Büyük Veri Platformu-AET Bazında Elektrikli Isıtma Gücü Tüketiminin Tahmin ve Analizi
Büyük veri platformuna dayalı olarak elektrikli ısıtma tüketiminin tahmini ve analizi
0 Önsöz
Araştırmacılar, son yıllarda elektrik kullanıcılarının sınıflandırılması ve elektrik tüketiminin özellikleri üzerine bazı çalışmalar yapmışlardır. Örneğin, literatür, geleneksel endüstri bölümüne dayalı küme tabanlı kullanıcı sınıflandırma araştırması önermektedir; literatür ayrıca, araştırma nesnesi olarak mesken güç kullanıcısı türlerini alır ve konut kullanıcılarını ikiye ayırmak için bulut platformu ve kümeleme algoritması K-Means'ı birleştirir. Beş kategori ve çeşitli kullanıcı davranışlarının analizi; literatür - elektrik yükü perspektifinden, endüstri veya ev kullanıcılarını sınıflandırmak, düzenli elektrik tüketimi, tepe ve vadi elektriği gibi şirket kararları için daha hedefli referans temeli sağlar, Belirli bir pratik önemi vardır. Araştırmacılar, akıllı elektrik stratejisinin oluşumunu, kullanıcıların elektrik verimliliğini etkin bir şekilde iyileştirme, ev enerji tüketimini azaltma ve ekonomik elektrik tüketimini gerçekleştirme açısından tartıştı. Ev kullanıcıları açısından literatür, hane kullanıcı sayısı, konut alanı, hane halkı sayısı, günlük elektrik tüketimi, tepe ve vadi elektriği, ev aletleri sayısı vb. Veri boyutlu bir model oluşturmuş ve daha sonra analiz ve madencilik için çok sayıda hane elektrik verisi kullanmaktadır. Kullanıcı yükünün yalnızca kullanıcının kendi çalışma ve dinlenme alışkanlıkları ve ekonomik geliri gibi doğrudan faktörlerden etkilenmediğini, aynı zamanda güneş koşulları, hava durumu, yerel minimum sıcaklık, önemli tatiller ve bölgesel özellikler gibi dolaylı faktörlerle de yakından ilgili olduğunu düşünürsek. Güç tüketimi davranış özelliklerinin farklılaştırılmış analizi, düz bölümlerdeki en yoğun saat güç tüketimi oranı, yük oranı, düşük güç katsayısı ve güç tüketimi yüzdesi gibi talep yanıtı için etkili veri desteği sağlar.
Büyük veri analizi platformuna dayanan bu makale, çeşitli faktörlerin kullanıcının ısıtma gücü tüketimi üzerindeki etkisini incelemek için BP sinir ağı tahmin yöntemini kullanır, kullanıcının ısıtma gücü tüketimi tahmin modelini oluşturur ve son olarak Pekin "Kömürden Elektriğe" proje bilgisine uygular Servis platformunda. Bu makale, proje verilerinin büyük hacmini tam olarak ele alır ve ısıtma gücü tüketimini etkileyen temel faktörleri bulur. Bu araştırma, kullanıcı ısıtma maliyetlerini düşürmek ve dağıtım ağı yapısını ve kullanıcı güç yükü konfigürasyonunu geliştirmek için veri desteği sağlamak açısından olumlu bir öneme sahiptir.
1 Akıllı hizmet platformu mimari tasarımı
Bu makaledeki akıllı hizmet platformunun genel mimarisi, temel olarak aşağıdaki beş seviyeye ayrılmıştır: Şekil 1'de gösterildiği gibi, temel katman, veri toplama katmanı, veri analizi katmanı, entegre uygulama katmanı, sunum katmanı ve birleşik bilgi veritabanı.
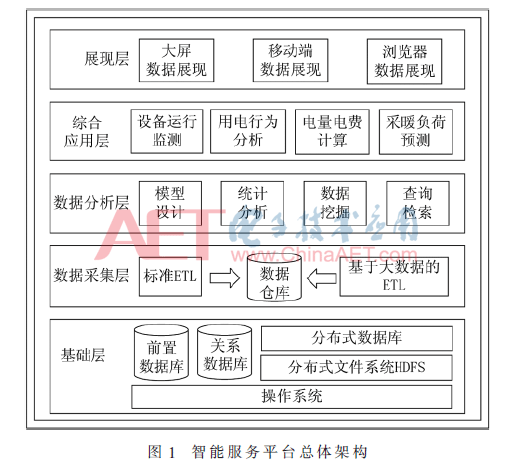
Platformun fonksiyonel mimarisi Şekil 2'de gösterilmektedir.

