Verileri manuel olarak etiketlemekten vazgeçin! Stanford Üniversitesi Açık Kaynak Zayıf Denetim Çerçevesi
Xin Zhiyuan Rehberi Büyük miktarda veriyi manuel olarak etiketlemek, makine öğreniminin geliştirilmesinde her zaman büyük bir darboğaz olmuştur. Stanford Yapay Zeka Laboratuvarı'ndaki araştırmacılar, programlı olarak eğitim verileri üreten ve açık kaynaklı Snorkel çerçevesini tanıtan "zayıf denetim" paradigmasını tartıştılar.
Son yıllarda, makine öğreniminin (ML) gerçek dünya üzerinde artan bir etkisi oldu. Bu, büyük ölçüde derin öğrenme modellerinin ortaya çıkmasından kaynaklanmaktadır ve uygulayıcıların herhangi bir manuel özellik tasarımı olmaksızın kıyaslama veri setlerinde en son teknolojiye sahip puanları elde etmelerine izin vermektedir. TensorFlow ve PyTorch gibi çok sayıda açık kaynaklı makine öğrenimi çerçevesinin ve mevcut çok sayıda son teknoloji modelin mevcudiyeti göz önüne alındığında, yüksek kaliteli makine öğrenimi modellerinin artık neredeyse ticari bir kaynak olduğu söylenebilir. Bununla birlikte, gizli bir sorun var: bu modeller, Büyük miktarlarda elle etiketlenmiş eğitim verisi .
Bu elle etiketlenmiş eğitim setleri oluşturulur Pahalı ve zaman alıcı -Özellikle alan uzmanlığı söz konusu olduğunda, genellikle toplamak, temizlemek ve hata ayıklamak için aylar, hatta yıllar ve çok fazla insan gücü gerekir. Ek olarak, görevler genellikle gerçek dünyada değişir ve gelişir. Örneğin, işaretleme yönergeleri, ayrıntı düzeyi veya satış sonrası kullanım örnekleri sık sık değişiyor ve yeniden işaretlenmeleri gerekiyor (örneğin, incelemeleri yalnızca olumlu veya olumsuz olarak sınıflandırmakla kalmayın, aynı zamanda tarafsız bir kategori de ekleyin).
Bu nedenlerden dolayı, uygulayıcılar giderek daha fazla Daha zayıf düzenleme Eğitim verilerini sezgisel olarak oluşturmak için harici bilgi tabanlarını, kalıpları / kuralları veya diğer sınıflandırıcıları kullanmak gibi. Esasen bunlar Eğitim verilerini programlı olarak oluşturun Yöntem veya daha kısaca, Eğitim verilerini programlama .
Bu makalede, ilk olarak etiketli eğitim verileriyle yönlendirilen bazı makine öğrenimi alanlarını gözden geçiriyoruz ve ardından çeşitli denetim kaynaklarının modellenmesi ve bütünleştirilmesi konusundaki araştırmamızı anlatıyoruz. Ayrıca, zayıf denetimle onlarca veya yüzlerce dinamik görevi kullanan ve karmaşık ve çeşitli şekillerde etkileşime giren büyük ölçekli çok görevli bir mekanizma için bir veri yönetim sistemi oluşturma fikrini tartıştık.
Gözden Geçirme: Daha fazla etiketli eğitim verisi nasıl elde edilir?
Makine öğrenimindeki birçok geleneksel araştırma yöntemi, etiketli eğitim verilerine olan ihtiyaçtan da kaynaklanmaktadır. Öncelikle bu yöntemleri zayıf denetim yöntemlerinden ayırıyoruz: Zayıf denetim, konu uzmanlarından (KOBİ'ler) daha yüksek düzeyde ve / veya daha gürültülü girdilerin kullanılmasıdır.

