemlisi, daha genel bir durumda, teorik olarak sığdırmamız gereken şey negatif bir gradyan değildir.
Önce tekrarlama formülüne sahibiz:

Boosting'in kayıp işlevini şu şekilde tanımlayın:

niyet
Bir değişken olarak, kayıp fonksiyonunun Taylor açılımını gerçekleştirin ve onu ikinci dereceden terime tutun:

Kayıp fonksiyonunu en aza indirmek için yukarıdaki Taylor genişlemesini en aza indirmektir.İlk terim sabit bir terimdir ve optimizasyona katılmaz.İkinci terimin katsayısı şu şekilde yazılır:
Üçüncü terimin katsayısı şu şekilde yazılır:
, Son iki öğenin toplamını sıfır yapıyoruz:

Kayıp ortalama kare hatası olduğunda,
Kalıntı mı
1'dir, bu nedenle bir sonraki adımdaki öğrencinin önceki adımın kalıntısına uyması gerekir. Daha genel bir kayıp fonksiyonu için, birinci türevin ve ikinci türevin bölümünü sığdırmamız gerekir, ancak ikinci türev genellikle 1'e yakındır, bu nedenle bir sonraki adımda yerleştirilecek hedef olarak negatif gradyanı seçeriz.
Ancak çeşitli Boosting'in tanıtımında, yalnızca ikinci türevi dikkate almayan, aynı zamanda ikinci türeve bir düzenlileştirme terimi ekleyen xgboost adlı bir algoritma da göreceğiz, böylece uygun hedef şöyle olur:
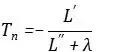

Çekirdeği okuyun
Sınıf İPUÇLARI
Adaboost, üstel bir kayıp işlevi kullanır, ancak üstel kaybın Adaboost'un genel çerçevesi üzerindeki etkisi, öğrenci ağırlığının güncelleme formu ve örnek ağırlığının güncelleme formu ile sınırlıdır.Diğer sınıflandırma kaybı fonksiyonlarını kullanarak Adaboost'u yine de oluşturabiliriz.
Adaboost'ta, esas olarak örnek güncellemesinin ağırlığının kayıp fonksiyonuna girmek için önemli olduğunu vurguladım, böylece yanlış örnek kaybın daha büyük bir oranını oluşturur, ancak aslında yeniden örnekleme adı verilen bir yöntem de kullanabiliriz. Numune alma işlemine numunenin güncellenmiş ağırlığının girilmesi, böylece yanlış numunenin tekrar alınma olasılığının artması ve kayıp fonksiyonunun değiştirilmemesidir.
Gradyan Artırmanın temel çerçevesi, gradyan inişinden anlaşılabilir. Gradyan inişimizin her adımı, Kaybımızın bir öncekine göre azalmaya devam etmesini sağlayacak ve aynı zamanda bir parametre güncellemesini tamamlayacaktır. Gradyan entegrasyon yöntemi, temel öğrenciyi her seferinde eğitecektir. Gradyan inişinin bir güncellemesine karşılık gelir.
Yazar: Head & Shoulders olmadan keşiş
Yeniden yazdırmanız gerekirse, lütfen arka planda bir mesaj bırakın ve yeniden yazdırma şartnamelerine uyun.