Kullanıcı, akıllı ısıtma APP'si aracılığıyla ev ısıtma ekipmanını ve toplama ekipmanını gerçek zamanlı olarak izler ve anormal durumlara karşı uyarır.Aynı zamanda, akıllı ısıtma APP'si ısıtma ekipmanını akıllı bir şekilde kontrol eder ve güç kaynağı hizmetlerinin kalitesini iyileştirmek için ısıtma ekipmanının miktarını ve ücret bilgilerini ve sübvansiyon bilgilerini uygun bir şekilde sorgular.
Kullanıcı bilgileri, ısıtma ekipmanı çalışma durumu, iç ortam sıcaklığı, hava durumu bilgileri ve "kömürden elektriğe" projesinin diğer verilerinin toplanması, hesaplanması ve analizi yoluyla işletme, kullanıcıların ısıtma alışkanlıklarını anlar ve kullanıcı ısıtma ve elektrik verilerinin tahminlerinin doğruluğunu iyileştirir. Aynı zamanda, dağıtım ağı yapısının ve kullanıcı yükü yapılandırmasının iyileştirilmesi için veri desteği sağlamak üzere bölgesel yük verilerini birleştirir.
Platformun alt kısmında Hadoop ve bellek içi bilgi işlem motoru Spark'a dayanan HDFS veri depolamasının büyük veri teknolojisinin kullanıldığını belirtmekte fayda var. HDFS dağıtılmış depolama, temel olarak Hadoop uygulamaları tarafından düşük maliyet, yüksek hata toleransı ve yüksek verim gibi büyük veri işleme gereksinimlerini karşılamak için kullanılır. Spark, gelişmiş mimari, verimli bilgi işlem, basit ve kullanımı kolay avantajlara sahiptir ve genel çözümler sağlamak için Hadoop ile sorunsuz bir şekilde bağlanabilir. Ayrıca, Spark'ın makine öğreniminde doğal avantajları vardır.Yinelemeli işleme ve hesaplamalarda Hadoop'tan 100 kat daha hızlıdır ve sistem iyi bir ölçeklenebilirliğe sahiptir.
Örnek veriler, seçilen tipik kullanıcıların evlerine monte edilen sıcaklık ve nem sensörleri, akım ve voltaj sensörleri aracılığıyla toplanır ve veriler 15 dakikalık aralıklarla toplanır.Isıtma sezonu boyunca 10 milyondan fazla ekipman izleme verisi, hava durumu verileri hizmet platformu ile birlikte toplanır. Isıtma sezonunun geçmiş hava durumu kaydı verileri, toplama üreticisi tarafından ETL aracı aracılığıyla sağlanan ön veritabanından büyük verilere dayalı akıllı bir hizmet platformu olan Hive veri ambarına okunur.
NN model eğitimi ve tahmin süreci Şekil 3'te gösterilmektedir. Temel tahmine dayalı analiz adımları aşağıdaki gibidir:
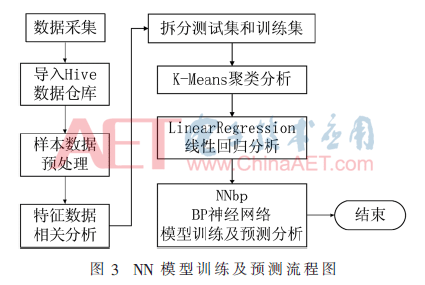
(1) pySpark aracılığıyla veri temizliği için bir iş görev programı yazın, toplanan anormal, eksik ve yinelenen veriler üzerinde ön işlem gerçekleştirin ve her zaman dilimindeki güç tüketimiyle ilgili istatistikleri gerçekleştirin;
(2) Toplanan karakteristik verilerin korelasyon analizi yoluyla, çok düşük korelasyonlu karakteristik verileri çıkarın ve son olarak 0,5'ten büyük korelasyona sahip 5 karakteristik veriyi koruyun;
(3) Özellik verileri üzerinde normalleştirilmiş veri işlemeyi gerçekleştirin ve veri setini iki eğitim seti ve test setine bölün;
(4) Eğitim seti verilerinin kümeleme modelini analiz etmek için MLLib makine öğrenimi kütüphanesinde K-Means kümeleme algoritmasını sağlamak için Spark motorunu kullanın;
(5) Doğrusal regresyon analizi için MLLib makine öğrenimi kitaplığında doğrusal regresyon algoritması LinearRegression sağlamak için Spark motorunu kullanın;
(6) Model eğitimi ve tahmine dayalı analiz için MLLib makine öğrenimi kitaplığında BP sinir ağı algoritması NNbp'si sağlamak için Spark motorunu kullanın.