Mevcut yaygın yöntemle ilgili temel bir sorun, Büyük miktarda veriyi doğrudan alan adı uzmanları tarafından etiketlemek pahalıdır : Örneğin, tıbbi görüntüleme araştırmaları için büyük veri kümeleri oluşturmak daha zordur, çünkü yüksek lisans öğrencilerinin aksine radyologlar küçük bir iyiliği kabul etmeyecek ve verileri sizin için etiketlemeye istekli olacaktır. Bu nedenle, makine öğreniminde birçok derinlemesine araştırma çalışma hattı, etiketli eğitim verilerini edinme darboğazından kaynaklanır:
- içinde Aktif öğrenme Amaç, alan uzmanlarının model için en değerli olduğu tahmin edilen veri noktalarını etiketlemesine izin vermek ve böylece alan uzmanlarının daha etkili bir şekilde kullanılmasını sağlamaktır. Standart bir denetimli öğrenim ortamında bu, etiketlenecek yeni veri noktalarının seçilmesi anlamına gelir. Örneğin, mevcut modelin karar sınırına yakın olan mamogramları seçebilir ve radyologdan sadece bu fotoğrafları işaretlemesini isteyebiliriz. Bununla birlikte, bu veri noktalarında yalnızca zayıf bir denetime ihtiyaç duyabiliriz Bu durumda, aktif öğrenme ve zayıf denetim mükemmel bir şekilde tamamlayıcıdır; bu konudaki örnekler için lütfen (Druck, yerleş ve McCallum 2009) bakın.
- içinde Yarı denetimli öğrenme Kurulumda amacımız, küçük etiketli bir eğitim seti ve daha büyük bir etiketlenmemiş veri kümesi kullanmaktır. Daha sonra etiketlenmemiş verilerden yararlanmak için pürüzsüzlük, düşük boyutlu yapı veya mesafe ölçütleri hakkındaki varsayımları kullanın (üretken bir modelin parçası olarak veya ayrımcı bir model için normal bir terim olarak veya kompakt bir veri temsilini öğrenmek için); bkz. (Chapelle, Scholkopf ve Zien 2009). Genel olarak, yarı denetimli öğrenme kavramı, KOBİ'lerden daha fazla girdi aramak değil, genellikle düşük maliyetle büyük miktarlarda elde edilebilen etiketlenmemiş verileri kullanmak için etki alanı ve görevden bağımsız varsayımları kullanmaktır. Son yöntemler, karar sınırlarını etkili bir şekilde normalleştirmeye yardımcı olmak için üretken karşıt ağlar (Salimans ve diğerleri 2016), sezgisel dönüşüm modelleri (Laine ve Aila 2016) ve diğer üretken yöntemler kullanır.
- Tipik olarak Transfer öğrenimi Ortamda amaç, farklı veri kümeleri üzerinde eğitilmiş bir veya daha fazla modeli veri kümelerimize ve görevlerimize uygulamaktır; inceleme için bkz. (Pan ve Yang 2010). Örneğin, vücudun diğer bölümlerinde zaten geniş bir tümör eğitim setine sahip olabiliriz ve sınıflandırıcıyı bu temelde eğitebilir ve sonra bunu mamografi görevimize uygulamayı umabiliriz. Günümüzün derin öğrenme topluluğunda, yaygın bir aktarım öğrenme yöntemi, modeli büyük bir veri kümesi üzerinde "önceden eğitmek" ve ardından ilgili göreve göre "ince ayar yapmaktır". Bir diğer ilgili alan, birçok görevin birlikte öğrenildiği çoklu görev öğrenmedir (Caruna 1993; Augenstein, Vlachos ve Maynard 2015).
Yukarıdaki örnek, alan uzmanı işbirlikçilerinden ek eğitim etiketleri almaktan kaçınmamızı sağlayabilir. Bununla birlikte, belirli verilerin işaretlenmesi kaçınılmazdır. Ya onlardan daha hızlı ve daha kolay elde edilebilecek çeşitli türlerde daha gelişmiş veya daha az hassas denetim biçimleri sağlamalarını istersek? Örneğin, radyologlarımız bir öğleden sonrayı bir dizi sezgisel kaynağı veya diğer kaynakları etiketleyerek geçirebilirse ve uygun şekilde kullanılırsa, bu kaynaklar etkin bir şekilde binlerce eğitim etiketinin yerini alabilirse?