Bu platform sayesinde, veriler hızlı bir şekilde işlenebilir ve analiz edilebilir, böylece veri analizi ve karar verme verimliliği artırılır.
2 BP model tasarımı ve yapılandırması
Bu makale, model eğitimi ve tahmine dayalı analiz için BP ağını (Back-Propagation Network) kullanır. BP ağı; girdi katmanı, gizli katman ve çıktı katmanından oluşur. Bu çalışmada, 3 katmanlı bir BP ağ modeli m × k × n seçildi ve ağ, S tipi transfer fonksiyonunu f (x) = 1 / (1 + ex) ve E = i (Ti + Oi) 2 / hata fonksiyonunu kullandı. 2 (Ti beklenen çıktıdır, Oi ağın hesaplanan çıktısıdır), E hata fonksiyonunu çok küçük yapmak için ağ ağırlığını ve eşiği sürekli olarak ayarlar.
Bağımsız değişkenler olarak "dış ortam sıcaklığı, dış ortam nemi, iç ortam sıcaklığı, kullanıcı barınma alanı, nüfus" ile BP sinir ağı tahmin yöntemine dayalı olarak, model parametreleri bir tahmin modeli oluşturmak için tekrar tekrar ayarlanır. Bu nedenle, giriş katmanındaki düğüm sayısı 5 ve çıkış katmanındaki düğüm sayısı 1'dir. Ağ tasarımı sürecinde gizli katmandaki nöron sayısının belirlenmesi önemlidir. Çok fazla gizli katman nöronu, ağ hesaplamalarının miktarını artıracak ve kolayca aşırı uyum sorunlarına neden olacaktır; çok az nöron, ağ performansını etkileyecek ve beklenen sonuçları elde edemeyebilir. Ağdaki gizli katman nöronlarının sayısı, asıl sorunun karmaşıklığı, beklenen hatanın ayarı ve giriş ve çıkış katmanlarındaki nöronların sayısı ile doğrudan ilişkilidir. Bu deneyde, gizli katmandaki nöron sayısını seçmek için aşağıdaki ampirik formül kullanıldı:
Bunlar arasında n giriş katmanındaki nöron sayısı, m çıkış katmanındaki nöron sayısı ve a arasında bir sabittir.
Deneysel formüle göre nöron sayısının hesaplanması 4 ile 13 arasında olabilir. Bu deneyde gizli katman nöron sayısı 6 olarak seçilmiştir. Sigmoid farklılaştırılabilir işlevi ve doğrusal işlevi, ağın aktivasyon işlevi olarak genellikle BP sinir ağı tarafından benimsenir. Ağın çıktısı aralığa göre normalize edildiğinden, tahmin modeli, çıktı katmanındaki nöronların aktivasyon işlevi olarak sigmoidal logaritmik fonksiyon tansigini seçer. Tahmin modeli ağ dönemlerinin yineleme sayısı 5000 olarak seçilir, beklenen hata hedefi 0.0001 ve öğrenme oranı lr 0.01'dir.
3 Deney ve sonuç analizi
Bu makale, 2017'den 2018'e kadar Pekin'de "kömürden elektriğe" projesini uygulayan kullanıcıların ölçülen verilerini analiz ediyor. Seçilen veri setleri şunları içerir: dış ortam sıcaklığı, dış nem, iç ortam sıcaklığı, kullanıcı konut alanı, nüfus ve ısıtma gücü tüketimi Tutar. Bu makale, gerçekte 40 günden fazla elektrikli ısıtma kullanan kullanıcıların verilerini seçer, bunları işler ve temizler ve saatlik ısıtma gücü tüketimini tahmin eder. Veriler normalize edilerek toplam 24.150 geçerli veri elde edilmiştir. Şekil 4, 16.180 eğitim verisi üzerinden model tarafından hesaplanan kullanıcının ısıtma gücü tüketiminin tahmin sonuçlarını göstermektedir.