Alan bilgisini AI'ya enjekte edin
Tarihsel bir bakış açısına göre, yapay zekayı "programlamaya" çalışmak (yani alan bilgisini enjekte etmek) yeni bir fikir değil, ancak şu anda bu soruyu gündeme getiren ana yenilik, YZ'nin hiçbir zaman şu an olduğu kadar güçlü ve aynı zamanda yorumlanabilirlikte olmamış olmasıdır. Kontrol edilebilirlik açısından hala bir "kara kutu" dur.

1970'lerde ve 1980'lerde yapay zekanın odak noktası uzman sistem , Alan uzmanları tarafından manuel olarak küratörlüğünü yapılan gerçekleri ve kuralları içeren bir bilgi tabanını birleştirir ve bunları uygulamak için bir çıkarım motoru kullanır. 1990'larda ML, bilgiyi yapay zeka sistemlerine entegre etmek için bir araç olarak başarılı olmaya başladı ve güçlü ve esnek olacağına söz verdi Bunu etiketli eğitim verilerinden otomatik olarak elde edin .
Klasik (temsili olmayan öğrenme) makine öğrenimi yöntemleri genellikle alan uzmanları için iki giriş bağlantı noktasına sahiptir. Birincisi, bu modeller genellikle modern modellerden daha iyidir Karmaşıklık çok daha düşük Bu, verilerin manuel olarak etiketlenmesinin daha az kullanılabileceği anlamına gelir. İkinci olarak, bu modeller, modelin verilerinin temel temsilini kodlamak, değiştirmek ve bunlarla etkileşim kurmak için bir yol sağlayan, elle tasarlanmış özelliklere dayanır. Direkt yöntem . Bununla birlikte, özellik mühendisliği, genellikle doktora kariyerinin tamamını belirli görevler için özellikler tasarlamak için harcayan ML uzmanlarının görevi olarak kabul edilir.
giriş Derin öğrenme modeli : Pek çok alan ve görevdeki temsilleri otomatik olarak öğrenme konusundaki güçlü yetenekleri nedeniyle, özellik mühendisliği görevinden büyük ölçüde kaçınırlar. Bununla birlikte, çoğu tamamen kara kutulardır ve çok sayıda eğitim setini işaretlemenin ve ağ mimarisini ayarlamanın dışında, sıradan geliştiricilerin bunlar üzerinde çok az kontrolü vardır. Birçok anlamda, eski uzman sistemin kırılgan ama kontrolü kolay kurallarının tam tersini temsil ediyorlar. Esnek ancak kontrolü zor .
Bu bizi biraz farklı bir perspektiften orijinal soruya geri getiriyor: Modern derin öğrenme modelleri yazmak için alan bilgimizi veya görev uzmanlığımızı nasıl kullanacağız? Eski kural tabanlı uzman sistemin doğrudanlığını, bu modern makine öğrenimi yöntemlerinin esnekliği ve gücü ile birleştirmenin bir yolu var mı?
Denetim olarak kod: programlama yoluyla ML eğitimi
Şnorkel Makine öğrenimi ile bu yeni etkileşim türünü desteklemek ve keşfetmek için oluşturduğumuz bir sistemdir. Snorkel'de elle etiketlenmiş eğitim verilerini kullanmıyoruz, ancak kullanıcıların yazmasını istiyoruz Etiketleme fonksiyonları (LF) , İşaretlenmemiş verilerin bir alt kümesini işaretlemek için kullanılan bir kara kutu kod parçacığıdır.
Ardından, makine öğrenimi modeli için eğitim verilerini etiketlemek için bir dizi LF kullanabiliriz. İşaretleme işlevleri yalnızca rastgele kod parçacıkları olduğundan, rastgele sinyalleri kodlayabilirler: örüntüler, buluşsal yöntemler, harici veri kaynakları, kalabalık çalışanlardan gelen gürültülü etiketler, zayıf sınıflandırıcılar vb. Ayrıca kod olarak, modülerlik, yeniden kullanılabilirlik ve hata ayıklama gibi diğer tüm ilgili faydaları elde edebiliriz. Örneğin, modelleme hedeflerimiz değişirse, markalama işlevini hızla adapte olacak şekilde ayarlayabiliriz!
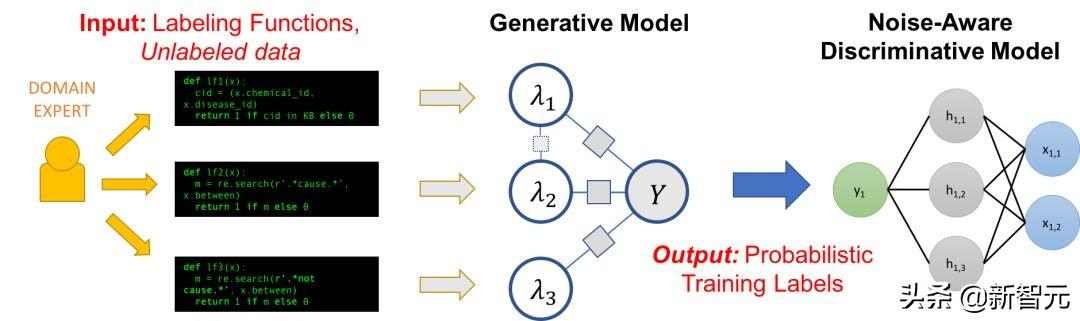
Bir problem, etiketleme fonksiyonunun gürültülü çıktı üretmesidir, bu da çakışabilir ve çakışabilir, bu da ideal eğitim etiketlerinin altında kalmasına neden olur. Snorkel'de, bu etiketleri ortadan kaldırmak için üç adımı içeren bir veri programlama yöntemi kullanıyoruz:
1. Etiketleme işlevini etiketlenmemiş verilere uygularız.
2. Herhangi bir etiketleme verisi olmadan etiketleme fonksiyonlarının doğruluğunu öğrenmek ve çıktılarını buna göre ağırlıklandırmak için üretken bir model kullanıyoruz. Hatta dernek yapısını otomatik olarak öğrenebiliriz.
3. Üretken model, bir dizi olasılık eğitim etiketi çıkarır.Bu etiketleri, etiketleme işlevi tarafından temsil edilen sinyali genelleyen güçlü ve esnek bir ayırt edici modeli (derin sinir ağı gibi) eğitmek için kullanabiliriz.
Bu boru hattının tamamının makine öğrenimi modellerinin "programlanması" için basit, sağlam ve modelden bağımsız bir yöntem sağladığı düşünülebilir!
Etiketleme İşlevleri
Biyomedikal literatürden yapılandırılmış bilgilerin çıkarılması bizi en çok motive eden uygulamalardan biridir: milyonlarca bilimsel makalenin yoğun yapılandırılmamış metninde büyük miktarda yararlı bilgi etkin bir şekilde kilitlenmiştir. Bu bilgileri elde etmek için makine öğrenimini kullanmayı ve ardından bu bilgileri genetik hastalıkları teşhis etmek için kullanmayı umuyoruz.