Şekil 4, toplanan karakteristik verilere göre hesaplanan ısıtma yükünün gerçek ve tahmin edilen değerlerini listeler. Göreceli hata ve ortalama hata hesaplama formülüne göre eğitim setinin hesaplanan ortalama kare hatası 0.82194'tür. Gerçek veri eğrisinin ve tahmin edilen verilerin tutarlı olduğu şekilden görülebilmektedir Kullanıcının gerçek zamanlı yük verilerinin eksiksiz ve doğru olduğu varsayımı altında, bu araştırmada benimsenen tahmin modeli, kullanıcıların 24 saat içindeki güç tüketimini etkin bir şekilde tahmin edebilmektedir. Gerçek verilerin birikimi ve model eğitim doğruluğunun iyileştirilmesiyle, gerçek kullanıcı verilerinin tahmini nihayet gerçekleştirilebilir.
4. Sonuç
Bu çalışmada, büyük veri analizine dayalı akıllı bir hizmet platformu oluşturulmuş ve BP ağı, kullanıcının güç tüketimini modellemek ve tahmin etmek için kullanılmaktadır Tahmin sonuçları gerçek verilerle tutarlıdır. Elbette, gerçek tahmin doğruluğu yalnızca dış ortam sıcaklığıyla değil, aynı zamanda kullanıcının hane halkı, oda büyüklüğü ve kullanım tercihleriyle de ilgilidir. Bu nedenle, etkin verinin mevcut kıtlığı göz önüne alındığında, hedeflenen modelleme ve tahmini gerçekleştirmek için sonraki veri takviyeleri kullanılabilir, böylece modelin doğruluğunu daha da iyileştirir ve sistemin daha büyük değer uygulamasına izin verir. Bu belgede kurulan sistem, Pekin'deki "Kömürden Elektriğe" projesinde uygulanmıştır ve dağıtım ağının inşasının ve kullanıcı güç yüklerinin konfigürasyonunun iyileştirilmesi açısından önemli bir değere sahiptir.
Referanslar
Feng Xiaopu Gerçek Yük Eğrisine Dayalı Güçlü Kullanıcı Sınıflandırma Teknolojisi Araştırması Baoding: Kuzey Çin Elektrik Gücü Üniversitesi, 2011.
Zhang Suxiang, Liu Jianming, Zhao Bingzhen.Bulut hesaplamasına dayalı konut elektrik tüketiminin analiz modeli üzerine araştırma.Güç Sistemi Teknolojisi, 2013 (6): 65-69.
Wang Bingxin, Hou Yan, Fang Hongwang. Enerji müşterilerinin "zirve kesme ve doldurma vadisine" yönelik elektrik tüketim davranışlarının analizi. Telecommunications Science, 2017, 33 (5): 164-170.
Zhang Tiefeng, Gu Mingdi. Power User Load Pattern Extraction Technology ve Uygulamasına Genel Bakış. Power System Technology, 2016, 40 (3): 804-811.
Sun Yi, Liu Di, Li Bin, vb. Ev elektrik yükü korelasyonuna dayalı gerçek zamanlı optimizasyon stratejisi Power System Technology, 2016, 40 (6): 1825-1829.
Sun Yi, Feng Yun, Cui Can. Dinamik uyarlanabilir K-ortalamalı kümelemeye dayalı güçlü kullanıcı yük kodlaması ve davranış analizi. Journal of Electric Power Science and Technology, 2017, 32 (3): 3-8.
Zhao Li, Hou Xingzhe, Hu Jun. Geliştirilmiş k-ortalamaları algoritmasına dayalı çok büyük akıllı güç tüketimi veri analizi Güç Sistemi Teknolojisi, 2014 (10): 104-109.
Li Le, Xin Jiang. Pekin kırsal "kömürden elektriğe" kullanıcı yükünün kullanıcı yükü ve güç kaynağı stratejisinin analizi. China Electric Power Enterprise Management, 2017 (10): 56-58.
Liu Xu, Luo Diansheng, Yao Jiangang.Yük ayrışması ve gerçek zamanlı meteorolojik faktörlere dayalı kısa vadeli yük tahmini. Güç Sistemi Teknolojisi, 2009 (12): 98-104.
Su Shi, Li Kangping, Yan Yuting. Yoğunluk uzaysal kümeleme ve yerçekimi arama algoritmasına dayalı konut yükü elektrik tüketimi modeli sınıflandırma modeli.Elektrik Güç Otomasyon Ekipmanları, 2018 (1): 129-136.
yazar bilgileri:
Yang Shuo, Sun Qinfei, Zhu Jie, Chen Ping
(Eyalet Şebekesi Pekin Elektrik Enerjisi Araştırma Enstitüsü, Pekin 100075)