Böyle bir görevi düşünün: Bilimsel literatürden belirli bir kimyasal-hastalık ilişkisini çıkarın . Bu görevi tamamlamak için yeterince büyük etiketli eğitim veri kümemiz olmayabilir. Bununla birlikte, biyotıp alanında, zengin bilgi ontolojisi, sözlükler ve çeşitli kimya ve hastalık adı verileri, çeşitli bilinen kimyasal-hastalık ilişkisi veri tabanları vb. Dahil olmak üzere diğer kaynaklar vardır. Bu kaynakları bize yardımcı olmak için kullanabiliriz. Görev, zayıf denetim sağlar. Ek olarak, bir dizi göreve özgü buluşsal yöntemler, düzenli ifade kalıpları, pratik kurallar ve negatif etiket oluşturma stratejileri önermek için biyolojik alandaki işbirlikçilerle de çalışabiliriz.

Temsilci olarak üretici model
Yaklaşımımızda düşünüyoruz Marker işlevi dolaylı olarak üretken bir modeli tanımlar . Hızlıca gözden geçirelim: Tahmin etmek istediğimiz veri noktası x ve bilinmeyen etiket y göz önüne alındığında, diskriminant yönteminde, doğrudan P (y | x) modelliyoruz ve oluşturma yönteminde, P ( x, y) = P (x | y) P (y) modellemesi. Örneğimizde, L nesnesinin etiketleme fonksiyonu tarafından üretilen etiket ve y'nin karşılık gelen (bilinmeyen) gerçek etiket olduğu bir eğitim seti etiketleme süreci P (L, y) modelliyoruz. Üretken modeli öğrenerek ve doğrudan P (L | y) 'yi tahmin ederek, esasen nasıl örtüştüğü ve çakıştığına bağlı olarak etiketleme işlevinin göreceli doğruluğunu öğreniyoruz (y'yi bilmemize gerek olmadığını unutmayın!)
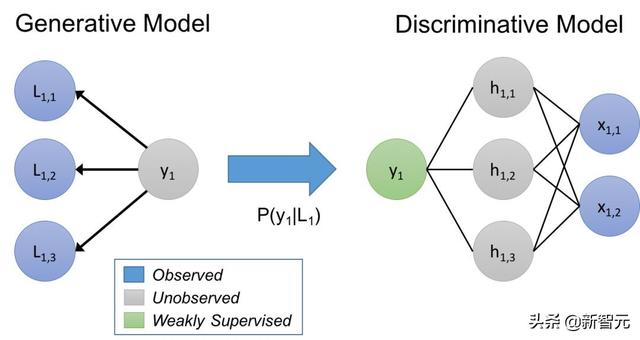
Etiket işlevinde son ayırıcı modelin gürültüye duyarlı bir versiyonunu eğitmek için bu tahmini üretken modeli kullanıyoruz. Bunu yapmak için, üretici model, eğitim verilerinin bilinmeyen etiketlerinin olasılıklarını ortaya çıkarır ve daha sonra bu olasılıklar üzerindeki diskriminant modelin beklenen kaybını en aza indiririz.
Bu üretken modellerin parametrelerini tahmin etmek, özellikle kullanılan etiketleme işlevleri arasında istatistiksel bağımlılıklar olduğunda zor olabilir. Data Programming: Creating Large Training Sets, Quickly (https://arxiv.org/abs/1605.07723) başlıklı makalede, yeterli etiketleme işlevi verildiğinde, denetimli yöntemle aynı asimptotik ölçeklendirmeyi elde edebileceğimizi kanıtladık. . Ayrıca, etiketli verileri kullanmadan etiketli işlevler arasındaki ilişkiyi nasıl öğreneceğimizi ve performansı önemli ölçüde nasıl artırabileceğimizi de inceledik.
Şnorkel: açık kaynaklı bir çerçeve

Snorkel ile ilgili yakın zamanda yayınlanan makalemizde (https://arxiv.org/abs/1711.10160), çeşitli pratik uygulamalarda, modern makine öğrenimi modelleriyle etkileşime girmenin bu yeni yöntemini bulduk. çok etkili ! Dahil etmek:
1. Şnorkel üzerine bir seminerde, KOBİ'lere Şnorkeli öğretmenin verimliliğini ve aynı zamanda verileri manuel olarak etiketlemek için harcamanın verimliliğini karşılaştıran bir kullanıcı çalışması yaptık. Keşfedeceğiz, Bir model oluşturmak için Snorkel kullanmak yalnızca 2,8 kat daha hızlı değil, aynı zamanda ortalama tahmin performansı da% 45,5 oranında artırıldı .
2. Stanford Üniversitesi, ABD Gazi İşleri Bakanlığı ve ABD Gıda ve İlaç Dairesi'nden araştırmacılar ile birlikte iki gerçek metin ilişkisi çıkarma görevinin yanı sıra diğer dört kıyaslama metni ve görüntü görevinde, temel teknolojinin nazaran, Şnorkel ortalama% 132 iyileştirildi .
3. Kullanıcı tarafından sağlanan işaretleme işlevlerini modellemek için yeni bir takas alanı araştırdık ve yinelemeli geliştirme döngüsünü hızlandırmak için kural tabanlı bir optimize edici elde ettik.
Sonraki adım: Büyük ölçekli çok görevli zayıf denetim
Laboratuvarımız, Snorkel tarafından tasarlanan zayıf denetimli etkileşim modelini, zengin biçimde biçimlendirilmiş veriler ve görüntüler, doğal dil kullanarak görevleri denetleme ve etiket işlevlerini otomatik olarak oluşturma gibi diğer modlara genişletmek için çeşitli çabalar göstermektedir!
Teknik açıdan, Snorkel'in temel veri programlama modelini, daha yüksek seviyeli arayüzlerle (doğal dil gibi) işaretleme işlevlerini belirtmeyi kolaylaştırmak ve diğer zayıf denetim türlerini (veri artırma gibi) birleştirmekle ilgileniyoruz.
Çoklu görev öğrenme (MTL) senaryoları Popülerlik aynı zamanda şu soruyu da gündeme getiriyor: Gürültülü, potansiyel olarak alakalı etiket kaynaklarının artık birden fazla ilgili görevi etiketlemesi gerektiğinde ne oluyor? Bu görevlerin ortak modellemesinden faydalanabilir miyiz? Bu sorunları, çok görevli zayıf denetim kaynaklarını destekleyebilen ve bir veya daha fazla ilgili görev için gürültü etiketleri sağlayan Snorkel'ın yeni bir çok görevli bilinçli sürümünde, yani Snorkel MeTaL'de çözdük.
Düşündüğümüz bir örnek Farklı ayrıntı düzeylerine sahip etiket kaynakları oluşturun . Örneğin, belirli kişi ve konum türlerini etiketlemek için ayrıntılı adlandırılmış bir varlık tanıma (NER) modeli eğitmek istediğimizi ve "avukat" ve "doktor" veya "banka" gibi bazı hassas etiketlerimiz olduğunu varsayalım. Ve "hastaneler" ve "insanları" ve "yerleri" işaretlemek gibi bazıları kaba tanelidir. Bu kaynakları farklı düzeylerdeki görevlerle ilgili etiketler olarak temsil ederek, doğruluklarını birlikte modelleyebilir ve daha net ve daha akıllı birleştirilmiş çok görevli eğitim verileri oluşturmak için çoklu görev etiketlerini yeniden ağırlıklandırabilir ve birleştirebilir, böylece nihai MTL modelinin performansı.
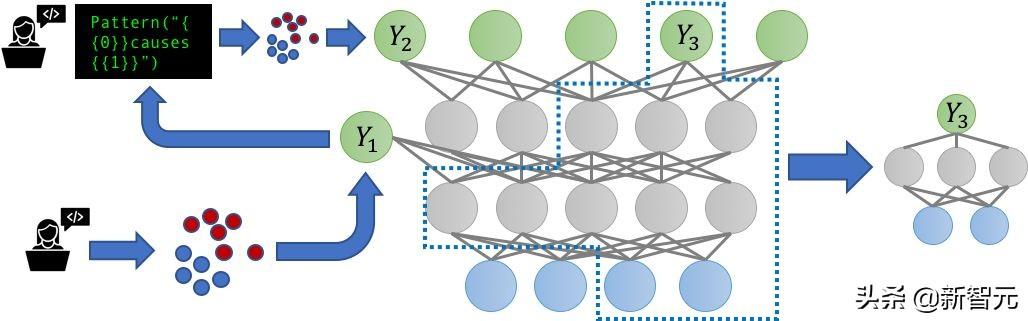
MTL için bir veri yönetim sistemi oluşturmanın en heyecan verici yönünün etrafında döneceğine inanıyoruz. Büyük ölçüde çok görevli rejim Bu mekanizmada, düzinelerce ila yüzlerce zayıf denetlenen (ve bu nedenle oldukça dinamik) görevler karmaşık ve çeşitli şekillerde etkileşimde bulunur.
Bugüne kadarki çoğu MTL çalışması, statik elle etiketlenmiş bir eğitim seti tarafından tanımlanan en fazla birkaç görevi dikkate almış olsa da, dünya hızla yüzlerce çalışmayı sürdürmesi gereken kuruluşlara (büyük şirketler, akademik laboratuvarlar veya çevrimiçi topluluklar) dönüşmektedir. Zayıf bir şekilde denetlenen, hızla değişen ve birbirine bağlı modelleme görevleri. Ek olarak, bu görevler zayıf bir şekilde denetlendiğinden, geliştiriciler, tüm modelin yeniden eğitilmesini gerektirebilecek görevler (yani eğitim seti) saatler veya günler içinde (aylar veya yıllar yerine) ekleyebilir, silebilir veya değiştirebilir.
The Role of Massively Multi-Task and Weak Supervision in Software 2.0 ( adlı yakın tarihli bir makalede, yukarıdaki sorunlardan bazılarını özetliyoruz. İlk fikir, MTL modelinin farklı geliştiriciler tarafından zayıf şekilde etiketlenmiş verileri eğitmek için merkezi bir depo olarak etkili bir şekilde kullanıldığı ve daha sonra merkezi bir "anne" çoklu görev modelinde birleştirildiği büyük ölçekli bir çok görevli ortamı öngörüyor.
Kesin form faktörlerine bakılmaksızın, MTL teknolojisinin gelecekte birçok heyecan verici gelişmeye sahip olduğu açıktır - sadece yeni model mimarileri değil, aynı zamanda transfer öğrenme yöntemleri, yeni zayıf denetimli yöntemler, yeni yazılım geliştirme ve sistemler ile de ilgilidir. Paradigma daha tekdüze hale geliyor.
orijinal:
https://ai.stanford.edu/blog/weak-supervision/
Şnorkel:
[2019 Xinzhiyuan AI Teknoloji Zirvesi için 13 günlük geri sayım]
27 Mart 2019'da Xinzhiyuan, AI'nın gücünü yeniden birleştirdi ve AI açılış töreni-2019 Xinzhiyuan AI Teknoloji Zirvesi'ni Beijing Taifu Hotel'de gerçekleştirdi. Zirve "ile başlıyor Akıllı Bulut Çekirdek Dünya "Tema olarak, akıllı bulut ve AI çiplerinin geliştirilmesine odaklanın ve gelecekteki AI dünya modelini yeniden şekillendirin.
Aynı zamanda, Xinzhiyuan yetkili olarak birkaç kişiyi serbest bırakacak AI teknik raporu , Endüstriyel zincirin yenilikçiliğine ve faaliyetine odaklanın, Çinli yapay zeka bilim adamlarının etkisi hakkında yorum yapın ve Çin'in birinci sınıf yapay zeka rekabetinde geçmesine yardımcı olun.
Bilet satın al
Etkinlik hattı bileti satın alma bağlantısı: 2019 Xinzhiyuan AI Teknoloji Zirvesi-Akıllı Bulut Temel World_Wonderful şehir hayatı, hepsi etkinlik hattında! !
